- Điện toán đám mây là gì?›
- Trung tâm khái niệm về điện toán đám mây›
- Cơ sở dữ liệu
Điểm khác biệt giữa Cassandra và HBase là gì?
Điểm khác biệt giữa Cassandra và HBase là gì?
Apache Cassandra và Apache HBase là các cơ sở dữ liệu NoSQL không lưu trữ dữ liệu ở định dạng bảng. Cả hai đều lưu trữ dữ liệu dưới dạng kho khóa-giá trị trên cơ sở hạ tầng dữ liệu lớn để quản lý khối lượng dữ liệu khổng lồ một cách chính xác và hiệu quả. Tuy nhiên, hai cơ sở dữ liệu này có những điểm khác biệt về kiến trúc, phù hợp hơn với các trường hợp sử dụng khác nhau. Ví dụ: Cassandra có hiệu năng đọc và ghi nhanh còn HBase có tính nhất quán của dữ liệu cao hơn. HBase cũng hiệu quả hơn trong việc xử lý các tập dữ liệu lớn, thưa thớt. Các tổ chức sử dụng Cassandra và HBase cho các trường hợp sử dụng dữ liệu lớn khác nhau.
Điểm tương đồng: Cassandra và HBase
Cassandra và HBase là hai cơ sở dữ liệu NoSQL có thể lưu trữ, xử lý và truy xuất hàng tỷ bộ dữ liệu. Hai cơ sở dữ liệu này có những điểm tương đồng trùng lặp trong các lĩnh vực sau.
Ứng dụng dữ liệu lớn
Bạn có thể lưu trữ khối lượng lớn dữ liệu phi cấu trúc, phi quan hệ bằng cả Cassandra và HBase. Hai công cụ này khác với hệ thống cơ sở dữ liệu thông thường, vốn lưu trữ dữ liệu trong các hàng cột đơn giản. Bạn có thể sử dụng Cassandra và HBase để lưu trữ hình ảnh, âm thanh, video và các loại dữ liệu phi cấu trúc khác để xử lý quy mô lớn.
Mã nguồn mở
Apache Software Foundation xuất bản và quản lý Cassandra và HBase dưới dạng các dự án mã nguồn mở. HBase được phát triển từ khái niệm do Google BigTable đưa ra và được Apache phát hành công khai vào năm 2008. Cassandra là một sáng kiến được xây dựng để giải quyết các vấn đề tìm kiếm hộp thư đến của Facebook. Sáng kiến này sử dụng một số tính năng nhất định của BigTable và các tính năng khác từ Amazon Dynamo.
Khả năng điều chỉnh quy mô
Bạn có thể điều chỉnh quy mô của HBase để đáp ứng nhu cầu dữ liệu ngày càng tăng bằng cách thêm nhiều máy chủ khu vực hơn vào cụm HBase. Sau đó, hệ thống cơ sở dữ liệu NoSQL có thể phân phối các nút dữ liệu đến các khu vực mới khi vượt quá một dung lượng nhất định. Một cụm Cassandra cũng có thể hỗ trợ nhiều nút để điều chỉnh quy mô khả năng quản lý dữ liệu của cụm. Bằng cách thêm nhiều nút hơn, bạn có thể phân phối đều dữ liệu và ngăn chặn tắc nghẽn lưu lượng truy cập một cách hiệu quả.
Phục hồi dữ liệu
Các nút dữ liệu trong cả Cassandra và HBase đều có khả năng chịu lỗi. Trong Cassandra, mỗi nút đều hỗ trợ sao chép dữ liệu. Thao tác ghi được tự động cấp cho tất cả các nút được gán dữ liệu cụ thể. HBase có cách tiếp cận sao chép dữ liệu tương tự, được tự động hóa bởi Hệ thống tệp phân tán Hadoop (HDFS) mà HBase dùng để chạy. HDFS tạo và duy trì các bản sao dữ liệu trên các máy chủ khác nhau. Cả hai cơ sở dữ liệu NoSQL đều sao chép các nút dữ liệu trong các mạng vật lý khác nhau dựa trên hệ số sao chép để giảm rủi ro lỗi trên toàn mạng.
