Containers
Blue/Green or Canary Amazon EKS clusters migration for stateless ArgoCD workloads
This blog was authored by Sébastien Allamand (Sr. Solution Architect Specialist, Containers), This blog has also been translated into Korean here.
- Edit: 02 Jun 2023: The sample has been updated according to the EKS Blueprint V5 Migration
- Edit 06 October 2023: Upgrade the blog and sample to use gitops-bridge-argocd-bootstrap integration
Introduction
Organizations use modern application development approaches, such as microservices, to increase innovation, performance, security, and reliability. However, when working with legacy deployment systems, it can be difficult to maintain a fast deployment pace while maintaining control and security over each deployment. As a result, customers often turn to orchestration systems like Amazon Elastic Container Services (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS) to manage their application workloads. Continuous Delivery is also a popular principle that helps customers define best practices for deploying applications and infrastructure, reducing risks, costs, and improving product quality and time to market. Applications running on AWS container services can be exposed through AWS Load Balancers and their associated domain names can be managed using Amazon Route 53.
Kubernetes upgrade strategy with Amazon EKS
Amazon EKS uses Amazon EKS Distro, which is a distribution of the same open-source Kubernetes including binaries and containers of Kubernetes, etcd, networking, and storage plugins that are tested for compatibility. Kubernetes releases occur approximately three times per year, and Amazon EKS is committed to supporting at least four production-ready versions of Kubernetes at any given time, and extend Kubernetes maintenance support for up to 14 months. Therefore, you’ll need an annual plan for upgrading the Kubernetes version, where you’re must adjust for multiple versions at a time, or upgrade your cluster regularly following new validated Amazon EKS Kubernetes versions.
As the Kubernetes features evolve, its application programming interfaces (APIs) have to evolve to support this change. There are rules in place that aim to ensure compatibility and stability; however, you’ll have to use new API versions and formats when the previous APIs are unsupported.
When planning for an upgrade, you need to test the migration before using it in a production environment, because multiple factors that can affect the upgrade process. These factors include: Amazon Machine Image (AMI) of your nodes, the add-ons deployed (e.g., kube-proxy, CodeDNS, and AWS Virtual Private Cloud (VPC) Container Network Interface), or any additional controllers or drivers that customers may have installed to extend Kubernetes functionalities, which may need to be upgraded. There are existing tools like Kubent that can help you identify which API isn’t working in the next Kubernetes version. We also recommend to read our documentation for the specific changes in the newly released version. You may also need to update your workload to fit the newly released version.
In-place rolling upgrade
If you want to upgrade each version individually, then you’ll need to plan for upgrades about two to three times a year, which is a typical upgrading frequency associated with adopting Kubernetes.
One of the main benefits you get from moving to Amazon EKS, is that AWS handles the Kubernetes control plane upgrades for you, by exposing APIs for the user to run those upgrades. The more Amazon EKS managed features you use (such as Managed Node Groups, AWS Fargate, and Amazon EKS-managed add-ons), the more you simplify this upgrading process. We automate Kubernetes upgrades of Managed Nodes Groupes in a rolling fashion way, and you can control how many nodes at a time Amazon EKS is allowed to upgrade. This process also respects any Pod Disruption Budget (PDB) we recommend you to set up in your cluster to protect your workloads. The time for an upgrade depends on how many pods need to be drained from the old nodes, the PDBs that we need to respect, the number of nodes in your cluster, and the upgrade parallelism you configured. Upgrading managed Amazon EKS add-ons is also simple to update by choosing new add-on version either through EKS console or within your Infrastructure as Code (IaC) and is managed by Amazon EKS. In this post, you can see that you can now preserve your Amazon EKS add-ons custom configuration with this upgrade process.
Blue/Green or Canary upgrade
In many cases, upgrading a cluster can be straightforward using a built-in rolling update solution. However, you may prefer to just create a new fresh cluster, and migrate your workloads from old cluster to the new one. It may be that you are several Kubernetes versions behind, or have detected an issue when playing rolling update in test. You can end-up with a mix of in-place or blue/green upgrades like our customer TheFork, who explained their Kubernetes cluster upgrade strategy in this post. In their implementation, they have a Terraform-first approach, where they want all their AWS infrastructure to be managed by Terraform and not by Kubernetes, which simplifies their Amazon EKS cluster blue/green migration process as theses resources stay the same when moving from one cluster to the other.
