Amazon Web Services ブログ
Amazon DocumentDB のスケーリング (MongoDB 互換性あり)、パート 1: 読み込みのスケーリング
Amazon DocumentDB (MongoDB 互換) は、MongoDB のワークロードをサポートする、高速かつスケーラブルで可用性に優れたフルマネージド型のドキュメントデータベースサービスです。Amazon DocumentDB で、MongoDB で使用しているものと同じアプリケーションコードを実行し、同じドライバー、およびツールを使うことができます。この記事では、Amazon DocumentDB の最新クラウドネイティブデータベースアーキテクチャにより、クラスターの読み込みスループットを従来のアーキテクチャよりも高速かつ柔軟にスケーリングできる方法を示します。この記事では、Amazon DocumentDB クラスターへの接続とそこからの読み込みに関する推奨事項も提供されます。
Amazon DocumentDB クラウドネイティブアーキテクチャ
従来のモノリシックなデータベースとは異なり、Amazon DocumentDB のクラウドネイティブアーキテクチャは、ストレージとコンピューティングを分離しています。Amazon DocumentDB クラスターは、分散ストレージボリュームと、ストレージボリュームからデータを読み書きする 1 つ以上のコンピューティングインスタンスで構成されます。次の図は、1 つのプライマリインスタンスと 2 つのレプリカインスタンスを持つ Amazon DocumentDB クラスターを示しています。

