Amazon Web Services ブログ
AWS Lambda のテナント分離モードによるマルチテナントアプリケーション開発の効率化
本記事は2025年11月19日に公開された「Streamlined multi-tenant application development with tenant isolation mode in AWS Lambda」を翻訳したものです。
マルチテナントアプリケーションでは、テナント固有のコードやデータを処理する際に厳格な分離が求められることがよくあります。例えば、ワークフロー自動化やコード実行のための Software-as-a-Service (SaaS) プラットフォームでは、個々のテナントやエンドユーザーに使用される実行環境が互いに完全に分離されていることを保証する必要があります。従来、開発者はテナントごとに個別の Lambda 関数をデプロイするか、共有関数内にカスタム分離ロジックを実装することでこれらの要件に対応してきましたが、これによりアーキテクチャと運用の複雑さが増していました。
本日、AWS Lambda は、Lambda の既存の分離機能を拡張する新しいテナント分離モードを導入しました。Lambda はすでに関数レベルでの分離を提供していますが、この新しいモードは単一の関数内で個々のテナントまたはエンドユーザーレベルまで分離を拡張します。この組み込み機能により、各テナントの関数呼び出しを個別の実行環境で処理できるため、関数コード内でテナント固有のリソースを管理する追加の実装作業なしに、厳格な分離要件を満たすことができます。
AWS Lambda コンソールでテナント分離モードを有効にする方法は次のとおりです。
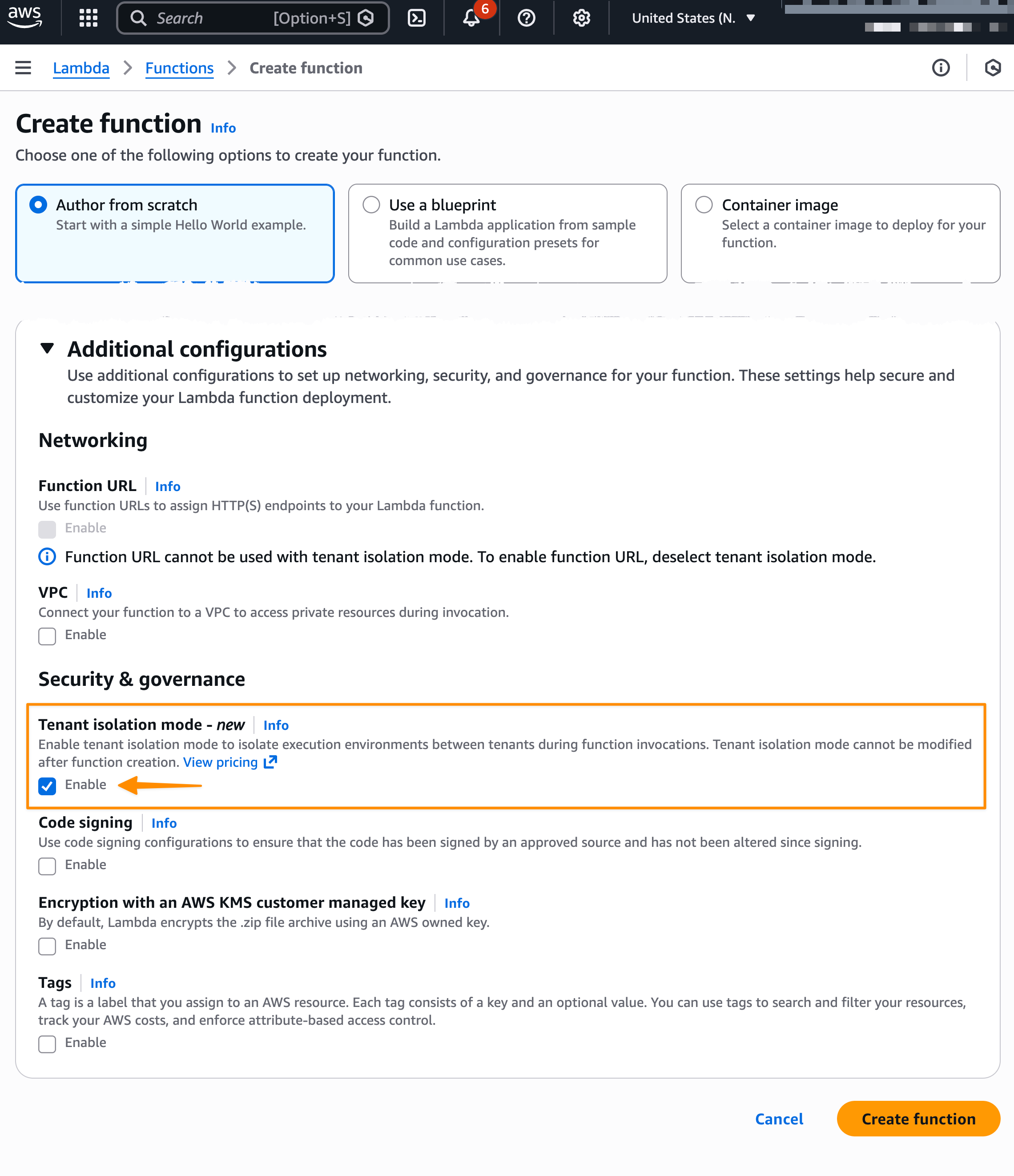
新しいテナント分離機能を使用すると、Lambda は関数の実行環境を顧客が指定したテナント識別子に関連付けます。これは、特定のテナントの実行環境が、同じ Lambda 関数を呼び出す他のテナントからの呼び出しリクエストに使用されないことを意味します。
