AWS 기술 블로그
Category: Amazon Simple Storage Service (S3)

알리는사람들의 Amazon Data Firehose로 Amazon DynamoDB를 Amazon S3 tables로 실시간 복제하기
개요 알리는사람들은 다양한 메시징 채널을 통합하여 기업의 커뮤니케이션을 자동화하고, 고객에게 정확한 메시지를 빠르게 전달할 수 있도록 돕는 테크 스타트업입니다. 인증, 마케팅, 알림 등 다양한 메시지 유형을 유연하게 다룰 수 있는 인프라를 바탕으로, 수많은 기업이 일상적인 고객 커뮤니케이션을 효율적으로 운영하고 있습니다. 센드온(Sendon)은 알리는사람들이 개발한 클라우드 네이티브 메시징 플랫폼으로, 대용량 메시지 전송에 최적화된 서버리스 아키텍처를 기반으로 운영됩니다. […]

Amazon S3 Tables이 압축을 사용하여 쿼리 성능을 최대 3배까지 개선하는 방법
이 글은 AWS Storage Blog에 게시된 How Amazon S3 Tables use compaction to improve query performance by up to 3 times by Aliaa Abbas, Anupriti Warade, and Jacob Tardieu 를 한국어 번역 및 편집하였습니다. 오늘날 페타바이트 규모의 데이터를 관리하는 기업들은 비용 효율성을 유지하면서 적시에 인사이트를 확보하기 위해 스토리지와 데이터 처리 과정을 최적화 해야 합니다. 고객들은 […]

AWS Lambda와 PyIceberg 로 Amazon S3 Tables 시작하기
2024년 AWS re:Invent에서 Amazon S3 Tables가 새롭게 공개되었습니다. S3 Tables는 Amazon S3에 Apache Iceberg 형식의 테이블을 관리할 수 있는 완전 관리형 기능으로, 데이터 레이크 테이블 관리의 복잡성을 크게 줄여줍니다. Iceberg를 통해 S3에 저장된 데이터를 마치 데이터베이스 테이블처럼 다룰 수 있으며, Athena, EMR(Spark), Redshift, Glue 등 다양한 분석 엔진과 통합됩니다. 특히 S3 Tables를 활용하면 자체 관리하는 […]

디프로모션의 DynamoDB, zero-ETL, ElastiCache Serverless 도입기
서비스의 간단한 소개 및 특징 브랜드의 중요한 순간을 함께 만들어가는 파트너. 디프로모션은 누구나 쉽고 빠르게 디지털 캠페인과 프로모션을 만들 수 있도록 돕는 서비스입니다. 직관적인 온라인 디자인 에디터를 통해 룰렛, 스크래치, 틀린그림찾기, 퀴즈, 래플 등 다양한 유형의 이벤트를 손쉽게 생성할 수 있으며, 당첨자 선정과 리워드 지급까지 하나의 플랫폼에서 관리하여 브랜드가 목표로 하는 마케팅 결과를 효과적으로 달성할 […]
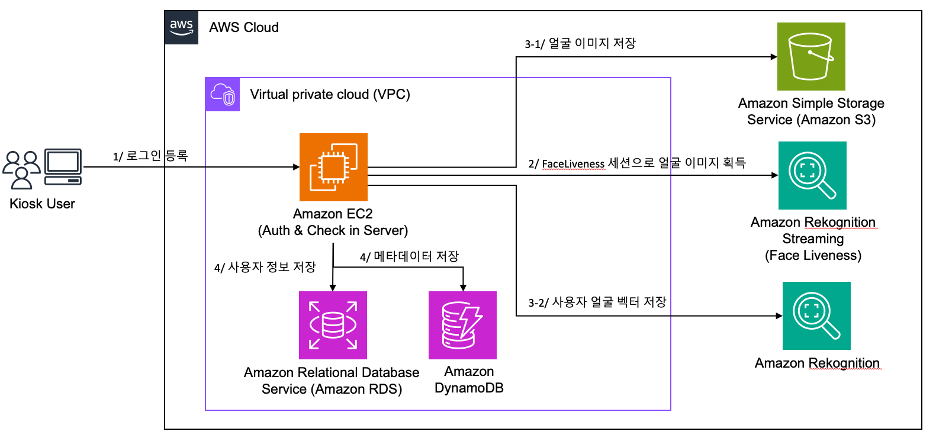
위커스의 Amazon Rekognition Face-Liveness를 활용한 얼굴 생체 인식 기반 무인 키오스크 구현
위커스(We Connect Space) 회사 소개 위커스(We Connect Space)는 공간 운영의 핵심 데이터를 연결하여, 회원 관리, 결제·수납, 예약, 좌석 관리 등 필수 기능을 하나의 AIoT SaaS 솔루션으로 제공합니다. 당사의 SaaS 기반 공간 운영 솔루션 ‘고스카 (GOSCA)’는 15개 이상의 업종에서 디지털 전환을 지원하고 있습니다. 스터디카페(무인·관리형), 키즈카페, 무인 탁구장 등 소상공인 공간 운영을 시작으로, 고등학교, 창업센터, 복지센터 등 […]

