셀트리온제약은 케미컬의약품과 바이오의약품을 국내외 시장에 공급하는 대한민국 대표 제약기업입니다. 주요 생산기지인 청주공장은 국내 최초로 미국 및 유럽 규제기관으로부터 GMP 인증을 획득했으며, 이를 기반으로 글로벌 시장에 의약품을 안정적으로 공급하고 있습니다.
복잡한 공급망 관리와 의사결정을 위해 매월 열리는 셀트리온제약의 S&OP(Sales & Operations Planning) 회의에는 임원진과 리더급, 실무진 등 20여 명이 모인 이 자리에서는 제품별 매출 실적, 재고 현황, 적응증 허가 이슈, 위탁생산처 정보 등 다양하고 복잡한 질의가 쏟아집니다.
“이번 달 A제품의 재고 현황은 어떻게 되나요?”
“B제품의 새로운 적응증 허가 진행 상황은?”
“C제품 위탁생산처에서 발생한 이슈 현황을 알려주세요.”
이런 질문들이 나올 때마다 회의는 잠시 멈춥니다. 담당자가 자료를 찾거나, 해당 분야 전문가에게 답변을 의존해야 하기 때문입니다. 때로는 정확한 답변을 위해 회의 후 별도로 확인해서 전달하는 경우도 빈번했습니다. 이런 과정에서 의사결정은 지연되고, 특정 인원에 대한 의존도는 높아져만 갔습니다. 셀트리온제약의 참여자들은 이런 상황을 개선하고 싶었습니다. “회의 중 즉석에서 정확한 정보를 얻을 수 있다면 얼마나 좋을까?” 이런 니즈에서 시작된 것이 바로 제약업계 특화 멀티 에이전트 AI 시스템 구축 프로젝트입니다.
제약업계는 다른 산업과 달리 높은 규제 준수 요구사항과 안전성 기준을 가지고 있습니다. 또한 ERP, SCMS(Supply Chain Management System, 셀트리온제약에서 자체 개발한 공급망 관리 시스템) 같은 내부 시스템부터 의약품안전나라 같은 외부 공공 데이터까지 매우 다양한 데이터 소스를 실시간으로 참조해야 합니다. 이처럼 복잡한 환경 속에서 생성형 AI가 어떤 혁신을 만들어낼 수 있는지 고민하고 AWS와 셀트리온제약이 함께 구축한 실제 사례를 통해 소개합니다.
배경 및 도전 과제
먼저 데이터의 복잡성 문제입니다. 하나의 질문에 답하기 위해서는 여러 시스템을 동시에 확인해야 합니다. 재고 현황을 확인하려면 ERP 시스템의 실시간 데이터를 조회해야 하고, 제품 허가 상태를 파악하려면 의약품안전나라와 같은 외부 공공 사이트를 참고해야 합니다. 또한 더 깊이 있는 분석 자료가 필요할 경우에는 각 부서에서 작성한 Excel·PPT 파일이나 SCMS 데이터를 검색해야 합니다. 이런 정보들이 서로 다른 형태와 위치에 흩어져 있어 통합적인 답변을 만들기가 매우 어려웠습니다.
두 번째는 시간의 압박입니다. 월간 S&OP 회의는 임원진이 참석하는 중요한 의사결정의 장입니다. “잠깐만요, 확인해보겠습니다”라는 말이 나오는 순간 회의의 흐름이 끊어지고, 때로는 정확한 답변을 위해 회의 후 별도 확인이 필요한 상황이 발생합니다. 이는 신속한 의사결정을 방해하는 주요 요인이었습니다.
세 번째는 지식의 편중 현상입니다. 각 제품과 영역별로 전문 담당자가 있지만, 그 사람이 부재하거나 다른 업무로 바쁠 때는 정확한 답변을 얻기 어려웠습니다. 또한 신입 직원이나 타 부서 직원은 어디서 어떤 정보를 찾아야 하는지조차 알기 어려운 상황이었습니다.
요약하면, 제약업계 S&OP 회의는 다음과 같은 특징을 갖고 있습니다.
복잡한 데이터 소스: 내부 시스템(ERP, SCMS), 사내 문서(Excel, PDF, PPT), 외부 웹사이트(의약품안전나라 등)
실시간 의사결정: 임원진의 즉석 질의에 대한 정확하고 신속한 답변 필요
전문성 의존: 특정 담당자의 지식에 의존하는 업무 프로세스
주요 질의 유형
실제 회의에서 나오는 질문들을 분석해보면 크게 다섯 가지 패턴으로 분류할 수 있었습니다. 이런 질문들은 각각 다른 데이터 소스와 전문 지식을 요구하기 때문에, 하나의 시스템으로 모든 답변을 처리하기 어려운 구조적 복잡성을 가지고 있었습니다.
적응증 및 허가 이슈
재고 현황 및 발주 상태
위탁생산처 정보
매출 실적 및 예측
제품별 공헌이익
차년도, 차차년도 사업계획
접근 방식 및 해결 전략
이런 복잡한 도전 과제들을 해결하기 위해 체계적인 접근 방식을 수립했습니다.
