В чем разница между Cassandra и HBase?
В чем разница между Cassandra и HBase?
Apache Cassandra и Apache HBase – это две базы данных NoSQL, в которых данные хранятся в нетабличном формате. Обе они хранят данные в формате «ключ-значение» в инфраструктуре больших данных, что позволяет точно и эффективно управлять огромными объемами данных. Но у них есть архитектурные различия, оптимизированные для разных вариантов использования. Например, Cassandra обеспечивает высокую производительность чтения и записи, а HBase гарантирует более высокую согласованность данных. HBase также более эффективно справляется с обработкой больших и разреженных наборов данных. Организации используют Cassandra и HBase в разных сценариях работы с большими данными.
Сходства Cassandra и HBase
Cassandra и HBase — две базы данных NoSQL, которые могут хранить, обрабатывать и извлекать миллиарды наборов данных. Они имеют некоторые сходства, которые описаны ниже.
Приложение для работы с большими данными
Как в Cassandra, так и в HBase вы можете хранить огромные объемы неструктурированных нереляционных данных. Они отличаются от традиционной системы баз данных, которая хранит данные в простых строках столбцов. Вы можете использовать Cassandra и HBase для хранения изображений, аудио, видео и других типов неструктурированных данных для обработки в большом масштабе.
Компоненты с открытым исходным кодом
Фонд программного обеспечения Apache издает Cassandra и HBase в формате проектов с открытым исходным кодом и управляет ими. HBase была разработан на основе концепции BigTable, представленной Google и выпущенной Apache в свободный доступ в 2008 году. Cassandra создавалась как инициатива для решения проблем с поиском по входящим сообщениям в Facebook. В ней используются некоторые функции из BigTable и Amazon Dynamo.
Подробнее об открытом исходном коде
Масштабируемость
Вы можете масштабировать HBase в соответствии с ростом потребностей в обработке данных, просто добавляя в кластер HBase новые региональные серверы. Система базы данных NoSQL перераспределит узлы данных по новым регионам, когда будет превышен определенный уровень пропускной способности. Кластер Cassandra также может поддерживать несколько узлов для масштабирования возможностей по управлению данными. Новые узлы помогут эффективно распределять данные и избежать узких мест с передачей трафика.
Восстановление данных
Узлы данных в Cassandra и HBase обладают отказоустойчивостью. В Cassandra поддерживается репликация данных для каждого узла. Операция записи автоматически направляется на все узлы, которым назначены сохраняемые данные. В HBase применяется аналогичный подход к дублированию данных, автоматизацию которого обеспечивает распределенная файловая система Hadoop (HDFS), на основе которой работает база данных. HDFS создает и хранит копии данных на разных серверах. Обе базы данных NoSQL дублируют узлы данных в разных физических сетях с учетом коэффициента репликации, чтобы снизить риск сбоев во всей сети.
Путь записи
И Cassandra, и HBase структурируют данные по столбцам. При сохранении данных каждая из баз данных ищет подходящее семейство столбцов, в котором содержится связанная информация. Также обе базы данных также записывают данные в файлы журнала при добавлении или изменении данных в столбце.
Архитектурные различия: Cassandra и HBase
Cassandra и HBase работают с разными характеристиками теоремы CAP. Теорема CAP определяет, что распределенные системы могут в любой момент времени обладать только двумя из следующих характеристик:
- Согласованность
- Доступность
- Устойчивость к разделению
Поскольку для баз данных, хранящих большие наборы данных, устойчивость к разделению является обязательным требованием, Cassandra и HBase отличаются друг от друга в подходах к доступности и согласованности. Cassandra гарантирует высокий уровень доступности и устойчивость к разделению благодаря архитектуре одноранговых узлов. HBase обеспечивает согласованность и устойчивость к разделению, поскольку один первичный сервер HBase реплицирует данные на все узлы.
Далее мы расскажем о дополнительных архитектурных различиях, от которых зависит обработка запросов в обеих базах данных.
Модель данных
И Cassandra, и HBase организуют данные по группам, строкам и столбцам, но они используют разные макеты. В Cassandra столбцы связанных данных хранятся в строках в более широкой категории, называемой пространством ключей. Например, база данных Cassandra может иметь следующую структуру ключевого пространства, семейств столбцов и ячеек:
- Ключевое пространство: CustomerOrders
- Семейство колонок: Client
- ID, FirstName, LastName
- Семейство колонок: Orders
- ID, Item, Price
- Семейство колонок: Client
Семейство столбцов Client расположено в иерархии выше семейства столбцов Orders. В реальных приложениях каждое пространство ключей объединяет несколько столбцов семейства.
