AWS 기술 블로그
Category: Amazon Bedrock

생성형AI를 통한 데브옵스 강화 – Part 2.운영 안정성 강화
이 블로그는 생성형 AI를 통한 데브옵스를 강화 시리즈의 두 번째입니다. DevOps Research and Assessment(DORA)에서 제시한 데브옵스 성숙도 측정 4가지 핵심 지표는 처리량 지표(변경 적용 시간, 배포 빈도)와 안정성 지표(변경 실패율, 장애 복구 시간)로 구분됩니다. 지난 생성형AI를 통한 데브옵스 강화 – Part 1.소프트웨어 딜리버리 가속화에 이어서 이번 편에서는 안정성 지표를 개선하여 운영 안정성을 높이는 방법에 대해 […]

하루만에 구축한 Cedar의 AWS 기반 다문화 가정 아동 디지털 심리 진단 서비스
Overview 시더가 AWS 모.각.큐(모여서 각자 Q로 코딩)에서 개발한 다문화 아동을 위한 디지털 심리 진단 서비스 사례를 소개합니다. Amazon Bedrock과 Amazon OpenSearch Service를 활용한 RAG 기반 멀티모달 분석으로 HTP(House-Tree-Person) 그림 검사를 자동화하고, “그림을 그리는 과정” 자체를 데이터화하여 전문가 수준의 심리 분석을 제공합니다. 태블릿 기반의 자연스러운 인터페이스와 다국어 지원을 통해 다문화 가정 아동의 심리적 접근 장벽을 낮추고, […]