가장 먼저 고민한 것은 “하나의 AI 모델 호출로 모든 것을 해결할 수 있을까?”라는 질문이었습니다. 분석 결과, 단일 AI 모델로는 ERP, SCMS 데이터 조회, 외부 웹사이트 크롤링, 문서 검색, 데이터 분석 등 서로 다른 성격의 작업을 효과적으로 처리하기 어렵다는 결론에 도달했습니다. 대신 실제 회의에서 각 분야 전문가들이 협력하여 답변을 만들어내는 것처럼, 각각의 전문 영역을 담당하는 여러 에이전트가 협업하는 멀티 에이전트 아키텍처를 채택했습니다.
하지만 모든 질문에 대해 모든 에이전트를 동원하는 것은 비효율적입니다. 따라서 사용자의 질의 의도를 먼저 파악하여 필요한 에이전트만 활성화하는 의도 기반 라우팅 전략을 수립했습니다. 이를 통해 불필요한 처리 과정을 줄이고 응답 속도를 크게 개선할 수 있었습니다.
제약업계에서 시장에 제품을 적시에 공급하기 위해서는 S&OP 회의에서 논의되는 정보의 정확성은 필수입니다. 따라서 단순히 LLM의 사전 학습 지식에만 의존하지 않고, 실시간으로 최신 정보를 검색하여 답변에 반영하는 RAG(Retrieval-Augmented Generation) 방식을 핵심 전략으로 삼았습니다. 이를 통해 항상 최신이고 정확한 정보를 제공할 수 있게 되었습니다.
마지막으로 제약업계 특성상 모든 정보는 검증 가능해야 합니다. 따라서 AI가 제공하는 모든 답변에는 반드시 출처 정보를 포함하여, 사용자가 원본 데이터를 직접 확인하고 검증할 수 있도록 출처 투명성을 확보했습니다.
Amazon Bedrock – AI Foundation Model (Anthropic Claude Sonnet 4.0 / Claude Sonnet 3.7)
Amazon Bedrock – Knowledge Bases
3. 개발 언어 및 프레임워크
python 3.12.9
streamlit 1.45
langchain, langgraph
4. 사용기술
