Amazon Web Services ブログ
プレビュー – Amazon Bedrock のエージェントを使用して、基盤モデルを会社のデータソースに接続する
7 月に、Amazon Bedrock のエージェントのプレビューを発表しました。これは、デベロッパーが生成系 AI アプリケーションを作成してタスクを完了するための新機能です。9月13日は、エージェントを使用して基盤モデル (FM) を会社のデータソースに安全に接続する新しい機能をご紹介します。
ナレッジベースがあれば、エージェントを使用して Bedrock の FM に追加データへのアクセスを提供できます。これにより、FM を継続的に再トレーニングしなくても、モデルはより関連性が高く、コンテキスト固有の正確な応答を生成できます。ユーザーの入力に基づいて、エージェントは適切なナレッジベースを特定し、関連情報を取得し、その情報を入力プロンプトに追加します。これにより、モデルに追加のコンテキスト情報が与えられ、補完することができます。
Amazon Bedrock のエージェントは、これを実現するために検索拡張生成 (RAG) と呼ばれる概念を使用しています。ナレッジベースを作成するには、データの Amazon Simple Storage Service (Amazon S3) の場所を指定し、埋め込みモデルを選択し、ベクトルデータベースの詳細を指定します。Bedrock はデータを埋め込みに変換し、埋め込みをベクトルデータベースに保存します。次に、ナレッジベースをエージェントに追加して、RAG ワークフローを有効にできます。
