Amazon Web Services ブログ
AWS Systems Managerフリートマネージャーを活用してWindowsワークロードの問題をトラブルシューティングする
クラウドの運用担当エンジニアは、利用料金を予算内に抑えつつ、多数のAmazon Elastic Compute Cloud(Amazon EC2)インスタンスの状態を健全に保つために問題を監視・追跡・解決できる仕組みを構築しなければなりません。つまり、コストとシステム安定性の両面で責任を持つことになります。このブログでは、AWS Systems Managerの新機能であるフリートマネージャーと共にOpsCenterとAmazon CloudWatchを活用し、大規模環境で発生する運用上の問題をすばやく検知・追跡・解決できる方法をご紹介します。
ここでは、CI/CDパイプラインのコードリポジトリとして、多数のAmazon EC2インスタンス(以下「EC2フリート」)を運用しているシナリオを仮定します。このワークロードは、「T3」や「T4」といった低コストのバーストパフォーマンスインスタンスを利用しています。これらのインスタンスは通常は基本的なレベルのCPUパフォーマンスを提供しながら、いつでも必要な時にCPU性能をバーストして利用することが可能です。
今回のシナリオでは、グローバル規模でデプロイされたCI/CDパイプラインの数が増えるにつれ、それを支えるEC2インスタンスの負荷も上がっていったと想定します。去年のある週末、グローバルのマルチプラットフォームアプリケーションをデプロイしている際に、多くのEC2インスタンスが基準値以上のCPUバースト利用を余儀なくされました。その結果として、ワークロードの運用コストが25%増加してしまいました。
前提条件
ここから先の手順を実践する場合は、CloudWatchアラームの作成・Systems Manager OpsItemへのアクセス・Systems Manager Session ManagerまたはAWS Cloudshellを利用したCLIコマンドの実行が可能なIAM権限を持つユーザーでAWS管理コンソールにアクセスできることを事前に確認してください。各EC2インスタンスは、適切なインスタンスプロファイルが割り当てられておりSystems Managerのエンドポイントと連携が可能な状態になっている必要があります。