구현 Tools – Text-to-SQL, RAG 검색, Web Crawling (bs4)
사용 Tools – tavily
비동기 구현 – asyncio
5. 기타
Data Pipeline 개발 : PPT to Text & Image 자동화
아키텍처 다이어그램
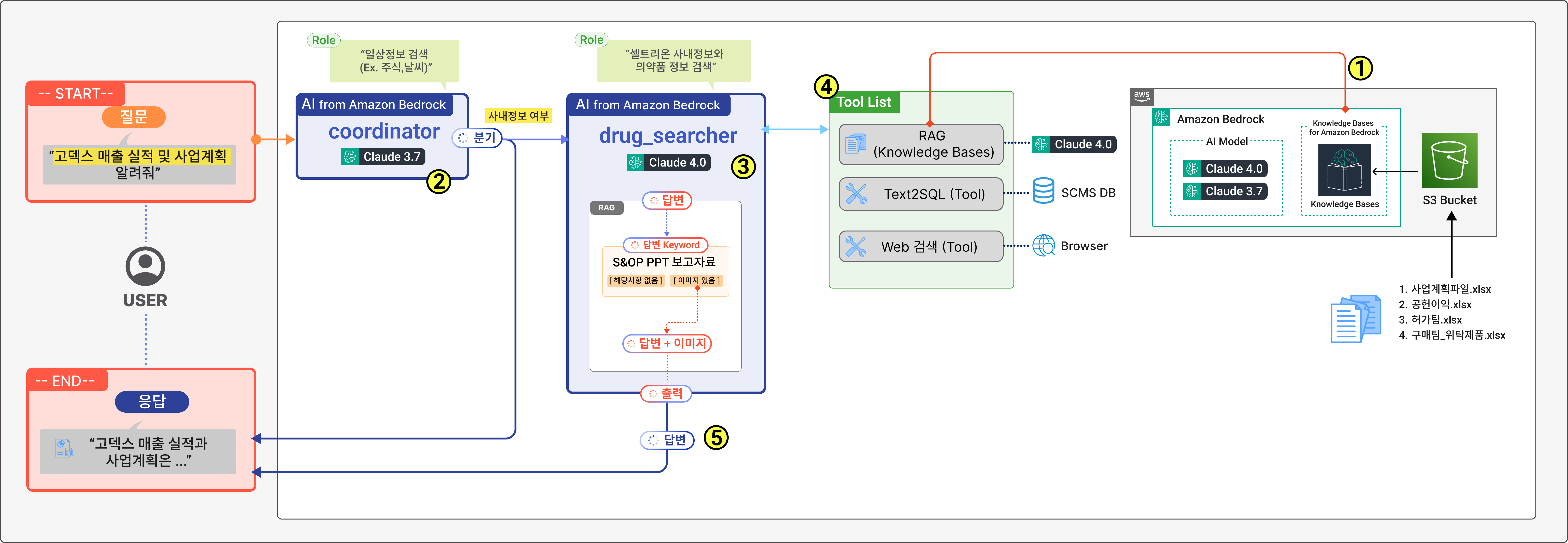
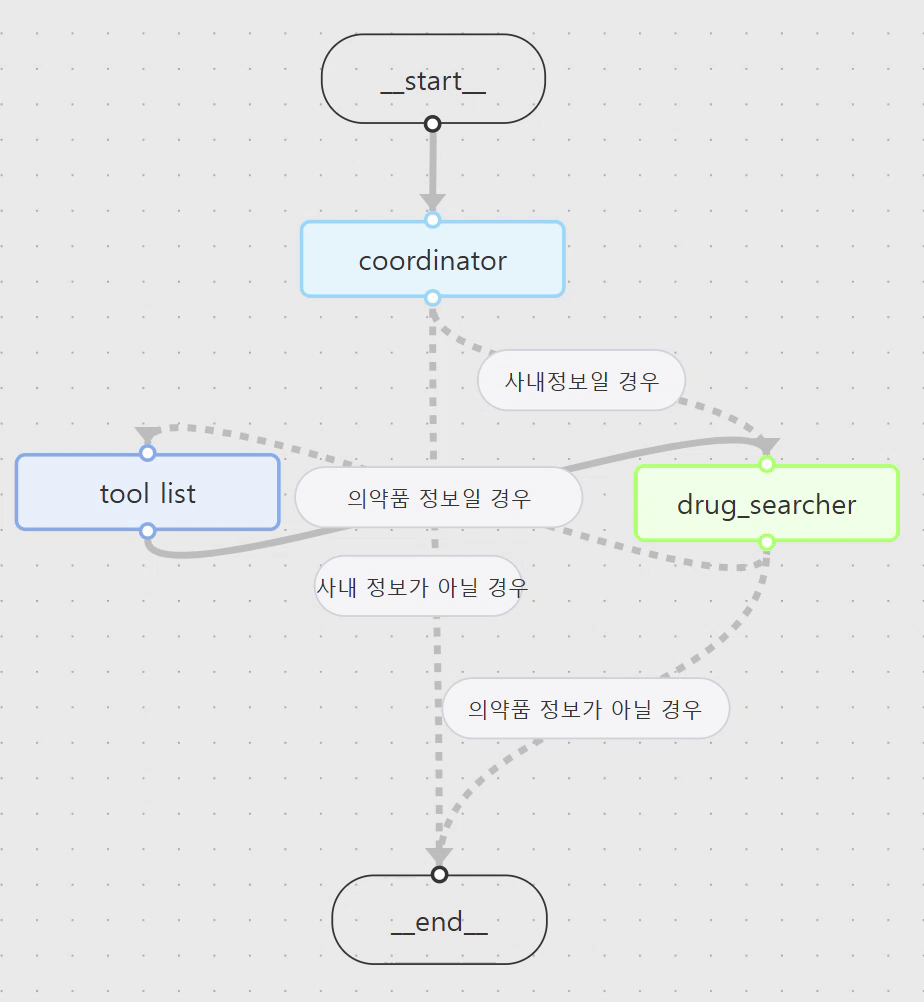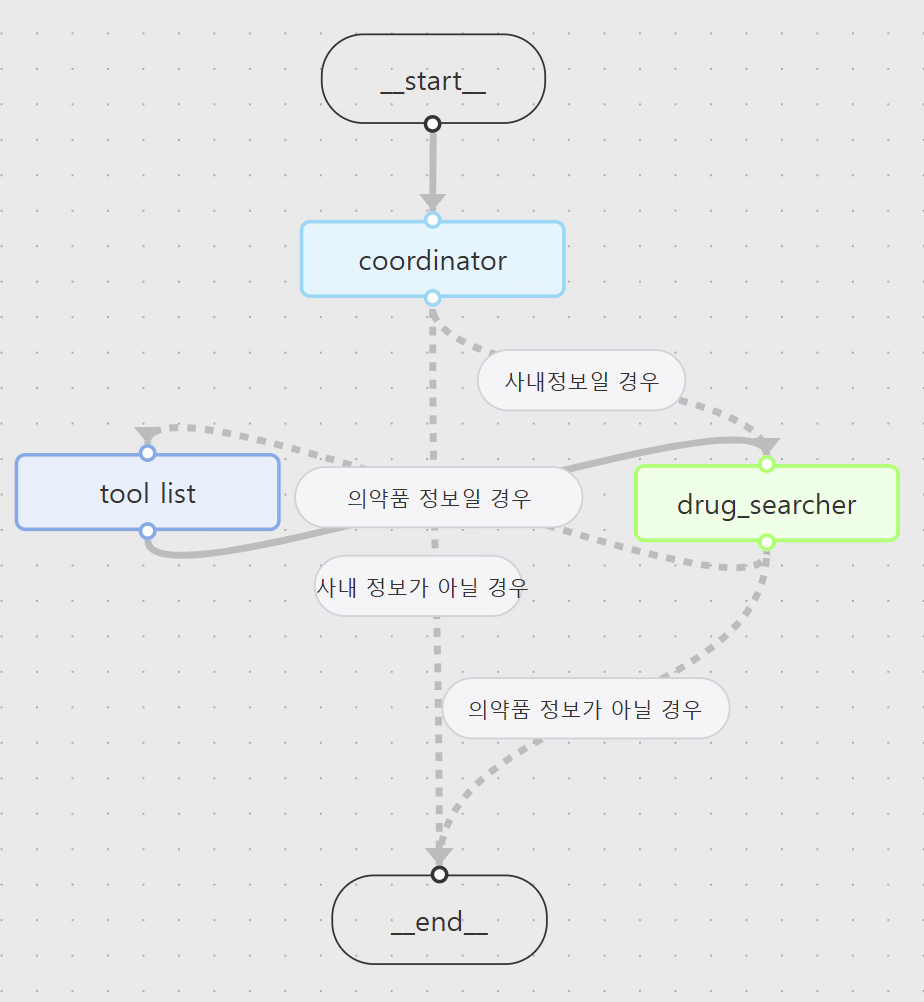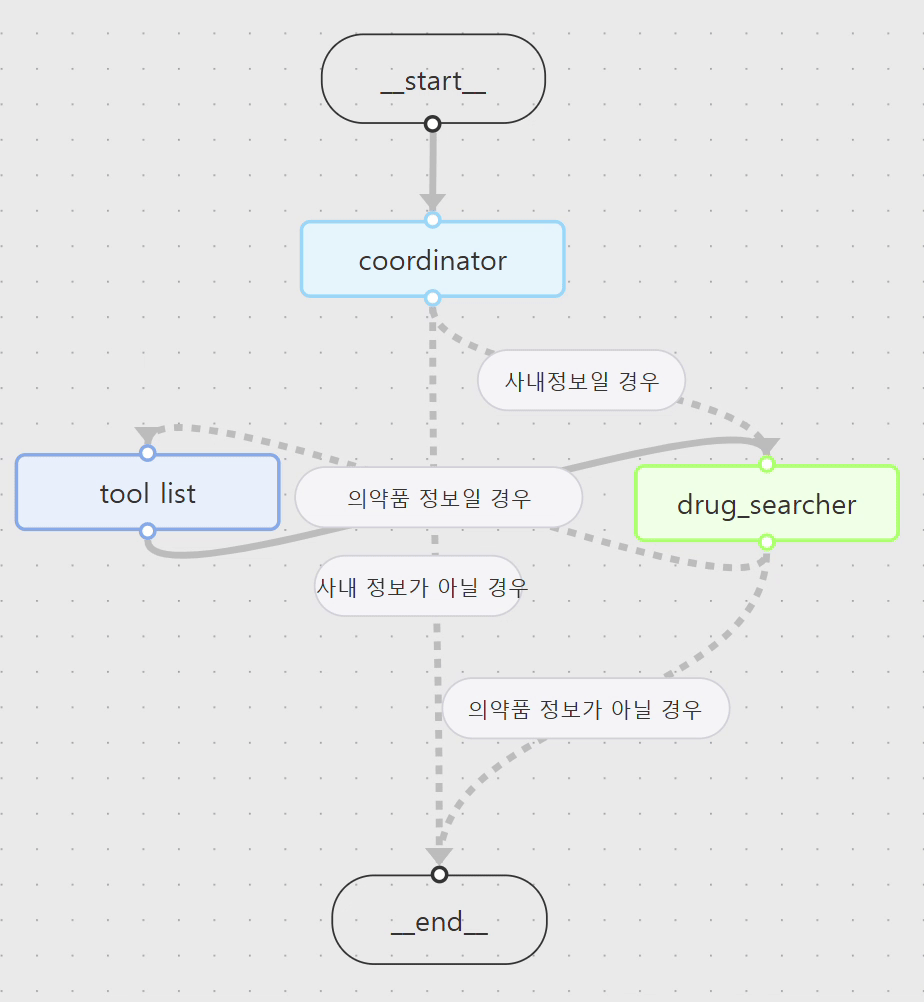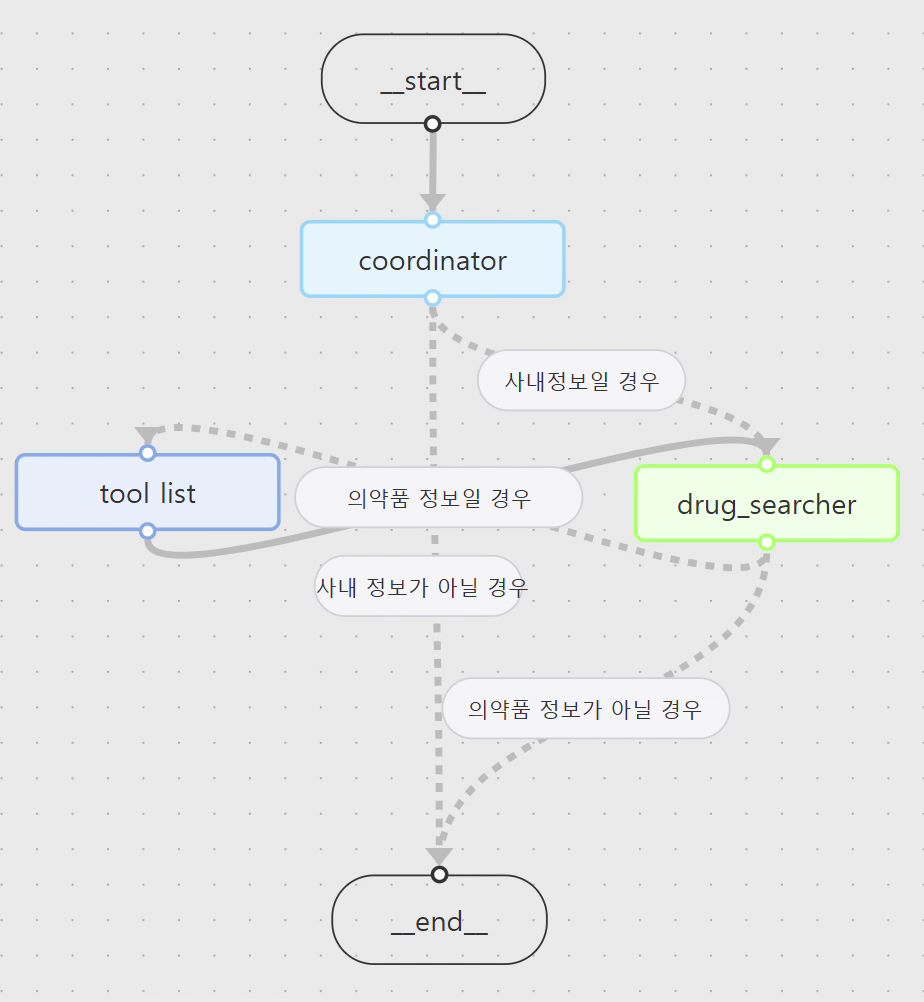
구축한 솔루션은 2개의 에이전트와 3개의 도구로 구성되어 있으며, 참조하는 데이터 소스로 Amazon Bedrock Knowledge Bases 기반의 RAG 및 SCMS DB, 웹 검색을 포함합니다. 다음과 같은 흐름으로 동작하도록 구성하였습니다.