AWS Control Tower 리전 제약 조건에서 Amazon Bedrock 크로스 리전 추론 기능 활용 지침
“이 게시글은 AWS Artificial Intelligence Blogs의 ‘Enable Amazon Bedrock cross-Region inference in multi-account environments by Satveer Khurpa‘ 를 번역 및 편집 하였습니다” Amazon Bedrock의 크로스 리전 추론 기능은 조직이 최적의 성능과 가용성을 유지하면서 AWS 리전 전반에 걸쳐 파운데이션 모델(FM)에 액세스할 수 있는 유연성을 제공합니다. 그러나 일부 기업은 규정 준수 요구사항을 충족하기 위해 서비스 제어 정책(SCP) […]
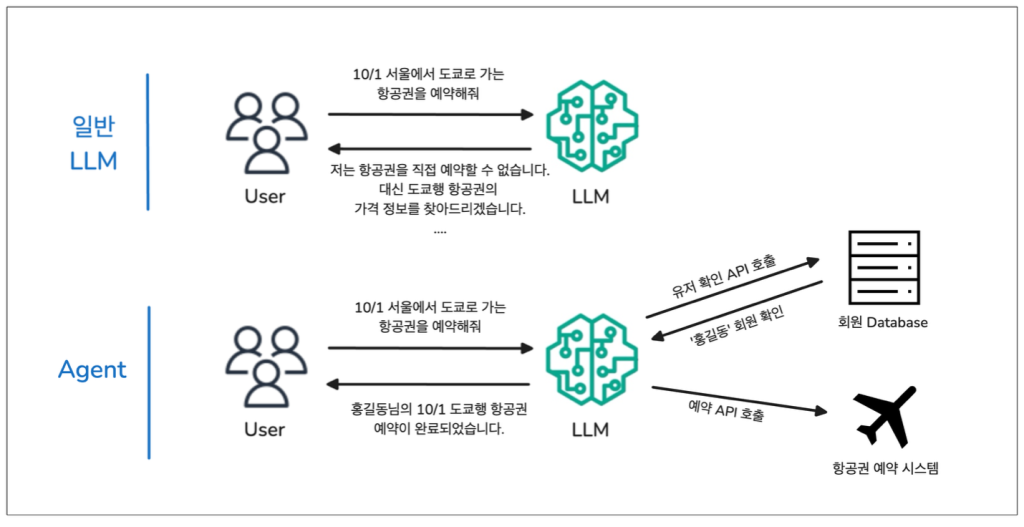
Amazon Bedrock Agent로 30분 만에 여행 예약 에이전트 구축하기 실전 가이드
최근 생성형 AI 트렌드에서 가장 많이 거론되는 키워드는 단연 “에이전트”입니다. RAG (Retrieval-Augmented Generation)가 맞춤형 지식 검색과 응답 생성으로 주목받았다면, 이제는 그 한계를 넘어 사용자의 요청을 이해하고 실제 액션까지 수행하는 AI 에이전트가 새로운 패러다임으로 떠오르고 있습니다. 그렇다면, 단순한 답변만 하는 수준을 넘어 외부 시스템과 연동해 액션까지 수행하는 AI 에이전트는 어떻게 만들 수 있을까요? 이번 포스팅에서는 Amazon […]
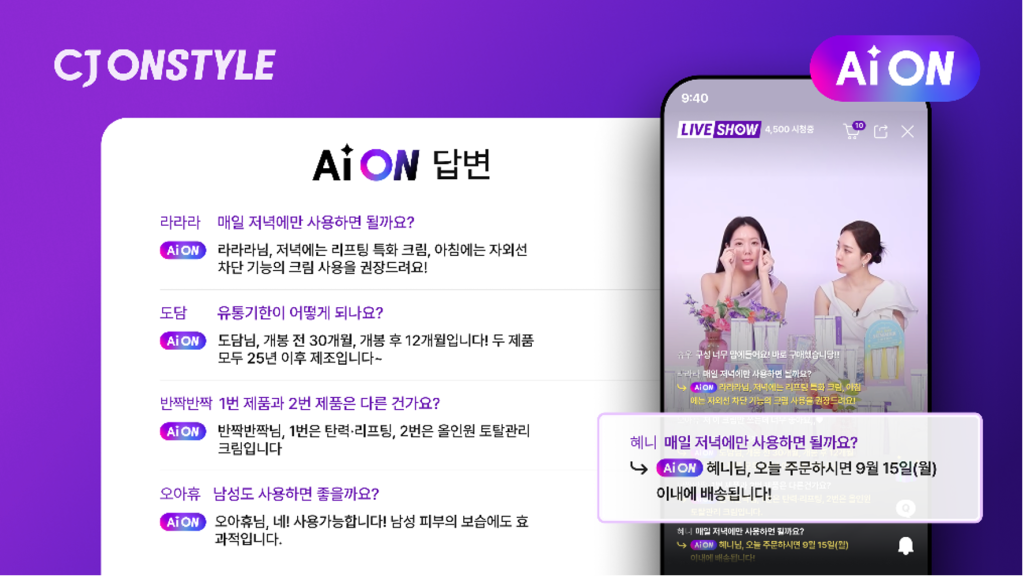
CJ 온스타일 라이브 커머스, Agentic AI로 고객 소통의 새로운 차원을 열다
이 블로그는 CJ온스타일의 고경락, 신영화, 성홍규, 송진호, 기수진 님과 AWS 변상규, 서지혜, Yash Shah, Charlie Chang 님께서 작성 해주셨습니다. 들어가며: 실시간 소통이 만드는 차별화 된 쇼핑 경험 CJ온스타일은 모바일과 TV, 이커머스를 연결해 영상 콘텐츠를 중심으로 한 차별화된 커머스 경험을 제공하는 커머스 플랫폼입니다. 특히 CJ온스타일은 모바일 라이브 커머스 1위(회당 거래액 기준) 플랫폼으로 고객과의 실시간 소통을 통해 차별화된 쇼핑 경험을 제공하는 핵심 […]

Amazon Nova Premier와 에이전트 워크플로우를 활용한 코드 마이그레이션 간소화
시작하기 전에 많은 기업들이 레거시 기술로 구축된 미션 크리티컬 시스템의 유지보수와 확장성 한계로 어려움을 겪고 있습니다. 동일 언어 내에서의 코드 리팩터링이나 일반적인 코드 변환의 경우에는 다양한 LLM 모델과 솔루션이 존재하지만, 서로 다른 프로그래밍 언어 간의 변환이나 고객의 복잡하고 특수한 요구사항을 충족하는 시스템 전환은 여전히 까다로운 과제입니다.이 블로그 포스트는 Amazon Bedrock Converse API와 Amazon Nova Premier를 […]

웅진의 Amazon Connect을 기반으로 한 차세대 컨택센터
클라우드와 AI가 혁신하는 컨택센터의 새로운 패러다임 생성형 AI 시장의 폭발적 성장과 함께, 고객 서비스 영역에서도 혁신적인 변화가 일어나고 있습니다. 가트너(Gartner)에 따르면 2025년 기업들의 생성형 AI 투자가 76.4% 증가할 것으로 예상되며, 특히 고객 서비스 분야에서의 AI 도입이 가속화되고 있습니다. 이는 AI 기술이 비즈니스 경쟁력의 핵심 도구로 자리매김하고 있음을 보여줍니다. 웅진은 20년 이상 컨택센터 운영 전문 기업으로서 […]

