Amazon Web Services ブログ
Amazon Timestream であらゆる規模の時系列データを保存してアクセス – 一般提供が開始されました
時系列は、物事が時間の経過とともにどのように変化するかを説明する非常に一般的なデータ形式です。最も一般的なデータソースには、産業機器と IoT デバイス、IT インフラストラクチャスタック (ハードウェア、ソフトウェア、ネットワークコンポーネントなど)、およびそれらの結果を経時的に共有するアプリケーションがあります。時系列データの効率的な管理は、このデータモデルが汎用データベースに合わないことから容易ではありません。
本日からの Amazon Timestream の一般提供をお知らせできることが嬉しいのは、これが理由です。Timestream は、1 日に数兆件もの時系列イベントを収集、保存、および処理することを簡単にする高速でスケーラブルなサーバーレスの時系列データベースサービスで、リレーショナルデータベースよりも 1000 倍速く、コストもわずか 10 分の 1 です。
これは、Timestream がデータを管理する方法によって可能になります。Timestream では、最近のデータがメモリに保持され、履歴データはユーザーが定義する保持ポリシーに基づいて、コスト最適化されたストレージに移動されます。データは常に、同じ AWS リージョン内にある複数の アベイラビリティーゾーン (AZ) にまたがって、すべてが自動的にレプリケートされます。新しいデータはメモリストアに書き込まれます。メモリストアでは、データが 3 つの AZ にレプリケートされてから、オペレーションの成功が返されます。データレプリケーションはクォーラムベースであるため、ノードまたは AZ 全体が損失されても、耐久性や可用性が損なわれることがありません。さらに、メモリストア内のデータは、万が一のために Amazon Simple Storage Service (S3) に継続的にバックアップされます。
クエリは、ストレージの場所を指定しなくても、階層全体における最近のデータと履歴データに自動的にアクセスして、それらを統合します。また、データの傾向とパターンをほぼリアルタイムで特定できるように、時系列固有の機能もサポートします。
初期費用はなく、お支払いいただくのは、書き込み、保存、またはクエリを実行するデータに対する料金のみです。Timestream は、負荷に基づいて自動的にスケールアップまたはスケールダウンしてキャパシティーを調整し、基盤となるインフラストラクチャを管理する必要はありません。