1. S3 Bucket에 내부 자료에 해당하는 ‘사업계획’ 및 ‘공헌이익’ 등의 현업에서 유통되는 파일(Excel) 을 업로드하고, 업로드된 파일은 Knowledge Bases이 제공하는 기능을 통해 의미적 청킹 및 임베딩을 거쳐 벡터 값으로 변환되어 벡터 스토어에 저장됩니다.
2. 사용자 질문이 들어오면 coordinator 에이전트는 일반적인 질문에 대한 답변을 하거나, 사내정보 검색이 필요할때는 drug_searcher 에이전트로 사용자 요청을 전달합니다.
3. drug_searcher 에이전트는 제공된 Tool List를 사용하여 사내정보 또는 의약품 전문 사이트 검색을 수행합니다.
4. drug_searcher 에이전트가 사용하는 도구는 다음과 같습니다.
RAG 검색 : 현업 유통 파일 내 사내정보 검색을 위한 도구
Text2SQL : SCMS Database를 통한 사내정보 검색을 위한 도구
Web search : 의약품 전문사이트 검색을 위한 도구
5. drug_searcher 에이전트는 텍스트 응답 뿐만 아니라 이와 관련된 PPT를 검색하여 “텍스트 답변 + PPT 이미지” 를 사용자에게 최종 답변으로 제공합니다.
구현 과정
셀트리온제약의 환경은 수많은 비정형 및 정형 데이터로 구성되어 있습니다. 이러한 데이터를 효과적으로 활용하고 사용자의 복잡한 질문에 정확하고 빠르게 답변하기 위해, RAG와 멀티 에이전트 아키텍처를 결합한 AI 서비스를 구축했습니다.
1단계: 데이터 파이프라인 구축 (Data 적재 및 변환)
“AI 서비스의 주요한 기반은 데이터다” 라는 명확한 목표 아래, 시스템은 사내에 산재한 다양한 형태의 문서를 처리해야 했습니다.
먼저 Excel, PDF, PPT와 같은 비정형 및 반정형 문서들을 수집하며 단순한 텍스트 추출을 넘어, 문서의 본래 의미와 맥락을 유지하기 위해 의미적 청킹(Semantic Chunking) 을 사용했습니다.
구조화된 데이터의 경우, 검색 성능을 최적화하기 위해 JSON 형태로 변환하여 저장했습니다. 이 방식은 AI 서비스가 처리할 데이터의 처리 속도를 향상시키고, 복잡한 쿼리에도 유연하게 대응할 수 있는 기반이 되었습니다.
또한, 시스템의 정보 범위를 확장하기 위해 ‘의약품안전나라’와 같은 외부 공공 API를 연동했습니다. 이를 통해 내부 데이터 뿐 만 아니라 신뢰할 수 있는 외부 정보까지 실시간으로 사용자에게 제공할 수 있게 되었습니다.
데이터 수집만큼 중요한 것은 데이터의 품질과 응답의 신뢰성을 보장하는 것입니다. 이를 위해 시스템에 적재되는 데이터의 정합성을 확보하는 절차를 마련했습니다. 데이터 사전 검증 단계에서 agent에 S&OP 도메인 지식을 적용하여 부정확하거나 유효하지 않은 정보가 시스템에 유입되는 것을 사전에 차단함으로써 데이터의 신뢰도를 확보하였습니다. 예를 들어, 재고 회전율이나 재고 과다 품목을 조회할 때 의약품 원료 성분은 해당 분석 대상이 아니므로, 완제품과 반제품만 답변에 포함되도록 필터링 로직을 적용했습니다.
2단계: RAG 시스템 구축과 검색 정확도 향상
데이터를 벡터로 변환하는 Amazon Bedrock Embeddings를 활용했습니다. 이는 대규모 텍스트 데이터를 효율적으로 처리하고, 높은 품질의 벡터 표현을 생성하여 검색 성능을 극대화했습니다.
의미적 청킹 전략을 통해 문서를 고정된 크기가 아닌, 의미 단위로 분할함으로써 사용자의 질문 의도와 데이터 본연의 의미를 가장 연계성이 높은 정보 조각을 정확하게 찾아낼 수 있었습니다.