AWS 데이터 분석 서비스 기반 게임 레벨링 환경 구성 사례
개요 기존의 문제 상황 소규모 인디게임 개발사는 작은 규모와 한정된 자원에도 불구하고 창의성과 혁신성을 발휘하며 새로운 게임 경험을 선사합니다. 하지만 이러한 장점에도 불구하고, 게임 개발 과정에서 적지 않은 과제에 직면하곤 합니다. 특히 게임 출시 전 완성도를 높이기 위한 테스팅과 난이도 조정 작업은 매우 중요하지만, 인력이 부족한 인디 게임 스튜디오에서는 이러한 작업을 충분히 수행하기 어려운 상황입니다. […]

Amazon Bedrock을 활용한 Aurora MySQL 운영하기-1부
불과 몇년만에 생성형 AI 서비스가 모든 사람의 화두가 되고 모든 비즈니의 중심과 투자는 생성형AI 서비스로 몰리고 있습니다. ChatGPT를 시작으로 많은 생성형 AI모델들이 쏟아져 나오고, 새로 나오는 모델들은 기존보다 훨씬 뛰어난 성능과 기능을 자랑합니다. 이러한 생성형AI서비스 모델을 LLM(Large Language Model)이라고도 합니다. 많은 기업들이 챗봇형태의 서비스를 시작으로 다양한 실험을 통해, 에이전트 형태의 서비스를 개발하고 있습니다. 이전에는 LLM […]

Amazon OpenSearch Service Custom Plugin 적용하기
OpenSearch는 검색, 분석, 보안 모니터링, 통합 가시성 애플리케이션을 위한 확장 가능하고 유연한 오픈 소스 소프트웨어 제품군으로, Apache 2.0 라이선스를 따릅니다. Amazon OpenSearch Service(AOS)는 AWS 클라우드에서 OpenSearch를 간편하게 배포, 확장, 운영할 수 있으며 Amazon OpenSearch Ingestion, Integration 기능을 통해 다양한 AWS 서비스와 연동이 가능한 완전 관리형 서비스 입니다. 검색 서비스에서는 다양한 필터가 필요합니다. 특히, 상품 검색시 […]

Amazon S3 데이터 레이크와 기계학습을 위한 Snowflake 통합 파이프라인 플랫폼 구축하기
인공지능과 기계학습 기술의 상용화로, 기업들은 대량의 데이터를 효과적으로 수집, 저장, 관리할 필요성을 점차 인식하고 있습니다. 데이터 레이크(Data Lake)는 이러한 필요성에 부응하여, 다양한 소스로부터 대규모의 데이터를 실시간으로 수집하고 저장함으로써 기업의 의사결정과 혁신을 지원합니다. 이제 데이터 레이크는 기업이 데이터 자산을 최대한 활용하고 비즈니스 가치를 창출하는 핵심 요소로 자리 잡고 있습니다. 정형, 반정형, 비정형 데이터 등 다양한 유형의 […]

Amazon S3 Metadata를 Amazon Athena와 Amazon Quicksight로 분석하기
이 글은 AWS Storage Blog에 게시된 Analyzing Amazon S3 Metadata with Amazon Athena and Amazon QuickSight by Lokesh AP, Tom Bailey, Huey Han, Lee Kear, Fabio Lattanzi, and Roohi Sood를 한국어 번역 및 편집하였습니다. 오브젝트 스토리지는 사실상 무제한의 확장성을 제공하지만 수십억 개, 심지어 수조 개의 오브젝트를 관리하는 데는 상당한 어려움이 따를 수 있습니다. 어떤 데이터가 있는지 어떻게 알 수 […]