EC2フリートをCloudWatchアラームで監視する
この記事では、バーストパフォーマンスインスタンスで構成されたEC2フリートを、CloudWatchアラームの作成を通じて監視し、フリートマネージャーを利用してトラブルシューティングする一連の流れをご紹介します。アラーム作成の際には、それをきっかけにしっかりとしたアクションをとるようにできることが重要です。基準値以上のCPU使用率を検知するためには、CPUUtilizationメトリクスを利用することを思いつくかもしれません。しかし基準値となるvCPU毎の使用率は、5%~40%という具合にインスタンスサイズによってばらばらです。適当なしきい値を設定してしまうと、アラームの発報が少なすぎる、または多すぎる結果になってしまうかもしれません。
この場合は、CPUCreditBalanceの方がもっと適切なメトリクスです。CPUクレジットの残高がゼロに近づいたらアラームが発報されるように設定することができます。この場合、しきい値を「5」等に設定することによって、CPUクレジットを余分に利用し始める前に問題を解決できるリードタイムを確保することができます。
大規模にアラームを設定する
理想的には、RunInstance APIコールがAWS CloudTrailに送信される度にAmazon EventBridge経由でAWS Lambda関数をトリガーすることにより、このアラームをすべてのバースト可能なEC2インスタンスタイプに対して適用したいところです。Lambda関数はAWS SDK for Python(Boto3)内のput_metric_alarm APIアクションをコールすることで、この構成を実現できます。もっと詳細な情報は、Boto3ドキュメント内のcreating alarms in Amazon CloudWatchパートをご参照ください。