ベクトルデータベースでは、Amazon OpenSearch Serverless 用ベクトルエンジン、Pinecone、Redis Enterprise Cloud から選択できます。ベクトルデータベースの設定方法については、この記事の後半で詳しく説明します。
検索拡張生成、埋め込み、ベクトルデータベースの入門
RAG は特定の技術セットではなく、FM がトレーニング中に見なかったデータにアクセスできるようにするための概念です。RAG を使用すると、モデルを継続的に再トレーニングしなくても、企業固有のデータなどの追加情報で FM を強化できます。
モデルを継続的に再トレーニングすると、計算負荷が高くコストがかかるだけではありません。モデルを再トレーニングするや否や、会社は既に新しいデータを生成していて、モデルが持つ情報が古くなっている可能性があります。RAG は、実行時にモデルが追加の外部データにアクセスできるようにすることで、この問題に対処しています。次に、関連データがプロンプトに追加され、補完の関連性と精度の両方が向上します。
このデータは、ドキュメントストアやデータベースなど、さまざまなデータソースから取得できます。ドキュメント検索は、一般的に、次の図に示すように、埋め込みモデルを使用してドキュメントまたはドキュメントのチャンクをベクトル埋め込みに変換し、そのベクトル埋め込みをベクトルデータベースに保存することで実装します。
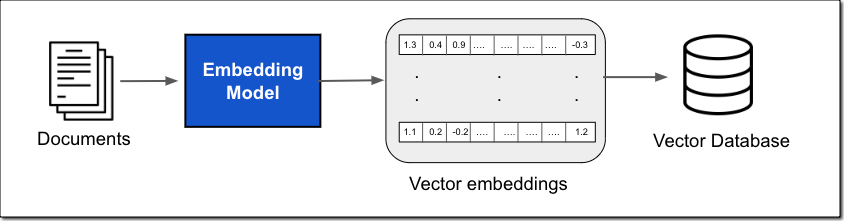
ベクトル埋め込みには、ドキュメント内のテキストデータの数値表現が含まれます。それぞれの埋め込みは、データのセマンティックまたはコンテキスト上の意味を捉えることを目的としています。各ベクトル埋め込みは、多くの場合、埋め込みが作成された元のコンテンツへの参照などの追加のメタデータとともに、ベクトルデータベースに入れられます。次に、ベクトルデータベースはベクトルにインデックスを付けます。これはさまざまな方法で実行できます。このインデックスにより、関連データをすばやく取得できます。