Đường dẫn ghi
Cả Cassandra và HBase đều sắp xếp dữ liệu thành các cột. Khi lưu trữ dữ liệu, mỗi cơ sở dữ liệu tìm kiếm bộ cột thích hợp, trong đó nhóm thông tin có liên quan lại với nhau. Cả hai cơ sở dữ liệu cũng ghi dữ liệu vào các tệp bản ghi khi cơ sở dữ liệu đang gắn hoặc lưu trữ dữ liệu vào cột.
Điểm khác biệt về kiến trúc giữa Cassandra và HBase
Cassandra và HBase hoạt động với các đặc điểm khác nhau của định lý CAP. Định lý CAP chỉ rõ rằng các hệ phân tán có thể sở hữu hai trong số các đặc điểm sau tại bất kỳ thời điểm nào:
- Tính nhất quán
- Độ sẵn sàng
- Dung sai phân vùng
Vì dung sai phân vùng là bắt buộc đối với cơ sở dữ liệu lưu trữ các tập dữ liệu khổng lồ nên Cassandra và HBase có độ sẵn sàng và tính nhất quán khác nhau. Cassandra có độ sẵn sàng và dung sai phân vùng cao do cách sắp xếp nút ngang hàng. HBase đảm bảo tính nhất quán với dung sai phân vùng vì một HBase chính duy nhất sao chép dữ liệu cho tất cả các nút.
Tiếp theo, chúng tôi giải thích thêm những điểm khác biệt về kiến trúc trong cách quản lý các yêu cầu dữ liệu của cả hai cơ sở dữ liệu này.
Mô hình dữ liệu
Cả Cassandra và HBase đều sắp xếp dữ liệu thành các nhóm, hàng và cột nhưng mỗi cơ sở dữ liệu có bố cục khác nhau. Trong Cassandra, các cột dữ liệu liên quan được lưu trữ trong các hàng dưới một danh mục rộng hơn được gọi là không gian khóa. Ví dụ: cơ sở dữ liệu Cassandra có thể chứa cách sắp xếp không gian khóa, bộ cột và ô như sau:
- Không gian khóa: CustomerOrders
- Bộ cột: Khách hàng
- ID, Tên, Họ
- Bộ cột: Đơn hàng
- ID, Mặt hàng, Giá
- Bộ cột: Khách hàng
Bộ cột Khách hàng nằm trong một phân vùng phía trên bột cột Đơn hàng. Trong các ứng dụng thực tế, không gian khóa xếp chồng nhiều cột trong bộ với nhau.
Kiến trúc HBase có bố cục giống với cơ sở dữ liệu quan hệ thông thường. Thay vì có một ID cho mỗi bộ cột, HBase sử dụng các khóa hàng tuần tự trong một bảng. Sau đó, công cụ này sắp xếp các cột thuộc cùng một bộ cột cạnh nhau để dễ dàng truy xuất dữ liệu. Dưới đây là một ví dụ:
- Bảng; CustomerOrders
- Khóa hàng, Bộ cột: Khách hàng {Tên, Họ}, Bộ cột: Đơn hàng {Mặt hàng, Giá}
Tìm hiểu về cơ sở dữ liệu quan hệ
Thành phần chính
Cassandra sử dụng một kỹ thuật gọi là hashing nhất quán để cho phép mỗi node tìm thấy dữ liệu cụ thể một cách nhanh chóng trong mạng ngang hàng của nó. Các thành phần chính của kỹ thuật này bao gồm các bảng memtable, commit log và SS. Các bảng này cùng tạo thành đường dẫn ghi cho các nút, trung tâm dữ liệu và cụm trong kiến trúc Cassandra.
HBase nằm ở đầu HDFS. Công cụ này sử dụng HBase chính, máy chủ khu vực và Zookeeper để quản lý dữ liệu.
Cassandra cung cấp dịch vụ quản lý dữ liệu và kho lưu trữ dữ liệu một cách độc lập còn HBase yêu cầu các hệ thống bên ngoài để có khả năng lưu trữ dữ liệu.