ここでは簡略なデモが目的のため、AWSコマンドラインインタフェース(AWS CLI)を利用し単一のインスタンスに対してアラームを設定する方法のみをご紹介します。認証情報が設定されているAWS CLIのプロンプト上で、put-metric-alarmコマンドを発行しJSON形式の入力ファイルを指定します:
aws cloudwatch put-metric-alarm --cli-input-json file://put_metric_alarm.json
JSONファイルの中身からは、[ACCOUNT_ID]と[INSTANCE_ID]をご自身の環境の値に差し替えてください:
{
"AlarmName": "[INSTANCE_ID]-BurstableInstanceCPUCreditBalanceLow",
"AlarmDescription": "Burstable instance type cpu credit balance approaching zero",
"ActionsEnabled": true,
"AlarmActions": [
"arn:aws:ssm:us-east-1:[ACCOUNT_ID]:opsitem:2#CATEGORY=Cost"
],
"MetricName": "CPUCreditBalance",
"Namespace": "AWS/EC2",
"Statistic": "Average",
"Dimensions": [
{
"Name": "InstanceId",
"Value": "[INSTANCE_ID]"
}
],
"Period": 300,
"EvaluationPeriods": 1,
"Threshold": 5,
"ComparisonOperator": "LessThanThreshold"
}
アラームが正常に作成されたことを確認する
- Amazon CloudWatchコンソールを開き、左側のナビゲーションからアラームを選択します。
- 「[INSTANCE_ID]-BurstableInstanceCPUCreditBalanceLow」というアラームを探し、選択します。