Timestream は、データ収集、視覚化、および機械学習のための一般的なサービスと統合されているため、既存、および新しいアプリケーションでの使用が簡単です。例えば、AWS IoT Core、Apache Flink 向けの Amazon Kinesis Data Analytics 、AWS IoT Greengrass、および Amazon MSK から直接データを取り込むことができます。異常検知などのために、Timestream に保存されたデータを Amazon QuickSight から視覚化し、Amazon SageMaker を使用して機械学習アルゴリズムを時系列データに適用することができます。Timestream のきめ細かい AWS Identity and Access Management (IAM) アクセス許可を使用して、AWS Lambda 関数からのデータの取り込み、またはデータのクエリを簡単に実行することができます。AWS では、Apache Kafka、Telegraf、Prometheus、および Grafana などのオープンソースプラットフォームで Timestream を使用するためのツールを提供しています。
コンソールからの Amazon Timestream の使用
Timestream コンソールで [Create database] (データベースを作成) を選択します。[Standard database] (標準データベース)、またはサンプルデータが投入されている [Sample database] (サンプルデータベース) の作成を選択できます。今回は、標準データベースを選択して MyDatabase という名前を付けます。

すべての Timestream データはデフォルトで暗号化されています。このデータベースにはデフォルトマスターキーを使用しますが、AWS Key Management Service (KMS) を使用して作成したカスタマー管理のキーを使用することができます。そうすることで、マスターキーのローテーションと、それを使用または管理する許可の所有者を制御できます。
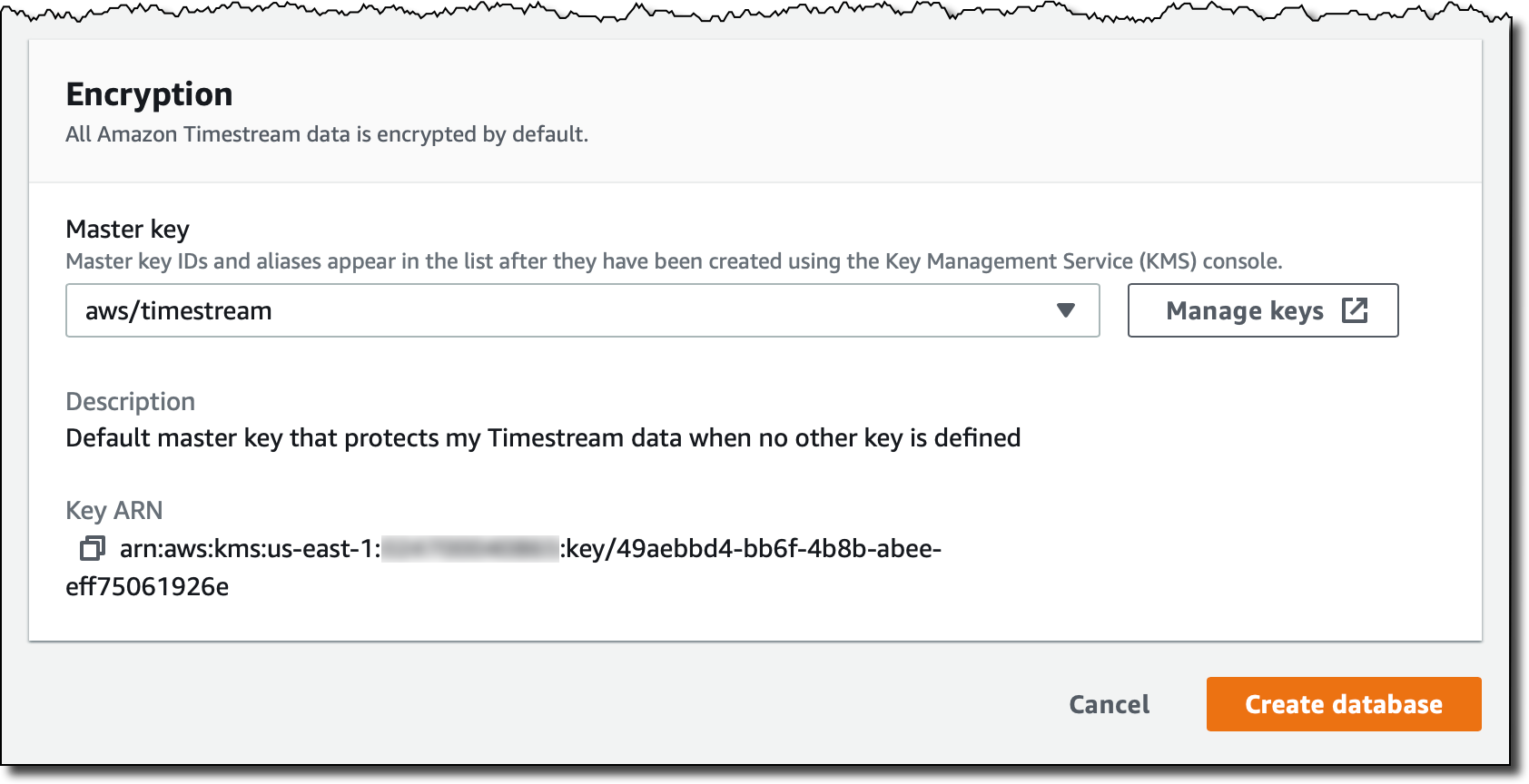
データベースの作成を完了します。現在、このデータベースは空です。[Create table] (テーブルを作成) を選択して、それに MyTable という名前を付けます。

各テーブルには、独自のデータ保持ポリシーがあります。最初のデータはメモリストアに取り込まれます。メモリストアでは、最小 1 時間から最大 1 年間データを保存できます。その後、データは自動的にマグネティックストアに移されます。ここでは、最小 1 日から最大 200 年までデータを維持することができ、その期間が過ぎるとデータは削除されます。今回の場合は、メモリストア保持に 1 時間、マグネティックストア保持に 5 年を選択します。

Timestream にデータを書き込む場合、メモリストアの保持期間よりも古いデータを挿入することはできません。例えば、今回の場合は 1 時間より古いレコードを挿入することはできません。同様に、未来のタイムスタンプを持つデータを挿入することもできません。
テーブルの作成を完了します。お分かりのように、データスキーマについては選択肢がありませんでした。Timestream は、データが取り込まれると同時に、スキーマを自動的に推論します。それでは、テーブルにデータを投入しましょう!
