Amazon Web Services ブログ
Coffee Meets Bagel が、Amazon ElastiCache for Redis を使用してリコメンデーションモデルを強化
Coffee Meets Bagel (CMB) は、毎日 150 万人以上のユーザーに出会いの機会を提供するマッチングアプリです。有意義な関係をもたらす、楽しく安全で質の高い出会いの経験をもたらすことに焦点を当てているため、当社のモットーは「量よりも質」です。こうした約束を果たすために、私たちが提供するすべてのマッチングは、ユーザーが求める厳格な基準を満たす必要があります。
ところが、現在のトラフィックでは、高品質のマッチングを作成することは困難な問題となっています。当社は 30 人のエンジニアで構成されています (データチームには 3 人のエンジニアしかいません)。 これは、すべてのエンジニアが当社の製品に大きな影響を与えることを意味します。当社のアプリは、それぞれの現地時間の正午にプッシュ通知によって、アプリにログインするようユーザーに促します。この機能は日々のエンゲージメントを促進するには最適ですが、予想されるように、この時間帯のトラフィックは急増します。

問題の説明: サービスやモバイルクライアントのレイテンシーをできるだけ短くしながら、高品質のマッチングを作成するにはどうすればよいか。
1 つの解決策は、ユーザーがアプリにログインする前にランク付けされた推奨されるマッチングを作成することです。ユーザー 1 人あたり 1,000 件のマッチングのバックログを保持するとすると、現在のユーザーベースで 10 億件のマッチングを保存する必要があります。この数は、新しいユーザーを獲得するにつれて二次的に増加します。
もう 1 つの解決策は、要求に応じてマッチングを作成することです。Elasticsearch などの検索データベースに潜在的なマッチングを保存することで、指定された基準に基づいてマッチングのセットを取得し、関連性で並べ替えることができます。実際に、私たちはこのメカニズムを通してマッチングの一部を取得しています。しかし、残念なことに、インデックス付きの基準だけで検索すると、ある種の機械学習モデルを利用することができなくなります。さらに、このアプローチでは、コストが大幅に増加し、巨大な Elasticsearch インデックスの保守の負担が増大します。
結局、両方のアプローチの組み合わせを選ぶことにしました。Elasticsearch をゼロデイモデルとして使用しますが、オフラインプロセスを使用してすべてのユーザーに対してさまざまな機械学習によるリコメンデーションを事前に計算し、それらをオフラインキューに保存します。
この記事では、Elasticsearch を使用してリコメンデーションを事前に計算するという選択したアプローチ、およびリコメンデーション (前述のキューコンポーネント) を保存して提供するために Redis を選択した理由について説明します。また、Amazon ElastiCache for Redis によって CMB エンジニアリングチームの管理およびインフラストラクチャメンテナンスの作業が、どのように簡略化されたかについても説明します。
Redis を使用してリコメンデーションをソート済みセットに保存する
私たち CMB が Redis を本当に気に入っている理由はたくさんありますが、ここではこの特定のユースケースに関連するいくつかの理由を概説します。
- 低レイテンシー Redis はインメモリデータベースであるため、Redis からの書き込みおよび (特に) 読み取りは、全体的なレイテンシーへの影響が非常に少ないです。私たちのドメインがペアに基づくという特性 (たとえば、システムから 1 人のユーザーを削除すると、他の何千ものユーザーのキューから削除することになる) から、アクセスパターンはセミランダムになります。この状況から、ディスクから読み取る必要があるデータベースで処理するとかなりのオーバーヘッドが発生する可能性があります。1 日の中で最も忙しい時間帯には、数分で何十万ものマッチングが行われるため、読み取りが低レイテンシーであることが基本です。今日の時点では、読み取りには平均 2 〜 4 ミリ秒かかり、書き込みプロセス (すべての新しいリコメンデーションを小さなバッチで書き込む) には、1 ユーザーあたり 3 〜 4 秒かかります。
- 整合性 CMB は、ユーザーが選択した基準に合う高品質のマッチングを提供することに誇りを持っています。このため、ユーザーがデートからの脱退を決定したり、自分のアカウントを削除することを決定したりした場合 (明らかにCMBを通じて結婚したため)、あるいはプロフィールの一部を変更することを決定した場合、すべてのリコメンデーションをできるだけ早く更新することが重要です。Redis は、こうしたシナリオの実行を非常に簡単にする整合性を保証します。これは、リスト内の項目を自動的にデキューおよびエンキューする組み込みコマンドを提供します。これらのリストとソート済みセットを使って、リコメンデーションに役立てます。
- 簡単さ Redis の最も良いところは、やり取りするのが非常に簡単であることです。だからこそ、世界でも有数の優れた企業が使っているのです。データ構造、ドキュメンテーション、各操作の複雑さはとてもよく定義されています。私たちは皆、単純であることで、コードの複雑さやバグが増える可能性が少ないことを知っています。
Redis を使用する前は、Cassandra を使用していました。これは、読み取りである程度の低レイテンシーを保証しながら、高スループットの書き込みを約束したためです。Cassandra には、Redis に変更することを決定したことですぐに解消した、いくつかの問題点がありました。
整合性
Cassandra は、結果整合性を約束しています。当初、私たちのユースケースはこの問題の影響を大きく受けないと考えていましたが、それは間違っていました。読み書きの整合性を高めようともしましたが、残念ながら、レイテンシーが急増してアプリの信頼性が低下しました。
狂気のメンテナンス!