コンピューティングインスタンスがリクエストを処理し、クラスターのストレージボリュームはすべてのデータのコピーを 6 つ (3 つのアベイラビリティーゾーンでそれぞれ 2 つのコピー) を維持することで耐久性を提供します。このアーキテクチャは、読み込みおよび書き込み操作用の単一のプライマリインスタンスと、読み込み操作用の最大 15 個の読み込みレプリカを提供し、1 秒あたり数百万回の読み込みにスケーリングします。
Amazon DocumentDB インスタンスにはデータが含まれていないうえに、新しいインスタンスを追加するときにデータをコピーする必要がないため、クラスターに新しいインスタンスをすばやく追加および削除できます。保存されているデータの量に関係なく、新しいレプリカインスタンスを追加し、既存のインスタンスのサイズを数分で変更することができます。新しいインスタンスは通常 8〜10 分でプロビジョニングされ、アクティブになるとすぐにクエリを処理できるようになります。Amazon DocumentDB の完全マネージド型のアプローチは、このアーキテクチャを利用して、ハードウェア障害が発生した場合にインスタンスをすばやく置き換えます。その結果、従来のデータベースアーキテクチャよりもはるかに迅速に回復できます。
Amazon DocumentDB エンドポイント
Amazon DocumentDB は、3 種類のエンドポイントをサポートしています。
- クラスターエンドポイント – クラスターの現在のプライマリインスタンスに接続します。読み込みおよび書き込み操作に使用できます。これは通常、クラスターに接続するときに推奨されるエンドポイントです。
- リーダーエンドポイント – クラスター内のすべての使用可能なレプリカ間で読み込み専用接続の負荷を分散します。データベースドライバーはクラスター全体で読み込みのバランスを取るのに優れたジョブであるため、リーダーエンドポイントを使用しないでください。
- インスタンスエンドポイント – クラスター内の特定のインスタンスに接続します。これは、特定のレプリカインスタンスにのみ影響を与えたい特殊なワークロードに役立ちます。
次の図は、これらのエンドポイントのアーキテクチャを示しています。
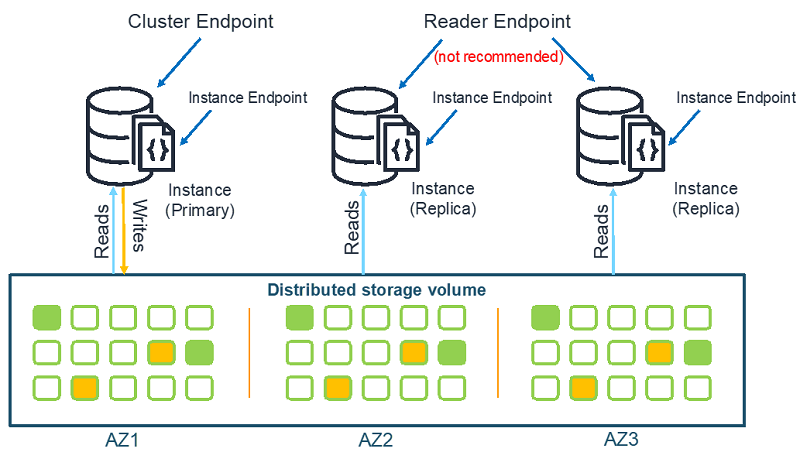
フェイルオーバーイベントにより、インスタンスのプライマリまたはレプリカとしてのロールが変わる可能性があるため、アプリケーションでは、特定のインスタンスエンドポイントがプライマリインスタンスであると想定してはいけません。
ドライバーがクラスタートポロジの変更を自動的に検出できるように、クラスターエンドポイントを使用し、レプリカセットとして Amazon DocumentDB クラスターに接続する必要があります。
レプリカセットとしての接続
Amazon DocumentDB は MongoDB レプリカセットのエミュレーションをサポートしているため、ドライバーはクラスターのトポロジー (たとえば、クラスター内にあるインスタンスの数、プライマリとレプリカはどちらか)、およびこのトポロジーで進行中の変更を自動的に検出し、好みに応じて読み込みを分散できます。この記事ではこの機能を実証するために、Amazon EC2 インスタンスから Python プログラムを使用してレプリカセットとして Amazon DocumentDB クラスターに接続し、クラスターのトポロジを変更して、プログラム出力の変更を確認する方法を説明します。
Amazon DocumentDB クラスターには VPC 内でのみアクセスできるため、この記事ではクラスターと同じ VPC 内の EC2 インスタンスを使用します。VPC の外部からクラスターにアクセスする場合は、VPC ピアリング、VPN、SSH トンネリングなどの手段を介して接続を有効にする追加の手順を実行する必要があります。詳細については、Amazon VPC の外部から Amazon DocumentDB クラスターに接続するを参照してください。
このユースケースでは、複数の AZ にデプロイされた 2 つのインスタンスを含む、デフォルト設定で作成された Amazon DocumentDB クラスターを使用します。クラスターの作成に関する詳細については、Amazon DocumentDB の使用開始を参照してください。また、クラスターと同じ VPC で EC2 インスタンスを使用します。EC2 インスタンスの作成については、Amazon EC2 の使用開始を参照してください。
EC2 インスタンスを作成してログインした後、次の Python プログラムを実行して、レプリカセットとしてクラスターに接続し、クラスターメンバーを 1 分ごとに 1 回印刷できます。
レプリカセットとして接続するために、スクリプトはクラスターエンドポイントを使用し、レプリカセット名 rs0 を接続文字列に含めます。接続エラーが発生した場合は、セキュリティグループの設定を確認して、EC2 インスタンスからクラスターへの適切な接続が許可されていることを確認できます。詳細については、Amazon DocumentDB のトラブルシューティングを参照してください。
スクリプトを実行して、スクリプトがクラスターに接続し、プライマリインスタンスと SECONDARY として表示される 1 つのレプリカを識別したことを確認できます。これは、次の出力で示されています。
これで、クラスターにセカンダリレプリカを追加し、アクティブになったときにクライアントがレプリカを自動的に検出することを確認できます。レプリカをクラスターに追加するには、以下の手順を実行します。
- Amazon DocumentDB コンソールで、ご使用のクラスターを選択します。
- [アクション] ドロップダウンメニューから、[インスタンスの追加] を選択します。

- [インスタンス識別子] に、インスタンス名を入力します。
- [インスタンスクラス] に、適切なクラスを入力します。この記事では、デフォルトオプションの r5.large を使用しています。
- [プロモーションティア] は、デフォルトである [指定なし] のままにしておきます。
- [作成] を選択します。