- アクション配下に、図1のようにSystems Managerのアクションが表示されていることを確認します。

図1. Systems Managerアクションを確認する
- しばらく経つと、図2のようにアラームのステータスがOKに変更されます。
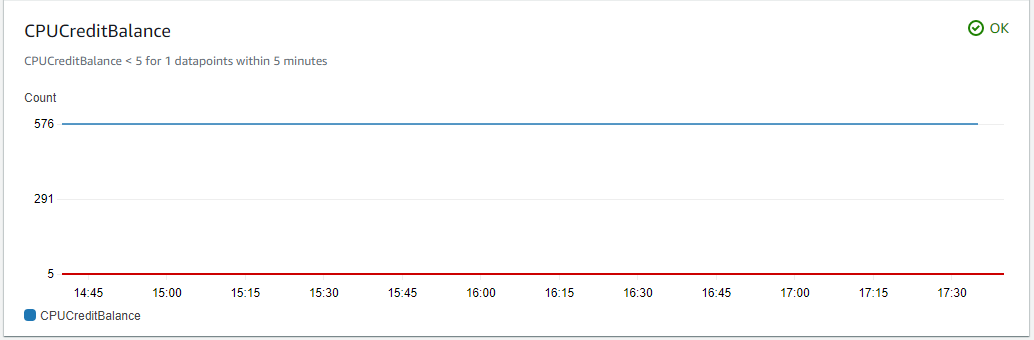
図2. ステータスがOKになったCPUCreditBalanceアラーム
Systems Manager OpsCenterでOpsItemを管理する
CloudWatchアラームが発報されると、Open状態のOpsItemが新たに作成され、運用エンジニアによるレビューと解決が求められます。さらに詳細な情報は、AWS Systems ManagerユーザーガイドのOpsItemの使用セクションをご参照ください。
ワークロードに対する負荷を再現し、アラームを発報させる
このシナリオでは、数時間に渡って実行されたPowerShellスクリプトがCPUクレジットの残高をしきい値以下になるまで消費しており、アラームが発報されています。図3はOpen状態のOpsItemが新たに作成されている様子を表しています。
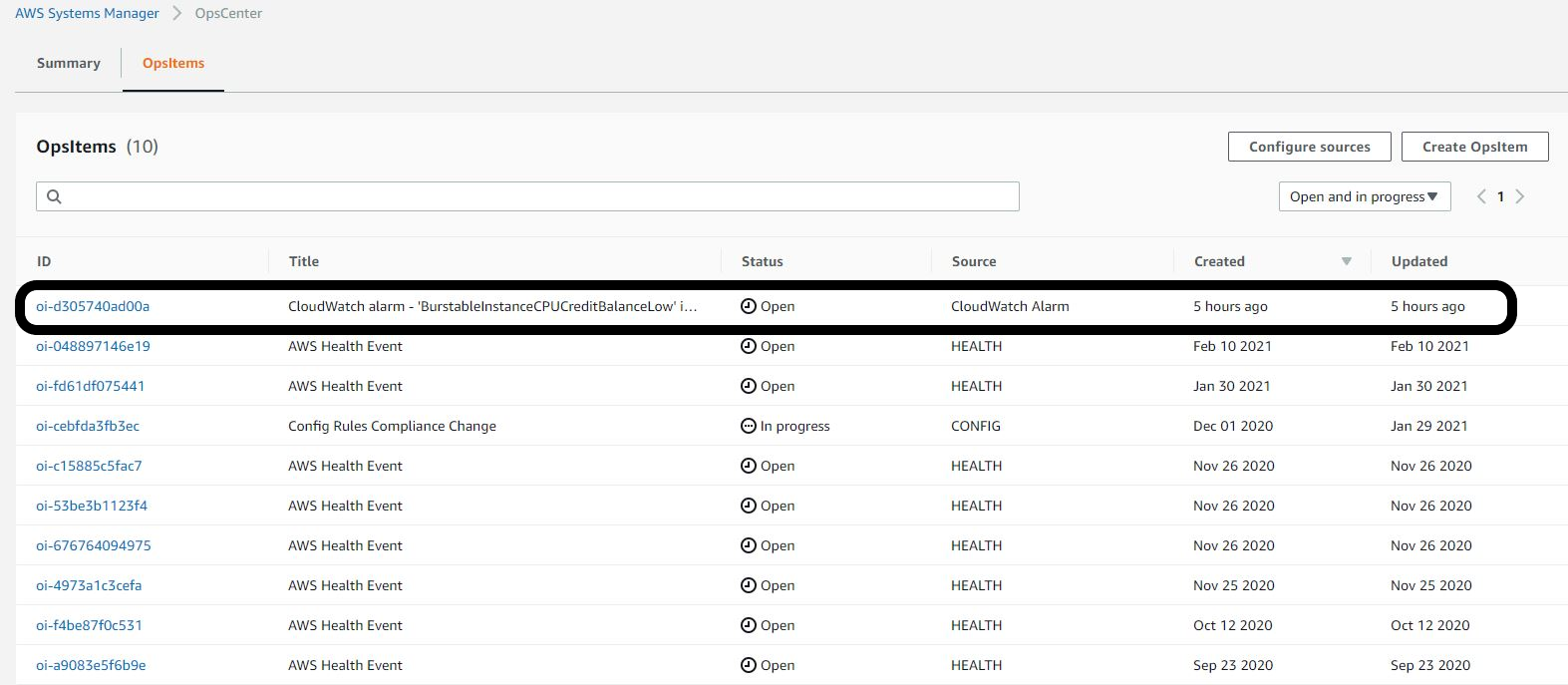
図3: アラーム発報により作成されたOpsItem
フリートマネージャーを利用し問題をトラブルシューティングする
フリートマネージャーは、システム管理者がSSHやRDPのリモート接続を行う必要なく、OSの種類を気にせず、一つの場所からマネージドインスタンスを参照・管理することを可能にしてくれます。ファイルシステム・Windowsレジストリ・パフォーマンスカウンター・Session Managerの機能を利用し、EC2またはオンプレミスのマネージドインスタンスの問題をトラブルシューティングし解決することができます。
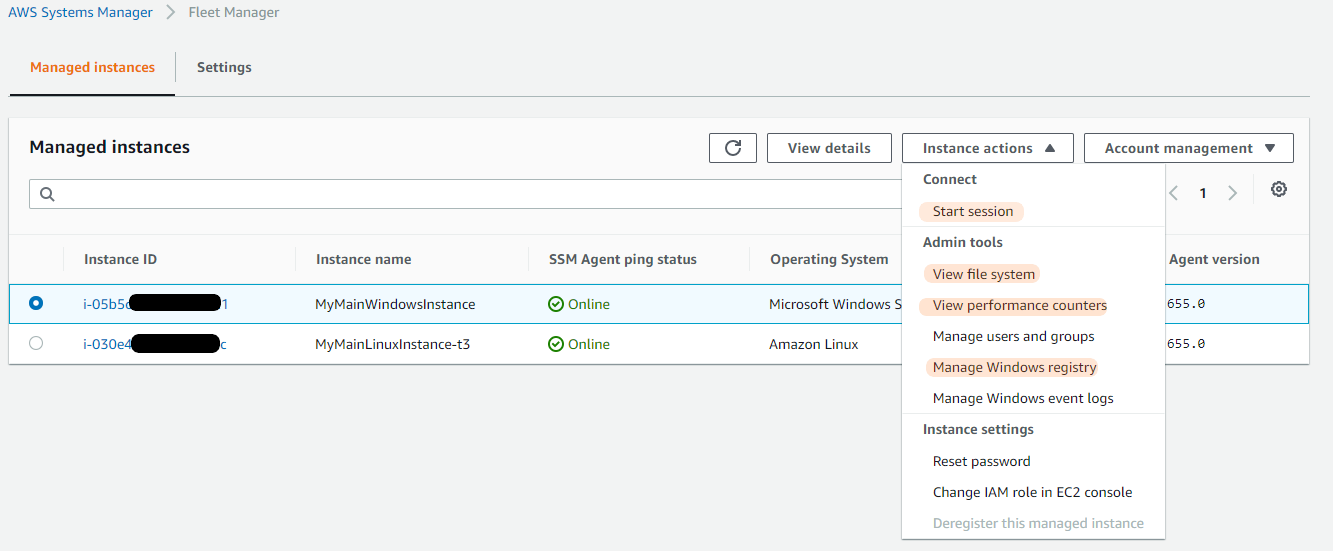
図4. Windowsインスタンスの場合利用可能なフリートマネージャーのインスタンスアクション