When using this pattern, we define our infrastructure as code to creates a load balancer, which remains the same for both Amazon EKS clusters and two target-groups, with one for each Amazon EKS cluster. Then, we can rely on AWS load balancer controller TargetGroupBinding custom resource definition (CRD) to dynamically associate our services to the existing target-group we just created. Within the load balancer rules, we configure the weight of requests to send to each target group to control the migration of requests between our clusters. The advantage of this solution is that we don’t rely on any domain name server (DNS) time to live (TTL) or caching on client machines.
You can find an implementation sample using existing Application Load Balancer in the EKS Blueprint for Terraform Workshop
When customers start having hundreds of services to expose that are managed by many different application teams, this pattern can be harder to scale, because it implies that every application team asks your platform team to create in advance load balancers and target-groups for their applications to expose. Many customers chose to give more autonomous to their application teams and rely on AWS load balancer controller and External DNS to let them configure their resources as they need, by annotating service or ingress Kubernetes objects.
Obviously, the implementation details of the cluster upgrade are different if we use IaC or Kubernetes to create load balancers, and keep in mind that in any case, it’s essential to repeatedly test your Kubernetes upgrades.
Solution overview
In this post, we’ll focus and explaining one possible implementation that could allow your platform team to automate the workloads migration from a Blue Amazon EKS cluster to a Green EKS cluster.
You can find the associated git repository which contains the Terraform IaC you can use to follow this solution.

We use Amazon EKS Blueprint for Terraform open-source project to create two clusters (eks-blue and eks-green) that share the same VPC and use the AWS Load Balancer Controller and the External-DNS add-ons, to expose our applications. The Amazon EKS Blueprint creates the clusters, installs the add-ons, and configure our teams.
There are two types of personas we consider here: The Platform team is responsible for the infrastructure automation code, and manages the Amazon EKS clusters (i.e., they have administrative rights). The Application teams are responsible for the build and deployment of their workloads. Each team is associated with a Kubernetes namespace and they have read-only rights in their namespace.
Application teams deploy workloads using GitOps with ArgoCD add-on, relying on our existing “App of Apps” configuration git repository that contains the application’s Helm charts, referenced by ArgoCD Application Kubernetes object. When the Amazon EKS cluster is created, ArgoCD connects to the Git repository and reconciles the cluster with associated manifests, which means it deploys the workloads defined in Git into the Amazon EKS clusters.
We have two ways to deploy Amazon EKS add-ons with Amazon EKS Blueprint. In both deployments, Terraform creates needed resources like AWS Identity and Access Management (AWS IAM) roles needed by the add-on kubernetes service account, but the helm chart of the application can be either deployed by Terraform or by ArgoCD.
We are leveraging the gitops-bridge (gitops-bridge-argocd-bootstrap) terraform module that allow us to dynamically provide metadatas from Terraform to ArgoCD deployed in the cluster. For doing this, the module will extract all metadatas from the terraform-aws-eks-blueprints-addons module, configured to create all resources except installing the addon’s Helm chart. The gitops-bridge will create a secret in the EKS cluster containing all the metadatas that will be dynamically used by ArgoCD ApplicationSets at deployment time, so that we can adapt their configuration to our EKS cluster context.
The gitops-bridge will also bootstrap the ArgoCD ApplicationSets for add-ons and workloads to initiate the installation process using the metadatas from the secret:
- The add-ons bootstrap reference a git configuration repository sample eks-blueprints-add-ons containing the ApplicationSets for each supported Addons (i.e., metrics server, AWS Load Balancer Controller, external DNS, Karpenter, kubecost…)
- The workloads bootstrap git configuration repository sample eks-blueprints-workloads containing helm charts for ArgoCD App of App for our applications to be deployed.

We configure within terraform the list of add-ons we want to activate:
#---------------------------------------------------------------
# ARGOCD ADD-ON APPLICATION
#---------------------------------------------------------------
aws_addons = {
enable_cert_manager = true
enable_external_dns = true
enable_external_secrets = true
enable_aws_load_balancer_controller = true
...
}
oss_addons = {
enable_kyverno = true
enable_kube_prometheus_stack = true
enable_metrics_server = true
...
}
addons = merge(local.aws_addons, local.oss_addons, { kubernetes_version = local.cluster_version }Our solution is comprised of an environment stack that creates a shared VPC and shared Route 53-hosted zone for our two eks-blue and eks-green clusters, that are using a local eks_cluster terraform module.
We configured Amazon EKS Blueprint to deploy the same applications in both clusters from our GitOps workloads repository.
Some applications define Kubernetes ingress objects, that trigger the load balancer controller to create load balancers. It also associates a transport layer security (TLS) endpoint with a wildcard AWS Certificate Manager. External DNS add-ons is configured to create the same records for each cluster in the shared environment hosted zone.