新しく追加されたレプリカインスタンスは、通常 10 分未満で利用可能になります。次の出力に示すように、プログラムの出力では新しいレプリカが自動的に検出されました。
このユースケースから分かるように、インスタンスをスケールアウトまたはスケールイン (リードレプリカを追加または削除)、スケールアップまたはスケールダウン (インスタンスのサイズを変更) すると、MongoDB ドライバーは、クラスターのトポロジ内で行われたこれらの変更を自動的に検出します。追加の作業を行う必要はありません。
読み込み設定
Amazon DocumentDB にレプリカセットとして接続する場合、接続文字列で読み込み設定を指定して、アプリケーションがクラスター内のインスタンス間でアプリケーションからの読み込みリクエストをルーティングする方法を決定できます。
5 つの読み込み設定オプションから選択できます。
- primary –
primary読み込み設定を指定すると、すべての読み込みがクラスターのプライマリインスタンスに確実にルーティングされます。プライマリインスタンスが使用できない場合、読み込み操作は失敗します。 - primaryPreferred –
primaryPreferred読み込み設定を指定すると、通常の操作で読み込みがプライマリインスタンスにルーティングされます。プライマリフェイルオーバーがある場合、クライアントはリクエストをレプリカにルーティングします。 - secondary –
secondary読み込み設定を指定すると、読み込みはレプリカにのみルーティングされ、プライマリインスタンスにはルーティングされません。クラスターにレプリカインスタンスがない場合、読み込みリクエストは失敗します。 - secondaryPreferred –
secondaryPreferred読み込み設定を指定すると、1 つ以上のレプリカがアクティブなときに、読み込みが確実にリードレプリカにルーティングされます。クラスター内にアクティブなレプリカインスタンスがない場合、読み込みリクエストはプライマリインスタンスにルーティングされます。 - nearest –
nearest読み込み設定ルートを指定すると、クライアントと Amazon DocumentDB クラスター内のすべてのインスタンスとの間で測定されたレイテンシーのみに基づいて読み込みがルーティングされます。
詳細については、Amazon DocumentDB 読み込み設定を参照してください。
前述のコード例では、readPreference=secondaryPreferred を使用しています。レプリカセットとして接続するときに secondaryPreferred 読み込み設定を指定することは、Amazon DocumentDB で推奨されるアプローチです。詳細な推奨事項については、Amazon DocumentDB の推奨事項を参照してください。
secondaryPreferred 読み込み設定を使用することにより、クライアントは読み込みクエリをレプリカに自動的にルーティングし、クエリをプライマリインスタンスに書き込みます。これにより、プライマリインスタンスが大量の書き込みを処理できるようになるため、クラスターリソースをより適切に使用できます。クラスターにリードレプリカがない場合 (たとえば、単一ノードクラスター、または一時的に問題が発生する単一のリードレプリカを持つクラスター)、secondaryPreferred 読み込み設定を使用すると、クライアントは読み込みトラフィックのプライマリインスタンスに自動的にフォールバックします。
Amazon DocumentDB レプリカからの読み込みは、結果整合性があります。アプリケーションが読み込み後の書き込み整合性を必要とするユースケースがあり、これは Amazon DocumentDB のプライマリインスタンスからのみ提供できます。これらの使用例では、アプリケーションで 2 つのクライアント接続プールを作成できます。1 つは書き込み後の読み込み整合性を必要とする書き込みと読み込み用 (readPreference=primary) で、もう 1 つは結果整合性のある読み込み用 (readPreference=secondaryPreferred) です。または、特定のコレクションの読み込み設定を上書きすることもできます。詳細については、複数の接続プールを参照してください。
まとめ
この記事では、Amazon DocumentDB 独自のアーキテクチャを使用して、読み込みトラフィックをレプリカインスタンスにルーティングすることで、クラスターのスループットをスケーリングする方法を示しました。このようなアプローチを最大限に活用するには、MongoDB ドライバーの組み込み機能を使用して、レプリカセットとしてクラスターに接続し、適切な読み込み設定を行う必要があります。
著者について

Leonid Koren はアマゾン ウェブ サービスのソリューションアーキテクトです。AWS のお客様と協力して、セキュアで回復力があり、かつスケーラブルで高性能なアプリケーションをクラウドに展開するのを支援しています。

Jeff Duffy は、アマゾン ウェブ サービスのシニア NoSQL スペシャリストソリューションアーキテクトです。