AWS Partner Network (APN) Blog
Demystifying Natural Language Processing and Machine Learning with Amazon Comprehend
By Ravi Prasad Vangala, Sr. Director, Healthcare Sciences – Virtusa
By Hussain Shabbir, AWS CoE Lead and Sr. Director – Virtusa
By Néstor Gándara, Global Principal Solutions Architect – AWS
 |
| Virtusa |
 |
Not too long ago, it was difficult for many organizations to think of implementing natural language processing (NLP) and machine learning (ML). To implement both, employees had to know multiple algorithms, have expert knowledge of mathematics and statistics, and come up with a well-founded, well-defined selection criteria for the ML algorithm used to process the data.
Processing natural language was also a complex and arduous task, as thousands of lines of code had to comprehend the text and select the right key words and sentiments.
With Amazon Comprehend, the implementation of NLP and ML has become a simple, routine task. Organizations no longer have to spend hours trying to pick the right algorithm, as Amazon Comprehend automatically selects the best ones for any given use case.
Today, building an implementation is easy and quick. It’s the work of three to four weeks, not months. It also boasts an accuracy of 75-90%, depending on the amount of data and training.
In this post, we will explore an implementation of Amazon Comprehend for risk prediction and sentiment analysis on the observations in clinical trials sites. Then, we’ll calculate the risk progression and sentiment progression of the sites over the time taken to complete the trials, and we’ll make any necessary corrective actions.
Virtusa Corporation is an AWS Premier Tier Services Partner and global provider of digital business strategy, engineering, and IT services and solutions.
Clinical Trial Studies
Pharmaceutical companies often conduct clinical trials, and it’s necessary to have these trials monitored and audited by auditors and principal investigators. Based on their site monitoring visits, investigators then prepare audit reports.
Most of these audits contain a set of questions, answers, and free-text comments, which the auditors review. They can then determine if the site is following all necessary guidelines and practices, or if it needs another audit.
Often, reviewing these audit documents takes too much time, which can be as many as 50,000 words. Further complicating the process, clinical trial auditors often must make multiple visits for each site—sometimes one visit a month.
When a client contacted Virtusa for help automating this review process, they wanted to automate the risk and sentiment prediction to help the business (audit teams) make timely decisions and perform corrective actions on future site audits, if needed.