マネージドインスタンスの画面にて、インスタンスアクションからパフォーマンスカウンターの表示を選択します。CPU使用率・ディスクI/O・ネットワークトラフィック・メモリ使用量等のメトリクスに関する直近1分間のリアルタイムデータが表示されます。図5によると、CPU使用率は高止まりしたままになっているため、原因のトラブルシューティングを続ける必要がありそうです。
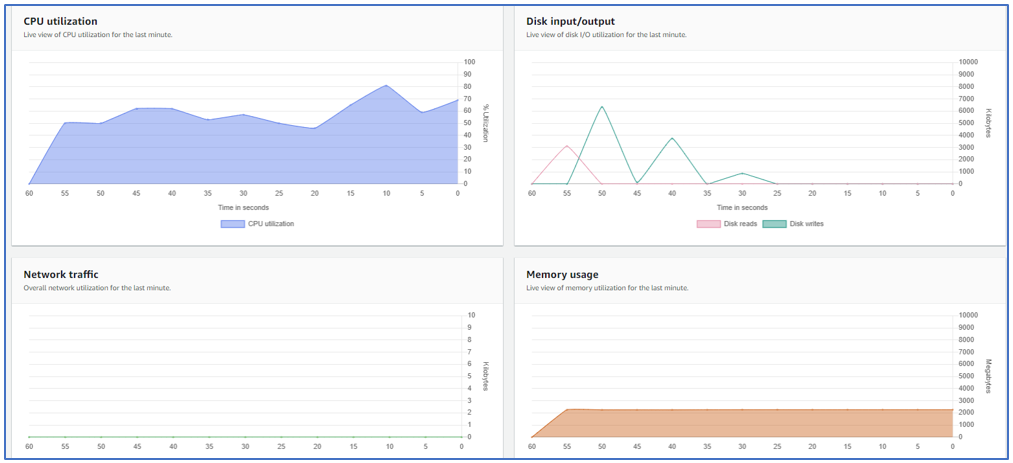
図5. 各種リアルタイムメトリクスを表示するパフォーマンスカウンター
トラブルシューティングの一環として、ファイルシステムのオブジェクトをブラウズしてそれらのプロパティ(例:更新日時・ファイルタイプ・パーミッションモード・サイズ等)を参照することができます。ファイルの中身を最大10,000行まで参照したりtailすることもできます。

図6. ファイルシステムをブラウズしファイルのプロパティを参照する
RDPポートを開放したり、踏み台サーバーを利用することなくフリートマネージャーからPowerShellセッションを開始することもできます。過度なCPU使用の原因を探るためのコマンドを実行するには非常に便利な方法です。
インスタンスに対して新しいPowerShellセッションを開始するには、インスタンスアクションからセッションを開始を選択します。フリートマネージャーがSystems Manager Session Managerを呼び出し、サーバーへの接続を確立します。
これで、PowerShellコマンドを実行し高いCPU使用率の原因を突き止める準備ができました。Session Managerを利用する際のセッションデータは、図7の上部に示されているようにAWS Key Management Service(AWS KMS)によって暗号化されます。
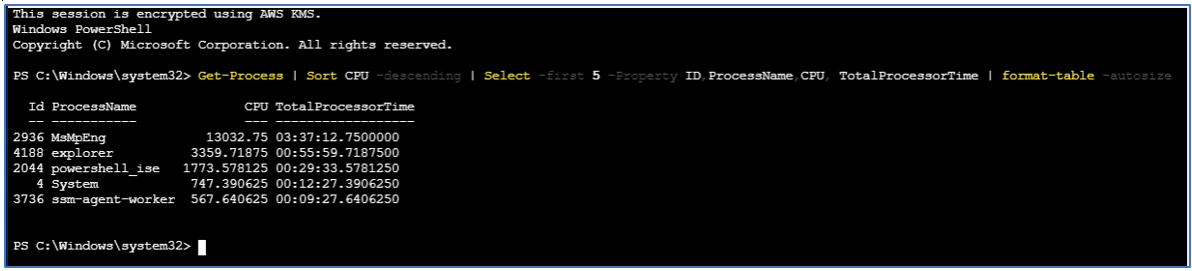
図7. Session ManagerからPowerShellコマンドを実行する
最も多くのCPU時間を消費している上位5つのプロセスの一覧を見てみると、プロセスID「2044」のものが目立ちます。このPowerShellプロセスは30分近くのCPU時間を消費しています。図8にあるように、ID 2044のプロセスの既存セッションに対話型で参加できるようPowerShellコマンドを実行し、デバッグモードを通じて実行中のスクリプトのフルパスを確認します。