Thiết kế lõi
Cassandra chạy trên kiến trúc chủ động-chủ động, trong đó mỗi nút phản hồi các thao tác ghi và yêu cầu. Ngay cả khi một nút cụ thể không lưu trữ dữ liệu được yêu cầu thì vẫn truy xuất dữ liệu từ các nút khác bằng phương thức giao tiếp ngang hàng được gọi là giao thức gossip.
HBase sử dụng thiết lập chính-phụ, trong đó HBase chính có quyền kiểm soát đối với các máy chủ khu vực của nút khác. Kiến trúc HBase thể hiện một điểm lỗi duy nhất nếu không có bản sao của HBase chính. Bạn có thể sao chép nhiều nút chính HBase nhưng chỉ có một nút chịu trách nhiệm cho tất cả các máy chủ khu vực.
Hình ảnh sau đây cho thấy thiết lập chính-phụ trong HBase.
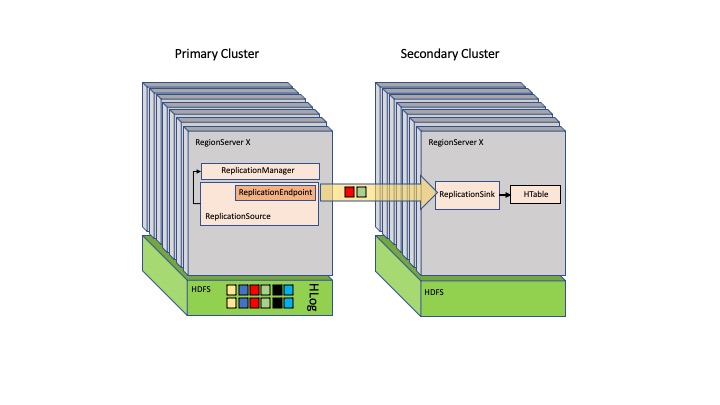
Ngôn ngữ truy vấn
Cassandra cho phép thao tác với dữ liệu trong cơ sở dữ liệu với Ngôn ngữ truy vấn Cassandra (CQL). Bạn sử dụng CQL để thêm, xóa hoặc cập nhật bản ghi trong hướng dẫn mô tả tương tự như SQL. Ngôn ngữ truy vấn HBase bao gồm các lệnh shell cơ bản cần nhiều nỗ lực học tập hơn.
Hiệu năng: Cassandra và HBase
Cả Cassandra và HBase đều cung cấp quyền truy cập tốc độ cao vào các tập dữ liệu lớn để phân tích dữ liệu lớn. Các cơ sở dữ liệu cho thấy những điểm khác biệt về hiệu năng trong các khía cạnh sau.
Độ trễ
Độ trễ là khoảng cách thời gian giữa việc gửi một lệnh đến hệ thống cơ sở dữ liệu và lưu trữ hoặc truy xuất dữ liệu. Nói chung, HBase cho thấy độ trễ thấp hơn khi số lần đọc và ghi dữ liệu tăng lên. Ngược lại, Cassandra cho thấy độ trễ lớn hơn khi nó tìm nạp nhiều dữ liệu hơn.
Thông lượng
Thông lượng đo lường số lượng thao tác đọc hoặc ghi mà cơ sở dữ liệu xử lý mỗi giây. HBase duy trì thông lượng nhất quán từ 100.000-200.000 thao tác nhưng cho thấy sự gia tăng sau khi đạt 250.000 thao tác. Thông lượng của Cassandra tăng lên khi ghi hoặc đọc nhiều dữ liệu hơn.
Hiệu năng đọc
Một thao tác đọc trong Cassandra liên quan đến việc tìm vị trí chính xác của dữ liệu đã lưu trữ trên bảng phân vùng. Nếu tìm kiếm liên quan đến khóa phụ hoặc bảng không phân vùng, Cassandra mất nhiều thời gian hơn để tìm kiếm mọi nút trong cụm. Đồng thời, dữ liệu sẽ không nhất quán khi một số nút chứa các phiên bản khác nhau của cùng một dữ liệu.