Business Process Flow
Virtusa looked at various possible solutions and decided on Amazon Comprehend, as it allows users to analyze text and provided the necessary risk and sentiment analysis for the client. It also had the right confidence scores.
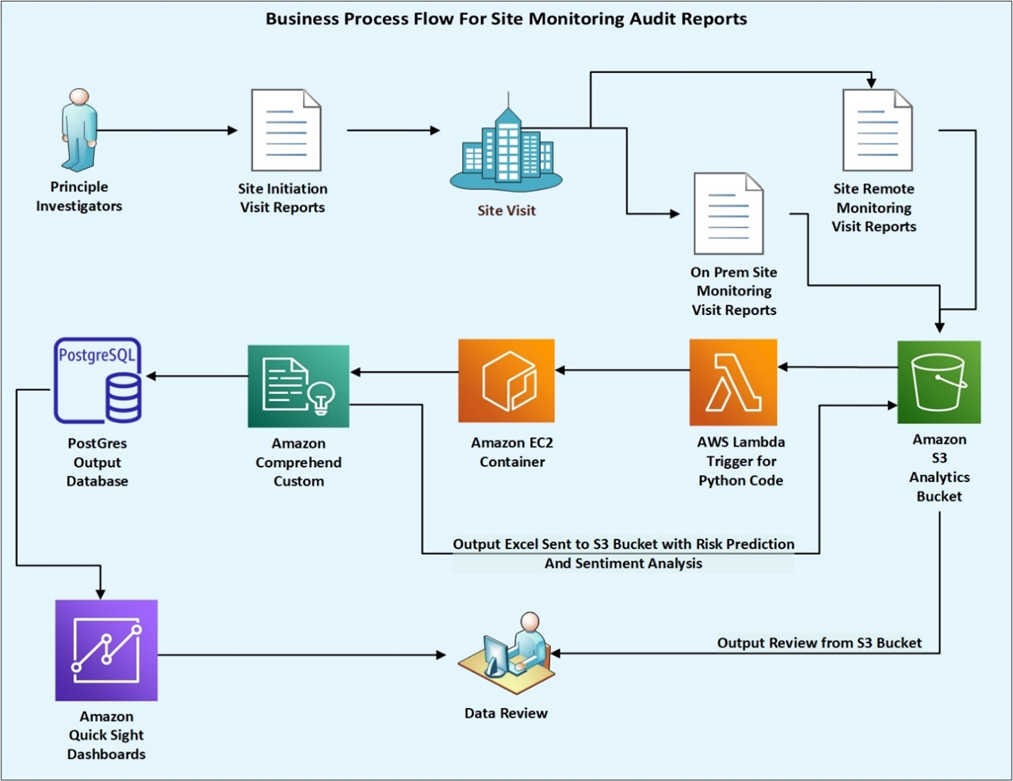
Figure 1 – Business process flow for site audits.
As part of the implementation of the risk and sentiment analysis, Virtusa trained a custom Amazon Comprehend model with labeled data (for both risk and sentiment).
Once the custom model was trained, Virtusa went ahead and processed multiple reports. The team determined that Amazon Comprehend could predict the risk and sentiment with an 80-85% accuracy, even though Virtusa had used a training dataset with approximately 200 comments per model.
Virtusa has now implemented the above solution in the client’s AWS environment. So far, the team has reached an accuracy greater than 85%. Further training is underway, and based on newly-added datasets it’s expected to improve the accuracy of the results.
One of the solution’s biggest strengths is that it enables auditors to review comments labeled “risk” or “sentiment.” This feature helps auditors save a great deal of time, as they don’t have to review the entire document.
All of the above objectives can be achieved with a simple architecture. It requires a training dataset with labeled data, which is usually a .CSV file. The training process is quick, secure, and easy, depending on your desire. In this case, Virtusa needed to first label the sample data according to the project’s needs.
Once the data has been labeled in a .CSV file, it can be loaded into Amazon Comprehend Custom for the purposes of training the model. Once trained, the model can analyze different types of data to predict risk and sentiment, extract the right keywords, and provide the entities in the sentences (a textual reference to the unique name of a real-world object).
Sample Architecture
The sample architecture for implementing Amazon Comprehend is simple and minimalistic. It requires only two Amazon Elastic Compute Cloud (Amazon EC2) or containers, depending of your business needs: one for hosting the Python code, and one for hosting the user experience and user interface, depending on business needs.
It also needs an Amazon Simple Storage Service (Amazon S3) bucket, an Amazon Aurora Postgres database, Amazon Comprehend Custom models, and an Amazon QuickSight dashboard to review the results and monitor the various site audits.
Virtusa trained two models in Amazon Comprehend for performing risk and sentiment analysis. These models need two endpoints, which can be called through the Python code in the EC2 instance, for processing the data and providing the output back to Amazon S3.