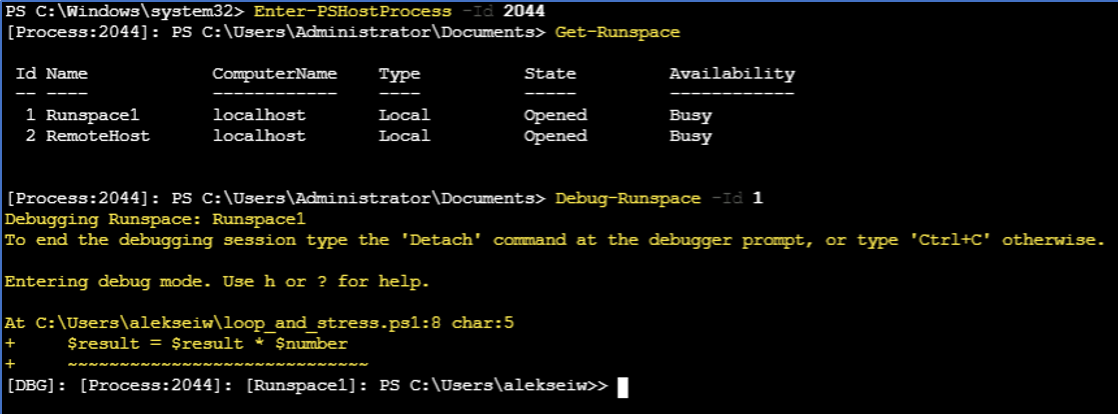
図8. PowerShellコマンドを実行し、問題のスクリプトのフルパスを確認する
そこから、図9にあるようにフリートマネージャーの機能を利用し実行中のスクリプトの内容をプレビューすることができます。
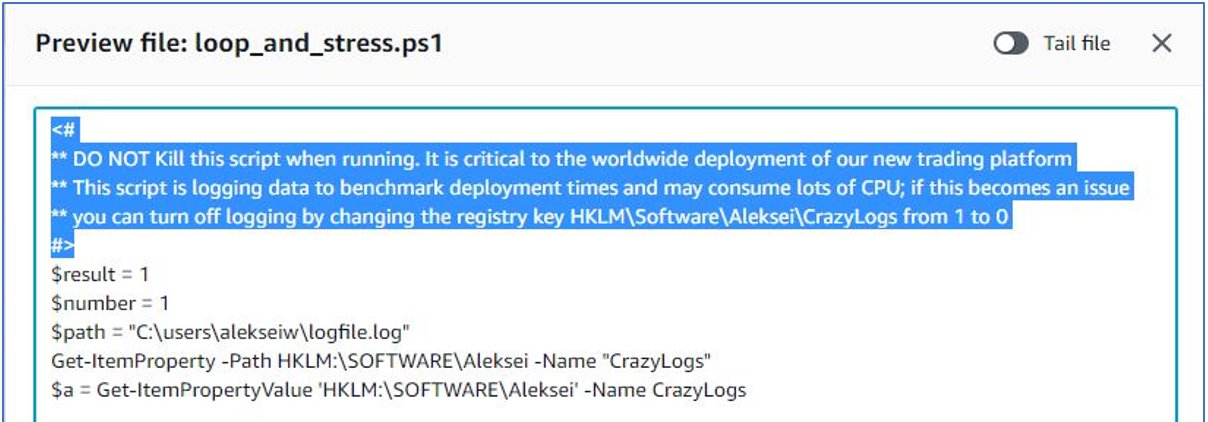
図9. フリートマネージャーを利用しファイルの中身を最大10,000行までプレビューする
スクリプトの作者がコメントセクションに問題解決のための有用な情報を提供してくれています。過度なログ出力が高いCPU使用を誘発しており、これはWindowsレジストリキーを変更することによって無効化することができます。図10にあるように、フリートマネージャーから直接このインスタンスのレジストリキーを変更することもできますが、それよりもCI/CDワークロードを構成するすべてのEC2インスタンスに対して同じことを実施できた方がいいでしょう。
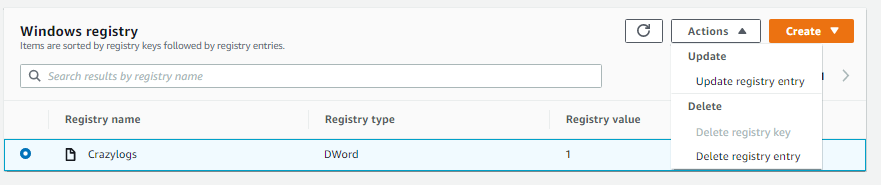
図10. フリートマネージャーのアクションにおけるレジストリキー更新機能
AWS Systems Manager Run Commandの、複数インスタンスをターゲットに設定できる機能を活用すれば、多数のEC2またはオンプレミスインスタンスのレジストリキーを安全に更新することができます。並列度とエラー数のしきい値のレート制御を設定することによって、同時に何台のインスタンスに対してコマンドを実行するか、そして何回実行の失敗が発生すれば次の新しいインスタンスへのコマンド送信を取りやめるかを管理することができます。
Run Commandの実行
- AWS Systems Managerコンソールを開き、左側のナビゲーションからドキュメントを選択します。
- 検索欄にて、「ドキュメントタイプ: コマンド」のフィルターを適用し、「SetWindows」で検索します。