この機能は、機密データを処理したり、信頼されていないテナントコードを実行したりする SaaS プロバイダーの厳格なセキュリティ要件に対応します。AWS Lambda の従量課金制とパフォーマンス特性を維持しながら、実行環境の分離を実現できます。さらに、このアプローチは、個々のテナント用の専用 Lambda 関数を管理する運用オーバーヘッドなしに、テナントごとのインフラストラクチャのセキュリティ上の利点を提供します。顧客がアプリケーションを採用するにつれて、管理対象が急速に増加する可能性があります。
AWS Lambda テナント分離の使用開始
マルチテナントアプリケーションのテナント分離を設定して使用する方法を説明します。
まず、AWS Lambda コンソールの関数の作成ページで、一から作成オプションを選択します。
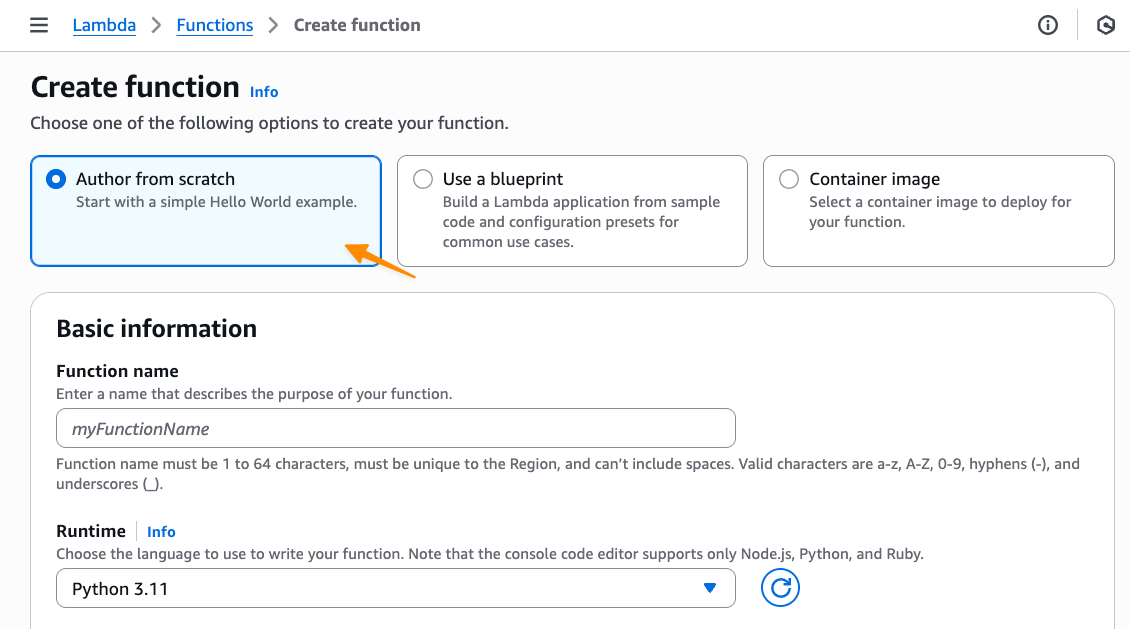
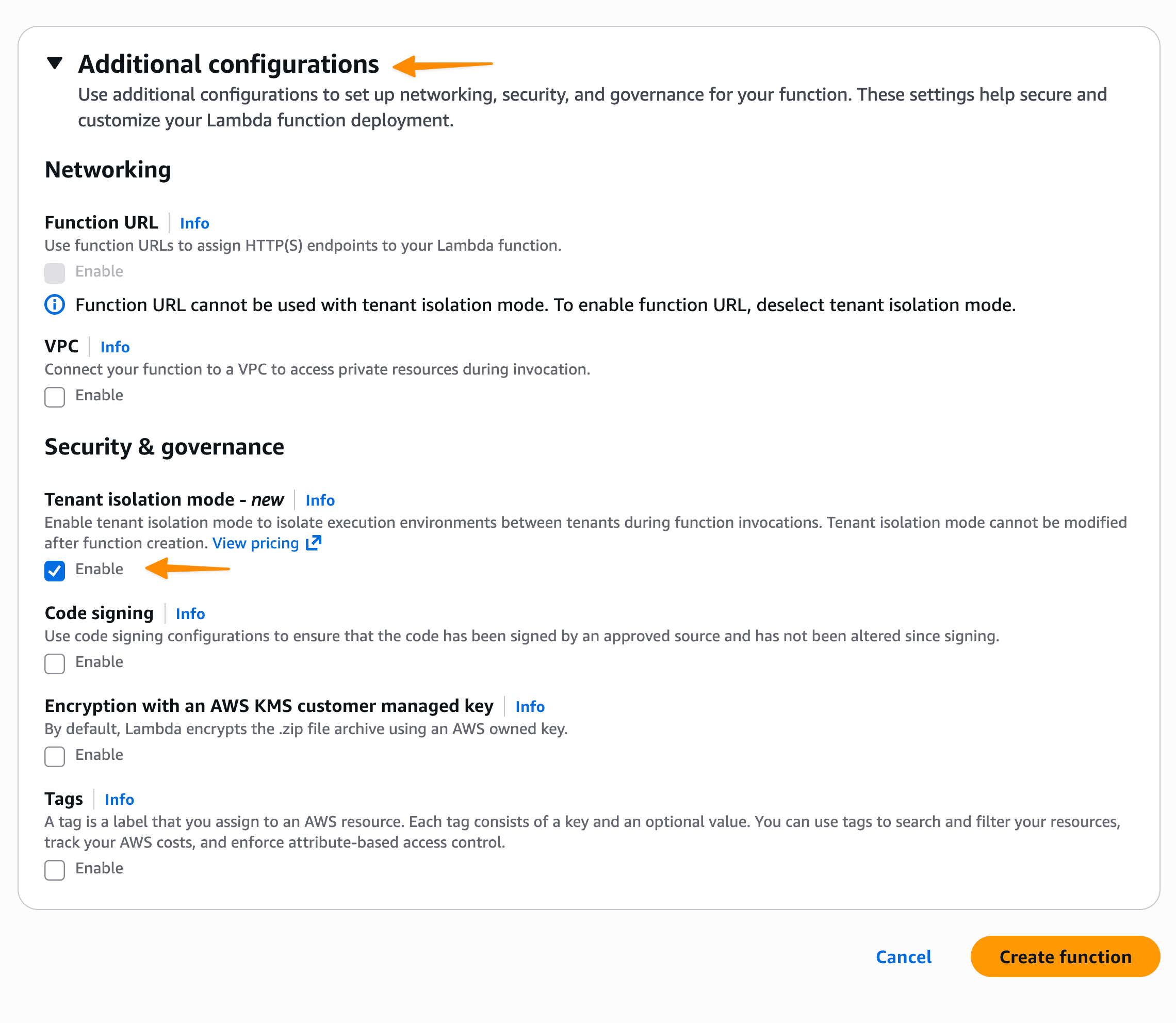