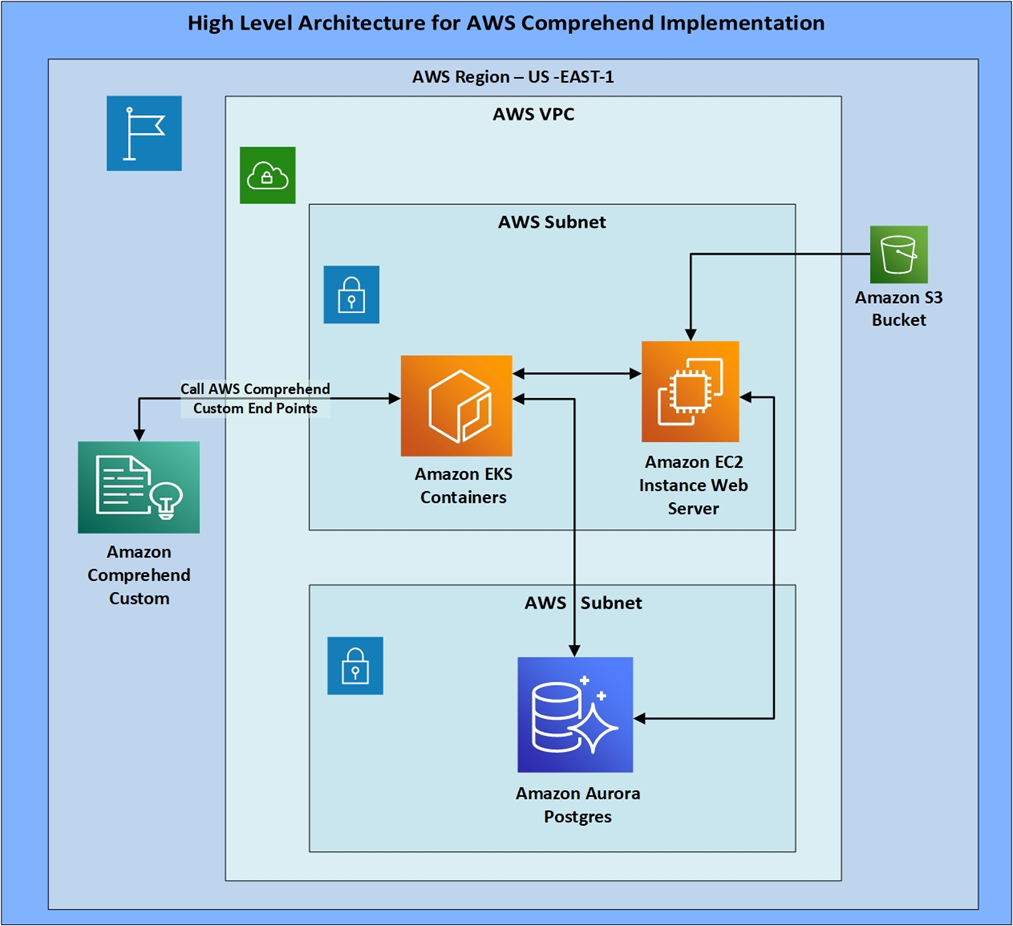
Figure 2 – Sample architecture for implementing Amazon Comprehend.
Once this architecture has been implemented, you need an iterative process that can continue to train Amazon Comprehend and improve its predictions.
Training the Model and Improving its Accuracy
This iterative process consists of the following steps:
- Fetch the data that falls below the confidence score threshold.
- Make sure the data is clean, and accurately label that data again.
- Train the model.
- Re-evaluate the results.
- Deploy the model.
You can continue to repeat the above steps until the accuracy reflects your business needs.
In Virtusa’s case, the team continued to monitor the model for any further reduction of the confidence score threshold. The team repeated the above process as often as necessary to further improve prediction accuracy.

Figure 3 – How accuracy can be improved for Amazon Comprehend.
The diagram above depicts how the model can be fine-tuned and trained for further accuracy. To improve the accuracy, you repeat the above process with all of the data which has fallen out as inaccurate.
Conclusion
Amazon Comprehend is customizable and makes easy work of training and deploying custom machine learning and built-in models. This versatile tool can resolve many of the challenges facing customers today, such as sentiment analysis, entity recognition, document classification, language detection, or key phrase extraction.
To learn more about demystifying the natural language processing journey in order to build smart and disruptive solutions to solve or optimize business needs, visit Virtusa’s website.
.

.
Virtusa – AWS Partner Spotlight
Virtusa is an AWS Premier Tier Services Partner and global provider of digital business strategy, engineering, and IT services and solutions. Virtusa accelerates clients’ cloud adoption through technical, training, and GTM investments.