図11に示されているように、「AWSFleetManager-SetWindowsRegistryValue」ドキュメントが検索結果に表示されます。
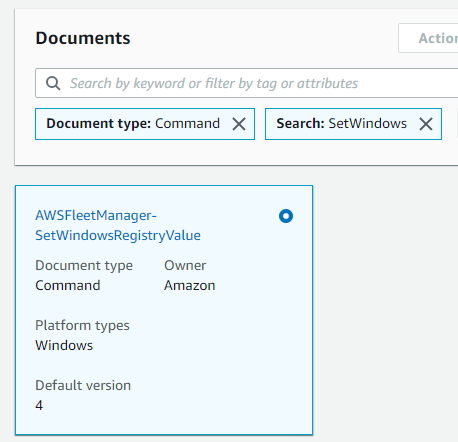
図11. Windowsレジストリキーを設定するためのSSMドキュメント
- コマンドのパラメータ設定にて、図12の通りにそれぞれの値を設定します。
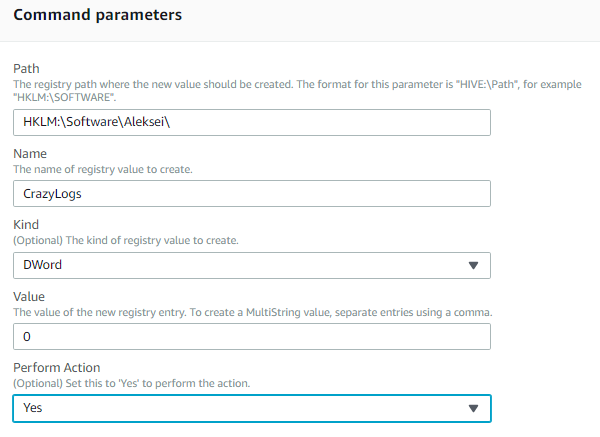
図12. SetWindowsRegistry Run Commandのパラメータ
このシナリオでは、CI/CDコードリポジトリを構成するすべてのインスタンスは既に「code-repo」:「true」というキーと値の組み合わせでタグ付けされています。
- これらのインスタンスだけをターゲットにするためには、図13に示されているようにインスタンスタグの指定を選択します。インスタンスを個別に選択したり、あらかじめ定義したリソースグループを指定することも可能です。
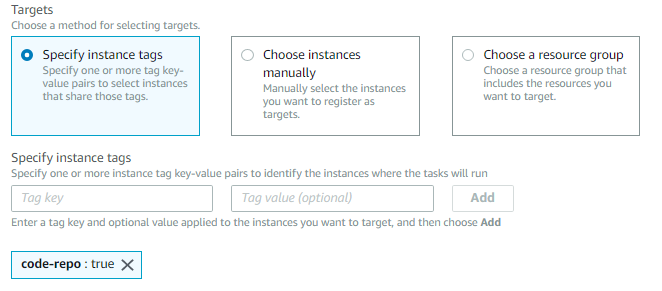
図13. インスタンスのタグを指定してターゲットを選ぶ
ドキュメントが実行され、ログ出力を無効化するためのレジストリキーが更新されるまでには数秒かかります。図14は、この変更の後にCPU使用率のパフォーマンスカウンターが急激に低下した様子を表しています。
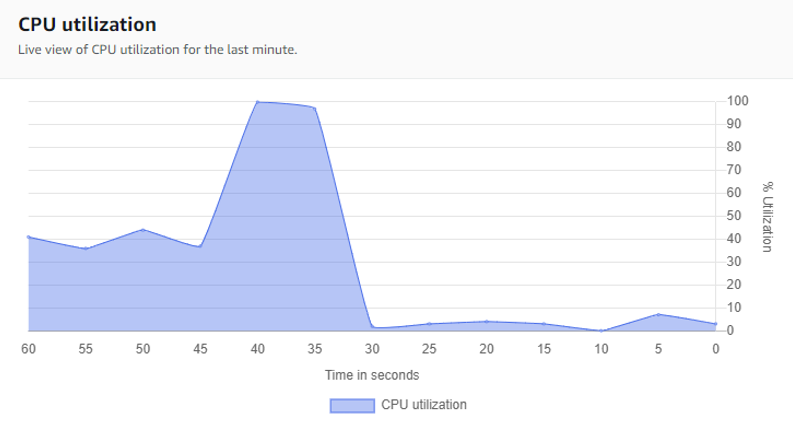
図14. 通常に戻ったCPU使用率
これで問題が解決したので、CloudWatchアラームによって作成されたOpsItemに戻り、右上のステータスの設定メニューから状態をResolved(解決済み)に変更しておくのがベストプラクティスです。
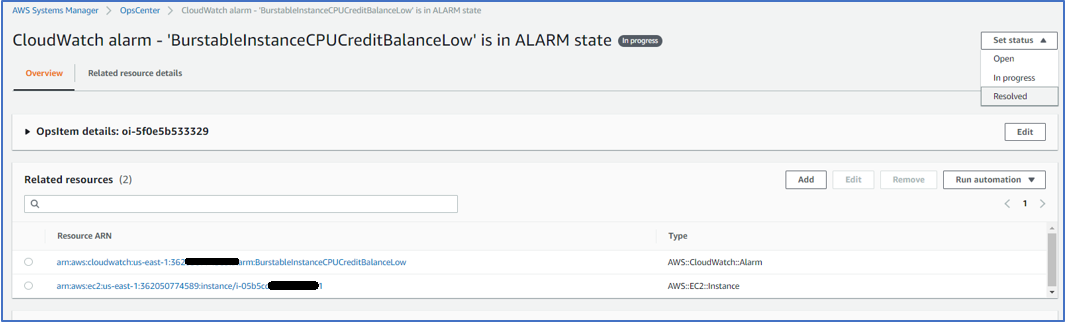
図15. OpsItemのステータスを進行中から解決済みに変更する
クリーンアップ