또한, 원본 문서를 별도 에이전트로 사전 분석하여 S&OP 도메인 지식이 반영된 구조화된 분석 결과를 생성하고, 이를 원본 문서 경로와 함께 RAG 데이터베이스에 저장했습니다. 사용자 질의 시에는 RAG 검색 결과를 시맨틱 비교 로직으로 필터링하여 관련성 높은 문서만 반환함으로써 검색된 정보의 신뢰성을 확보했습니다. 이는 사용자 경험 최적화에서 출처 표시 기능의 기반이 되었습니다.
3단계: 멀티 에이전트 아키텍처
LangGraph를 통해 멀티 에이전트 패턴을 구현했으며, 시스템의 상태를 명시적으로 관리하고 대화의 전체 맥락과 중간 처리 결과를 안정적으로 저장할 수 있게 되었습니다.
가장 큰 장점은 에이전트 간의 유기적인 협업이 가능해졌다는 점입니다. 예를 들어, 사용자의 질문을 분석하여 일반적인 정보 검색을 담당하는 에이전트(coordinator)와 의약품 정보와 같은 특정 도메인을 담당하는 전문 에이전트(drug_searcher)로 작업을 분리했습니다. 이러한 단계별 처리는 각 에이전트가 성능을 최대한 발휘하게 하여 복잡한 질문에도 깊이 있는 답변을 생성할 수 있게 했습니다.
4단계: 신뢰와 속도를 더하는 사용자 경험(UX) 최적화
저희는 시스템의 신뢰성과 응답 속도를 높이는 데 집중했습니다.
사용자의 이해를 돕기 위해 시각적 응답을 강화했습니다. 특히 PPT 문서에서 정보를 가져올 경우, 관련 텍스트뿐만 아니라 해당 PPT의 원본 이미지를 함께 제공하여 사용자가 맥락을 직관적으로 파악할 수 있도록 했습니다.
모든 답변에 명확한 출처(참조 정보)를 표시했습니다. 이는 시스템이 생성한 답변의 신뢰성을 확보하고, 사용자가 필요시 원본 문서를 직접 확인할 수 있게 하는 중요한 기능입니다.
응답 시간 단축을 위해 사용자의 질문 의도를 먼저 파악하여, 불필요한 RAG 검색이나 복잡한 에이전트 호출 없이 즉각적인 답변이 가능한 경우는 처리 속도를 획기적으로 개선했습니다.
주요 코드 설명
1. Node 공통 기능
LangGraph State 에 history 속성 생성하여 사용자와 대화했던 이력 저장, 새로운 질문이 들어오면 Agent Instruction 에 history를 더해 에이전트가 참조할 수 있게 개발하였습니다.
Text-to-SQL 구현 : asyncpg 라이브러리 활용하여 Connection 구현 및 SELECT를 제외한 SQL 변환 로직을 개발하였습니다. 구현 과정은 아래와 같습니다.
# SCMS System's Database Description
<scms_system_information>
<database_system_information>
It is postgreSQL, version "PostgreSQL 14.19 (Ubuntu 14.19-0ubuntu0.22.04.1) on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 11.4.0-1ubuntu1~22.04.2) 11.4.0, 64-bit".
</database_system_information>
<system_description>
The SCMS is acronym that is 'S'upply 'C'hain 'M'anagement 'S'ystem. It is for S&OP committee...
</system_description>
<words_description>
DB에서 사용되는 업무와 관련된 단어 설명
</words_description>
<databse_authorization>
AI 에이전트가 접속할 DB 계정의 권한 설명
</databse_authorization>
<database_table_name>
DB Table 이름
</database_table_name>
<database_table_description>
DB Table 설명
</database_table_description>
<database_table>
<columns>
<columns1> Column1 설명.. </columns1>
<columns2> Column2 설명.. </columns2>
...
</columns>
</database_table>
</scms_system_information>
Agent 가 사용할 Tool 제공
async def get_result_scms_db(query: Annotated[str, ""]) -> str:
"""
Use this tool to find out internal information from database for SCMS.
Args:
query : The SQL for SCMS DB.
Returns:
The information which is managed internally. (e.g. 제품코드, 제품명, 사업단가, 배치사이즈, 판매단위(팩) etc.)
"""
def validate_sql(sql: str) -> bool:
"""
The function prevent to execute invalid SQL except 'SELECT'.
"""
if not sql.strip().upper().startswith('SELECT'):
raise Exception("SELECT 문만 실행 가능합니다.")
dangerous = ['DROP', 'DELETE', 'UPDATE', 'INSERT', 'CREATE', 'ALTER', 'TRUNCATE']
for keyword in dangerous:
if keyword in sql.upper():
raise Exception(f"보안상 {keyword} 문은 실행할 수 없습니다.")
return True
if not query:
return f"It is not existed SQL."
try:
conn = await asyncpg.connect(
host=os.getenv('DB_HOST'),
port=os.getenv('DB_PORT'),
database=os.getenv('DB_NAME'),
user=os.getenv('DB_USER'),
password=os.getenv('DB_PASSWORD')
)
validate_sql(query)
rows = await conn.fetch(query)
results = "\n".join([str(row) for row in rows])
await conn.close()
return results
except BaseException as e:
return f"Error fetching data from SCMS DB: {str(e)}"
Web Crawling 구현 : 검색 정확도를 높이기 위해 bs4 라이브러리 활용하여 의약품 관련 특정사이트 HTML 태그 기반으로 정보 검색 할 수 있게 개발하였습니다. 구현 과정은 아래와 같습니다.
async def get_result_knowledge_base(query: Annotated[str, "Must be found information from Bedrock's Knowledge Base."]) -> str:
"""
Use this tool to find out internal information from AWS Bedrock's Knowledge Base.