Amazon Bedrock으로 해보는 Nova 모델 지식 증류, 배포, 평가
Bedrock 모델 커스터마이제이션 개요 Amazon Bedrock은 생성형 AI 애플리케이션 및 에이전트 구축을 위한 완전 관리형 서비스입니다. LLM포함 다양한 AI 모델들을 통합 API를 통해서 쉽게 사용할 수 있으며 미세 조정하고 애플리케이션에 연결하는 데 필요한 도구와 기능을 제공하여 개발자가 인프라 관리 부담 없이 빠르고 안전하게 생성형 AI 애플리케이션을 개발하고 배포할 수 있도록 해줍니다. Bedrock 온디맨드(on-demand) 배포 기능 […]

티로의 Amazon Bedrock과 RDS를 활용한 대화 기록 기반 Ask Tiro 구현
매일 쏟아지는 회의 내용, 강의 녹음, 팀 미팅 기록들이 쌓여가면 쌓여갈수록 필요한 정보를 빠르게 찾는 것은 점점 더 어려워집니다. “지난주 온보딩 프로젝트에서 논의된 핵심 이슈가 뭐였지?”, “지난주 A 기업과의 미팅에서 결정된 주요 사항들이 뭐였지?”와 같이 대화 기록을 기반으로 한 고-맥락의 질문에 답하려면 수 많은 대화 기록을 일일이 찾아 봐야 하는 번거로움이 생기기 마련 입니다. 티로(Tiro) […]
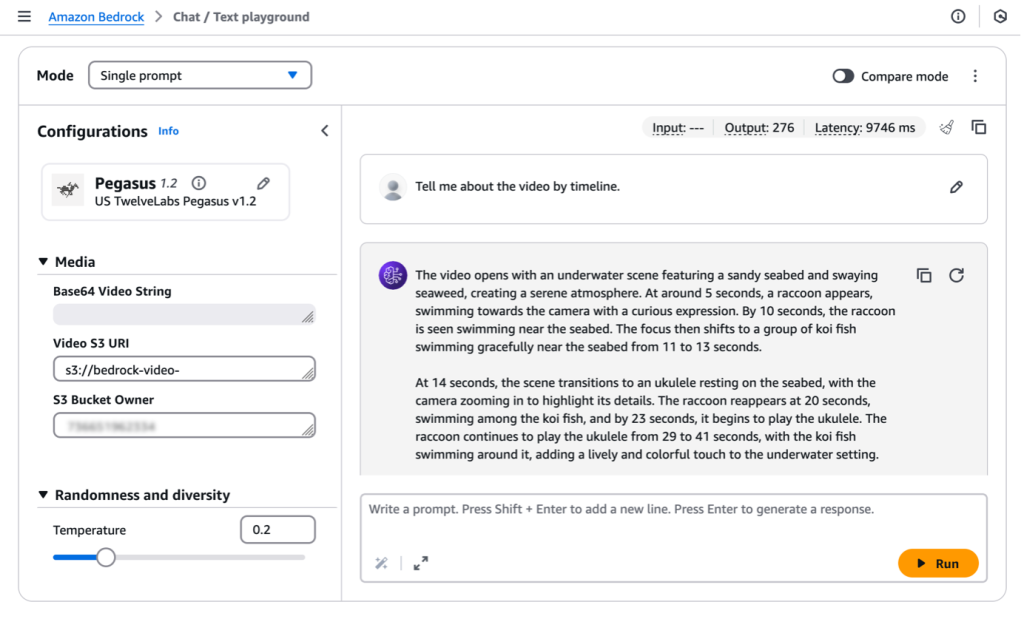
TwelveLabs 비디오 이해 모델, Amazon Bedrock 에서 사용하기
이 블로그는 원본 블로그를 번역 및 일부 내용을 수정한 버전 입니다. TwelveLabs video understanding models are now available in Amazon Bedrock 2025년 초, Amazon Bedrock에 TwelveLabs 의 비디오 이해 모델이 출시될 예정이라는 소식이 사전 발표되었습니다. TwelveLabs 모델들을 통해 정확하고 신뢰할 수 있는 비디오 검색, 장면 분류, 요약 및 인사이트 추출 작업이 Amazon Bedrock 에서 현재 사용 가능함을 안내드립니다. TwelveLabs는 […]