AWS Partner Network (APN) Blog
Accelerate Workload Migrations with modelizeIT’s Application Architecture Discovery Technology
By Nikolai Joukov, PhD, CEO at modelizeIT
By Jim Huang, PhD, Sr. Partner Solutions Architect at AWS
By Jim Brull, Managing Partner at Centroid Systems
 |
What does it take for an organization to successfully migrate workloads from data centers to the Amazon Web Services (AWS) Cloud?
We believe the critical first step is to analyze the IT assets in your data center using a comprehensive discovery process, followed by a total cost of ownership (TCO) analysis to produce a directional business case for migration.
Discovery of existing applications and business applications, and their dependencies, is required to plan and migrate workloads to AWS. Given this, the data center discovery process is essential in determining the migration business case, and for planning migration waves in an organization’s cloud migration journey.
The discovery process can be tedious and daunting, especially for large-scale data centers that host thousands of applications and tens of thousands of resources. These resources include physical and virtual servers, databases, storage systems, networks, infrastructure equipment, software, and “shadow IT” computers, not to mention dependency relationships that can number in the millions.
In this post, we will describe the key characteristics of technologies needed to effectively serve the discovery purpose—TCO analysis and migration planning.
We will introduce modelizeIT, an advanced discovery and application architecture mapping tool, to illustrate discovery functions and mechanisms, and to demonstrate techniques needed to maximize discovery automation and accuracy.
An AWS Partner Network (APN) Advanced Technology Partner with the AWS Migration Technology Competency, modelizeIT helps customers lower cloud migration risks and costs.
Centroid Systems, a modelizeIT partner, will also share a customer case study to show how modelizeIT helped customers migrate to the AWS Cloud.
Discovery Technology Characteristics
Discovery solutions can be characterized by several key technology characteristics, as outlined below.
Discovery Solution
Typically consists of management function, data collection function, and data repository. The management function can be realized with either software-as-a-service (SaaS) in the cloud, or a server deployed in the source data center environment or cloud.
The data collection function can be agent-based or agentless. The agent-based scheme requires installing a piece of software in each source server to collect data from within the server. The agentless method uses an appliance to collect data from servers through protocols such as SNMP.
A variant is logging onto source servers via secure protocols and server access credentials to collect data. Among these data collection mechanisms are tradeoffs between the depth of data collection, and the compliance of data center security.
Collected data are stored either on-premises or in the repository of the discovery tool outside of the customer environment. This decision depends on the customer’s data retention policy or data sovereignty considerations.
Resources
A discovery solution shall uncover the resources a data center is comprised of, including servers, storage systems (attached and detached), databases, and network equipment in virtual and physical environments.
Data Types
Across the discovered compute, storage, and network resources, a discovery solution collects the following data for target resource right-sizing and TCO analysis:
- CPU model, core count, memory size
- Storage type and capacity
- Database type and capacity
- Network component type and bandwidth
- Operating system version
- Licenses of operating systems, server software, databases, and applications
- Resource utilization in terms of maximum (peak), average (or median), standard deviation over a minimum of one-month period
Dependency Information
This is critical for migration planning and target solution design. Since workload migration takes place on a per application basis, a discovery solution detects and groups software processes across servers and infrastructure resources that constitute an application end-to-end.
This requires the capability of filtering discovered resources, software processes, and traffic flows to help identify individual applications. Server dependency data derived from server connectivity alone is insufficient for application migration planning.
Dependency Visualization
This provides graphical representation of discovered dependency data. The visualization can become complex or even unattainable when the dependency data capture a large number of applications and resources.
To limit the complexity, a discovery solution provides a hierarchical visualization structure with different degrees of dependency abstraction that can be at software process level, server level, and application level. Through the hierarchical structure, users can visualize individual applications and drill down a specific application to its comprising servers and further down to its processes.
Data Import and Export
A discovery solution should be capable of integrating with other tools, importing business and application-specific attributes and values from customer sources. It also exports discovered data in CSV, JSON, SVG, or API for the purposes of TCO analysis and migration planning by downstream tools.
Exploring modelizeIT Solutions for Discovery Problems
The modelizeIT system was designed to collect comprehensive information for a broad range of systems and applications at a deep level, and offer the discovery characteristics described above.
While collecting inventory and utilization information from various hardware systems is typically straightforward, modelizeIT was developed to collect deep information about various applications, including custom and home-grown applications. ModelizeIT maximizes application discovery automation in absence of human inputs.
More information is available at modelizeIT product gallery.
Automated Business Application Identification and Architecture Mapping
An organization that wants to migrate to the AWS Cloud needs to identify its business applications, map each server to the business applications, and map the architecture of all business applications.
If we look at the server connectivity graph just for a few hundred servers, a typical corporate environment would look like this.

Figure 1 – Sample 600 server data center.