本ブログに書かれている手順に従って検証を実施した場合、望まない利用料金が発生しないよう、作成したEC2インスタンスやCloudWatchアラームを削除しておくようにしてください。
まとめ
このブログでは、フリートマネージャー・Session Manager・OpsCenter・CloudWatchアラームを活用し、すばやく運用上の問題を検知・追跡・トラブルシュート・解決する方法をご紹介しました。アラームを定義し、発報された場合はOpsItemを自動的に作成することによって、未解決の問題を容易に管理できるようにしました。また、RDPのポートを開放したり踏み台サーバーを利用することなく、PowerShellセッションを開始しコマンドを実行することによって問題の原因を特定しました。最後に、Windowsレジストリキーの設定等、繰り返される管理タスクを多数のインスタンスに対して実施する方法を学びました。
本投稿は Aleksei Wolffによる記事を翻訳したものです。翻訳はソリューションアーキテクトRyan Choが担当しました。
投稿者について
 Aleksei(Alex) WolffはAWS Enterprise Supportに属するシニアテクニカルアカウントマネージャーです。彼は2016年の頃からAWSテクノロジーに関わっています。Alexは普段エンタープライズのお客様が複雑なクラウドインフラストラクチャを設計・実装・サポートできるように支援しています。Alexは妻と二人の子供と一緒にNorth Carolina州Greensboroに住んでおり、仕事でお客様の支援に精を出している時以外は、ロードサイクリングで余暇を楽しんでいます。
Aleksei(Alex) WolffはAWS Enterprise Supportに属するシニアテクニカルアカウントマネージャーです。彼は2016年の頃からAWSテクノロジーに関わっています。Alexは普段エンタープライズのお客様が複雑なクラウドインフラストラクチャを設計・実装・サポートできるように支援しています。Alexは妻と二人の子供と一緒にNorth Carolina州Greensboroに住んでおり、仕事でお客様の支援に精を出している時以外は、ロードサイクリングで余暇を楽しんでいます。