従来のキーワード検索と比較して、ベクトル検索では、キーワードが完全に一致しなくても関連する結果を見つけることができます。例えば、「製品 X のコストはいくらですか」と検索する場合、ドキュメントに「製品 X の価格は […] です」と記載されていると、「価格」と「コスト」は異なる単語であるため、キーワード検索が機能しない可能性があります。ベクトル検索では、「価格」と「コスト」は意味的に似ていて同義なので、正確な結果が返されます。ベクトル類似度は、ユークリッド距離、コサイン類似度、ドット積類似度などの距離メトリクスを使用して計算されます。
次に、ベクトルデータベースをプロンプトワークフロー内で使用して、下の図に示すように、入力クエリに基づいて外部情報を効率的に取得します。

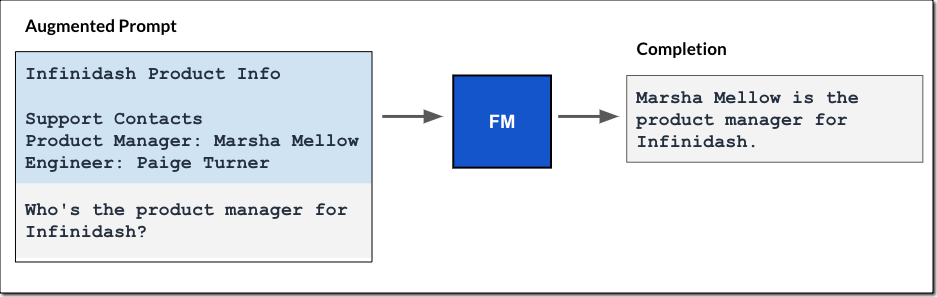
ワークフローは、ユーザー入力プロンプトから始まります。同じ埋め込みモデルを使用して、入力プロンプトのベクトル埋め込み表現を作成します。次に、この埋め込みを使用してデータベースに類似のベクトル埋め込みをクエリすると、最も関連性の高いテキストがクエリ結果として返されます。
次に、そのクエリ結果がプロンプトに追加され、拡張されたプロンプトが FM に渡されます。このモデルは、次の図に示すように、プロンプト内の追加コンテキストを使用して補完を生成します。