HBase có hiệu năng đọc tốt hơn Cassandra vì ghi tất cả dữ liệu vào một máy chủ duy nhất. Không giống như trong Cassandra, thao tác đọc dữ liệu trong HBase không yêu cầu hệ thống cơ sở dữ liệu tìm kiếm thông qua bảng phân vùng. HDFS mà HBase sử dụng để lưu trữ dữ liệu cung cấp bộ lọc bloom và bộ nhớ đệm khối, giúp tăng tốc độ truy xuất dữ liệu.
Hiệu năng ghi
Cassandra hoàn thành thao tác ghi nhanh hơn HBase. Với Cassandra, bạn có thể đồng thời ghi dữ liệu vào bản ghi và bộ nhớ đệm. HBase không hỗ trợ ghi đồng thời. Thay vào đó, ứng dụng máy khách HBase đi qua Zookeeper để bắt đầu thao tác ghi, trong đó HBase chính cung cấp địa chỉ để lưu trữ dữ liệu. Các bước bổ sung trong HBase làm chậm quá trình ghi dữ liệu.
Các điểm khác biệt chính: Cassandra và HBase
Bạn có thể sử dụng cả Cassandra và HBase để xây dựng các ứng dụng khoa học dữ liệu nhưng những điểm khác biệt nhỏ sẽ ảnh hưởng đến quyết định chọn ứng dụng này hay ứng dụng kia.
Bảo mật
Với Cassandra, bạn có thể điều tiết quyền truy cập vào cấp hàng của bản ghi. Công cụ này cũng cung cấp mã hóa SSL để bảo vệ trao đổi dữ liệu giữa các nút. Không giống như Cassandra, HBase cung cấp thêm các tính năng mã hóa và mã hóa cùng xác thực cấp ô.
Phân vùng dữ liệu
Cassandra hỗ trợ phân vùng có thứ tự và có thể quét các bản ghi được sắp xếp tuần tự bằng cách sử dụng một cột làm khóa phân vùng. Mặc dù cách này có thể hữu ích nhưng việc phân vùng có thứ tự khiến việc cân bằng tải trở nên phức tạp với nhiều lần ghi diễn ra trên một nút duy nhất. Bảng HBase không hỗ trợ phân vùng có thứ tự.
Giao tiếp nút
Trong kiến trúc Cassandra, các nút hạt giống là những điểm chính giao tiếp chính giữa các cụm. Các nút này sử dụng giao thức gossip để di chuyển dữ liệu giữa các cụm khác nhau. HBase sử dụng một nút chính HBase đang hoạt động để điều phối giao tiếp giữa một số máy chủ khu vực. Trong kiến trúc này, việc di chuyển dữ liệu được đàm phán bởi giao thức Zookeeper.
Thời điểm nên sử dụng: Cassandra hay HBase
Cả cơ sở dữ liệu Cassandra và HBase đều có thể giúp các loại ứng dụng dữ liệu lớn khác nhau. Tiếp theo, chúng ta chia sẻ cơ sở dữ liệu phân tán nào sẽ hoạt động tốt hơn trong các trường hợp khác nhau.
Độ sẵn sàng và tính nhất quán
Cassandra phù hợp với các trường hợp sử dụng yêu cầu ghi dữ liệu thường xuyên nhưng không được tối ưu hóa để cập nhật hoặc xóa dữ liệu thường xuyên. Ví dụ: các tổ chức sử dụng Cassandra để xây dựng hệ thống nhắn tin, giải pháp xử lý dữ liệu tương tác và lưu trữ dữ liệu cảm biến theo thời gian thực. HBase phù hợp hơn cho các ứng dụng yêu cầu tính nhất quán của dữ liệu và xử lý thường xuyên. Ví dụ: các giải pháp ngân hàng, chăm sóc sức khỏe và viễn thông sử dụng HBase để phân tích khối lượng lớn dữ liệu.