次に、追加設定で、テナント分離モードの下にある有効化を選択します。テナント分離モードは関数作成時にのみ設定でき、既存の Lambda 関数に対して変更することはできないことに注意してください。
次に、この機能を実証するための Python コードを記述します。関数コード内で context オブジェクトを通じてテナント識別子にアクセスできます。完全な Python コードは次のとおりです。
import json
import os
from datetime import datetime
def lambda_handler(event, context):
tenant_id = context.tenant_id
file_path = '/tmp/tenant_data.json'
# 既存データの読み取りまたは初期化
if os.path.exists(file_path):
with open(file_path, 'r') as f:
data = json.load(f)
else:
data = {
'tenant_id': tenant_id,
'request_count': 0,
'first_request': datetime.utcnow().isoformat(),
'requests': []
}
# カウンターをインクリメントしてリクエスト情報を追加
data['request_count'] += 1
data['requests'].append({
'request_number': data['request_count'],
'timestamp': datetime.utcnow().isoformat()
})
# 更新されたデータをファイルに書き戻す
with open(file_path, 'w') as f:
json.dump(data, f, indent=2)
# 分離を示すためにファイルの内容を返す
return {
'statusCode': 200,
'body': json.dumps({
'message': f'File contents for {tenant_id} (isolated per tenant)',