Amazon Bedrock のエージェントに関するブログ記事で説明したフルマネージド型エージェントのエクスペリエンスと同様に、Amazon Bedrock のナレッジベースはデータインジェストワークフローを管理し、エージェントは RAG ワークフローを管理します。
Amazon Bedrock のナレッジベースの開始方法
Amazon S3 などのデータソースを指定してナレッジベースを追加したり、Amazon Titan Embeddings などの埋め込みモデルを選択してデータをベクトル埋め込みに変換したり、送信先ベクトルデータベースを選択してベクトルデータを保存したりできます。Bedrock は、ベクトルデータベースへの埋め込みの作成、保存、管理、更新を行います。
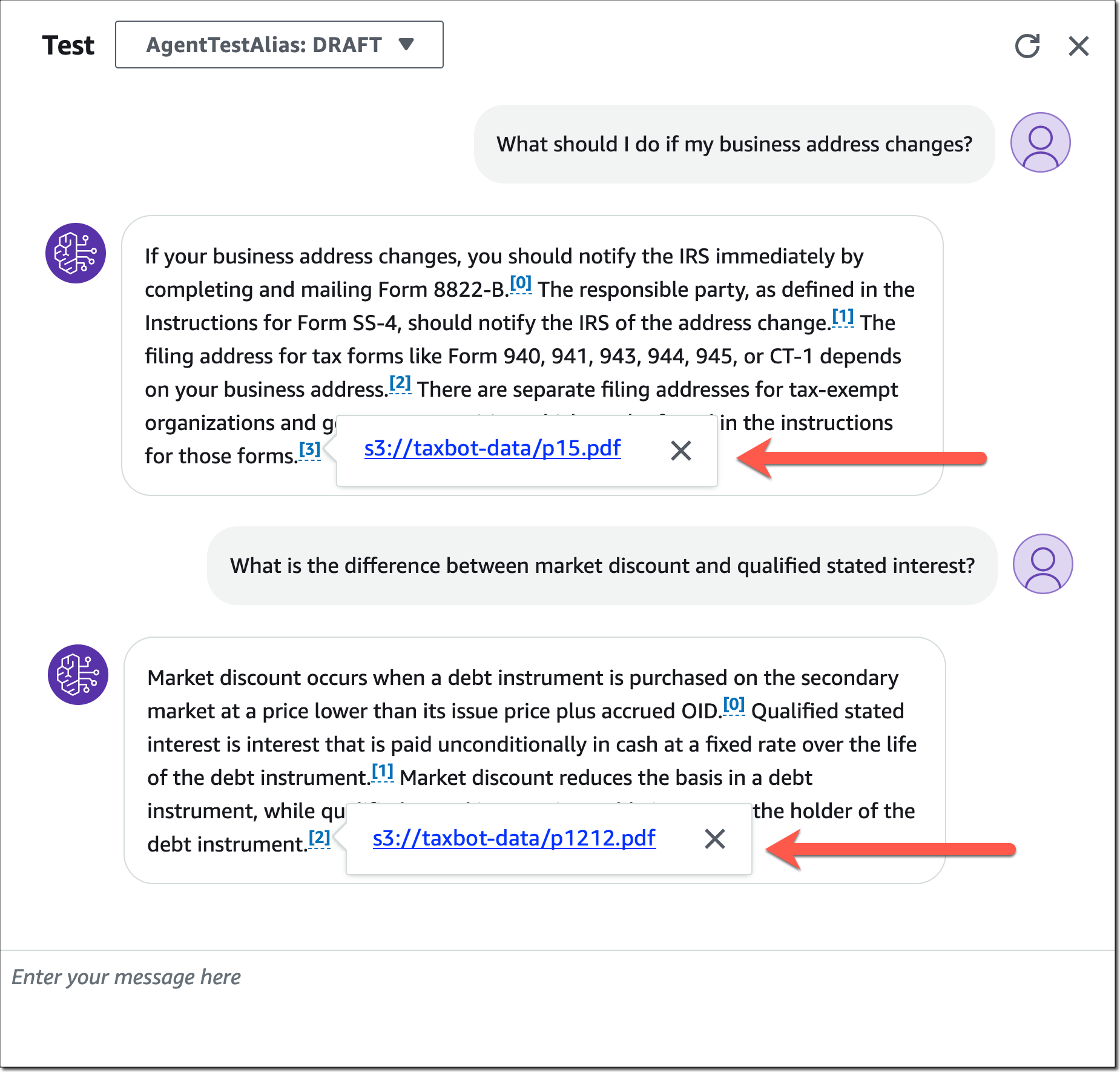
エージェントにナレッジベースを追加すると、エージェントはユーザー入力に基づいて適切なナレッジベースを識別し、関連情報を取得して情報を入力プロンプトに追加します。これにより、次の図に示すように、応答を生成するためのより多くのコンテキスト情報がモデルに提供されます。ナレッジベースから取得するすべての情報には、透明性を高め、ハルシネーションを最小限に抑えるためのソース属性が付いています。

これらのステップを詳しく説明しましょう。
Amazon Bedrock のナレッジベースを作成する
あなたが税務コンサルティング会社のデベロッパーで、米国の税務申告に関する質問に回答できる生成系 AI アプリケーション (TaxBot) をユーザーに提供したいとしましょう。 まず、関連する税務書類を保持するナレッジベースを作成します。次に、このナレッジベースにアクセスできるように Bedrock のエージェントを設定し、そのエージェントを TaxBot アプリケーションに統合します。