Компоновка в архитектуре HBase аналогична структуре традиционных реляционных баз данных. Вместо идентификатора для каждого семейства столбцов HBase использует последовательные ключи строк в таблице. Столбцы, принадлежащие одному семейству столбцов, размещаются рядом друг с другом для удобного извлечения данных. Вот один из примеров:
- Таблица: CustomerOrders
- Ключ строки, семейство столбцов: Client {First Name, LastName}, семейство столбцов: Order {Item, Price}
Подробнее о реляционных базах данных
Ключевые компоненты
Cassandra использует метод последовательного хеширования, позволяющий каждому узлу быстро находить определенные данные в своей одноранговой сети. Ключевыми компонентами архитектуры являются таблицы memtable, журнал подтвержденных транзакций и таблицы SS. Вместе они формируют путь записи для узлов, центров обработки данных и кластеров в архитектуре Cassandra.
HBase функционирует поверх HDFS. Она использует первичный сервер HBase, региональный сервер и Zookeeper для управления данными.
Cassandra самостоятельно обеспечивает управление данными и хранение данных, а HBase для хранения данных требуются внешние системы.
Базовая структура
Cassandra работает по схеме «активный – активный», где каждый узел отвечает на запросы чтения и записи. Даже если на узле нет запрошенных данных, он получает их от других узлов по протоколу gossip, который обеспечивает одноранговое взаимодействие.
HBase использует схему «первичный – вторичный», в которой первичный сервер HBase контролирует региональные серверы других узлов. Архитектура HBase имеет единую точку отказа, если для первичного сервера HBase не существует реплик. Вы можете создать несколько первичных узлов HBase, но только один из них будет управлять региональными серверами.
На следующем рисунке представлена схема первичных и вторичных узлов в архитектуре HBase.
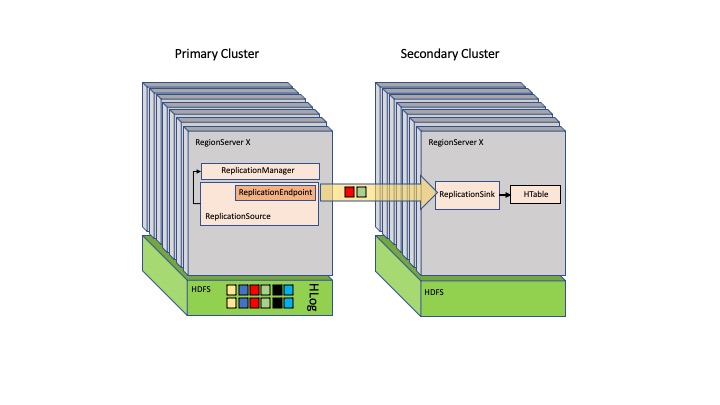
Язык запросов
Cassandra позволяет управлять данными в базе данных с помощью языка запросов Cassandra (CQL). CQL использует описательные инструкции, аналогичные SQL, для добавления, удаления или обновления записей. Язык запросов HBase состоит из базовых команд оболочки, для изучения которых требуется больше усилий.
Сравнение производительности Cassandra и HBase
И Cassandra, и HBase обеспечивают высокоскоростной доступ к большим наборам данных для аналитики больших данных. Эти базы данных демонстрируют различия по следующим аспектам производительности.
Задержка
Задержка — это промежуток времени между отправкой инструкции в систему баз данных и хранением или получением данных. Как правило, HBase демонстрирует меньшую задержку при увеличении количества операций чтения и записи данных. Обратное верно для Cassandra, в которой задержки увеличиваются при получении большего объема данных.
Пропускная способность сети
Пропускная способность измеряет количество операций чтения или записи, обрабатываемых базой данных каждую секунду. HBase поддерживает стабильную пропускную способность на уровне 100 000–200 000 операций, но она растет после достижения уровня 250 000 операций. Пропускная способность Cassandra увеличивается по мере увеличения объема считываемых или записываемых данных.
Производительность операций чтения
Для операции чтения в Cassandra требуется определить точное местоположение сохраненных данных в таблице разделов. Если для поиска используется вторичный ключ или таблица без разделов, Cassandra потребуется больше времени на поиск каждого узла кластера. Кроме того,возникают несоответствия в данных, когда несколько узлов содержат разные версии одних и тех же данных.
HBase обладает более высокой производительностью чтения, чем Cassandra, поскольку она записывает все данные на один сервер. В отличие от Cassandra, базе данных HBase не нужен поиск в таблице разделов для чтения данных. HDFS, которая используется в HBase для хранения данных, предоставляет фильтры Блума и кэши блоков, которые ускоряют извлечение данных.
Производительность операций записи
Cassandra выполняет операцию записи быстрее, чем HBase. При работе с Cassandra можно одновременно записывать данные в журнал и в кэш. HBase не поддерживает параллельную запись. Вместо этого клиентское приложение HBase через Zookeeper инициирует операцию записи, а первичный сервер HBase предоставляет адрес для сохранения данных. Эти дополнительные шаги в HBase замедляют процесс записи данных.
Другие ключевые различия между Cassandra и HBase
В приложениях для обработки и анализа данных можно использовать как Cassandra, так и HBase, но выбор между ними может зависеть даже от минимальных различий среды.