Amazon Timestream へのデータのロード
Timestream テーブル内の各レコードは、時系列における単一データポイントであり、以下が含まれます。
- メジャー名、メジャータイプ、およびメジャー値。各レコードには単一のメジャーを含めることができますが、同じテーブルに異なるメジャー名とメジャータイプを保存することができます。
- メジャーが収集されたときのタイムスタンプ (ナノ秒粒度)。
- メジャーを説明する 0 個以上のディメンション。これは、データのフィルタリングや集計に使用できます。テーブル内のレコードは、異なるディメンションを持つことができます。
例として、サーバーから CPU、メモリ、スワップ、およびディスクの使用量を収集するシンプルなモニタリングアプリケーションを構築してみましょう。各サーバーはホスト名によって識別され、国および都市として表される場所があります。
この場合、ディメンションはすべてのレコードに対して同じになります。
countrycityhostname
テーブル内のレコードは、異なるものを測定します。今回使用するメジャー名は以下のとおりです。
cpu_utilizationmemory_utilizationswap_utilizationdisk_utilization
メジャータイプは、すべて DOUBLE に設定します。
モニタリングアプリケーションには Python を使用しています。モニタリング情報を収集するため、以下を使ってインストールできる psutil モジュールを使用します。
以下は、collect.py アプリケーションのコードです。
import time
import boto3
import psutil
from botocore.config import Config
DATABASE_NAME = "MyDatabase"
TABLE_NAME = "MyTable"
COUNTRY = "UK"
CITY = "London"
HOSTNAME = "MyHostname" # You can make it dynamic using socket.gethostname()
INTERVAL = 1 # Seconds
def prepare_record(measure_name, measure_value):
record = {