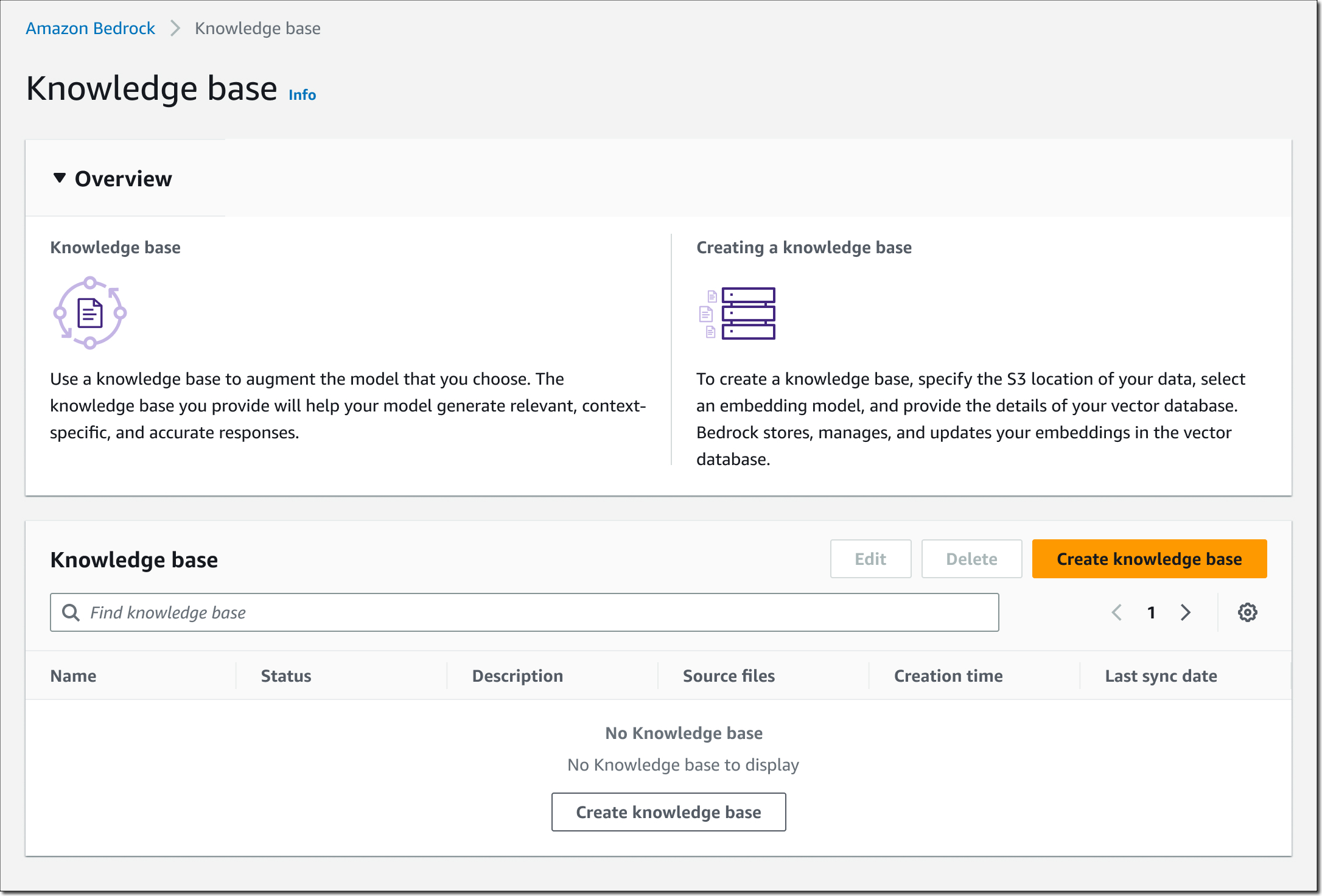
開始するには、Bedrock コンソールを開き、左側のナビゲーションペインで [Knowledge base] (ナレッジベース) を選択し、次に [Create knowledge base] (ナレッジベースの作成) を選択します。
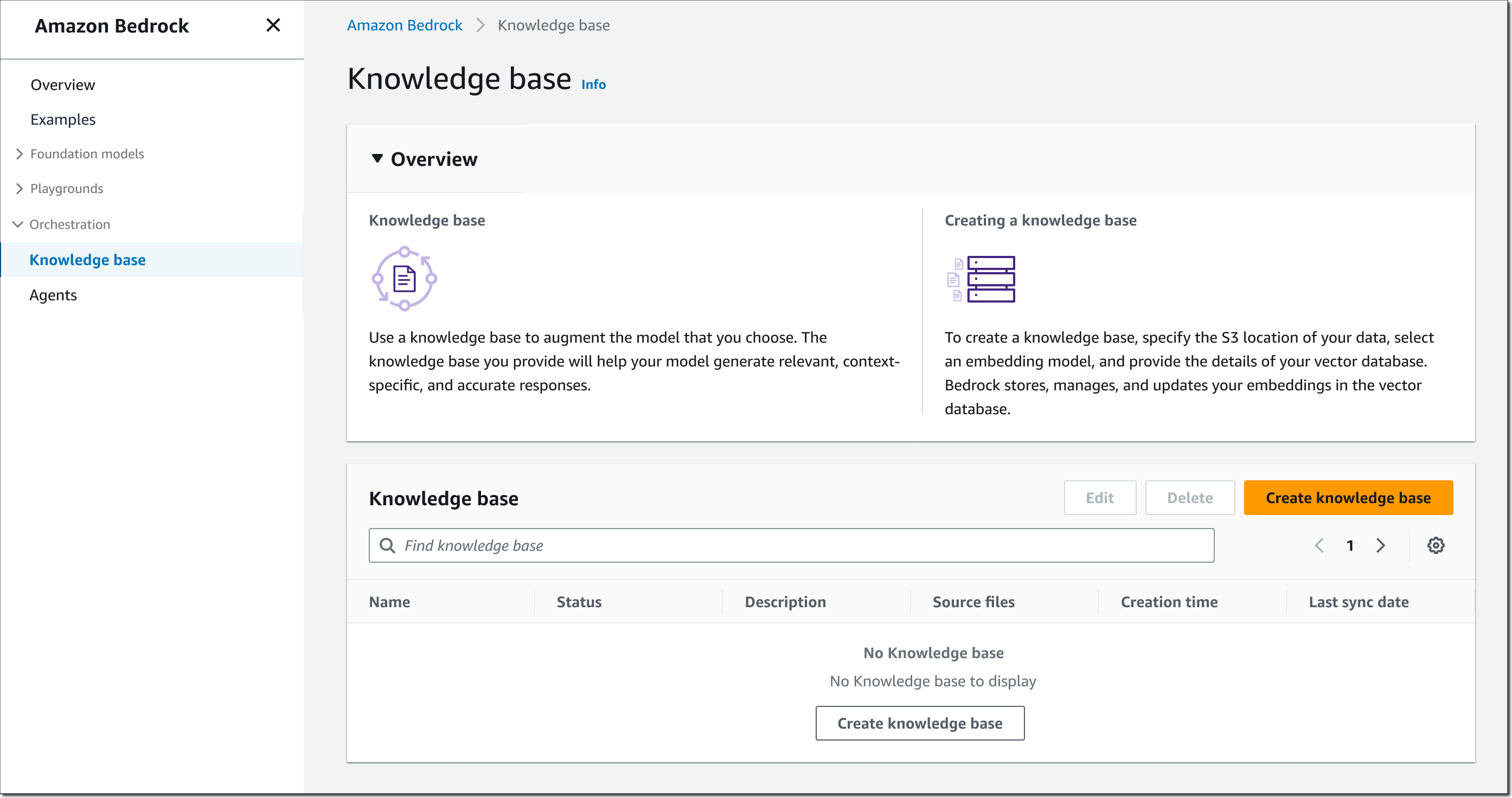
ステップ 1 – ナレッジベースの詳細を入力します。 ナレッジベースの名前と説明 (オプション) を入力します。また、Amazon Bedrock の信頼ポリシー、ナレッジベースで使用する S3 バケットへのアクセス許可、およびベクトルデータベースへの読み取り/書き込み許可を備えた AWS Identity and Access Management (IAM) ランタイムロールを選択する必要があります。必要に応じてタグを割り当てることもできます。

ステップ 2 – データソースをセットアップします。 データソース名を入力し、データの Amazon S3 ロケーションを指定します。サポートされているデータ形式には、.txt、.md、.html、.doc と .docx、.csv、.xls、.xlsx、.pdf ファイルが含まれます。Bedrock でデータの復号化と暗号化を行えるようにする AWS Key Management Service (AWS KMS) キーと、Bedrock がデータを埋め込みに変換している間の一時的なデータストレージ用の別の AWS KMS キーを指定することもできます。