Безопасность
Cassandra позволяет регулировать доступ на уровне строк записей. Также она поддерживает шифрование SSL для защиты обмена данными между узлами. В отличие от Cassandra, HBase предлагает шифрование на уровне ячеек и дополнительные функции шифрования и аутентификации.
Разделение данных
Cassandra поддерживает упорядоченное разбиение на разделы и может сканировать последовательно упорядоченные записи, используя столбец в качестве ключа раздела. Это может быть полезно, но упорядоченное разбиение на разделы усложняет балансировку нагрузки, поскольку на одном узле происходит несколько операций записи. Таблица HBase не поддерживает упорядоченное разбиение на разделы.
Связь между узлами
В архитектуре Cassandra начальные узлы являются ключевыми точками для взаимодействия между кластерами. Эти узлы используют протокол gossip для перемещения данных между разными кластерами. HBase использует активный первичный узел HBase для координации взаимодействия между несколькими региональными серверами. В этой архитектуре перемещение данных согласовывается по протоколу Zookeeper.
Выбор между Cassandra и HBase
Базы данных Cassandra и HBase упрощают работу с большими данными в приложениях разных типов. Далее мы расскажем, какая из распределенных баз данных будет лучше работать в определенных условиях.
Доступность или согласованность
Cassandra подходит для тех сценариев, в которых требуется частая запись данных, но она не оптимизирована для частого обновления или удаления данных. Обычно организации используют Cassandra для создания систем обмена сообщениями, решений для интерактивной обработки данных и сохранения данных от датчиков в реальном времени. HBase лучше подходит для приложений, в которых требуется согласованность данных при частых изменениях. Например, для анализа больших объемов данных HBase используют банковские, медицинские и телекоммуникационные решения.
Настройка базы данных
Cassandra проще в настройке, потому что этот полностью автономный продукт содержит все необходимые компоненты базы данных. В отличие от Cassandra, HBase имеет зависимости от несколько компонентов Hadoop, например Zookeeper, основной сервер HDFS и HDFS DataNode. Настройка такой системы не вызывает сложностей, но поддержание правильных взаимозависимостей в реальных приложениях может оказаться непростой задачей. Если вы уже используете инфраструктуру Hadoop, вам будет проще перейти на HBase, чем на Cassandra.
Краткое изложение различий: Cassandra и HBase
|
Cassandra |
HBase |
|
|
Базовая структура |
Основывается на архитектуре «активный – активный». Все узлы обрабатывают запросы на чтение и запись. |
Использует архитектуру «первичный – вторичный». Первичная система HBase управляет несколькими региональными серверами. |
|
Ключевые компоненты |
Таблицы Memtable, журнал подтвержденных транзакций и таблицы SS. |
Основной сервер HBase, региональный сервер и Zookeeper. |
|
Модель данных |
Строки связанных семейств столбцов хранятся в пространстве ключей. |
Семейства столбцов размещаются горизонтально на основе последовательного ключа строк. |
|
Язык запросов |
Использует язык запросов Cassandra. |
Использует команды оболочки. |
|
Задержка |
Более высокая задержка при большем объеме операций получения данных. |
Меньшая задержка при большем объеме операций с данными. |
|
Пропускная способность сети |
Пропускная способность увеличивается по мере увеличения количества операций с данными. |
Пропускная способность увеличивается после достижения определенного количества операций. |
|
Производительность операций чтения |
Медленное чтение. Использует таблицу разделов для определения места чтения. Могут возникать несоответствия в данных. |
Более высокая производительность чтения и согласованность данных. |
|
Производительность операций записи |
Более высокая производительность записи. Одновременная запись в журнал и кэш. |
Дополнительные шаги. Проходит через Zookeeper и основной сервер HBase. |
|
Безопасность |
Доступ регулируется до уровня ролей. |
Доступ регулируется до уровня клеток. |
|
Разделение данных |
Поддерживает упорядоченное разбиение на разделы. |
Не поддерживает упорядоченное разбиение на разделы. |
|
Связь между узлами |
Используется протокол gossip. |
Используетcя протокол Zookeeper. |
Как AWS поможет удовлетворить ваши требования к Cassandra и HBase?
Amazon Web Services (AWS) предоставляет масштабируемые облачные сервисы баз данных, с помощью которых можно эффективно и недорого внедрять технологии обработки и анализа данных. Чтобы не выделять базовую инфраструктуру вручную, вы можете применить следующие сервисы AWS для поддержки баз данных Cassandra и HBase:
- Amazon Keyspaces (для Apache Cassandra) — это онлайн-сервис баз данных для выполнения высокопроизводительных рабочих нагрузок Cassandra. С помощью Amazon Keyspaces можно масштабировать приложения, сохраняя время отклика не более десятка миллисекунд.
- С помощью Amazon EMR можно развертывать кластеры HBase для крупномасштабных приложений по обработке данных. Запуск HBase на EMR повышает возможность восстановления данных за счет резервного копирования сохраненных данных в Amazon Simple Storage Service (Amazon S3).
Начните работу с аналитикой больших данных на AWS, создав аккаунт уже сегодня.