We configure our workloads applications from Terraform using the addons metadatas and any required values, so that we can apply different parameters for each cluster (i.e., weight for our DNS records) that allows us to define how many requests to send to each cluster, and control the Canary workload migration between our two clusters.
In this post, we show how you can seamlessly migrate your stateless workloads between the two clusters using a Blue/Green or Canary strategy. Another use case for this architecture is to have your workloads separated in different EKS clusters, VPCs or Regions, for either high availability or lower latency access from your customers.
Walkthrough
Getting started
To test this setup, please go to our Amazon EKS Blueprint Example and follow the step-by-step instructions. In the remainder of the post, we’ll show the configurations used in this repository. Also check that you have the correct prerequisites, and then follow the QuickStart details.
Meet our test application
We are going to look at one of the applications deployed from the workload repository as an example to demonstrate our migration automation. The Burnham workload, deployed in the team-burnham Kubernetes namespace. This simple application responds with the name of the cluster it’s running on, which makes it easy to see the current migration on our workload.
Hello EKS Blueprint Version 1.4
Server address: 10.0.0.156:63492
Server name: burnham-665d4fb487-fc6w9
Date: 2023.10.06 16:24:14
URI: /
HOST: burnham.eks-blueprint.mydomain.com
CLUSTER_NAME: eks-blueprint-greenThe application is deployed from our workload repository manifest referenced by the workloads bootstrap
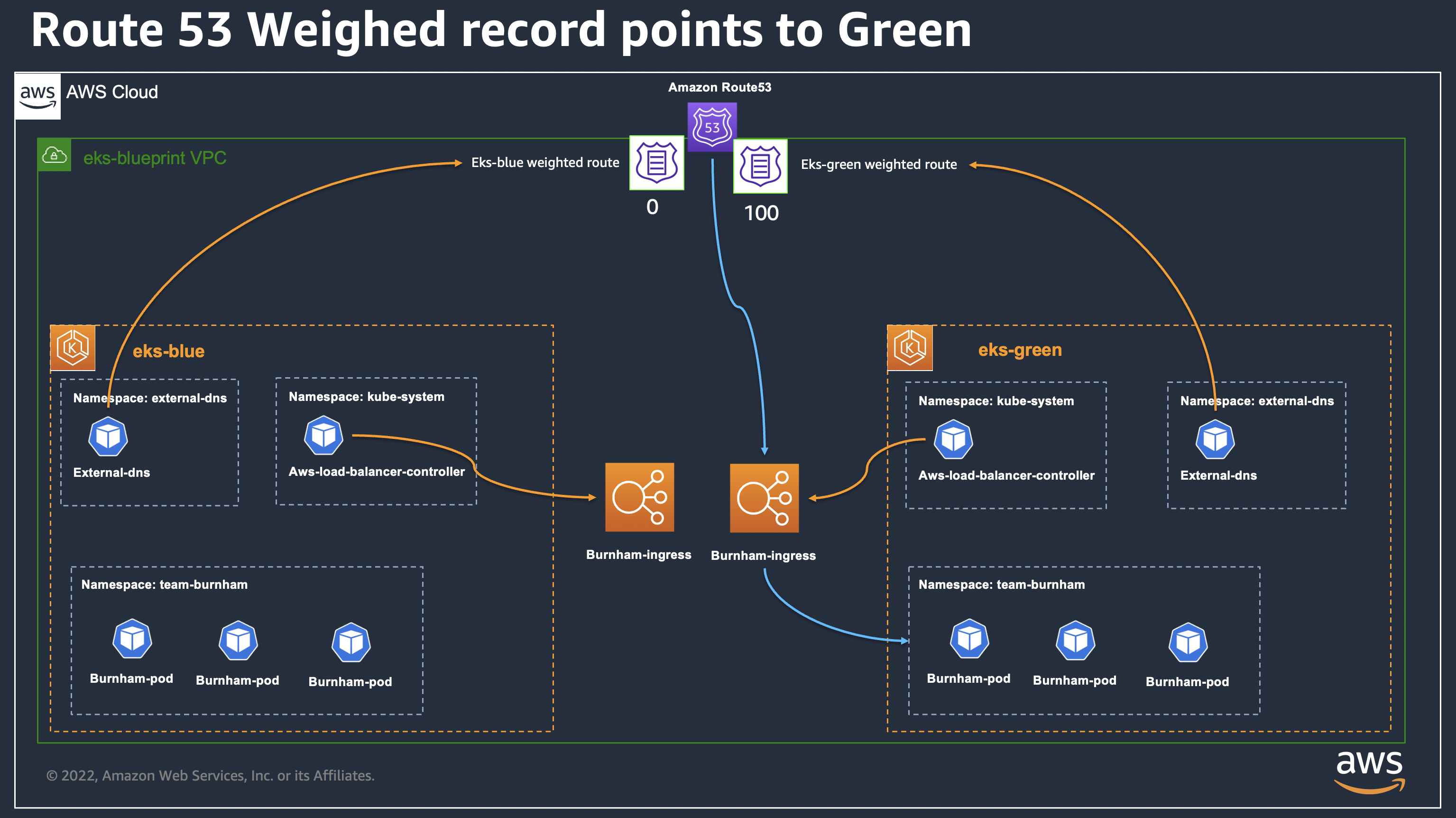
We configured both of our Amazon EKS clusters to use the same Amazon Route 53-hosted zones. This is done by configuring the External DNS add-on in main.tf.