The traditional process of understanding the business application details is to rely on IT staff interviews, documentation, and a discovery tool to augment the information.
Unfortunately, the documentation is rarely complete and IT staff’s “tribal knowledge” is often erroneous. In addition, much will be unknown by IT staff (depicted with red color in Figure 3 below).
At the same time, traditional discovery technologies require manual inputs to identify applications and map the architecture, and filter the connections and software components that do not define the business application logic. This is problematic because these manual inputs are labor-intensive and rely on information that is not available.
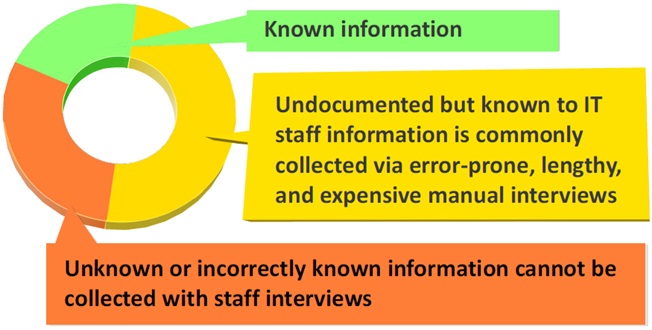
Figure 2 – Data center knowledge in a typical IT organization.
The modelizeIT process consists of collecting deep and comprehensive application data and auto-identifying business application groups without relying on client IT staff knowledge.
Referring to the pie chart in Figure 2, using modelizeIT automated collection solves the discovery of unknown or incorrect application information that cannot be obtained through IT staff interviews (red-colored).
IT staff then reviews, augments, and verifies the collected information versus starting from scratch. The end result is use of significantly less labor, higher accuracy, and completeness of discovery reports.
Illustrated in Figure 3 is a comparison of modelizeIT’s process and a traditional process for application discovery.
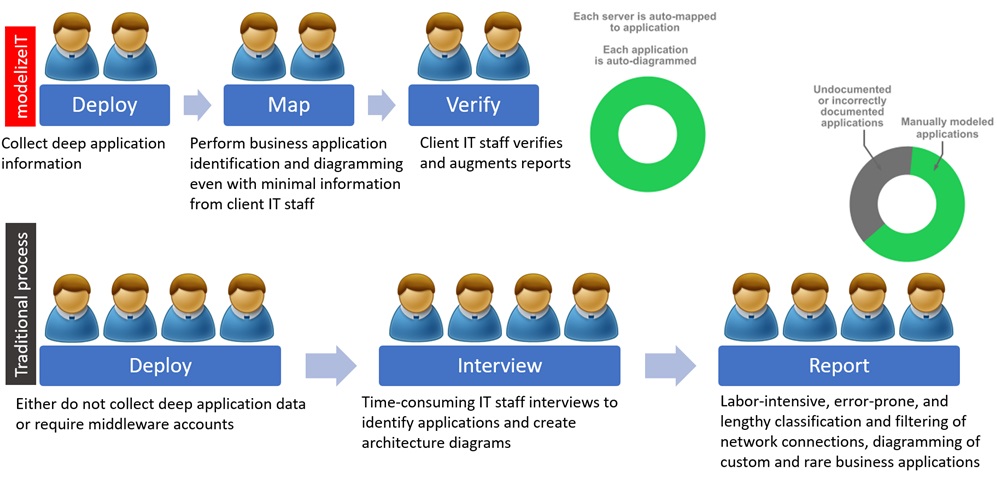
Figure 3 – Automated vs. Traditional information collection process.
Deep and Comprehensive Application Modeling
The following diagram illustrates a business application consisting of two application servers (appserver01 and appserver02) and a database cluster (dbserver01 and dbserver02) inter-connected via F5 load balancers (f5ltm01 and f5ltm02).
In this example, the load balancers are highly shared. The modelizeIT system identifies individual load balancing pools allowing the migration practitioner to trace interdependencies through such shared systems.
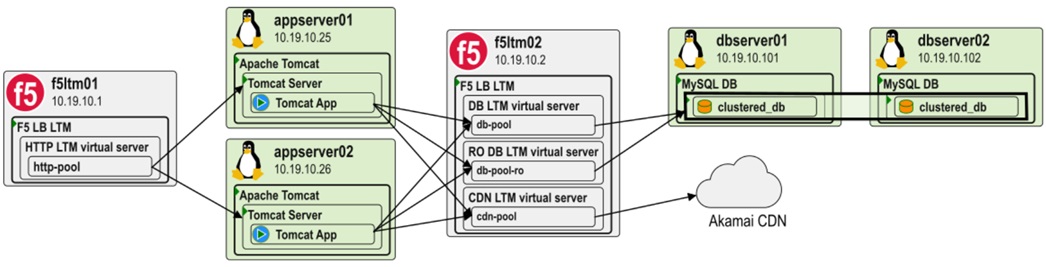
Figure 4 – Example of automated information collection using modelizeIT with load balancers.