'Time': str(current_time),
'Dimensions': dimensions,
'MeasureName': measure_name,
'MeasureValue': str(measure_value),
'MeasureValueType': 'DOUBLE'
}
return record
def write_records(records):
try:
result = write_client.write_records(DatabaseName=DATABASE_NAME,
TableName=TABLE_NAME,
Records=records,
CommonAttributes={})
status = result['ResponseMetadata']['HTTPStatusCode']
print("Processed %d records.WriteRecords Status: %s" %
(len(records), status))
except Exception as err:
print("Error:", err)
if __name__ == '__main__':
session = boto3.Session()
write_client = session.client('timestream-write', config=Config(
read_timeout=20, max_pool_connections=5000, retries={'max_attempts': 10}))
query_client = session.client('timestream-query')
dimensions = [
{'Name': 'country', 'Value': COUNTRY},
{'Name': 'city', 'Value': CITY},
{'Name': 'hostname', 'Value': HOSTNAME},
]
records = []
while True:
current_time = int(time.time() * 1000)
cpu_utilization = psutil.cpu_percent()
memory_utilization = psutil.virtual_memory().percent
swap_utilization = psutil.swap_memory().percent
disk_utilization = psutil.disk_usage('/').percent
records.append(prepare_record('cpu_utilization', cpu_utilization))
records.append(prepare_record(
'memory_utilization', memory_utilization))
records.append(prepare_record('swap_utilization', swap_utilization))
records.append(prepare_record('disk_utilization', disk_utilization))
print("records {} - cpu {} - memory {} - swap {} - disk {}".format(
len(records), cpu_utilization, memory_utilization,
swap_utilization, disk_utilization))
if len(records) == 100:
write_records(records)
records = []
time.sleep(INTERVAL)collect.py アプリケーションを起動します。100 レコードごとに、データが MyData テーブルに書き込まれます。
これで、取り込まれたデータに基づいて自動的に更新される MyData テーブルのスキーマが Timestream コンソールに表示されるようになります。
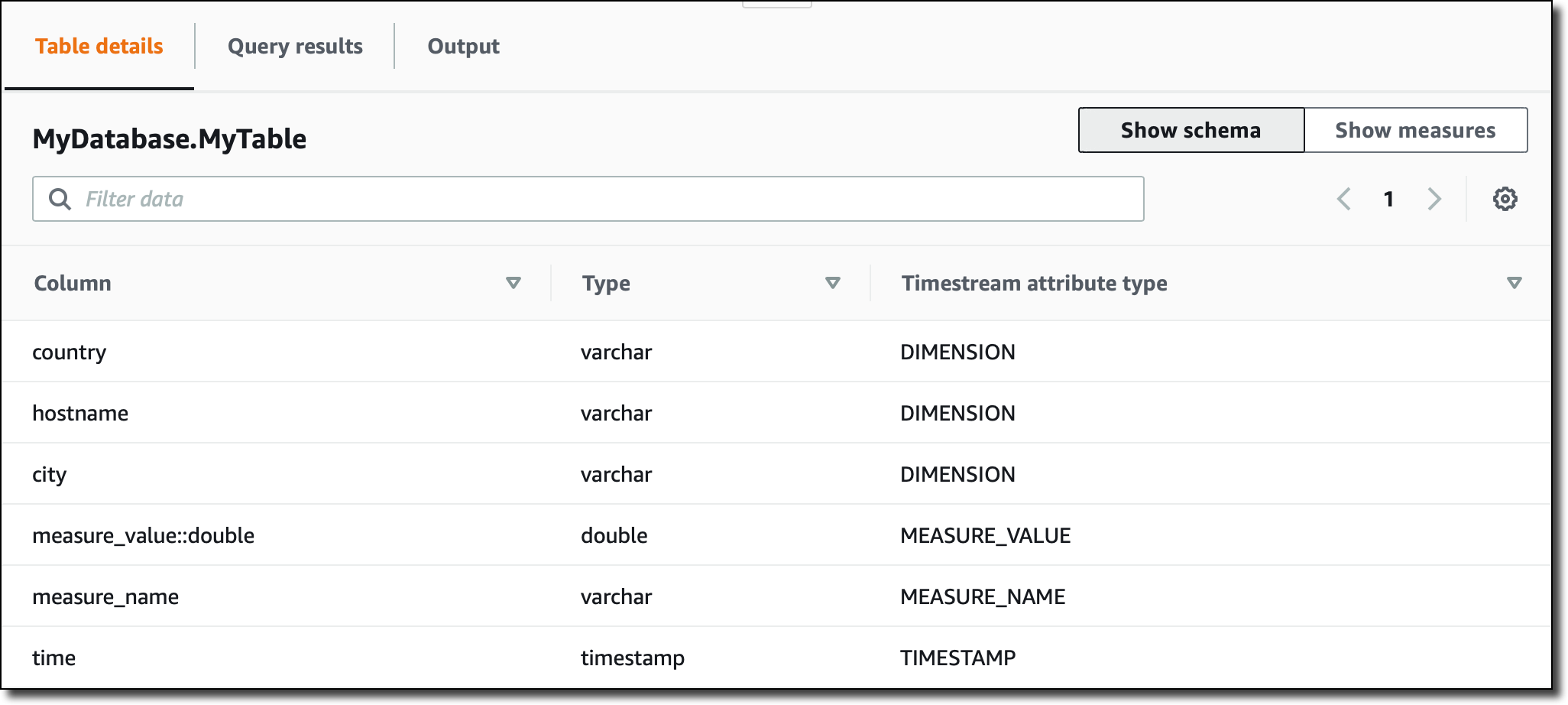
テーブル内のすべてのメジャーは DOUBLE タイプであるため、measure_value::double 列にそれらのすべての値が含まれていることに注意してください。メジャーが異なるタイプ (例えば、INT または BIGINT) であった場合は、より多くの列 (measure_value::int および measure_value::bigint など) が表示されます。
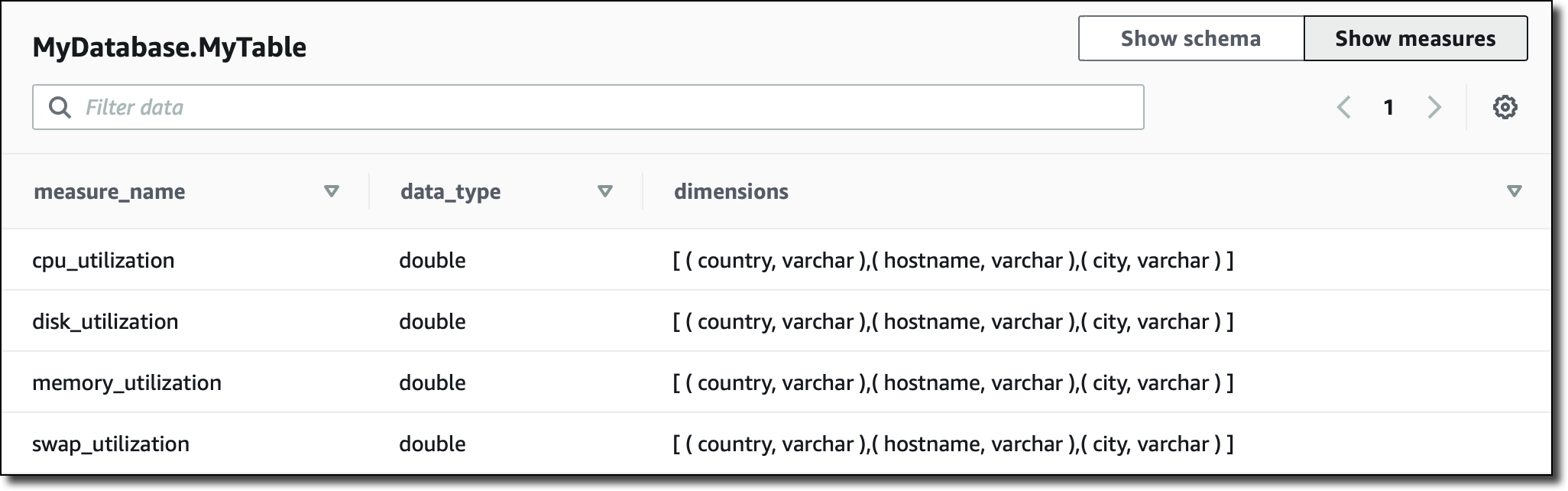