Args:
query : Text from user request
Returns:
The internal information( e.g., 사업계획 매출액, 공헌이익 etc.)
"""
try:
bedrock_agent = await get_bedrock_agent_client_async()
retrieve_response = await bedrock_agent.retrieve(
knowledgeBaseId=os.getenv('KNOWLEDGE_BASE_ID'),
retrievalQuery={'text': query},
retrievalConfiguration={'vectorSearchConfiguration': {'numberOfResults': 5}}
)
result = [result['content']['text'] for result in retrieve_response.get('retrievalResults', []) if
'content' in result and 'text' in result['content']]
if not result:
return "AWS Knowledge Base에서 관련 정보를 찾을 수 없습니다."
except Exception as e:
raise f"Bedrock-KB 호출 에러 발생 : {e}"
finally:
import aioboto3
if isinstance(bedrock_agent, aioboto3.Session):
await bedrock_agent.close()
return result
Tavily : 에이전트 프롬프트에 의약품 관련 사이트 리스트 & 우선순위 제안하여 검색할 수 있게 구성하였습니다
Query 실행할 시스템의 DB Schema, 예시 쿼리 프롬프트로 에이전트에게 제공
(정보 제공을 위한 View Table를 임시로 생성해서 사용하였으며, 추후 전체 ERD 정보를 제공할 예정)
...
# Tools
tavily_tool : You can look up specific website.
[CRITICAL] It should be used when you can't find out answer using korean_drug_search.
[CRITICAL] You can use this tool only website below :
1) Access URL 1 : (약학정보원) https://www.health.kr/
2) Access URL 2 : (특허청) https://www.kipris.or.kr/
Examples
[Information X] About drug information on official two websites.
...
4. Return with Images : 에이전트가 생성한 최종 답변과 관련된 S&OP 보고자료(PPT) 페이지가 있을 경우, 해당 페이지를 Image 형태로 함께 제공하도록 구현했습니다. 구현 과정은 아래와 같습니다.
PPT to Text&Image 데이터 파이프라인 개발 : AI를 활용한 별도 서비스로 개발
PPT Images를 S3 특정 경로에 업로드 : 해당 페이지에 대한 설명을 S3 경로와 1:1로 매칭 시켜놓음
에이전트 최종 답변으로 해당 페이지의 설명 검색, S3 경로를 리턴 받음
LangGraph State의 s3_path 속성 업데이트, 최종 답변과 함께 리턴
이미지 다운로드 후 사용자에게 최종 답변과 함께 리턴
# 1. Amazon Bedrock-Knowledge Base 에서 AI 답변과 관련된 이미지가 저장된 S3경로 Return 함수
async def get_result_business_report(query: Annotated[str, "Must be final AI's response."]) -> str:
report_agent = await get_bedrock_agent_client_async()
retrieve_response = await report_agent.retrieve(
knowledgeBaseId="Amazon Bedrock-Knowledge Base's ID"
retrievalQuery={'text': query},
retrievalConfiguration={'vectorSearchConfiguration': {'numberOfResults': 5}}
)
result = [result['content']['text'] for result in retrieve_response.get('retrievalResults', []) if
'content' in result and 'text' in result['content']]
if not result:
return None
s3_paths = []
for text in result:
try:
if '"s3_path"' in text:
s3_path_match = re.search(r'"s3_path":\s*"([^"]+)"', text)
if s3_path_match:
s3_paths.append(s3_path_match.group(1))
except Exception as e:
print(f"s3_path 추출 중 오류: {e}")
continue
await report_agent.close()
if s3_paths:
unique_s3_paths = list(set(s3_paths))
return "\n".join(unique_s3_paths)
else:
return None
# 2. drug_searcher Node에서 S3경로 리턴받는 부분
async def drug_searcher_node(state: State) -> Command[Literal["__end__"]]:
...
s3_paths = ""
try:
logger.info(f"{Colors.BLUE}===== Business Report 검색 시작 ====={Colors.END}")
business_report_result = await get_result_business_report(query=user_query)
# ③ 에이전트 최종 답변으로 해당 페이지의 설명 검색, S3경로를 리턴 받음
if business_report_result:
logger.info(f"{Colors.BLUE}Business Report에서 관련 문서를 찾았습니다.{Colors.END}")
s3_paths = business_report_result.split("\n")
else:
logger.info(f"{Colors.BLUE}Business Report에서 관련 문서를 찾지 못했습니다.{Colors.END}")
final_response = result["content"][-1]["text"]
except Exception as e:
logger.error(f"Business Report 검색 중 오류 발생: {e}")
final_response = result["content"][-1]["text"]
# ④ LangGraph State의 s3_path 속성 업데이트, 최종 답변과 함께 리턴
return Command(
update={
**contents,
"s3_paths": s3_paths,
},
goto="__end__",
)
5. 멀티 에이전트 패턴 구현: LangGraph의 nodes 및 edges를 활용하여 에이전트 간 연결 관계를 선언적으로 정의하고, 각 노드의 실제 동작을 함수로 구현합니다.
spec.yaml: 에이전트들의 역할과 연결 관계를 선언적으로 정의하는 설계도입니다. 노드는 각 에이전트의 기능을, 엣지는 작업 흐름을 나타냅니다.