Software components shared among hundreds of applications is common. These shared components are commonly database, application, message queueing, file, and web servers.
For example, the diagram in Figure 5 shows a cluster of four application servers (qp12u01, qp12u02, qp12u03, qp12u04) hosting several individual Java applications (TransferBOR, IpmTransferBOR, sabrix-extensions, BOR, ErpEditBOR).
ModelizeIT provides a unique ability to display the clustering details at the software cells level (StageCluster7, StageCluster8, StageCluster9), as well as individual deployed applications (sabrix-extensions is not part of any cell, for example, and is deployed on server qp12u04 only).
Software cells are software-specific clustering implemented by the software for its internal components, such as deployed applications in this example. This is not possible when only the processes or network connections are collected.

Figure 5 – Automated information collection using modelizeIT with Weblogic clusters.
This type of deep software information is being collected for most existing operating systems, such as:
- Microsoft Windows 2000 and above and Hyper-V
- Linux (including zLinux)
- AIX v4 and above (Power and Intel/AMD)
- Solaris v8 and above (SPARC and Intel/AMD)
- HP-UX v10 and above (PA-RISC and Intel/AMD)
- VMware v3 and above
- FreeBSD v4 and above
- SCO UNIX
- Tru64
- Other systems virtualized by the operating systems above, as well as by Oracle virtualization servers, Xen, KVM, and Docker
Deep data collection support is available for most common server software from various vendors:
- Clusters
- Databases
- Web and application servers
- Messaging middleware
- Job schedulers
- Email Servers
- Local and Network File Systems
- Local and Network Block Devices
Collecting the information about applications is challenging because there are so many applications being created by all of the software vendors. The complexity is increased because so many vendors have rare domain-specific or in-house built applications.
ModelizeIT addresses these challenges by:
- Supporting thousands of application signatures out-of-the box.
- Identifying rare or custom applications using special algorithms.
- Providing a quick service to add application models for rare and custom applications.
This depth and breadth of application information offers opportunities for various automated algorithms.
Affinity Grouping and Auto-Drafting Application Architecture Diagrams
Application models from modelizeIT are used to identify applications and classify applications, dependencies, and understand application topologies.
The example in Figure 6 shows how modelizeIT can automatically derive an application affinity group and produce application architecture from a “hair ball” of discovered servers and connections.
With the click of a button, all unmapped servers (displayed as “All Servers”) are automatically assigned to application affinity groups (displayed as “Unknown APPs”) that correspond to a business application or closely intertwined business applications.
Each group can then be investigated by looking at various topological diagrams automatically generated as enterprise architects expect, which is displayed as “IPM (Prod). Because the dependencies are automatically classified, it’s possible to filter out information by type. For example, show storage dependencies and software or not.
As an added benefit, based on application topologies, the modelizeIT system auto-identifies servers as being used for both business and non-business purposes.

Figure 6 – Example of modelizeIT automated application discovery process.
Enterprise Software Licensing
For many enterprises, the cost of licensing is a major TCO contributor, or sometimes even the biggest IT expense. The modelizeIT system creates a software inventory report for all vendors, providing the information needed to make critical licensing decisions.
For products such as Microsoft and IBM, this inventory report contains version, edition, and additional licensing information. However, Oracle licensing is notoriously complex, and even inventory with additional information is not enough to estimate the licensing requirements.
The modelizeIT system fetches both Oracle usage information and system and virtualization information, making it possible to make automated Oracle licensing analysis.
For example, if an Oracle “Partitioning” option is used on a virtual machine (VM) and requires a license, modelizeIT system can map all such VMs to the CPU pools via the virtualization layers and estimate the required number of processor licenses for large corporate environments.
In addition, if the corresponding database is clustered, modelizeIT can include that information in the licensing analysis as well.
The modelizeIT Architecture
The diagram in Figure 7 illustrates the functional components of the modelizeIT system with the main components being:
- Gatherer scans networks and collects the data from servers and other devices.
- Parser processes raw collected data from separate targets into the structured data repository.
- RejuvenApptor is the analysis server that analyzes the data graph as a whole and performs various graph-analytic algorithms and presents the reports to the users.