コンソールには、テーブルになるメジャーの種類、それらに対応するデータタイプ、およびその特定のメジャーに使用されたディメンションの要約も表示されます。
コンソールからのデータのクエリ
時系列データは、SQL を使用してクエリできます。メモリストアは高速のポイントインタイムクエリ向けに最適化されており、マグネティックストアは高速の分析クエリ向けに最適化されていますが、クエリでは、クエリでデータの場所を指定しなくても、すべてのストア (メモリとマグネティック) のデータが自動的に処理されます。
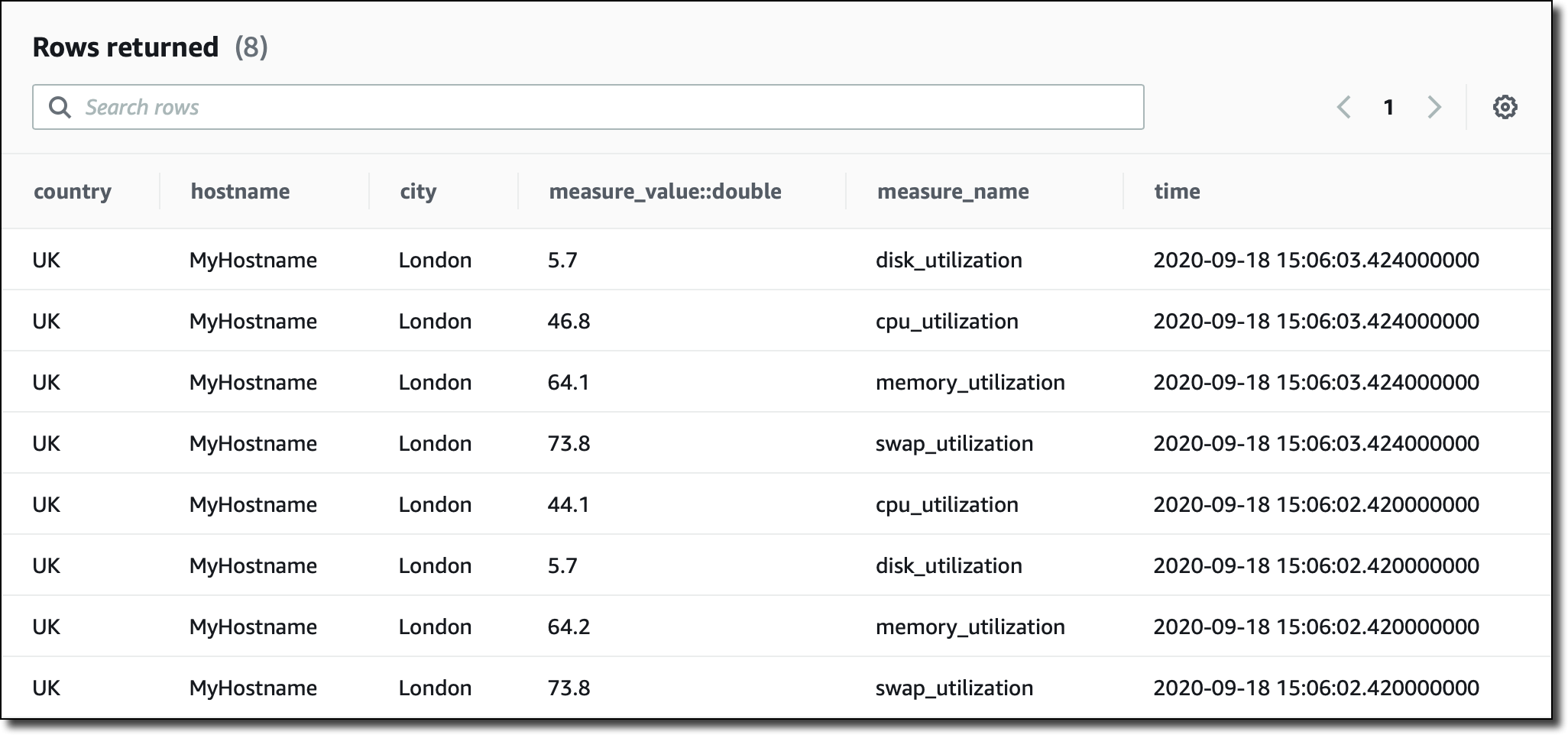
今回のクエリはコンソールから直接実行しますが、JDBC 接続を使用してクエリエンジンにアクセスすることもできます。基本的なクエリから始めて、テーブル内の最近のレコードを表示します。
もう少し複雑なクエリを試してみましょう。ホスト名ごとに集計された CPU の平均的な使用状況を、過去 2 時間、5 分間隔で表示したいと思います。レコードを measure_name のコンテンツに基づいてフィルタリングします。関数 bin() を使用して時間を間隔サイズの倍数に丸め、関数 ago() を使用してタイムスタンプを比較します。
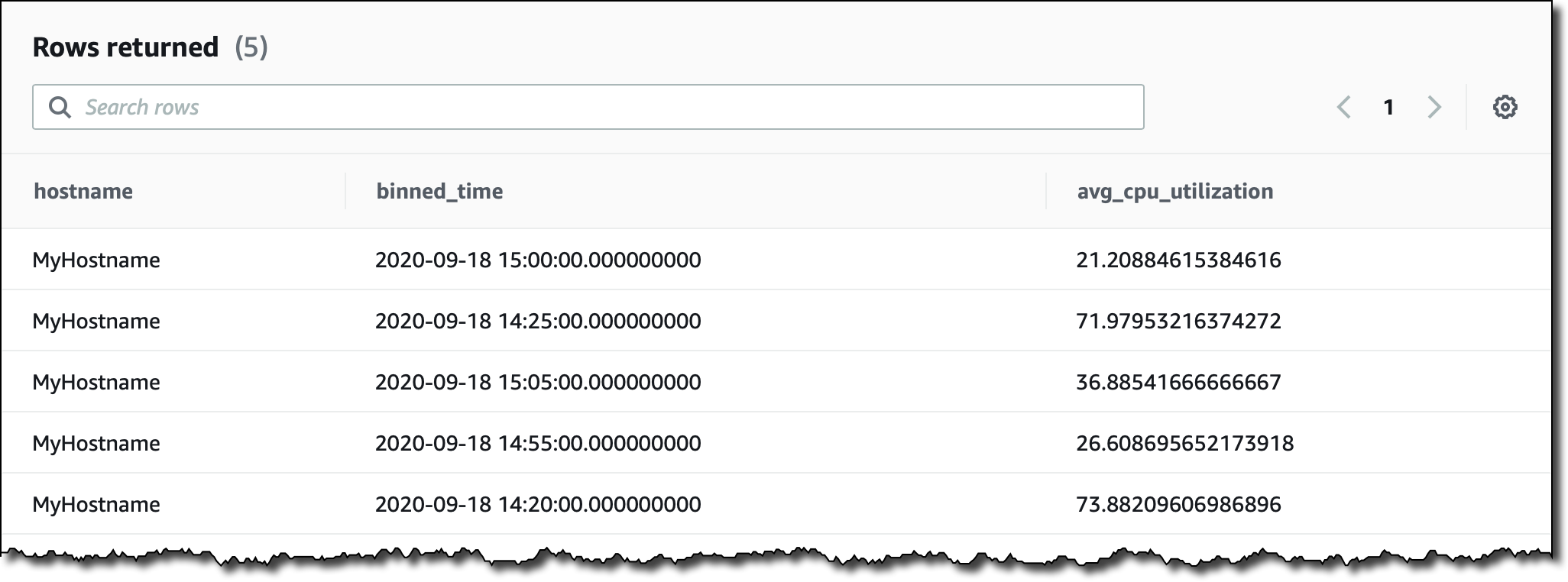
時系列データを収集するときは、値がいくらか欠落する場合があります。これは、特に分散型アーキテクチャと IoT デバイスで極めて一般的に発生します。Timestream には、欠損値を埋めるために使用できる興味深い関数がいくつかあります。例えば、線形補間を使用する関数、または LOCF (Last Observation Carried Forward) に基づく関数などです。
より一般的に、Timestream は、数式の使用、文字列、アレイ、およびデータ/時間値の操作、正規表現の使用、および集計/ウィンドウでの作業を行うために役立つ多数の関数を提供します。
Timestream で実行できることを体験するには、サンプルデータベースを作成して、AWS が提供する 2 つの IoT と DevOps のデータセットを追加します。その後、コンソールのクエリインターフェイスでサンプルクエリを表示して、より高度な機能をいくつかご覧ください。

Grafana と Amazon Timestream の併用