Amazon Titan Embeddings などの埋め込みモデル、テキスト、使用しているベクトルデータベースを選択します。ベクトルデータベースでは、前述のように、Amazon OpenSearch Serverless 用ベクトルエンジン、Pinecone、または Redis Enterprise Cloud から選択できます。

ベクトルデータベースに関する重要な注意事項: Amazon Bedrock がお客様に代わってベクトルデータベースを作成することはありません。サポートされているオプションのリストから新しい空のベクトルデータベースを作成し、ベクトルデータベースのインデックス名とインデックスフィールドとメタデータフィールドのマッピングを指定する必要があります。このベクトルデータベースは Amazon Bedrock 専用である必要があります。
Amazon OpenSearch Serverless 用ベクトルエンジンのセットアップがどのようなものかをお見せしましょう。デベロッパーガイドとこの AWS ビッグデータブログ記事で説明されているように OpenSearch Serverless コレクションをセットアップしたと仮定して、OpenSearch Serverless コレクションの ARN を指定し、ベクトルインデックス名、ベクトルフィールドとメタデータフィールドのマッピングを指定します。
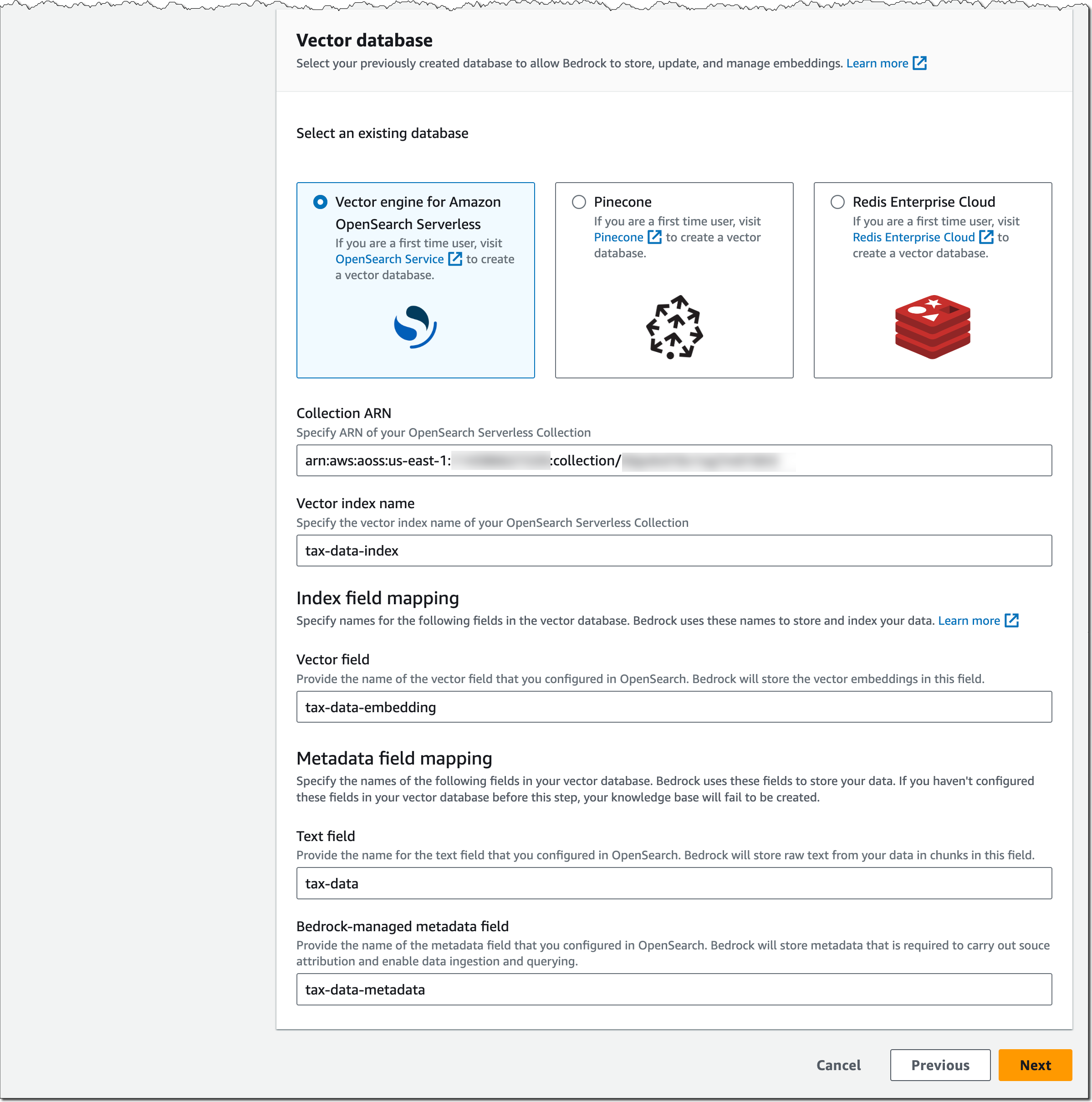
Pinecone と Redis Enterprise Cloud の設定は似ています。Bedrock のベクトルデータベースをセットアップして準備する方法の詳細については、この Pinecone のブログ記事と Redis Inc. のブログ記事をチェックしてください。