'file_data': data
})
}
完了したら、デプロイを選択します。次に、テストを選択してこの機能をテストする必要があります。新しいテストイベントの作成パネルに、テナント IDという新しい設定があることがわかります。
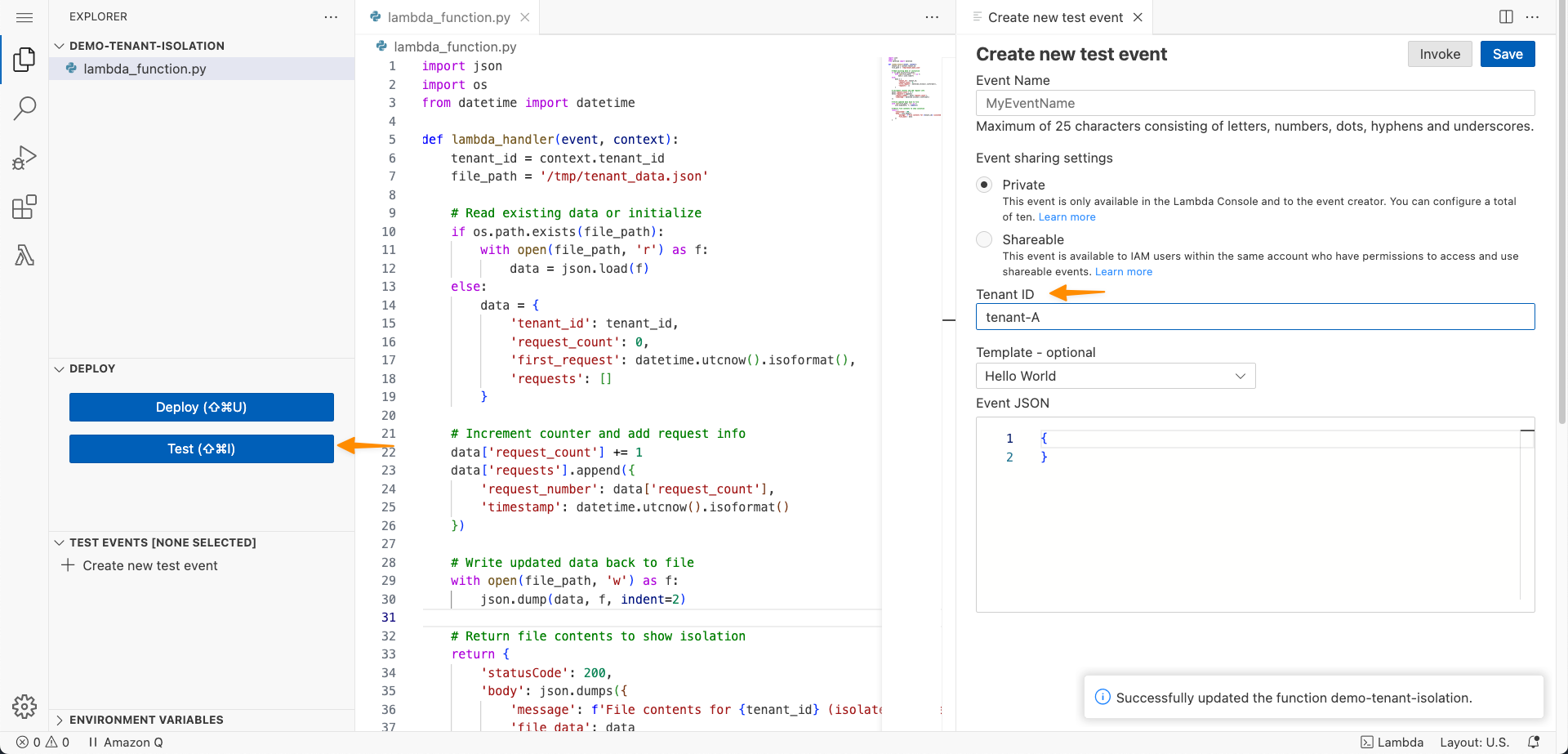
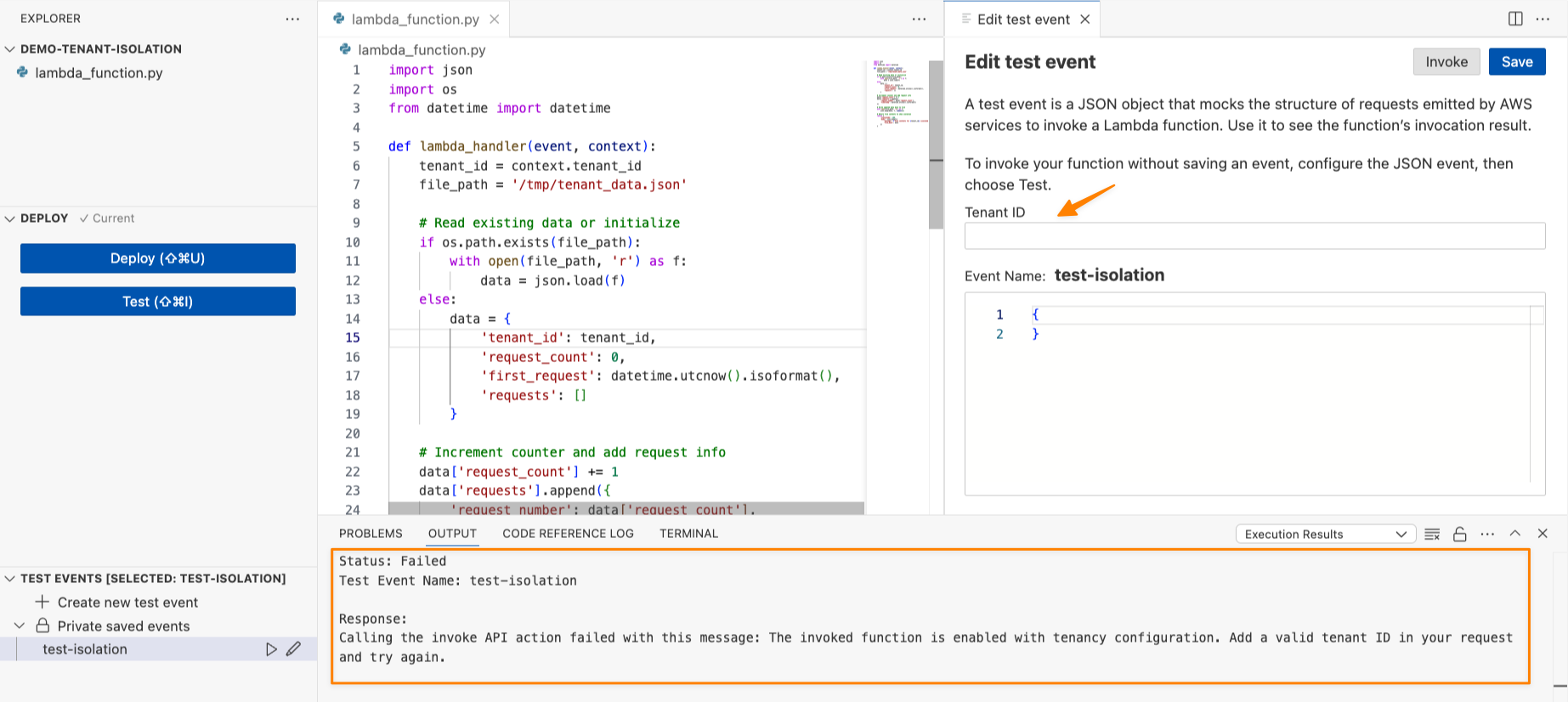
テナント ID なしでこの関数を呼び出そうとすると、「Add a valid tenant ID in your request and try again.」というエラーが表示されます。
tenant-A というテナント ID でこの関数をテストしてみましょう。
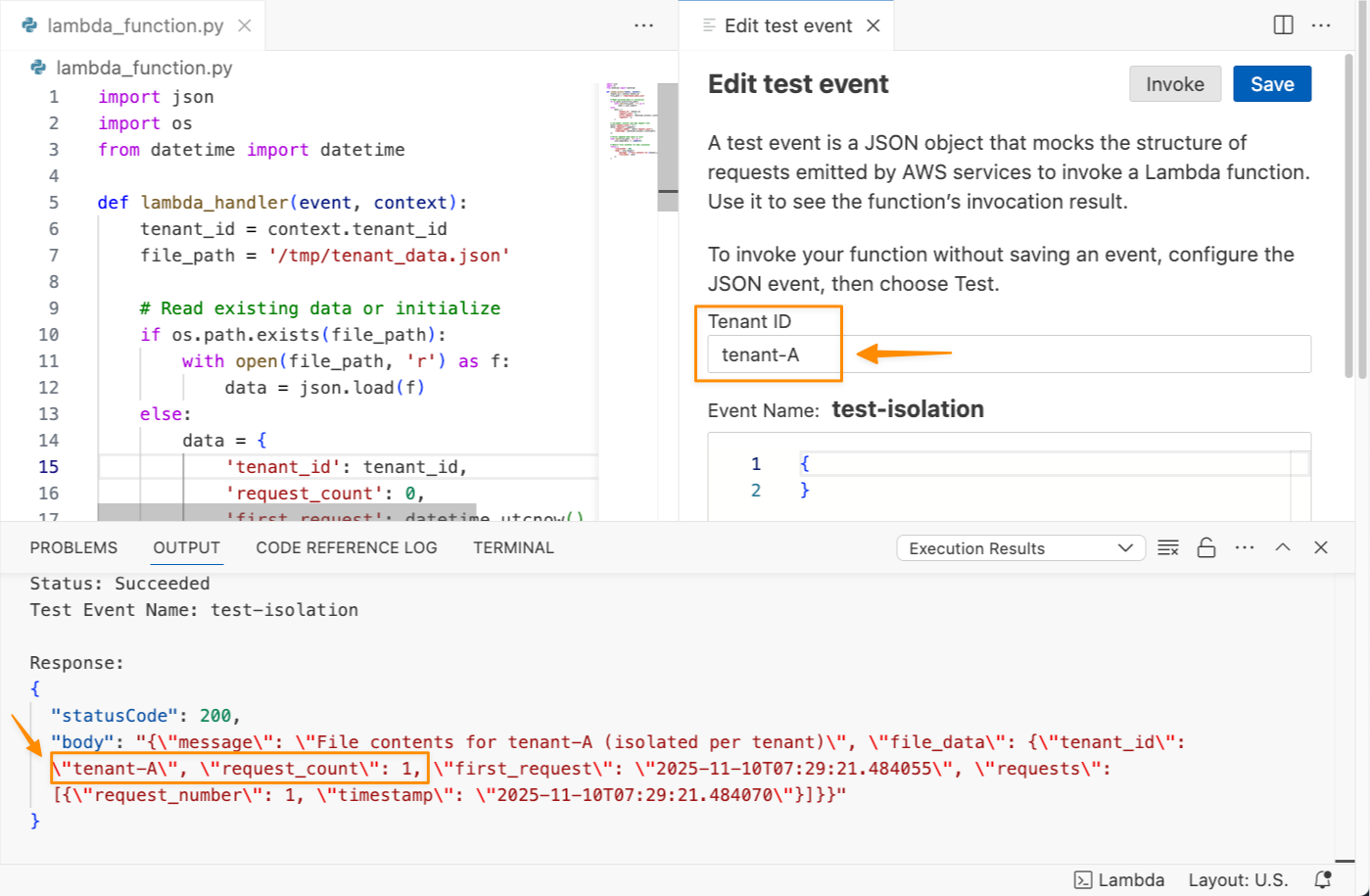
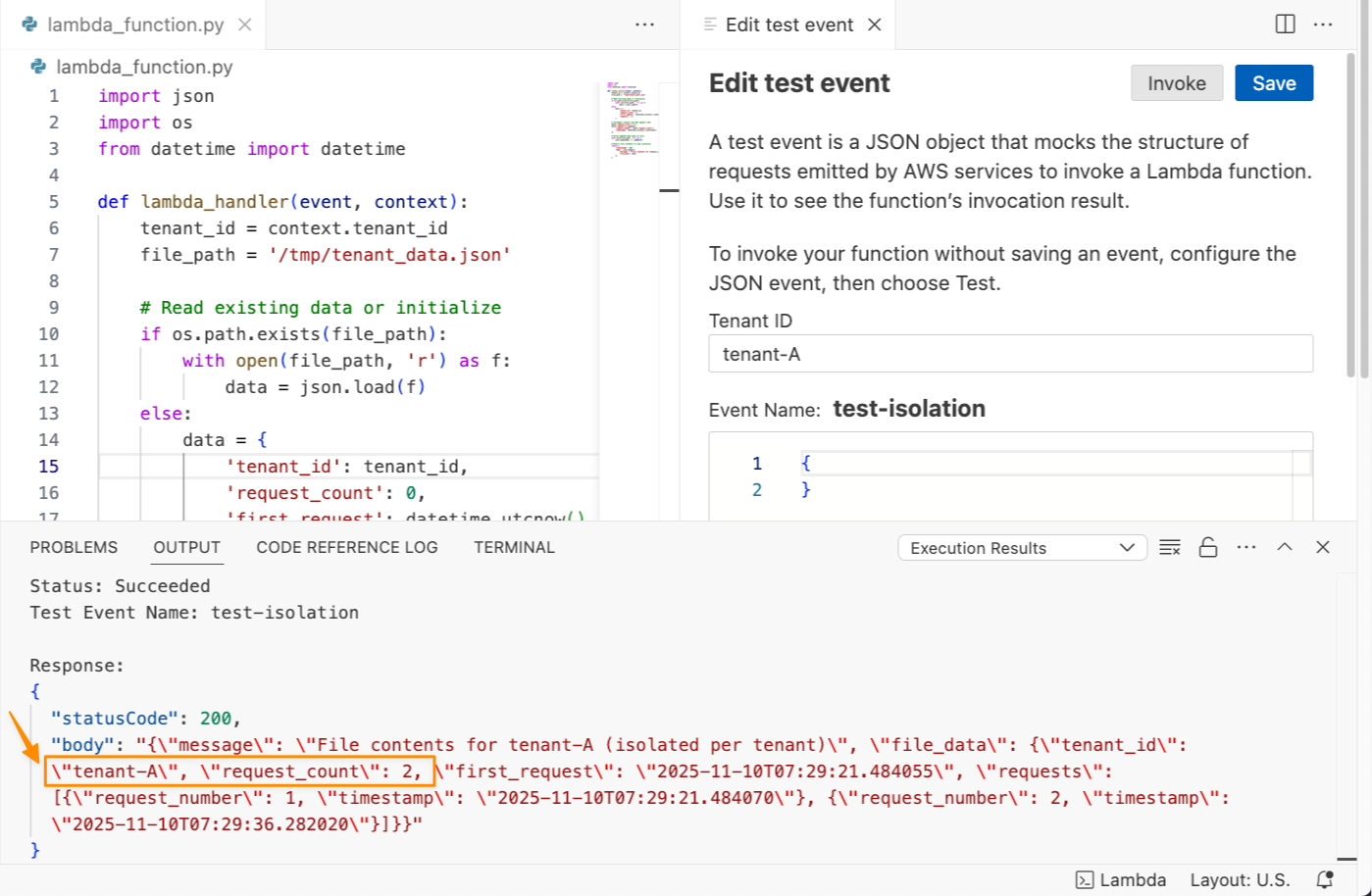
関数が正常に実行され、request_count: 1 が返されたことがわかります。この関数を再度呼び出すと、request_count: 2 が返されます。