Timestream の最も興味深い側面のひとつは、多くのプラットフォームとの統合です。例えば、Grafana 7.1 以降を使用して時系列データを視覚化し、アラートを作成することができます。Timestream プラグインは、Grafana のオープンソースエディションの一部です。
データベースに新しい GrafanaDemo テーブルを追加し、別のサンプルアプリケーションを使用してデータを継続的に取り込みます。このアプリケーションは、数千ものホストで実行されているマイクロサービスアーキテクチャから収集されたパフォーマンスデータをシミュレートします。
Amazon Elastic Compute Cloud (EC2) インスタンスに Grafana をインストールし、Grafana CLI を使用して Timestream プラグインを追加します。
SSH Port Forwarding を使用して、ラップトップから Grafana コンソールにアクセスします。
Grafana コンソールで、適切な AWS 認証情報、および Timestream のデータベースとテーブルを使ってプラグインを設定します。これで、パフォーマンスデータが継続的に収集される GrafanaDemo テーブルを使用して、Timestream プラグインの一部として配布されたサンプルダッシュボードを選択することができるようになります。

今すぐご利用いただけます
Amazon Timestream は、本日から米国東部 (バージニア北部)、欧州 (アイルランド)、米国西部 (オレゴン)、および米国東部 (オハイオ) でご利用いただけます。Timestream は、コンソール、AWS コマンドラインインターフェイス (CLI)、AWS SDK、および AWS CloudFormation で使用できます。Timestream では、書き込み数、クエリによってスキャンされたデータ、使用したストレージに基づく料金をお支払いいただきます。詳細については、料金ページを参照してください。
このリポジトリには、さらに多くのサンプルアプリケーションがあります。詳細については、ドキュメントを参照してください。データの取り込み、保持、アクセス、ストレージの階層化など、時系列での作業がかつてないほど容易に実行できるようになりました。この新機能を使って何を構築するのかをぜひお教えください!
— Danilo