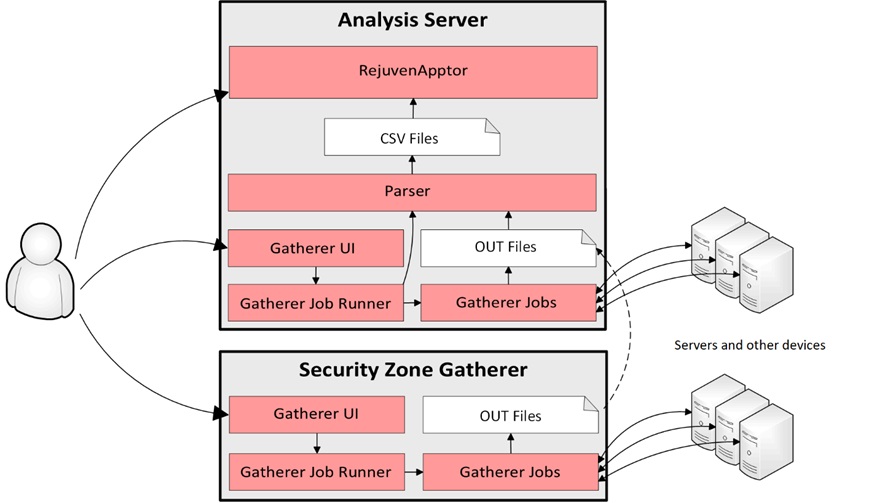
Figure 7 – The modelizeIT analysis server.
The modelizeIT system was designed to be flexible and easy to deploy in various client environments given a multitude of policies and requirements.
Prior to collecting the data from the hosts, the Gatherer(s) can scan networks to locate and recognize the devices using: DNS lookups, ICMP pings, NMAP scans, and SNMP scans.
To collect the data, Gatherer can rely on both SNMP (primarily for network and storage devices) and logging in to servers and fetching necessary software configuration files to get deep software configuration details (primarily for servers).
The data collection and analysis can be performed either entirely on-premises in the client environment, or the data can be analyzed in the cloud on modelizeIT SaaS instances.
In this example, the Gatherer server starts data collection processes on the target servers and relays collected information to the analysis server in the cloud. Migration specialists working on the migration planning can access both the Gatherer server and SaaS interface.
Clients can select the desired geographic data storage location from AWS regions to comply with their compliance requirements.

Figure 8 – The modelizeIT AWS architecture.
Customer Use Case: Centroid Systems
Centroid Systems is an APN Select Technology Partner that provides Oracle enterprise workload consulting and managed services. Centroid’s broad range of capabilities helps clients modernize, transform, and grow their business to the next level.
Prior to engaging with modelizeIT, Centroid used many other tools and a manual process to gather the critical software licensing cost information and other data from their clients needed to complete a TCO customer migration analyses.
Five years ago, Centroid partnered with modelizeIT and started using its tool to accurately and efficiently collect the software licensing costs needed for TCO analysis.
Centroid uses modelizeIT to discover, inventory, and measure clients’ use of various technologies in their data centers to prepare for migrations, and to determine what servers are used and unused prior to migration of applications and systems to the cloud.
The ease of use and accuracy of modelizeIT greatly benefits the Centroid team, and enhances the delivered services. Unlike other tools, modelizeIT quickly and easily captures utilization, determines capacity need, maps application architecture, and supports wave planning.
Over the years, Centroid has used the modelizeIT system to collect and analyze the data for dozens of clients on servers that run various flavors of UNIX, Linux, and Windows operating systems.
These servers are also located across the globe and use tricky clustering, replication, virtualization, and containerization technologies common for the large enterprises. Some of these operating systems and servers are 20 or more years old and were still perfectly handled by modelizeIT system.
As part of large migration projects, Centroid also uses modelizeIT for longer-term monitoring of client environments in preparation for migrations.
For example, one of Centroid’s global clients with approximately 10,000 servers worldwide collected and analyzed information monthly, monitoring actual and detailed trends over a year. As a result of that analysis, the client migrated close to 3,000 servers worldwide to significantly optimize its TCO and risks.
Summary
For many organizations, the data center discovery process is the first step on their cloud migration journey. Application discovery enables migration business case analysis and migration planning.
It’s crucial for organizations to gain application architecture and dependency information in an automated fashion for efficient and effective workload migration.
The modelizeIT system offers unique application architecture mapping opportunities. With modelizeIT, businesses can minimize labor expenses and decrease migration times. This enables migration opportunities that are currently considered too risky or expensive because of the missing application knowledge.
Here are some of the IT domains modelizeIT collects data for and analyzes:
- Application discovery
- Multi-level dependency visualization
- Resource portfolio discovery
- Resource utilization collection
- Database discovery
- Storage discovery
- File system discovery
- Software, framework, language discovery
- License discovery
- Container discovery
- Public cloud discovery
Check out modelizeIT’s customer case studies to see how the discovery tool uncovers unknown applications for the customers, and watch this video to learn more about the modelizeIT application mapping process. To get started, request a demo or pilot.
.

.
modelizeIT – APN Partner Spotlight
ModelizeIT is an AWS Migration Competency Partner and discovery and application architecture mapping tool that helps customers maximize discovery automation and accuracy.
Contact modelizeIT | Solution Overview
*Already worked with modelizeIT? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.