We use External DNS in sync mode so that the controller can create and remove DNS records according to the service or ingress object creation. We also configured the txtOwnerId with the name of the cluster, so that each controller can create, update, or delete records but only for records which are associated to the proper OwnerId. Each clusters has different IDs : eks-blue and eks-green, which are propagated to dedicated TXT records in the form of:
Here, the owner is the External DNS controller, from the eks-blueprint-green Amazon EKS cluster, and corresponds to the Kubernetes ingress resource named burnham-ingress in the team-burnham namespace.
Using this feature, and relying on weighted records, we can do Blue/Green or Canary migration by changing the weight of ingress resources defined in each cluster.
Configure the records weights for the Applications
Since the Platform team has configured ExternalDNS add-on, the Application teams can now defined specific annotations in their ingress/service objects. You can see an example of the ingress configuration in our sample repository, which is shown in the following:
We rely on two external-dns annotation to configure how the record is created. The set-identifier annotation contains the name of the cluster we want the record to be associated with, and the aws-weight used to configure the value of the weighted record. The value is injected from the Terraform code when creating or updating each cluster, so that our Platform team can control how and when they want to migrate workloads between the Amazon EKS clusters.
Automate the migration from Terraform
If we’re running our workloads in the eks-blue cluster only in version Kubernetes 1.23, then we’d use the following:
Now imagine, we want to create a new cluster eks-green in version 1.24. This is done by configuring in the eks-green repository. We should also ensure that the record weights for the green repository are set to 0 like this and terraform apply:
Then, we will be in this configuration:
![Architecture diagram with 100% request on eks-blue and 0% requests on eks-green. User can still reach eks-green cluster by manually targeting the load balancer]](https://d2908q01vomqb2.cloudfront.net/fe2ef495a1152561572949784c16bf23abb28057/2022/12/22/blue.png)
Our new cluster is created with its associated load balancers, but it isn’t included yet in the DNS responses, due to its weight set to 0.
We can still test that our applications are responding correctly from the eks-green cluster by calling directly it’s load balancer, and adding the desired host header:
That should respond with eks-green cluster (If you get a 404 error, check you’ve updated the Host header with appropriate name):
If we are satisfied, then we can start the Canary migration by gradually changing the weight parameters for burnham workload on both eks-blue and eks-green cluster, applying our changes with Terraform, and seeing our request migrating from one cluster to the other until we had 100% of requests on the eks-green cluster.
Note that this solution relies on DNS, with a default TTL set to 60 seconds, but you’ll need to wait to all the HTTP clients or proxies to update their DNS Cache for the migration to be fully effective.
At this stage, we have successfully migrate our workload from eks-blue cluster to the new eks-green cluster running in the latest EKS version available. We can either keep the eks-blue cluster if we need to rollback some workloads. Once the cluster isn’t useful anymore, you can remove it to free up associated resources.
Cleaning up
When you finish experimenting with this example, you can delete it from your account. You can reference to this section for detailed instructions.
First go to both eks-blue and eks-green and execute the tear down script:
../tear-down.sh
When every EKS clusters are down, you can go to the environment directory and run:
terraform apply -destroy -auto-approve
Conclusions
In this post, we demonstrated various strategies for upgrading clusters and provided a solution for automating the migration of stateless workloads from one cluster to another using Route 53 weighted records, Terraform configurations, and ArgoCD. We also discussed the benefits of this solution, as well as the limitations of DNS TTL and an alternative method using infrastructure as code (IaC) for creating load balancers and target groups with the Load Balancer Controller’s TargetGroupBinding feature for dynamic mapping with Kubernetes services, you can find this solution in the EKS Blueprint for Terraform Workshop.