ステップ 3 – 確認して作成します。 ナレッジベースの設定を確認し、[Create knowledge base] (ナレッジベースの作成) を選択します。
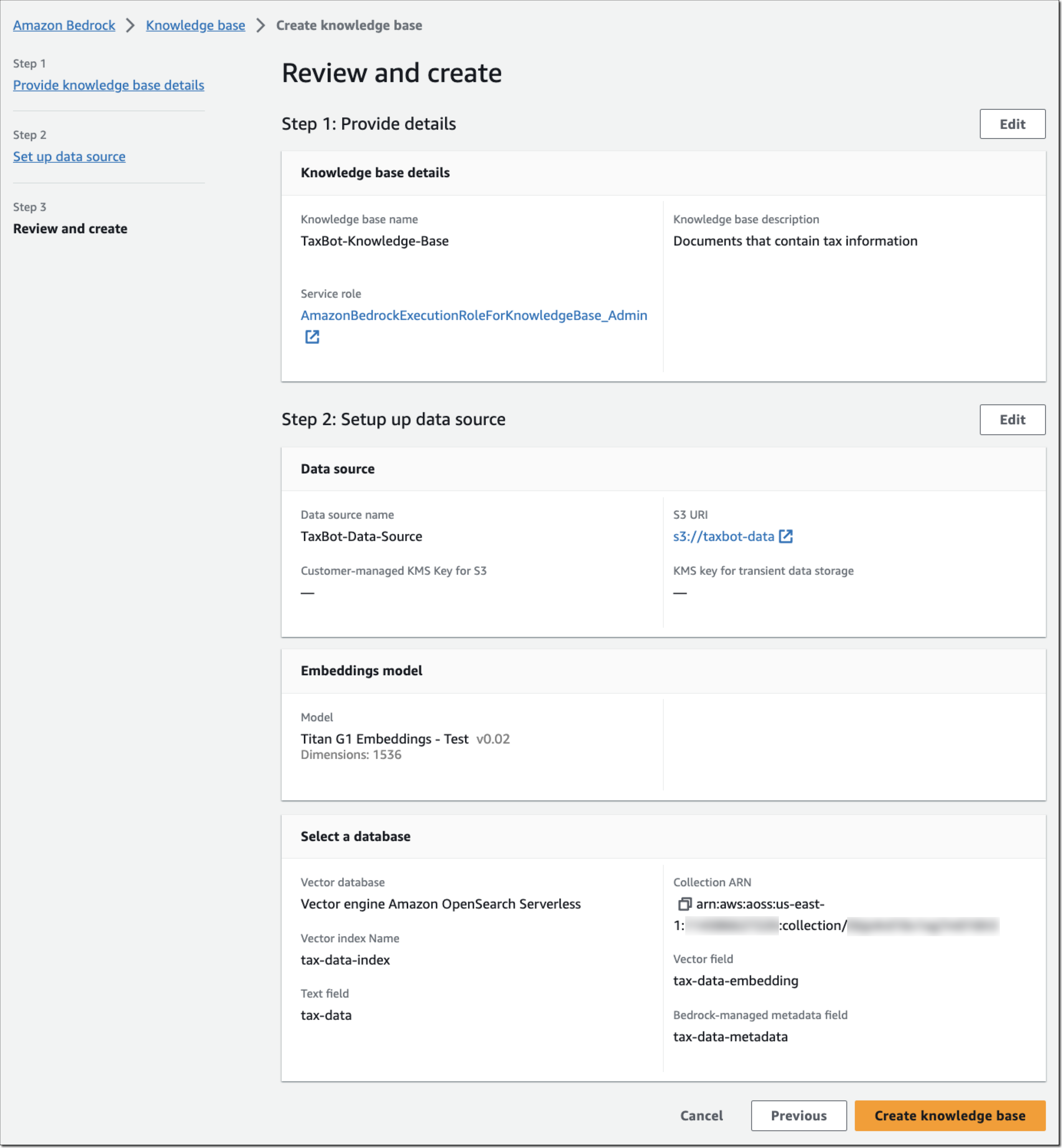
ナレッジベースの詳細ページに戻り、新しく作成したデータソースの [Sync] (同期) を選択します。データソースに新しいデータを追加するたびに、Amazon S3 データをベクトル埋め込みに変換し、その埋め込みをベクトルデータベースにアップサートする取り込みワークフローを開始します。データ量によっては、このワークフロー全体に時間がかかる場合があります。
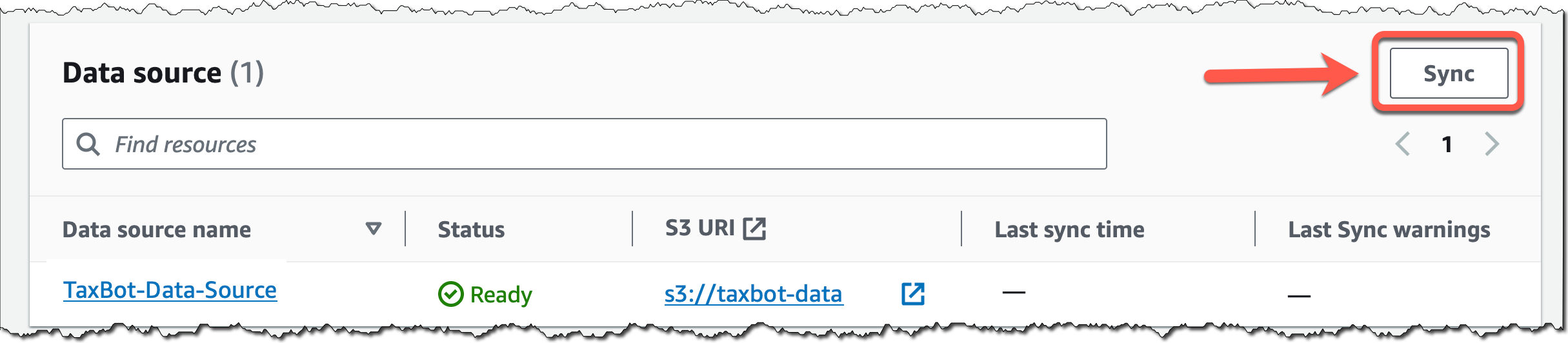
次に、ナレッジベースをエージェント設定に追加する方法を説明します。
ナレッジベースを Amazon Bedrock のエージェントに追加する
Amazon Bedrock のエージェントを作成または更新するときに、ナレッジベースを追加できます。Amazon Bedrock のエージェントに関するこの AWS ニュースブログの記事で説明されているように、エージェントを作成します。
私の税務ボットの例として、「TaxBot」というエージェントを作成し、基盤モデルを選択し、ステップ 2 でエージェントに次の指示を行いました。「あなたはアメリカの税務申告に関するユーザーの質問に答えてくれる、親切でフレンドリーなエージェントです」。 ステップ 4 では、以前に作成したナレッジベースを選択し、そのナレッジベースをいつ使用するかを説明する指示をエージェントに提供できます。