name: CustomAgent
nodes:
- name: Coordinator
- name: drug_searcher
- name: tool list
edges:
- from: __start__
to: Coordinator
- from: tool list
to: drug_searcher
- from: Coordinator
condition: 사내정보 여부
paths: [drug_searcher, __end__]
- from: drug_searcher
condition: 의약품 정보
paths: [__end__, tool list]
implementation.py: 각 노드의 실제 비즈니스 로직을 구현합니다. 상태를 공유하며 순차적으로 작업을 수행하는 에이전트들의 동작을 정의합니다.
from typing_extensions import TypedDict
from stub import CustomAgent
class SomeState(TypedDict):
foo: str
def Coordinator(state: SomeState) -> dict:
print("In node: Coordinator")
return {
# Add your state update logic here
}
def drug_searcher(state: SomeState) -> dict:
print("In node: drug_searcher")
return {
# Add your state update logic here
}
def tool_list(state: SomeState) -> dict:
print("In node: tool list")
return {
# Add your state update logic here
}
def 사내정보_여부(state: SomeState) -> str:
print("In condition: 사내정보 여부")
raise NotImplementedError("Implement me.")
def 의약품_정보(state: SomeState) -> str:
print("In condition: 의약품 정보")
raise NotImplementedError("Implement me.")
agent = CustomAgent(
state_schema=SomeState,
impl=[
("Coordinator", Coordinator),
("drug_searcher", drug_searcher),
("tool_list", tool_list),
("사내정보 여부", 사내정보_여부),
("의약품 정보", 의약품_정보),
],
)
compiled_agent = agent.compile()
프로젝트 성과 및 시사점
구매수출입관리팀과 SCM팀 9명을 대상으로 진행한 2주간의 파일럿 운영에서 멀티 에이전트 AI 시스템은 평균 1분 이내의 응답 속도와 약 90%의 정확도를 기록했습니다. 이러한 성능은 현업의 데이터를 활용한 시험 환경에서 즉각적인 영향을 끼쳤습니다.
가장 큰 변화는 S&OP 회의 운영 방식의 혁신입니다. 이전에는 임원진의 갑작스러운 질의에 회의가 중단되거나, 정확한 답변을 위해 회의 후 별도 확인이 필요했던 상황이 완전히 개선되었습니다. 이제는 ERP, SCMS 등 내부 시스템부터 의약품안전나라 같은 외부 공공 데이터까지 실시간으로 통합 조회하여 즉시 데이터 기반 답변을 제공할 수 있게 되었습니다.
특히 특정 담당자에게 집중되던 정보 의존도를 낮추고 질의에 실시간으로 대응 가능한 환경을 구축함으로써, 의사결정 속도가 크게 향상되었습니다. 신입 직원이나 타 부서 직원도 복잡한 제약업계 정보에 쉽게 접근할 수 있게 되어 조직 전체의 정보 접근성이 개선되었습니다.
기술적 관점에서는 멀티 에이전트 아키텍처와 RAG 기반 실시간 검색, AWS 관리형 AI 서비스의 결합이 복잡한 제조업 환경에서도 실용적인 가치를 창출할 수 있음을 입증했습니다. 특히 의미적 청킹을 통한 데이터 처리와 출처 투명성 확보, 그리고 PPT 이미지까지 포함한 시각적 응답 제공은 사용자 경험을 크게 향상시켰습니다.
이 프로젝트의 가장 중요한 시사점은 생성형 AI가 단순한 기술 도입을 넘어서 실제 비즈니스 현장의 복잡한 요구사항을 해결하는 실용적인 솔루션이 될 수 있다는 것입니다. 높은 규제 준수 요구사항과 안전성 기준을 가진 제약업계에서도 적절한 아키텍처 설계와 데이터 검증 절차를 통해 신뢰할 수 있는 AI 시스템 구축이 가능함을 보여주었습니다.
셀트리온제약과의 이번 협업 사례는 다른 제약업계 및 제조업 고객들에게도 적용 가능한 검증된 참조 아키텍처로 활용될 수 있을 것입니다. 특히 복잡한 데이터 환경과 실시간 의사결정이 중요한 산업 분야에서 AWS의 관리형 AI 서비스를 활용한 멀티 에이전트 시스템의 효과적인 구현 방안을 제시했다는 점에서 큰 의미를 갖습니다.
[데모영상] 셀트리온제약 의약품 공급망 관리를 위한 멀티 에이전트 시스템 데모
본 포스팅은 셀트리온제약과 AWS가 협업하여 생성형 AI를 구축한 경험과 솔루션을 공유하기 위한 목적으로 작성되었습니다. 도표, 예시 코드, 알고리즘, 고유명사, 지표, 데이터는 실제 시스템 코드, 데이터와 무관하고, 외부에 공개가 가능한 수준으로 비식별 처리를 하였습니다. 따라서 본 포스팅은 셀트리온제약 내 AI 시스템의 기술 수준, 실제 데이터를 담고 있지 않고, 셀트리온제약의 의약품의 안전, 품질 및 유통관리, 영업활동에 관하여 홍보하거나 판매 제안, 권유, 조언 등을 하지도 않습니다. 아울러 본 포스팅은 AWS의 제품이나 서비스에 관해 어떠한 보증을 하거나 책임을 부담 하지 않음을 안내 드립니다.