次に、tenant-B というテナント ID でこの関数をテストしてみましょう。
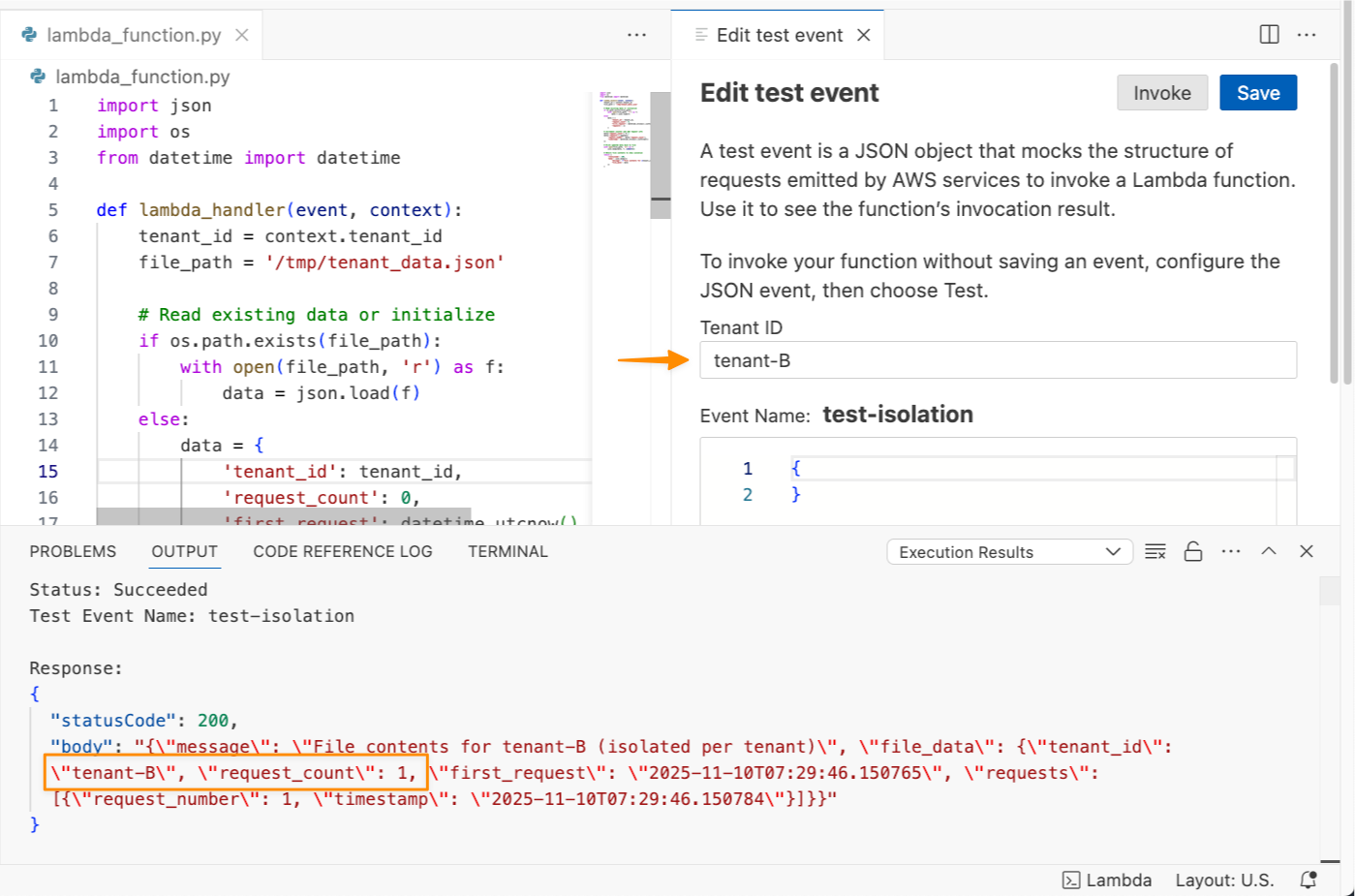
最後の呼び出しでは request_count: 1 が返されました。これは、tenant-B でこの関数を呼び出したことがなかったためです。各テナントの呼び出しは個別の実行環境を使用するため、キャッシュされたデータ、グローバル変数、/tmp に保存されたファイルが分離されます。
この機能により、マルチテナントサーバーレスアーキテクチャへのアプローチが変わります。複雑な分離パターンに苦労したり、数百のテナント固有の Lambda 関数を管理したりする代わりに、AWS Lambda に分離を自動的に処理させることができます。これにより、テナント間でテナントデータが分離され、マルチテナントアプリケーションのセキュリティと分離に自信を持つことができます。
知っておくべきその他の事項
知っておくべきその他の事項のリストは次のとおりです。
- パフォーマンス — 同じテナントの呼び出しは、最適なパフォーマンスのためにウォーム実行環境の再利用の恩恵を受けることができます。
- 料金 — Lambda が新しいテナント対応実行環境を作成すると課金され、料金は関数に割り当てるメモリ量と使用する CPU アーキテクチャによって異なります。詳細については、AWS Lambda の料金をご覧ください。
- 利用可能なリージョン — アジアパシフィック (ニュージーランド)、AWS GovCloud (US)、中国リージョンを除くすべての商用 AWS リージョンで現在利用可能です。
この機能により、ワークフロー自動化やコード実行のための SaaS プラットフォームなど、AWS Lambda 上でのマルチテナントアプリケーションの構築が簡素化されます。マルチテナント Lambda 関数のテナント分離を設定する方法の詳細については、AWS Lambda 開発者ガイドをご覧ください。
Happy building!
— Donnie