Thiết lập cơ sở dữ liệu
Cassandra dễ thiết lập hơn vì là một sản phẩm độc lập, có tất cả các thành phần cơ sở dữ liệu cần thiết. Không giống như Cassandra, HBase hoạt động dựa vào một số thành phần Hadoop, chẳng hạn như Zookeeper, HDFS chính và HDFS DataNode. Việc thiết lập có thể đơn giản nhưng việc duy trì nhiều phần phụ thuộc lẫn nhau có thể khó khăn trong các ứng dụng thực tế. Nếu đang sử dụng cơ sở hạ tầng Hadoop, bạn có thể thấy việc di chuyển sang HBase dễ dàng hơn việc di chuyển sang Cassandra.
Tóm tắt các điểm khác biệt giữa Cassandra và HBase
|
Cassandra |
HBase |
|
|
Thiết kế lõi |
Sử dụng kiến trúc chủ động-chủ động. Tất cả các nút xử lý các yêu cầu đọc/ghi. |
Sử dụng kiến trúc chính-phụ. HBase chính kiểm soát một số máy chủ khu vực. |
|
Thành phần chính |
Bảng memtable, commit log và SS. |
HBase chính, máy chủ khu vực và Zookeeper. |
|
Mô hình dữ liệu |
Lưu trữ các hàng của các bộ cột có liên quan trong không gian khóa. |
Các bộ cột được sắp xếp theo chiều ngang với một khóa hàng tuần tự. |
|
Ngôn ngữ truy vấn |
Sử dụng Ngôn ngữ truy vấn Cassandra. |
Sử dụng lệnh shell. |
|
Độ trễ |
Độ trễ cao hơn với nhiều thao tác tìm nạp dữ liệu hơn. |
Độ trễ thấp hơn với nhiều thao tác dữ liệu hơn. |
|
Thông lượng |
Thông lượng tăng với nhiều thao tác dữ liệu hơn. |
Thông lượng tăng sau một số thao tác nhất định. |
|
Hiệu năng đọc |
Đọc chậm. Đề cập đến bảng phân vùng cho vị trí đọc. Có thể xảy ra mâu thuẫn dữ liệu. |
Hiệu năng đọc và tính nhất quán của dữ liệu tốt hơn. |
|
Hiệu năng ghi |
Hiệu năng ghi tốt hơn. Đồng thời ghi vào bản ghi và bộ nhớ đệm. |
Các bước bổ sung. Đi qua Zookeeper và HBase chính. |
|
Bảo mật |
Điều tiết quyền truy cập lên đến cấp vai trò. |
Điều chỉnh quyền truy cập lên đến cấp ô. |
|
Phân vùng dữ liệu |
Hỗ trợ phân vùng có thứ tự. |
Không hỗ trợ phân vùng có thứ tự. |
|
Giao tiếp nút |
Sử dụng giao thức gossip. |
Sử dụng giao thức Zookeeper. |
AWS có thể hỗ trợ các yêu cầu về Cassandra và HBase của bạn như thế nào?
Amazon Web Services (AWS) cung cấp các dịch vụ cơ sở dữ liệu đám mây có thể điều chỉnh quy mô mà bạn có thể sử dụng để triển khai các công nghệ khoa học dữ liệu một cách hiệu quả và với giá cả phải chăng. Thay vì cung cấp cơ sở hạ tầng cơ bản theo cách thủ công, bạn có thể sử dụng các dịch vụ AWS sau đây để hỗ trợ cơ sở dữ liệu Cassandra và HBase của mình:
- Amazon Keyspaces (dành cho Apache Cassandra) là một dịch vụ cơ sở dữ liệu trực tuyến để chạy khối lượng công việc Cassandra thông lượng cao. Với Amazon Keyspaces, bạn có thể điều chỉnh quy mô ứng dụng trong khi vẫn duy trì thời gian phản hồi chỉ vài mili giây.
- Với Amazon EMR, bạn có thể triển khai các cụm HBase cho các ứng dụng xử lý dữ liệu quy mô lớn. Chạy HBase trên EMR cải thiện khả năng phục hồi dữ liệu bằng cách sao lưu dữ liệu được lưu trữ trên Amazon Simple Storage Service (Amazon S3).
Bắt đầu với phân tích dữ liệu lớn trên AWS bằng cách tạo tài khoản ngay hôm nay.