これらの指示は、特定のナレッジベースを検索に使用すべきかどうかをエージェントが判断するのに役立つため、非常に重要です。エージェントは、ユーザー入力と利用できるナレッジベースの指示に基づいて適切なナレッジベースを特定します。
私の税務ボットの例として、ナレッジベース「Taxbot-Knowledge-Base」と「税務申告に関する質問に答えるには、このナレッジベースを使ってください」という指示を追加しました。
エージェントの設定が完了したら、エージェントをテストし、追加されたナレッジベースをどのように使用しているかをテストできます。エージェントがナレッジベースから取得した情報のソース属性をどのように提供しているかに注目してください。
 生成系 AI の基礎を学ぶ
生成系 AI の基礎を学ぶ
大規模言語モデル (LLM) を使用した生成系 AI は、RAG を含む LLM を使用して生成系 AI アプリケーションを構築する方法を学びたいデータサイエンティストとエンジニアを対象とした 3 週間のオンデマンドコースです。Amazon Bedrock で構築を始めるのに最適な基礎コースです。今すぐ LLM で生成系 AI を申請しましょう。
サインアップして、Amazon Bedrock (プレビュー) についての詳細を学ぶ
Amazon Bedrock は現在プレビューでご利用いただけます。プレビューの一部として Amazon Bedrock のナレッジベースを利用したい場合は、普段の AWS サポート担当者にお問い合わせください。私たちは定期的に新規顧客へアクセスを提供しています。詳細については、Amazon Bedrock の機能ページにアクセスし、サインアップして Amazon Bedrock について詳しく学んでください。
— Antje
原文はこちらです。