おそらく、Cassandra が抱えていた主な問題はメンテナンスに関連していました。私たちの DevOps チームとバックエンドエンジニアは、ノードのフラッピング (断続的なオンとオフ) または停止のために常にページングされていました。さらに悪いことに、ノードのクラッシュが大量のヒープダンプを生成し、それがディスクを一杯にしました。クラスターの最適なチューニングを学ぶことはできたかもしれませんが、すでにクラスターのメンテナンスに膨大な時間を費やしていました。
Redis に移行することを決定した時に、これらの問題はすべて解消し、私たちの小さなチームは、気難しいクラスターを管理するよりもっと重要な問題に集中することができるようになりました。
Amazon ElastiCache for Redis を選ぶ理由
Amazon ElastiCache for Redis を選択することは、当社のエンジニアリングチームにとって大きな動きでした。スタートアップ企業にとって、時間は本当に重要です。管理作業の実行、ハードウェアのプロビジョニング、ソフトウェアのパッチのチェック、インフラストラクチャの保守を行う必要がないので、アイデアやアルゴリズムに取り組む時間が大幅に増えます。ElastiCache の最大の機能の 1 つは、Redis の最新の安定バージョンに非常に早く対応できることです。容易にスケールアウトできるようになりますが、物事がうまくいかない場合に備えてまだ冗長という魔法の層があります。エンジニアとして、メンテナンスを考えずに数分で新しい Redis インスタンスをスピンアップできることで力を与えられ、強化版の Redis に頼ることができます。
ほとんどのデータベースに当てはまりますが、管理された Redis を使うことは特に有益であると思います。これは、Redis がインメモリデータストアであるからであり、メモリ管理、フラグメンテーション、バックアップには細心の注意を払う必要があるためです。ElastiCache for Redis が、すべてを行ってくれます。
CMB のリコメンデーションのアーキテクチャ
次の図に示すように、CMB のリコメンデーションのアーキテクチャは、リアルタイム (オンライン) とバッチ (オフライン) の 2 つの主要コンポーネントで構成されています。
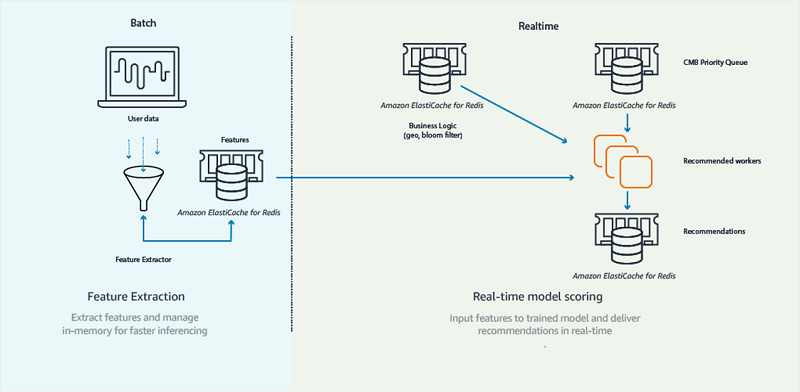
バッチコンポーネントは、毎日午前 7 時に実行される一連のスケジュールされたタスクです。これらのタスクは、大量のマッチングの履歴の読み取りを担当し、リコメンデーションモデルをトレーニングし、後で使用するために特徴 (ユーザーを記述する属性) を抽出します。リコメンデーションモデルは、このアプリの予測コンポーネントであり、2 人のユーザーの親和性を効果的に定量化し、マッチングの可能性を「スコア」にすることを可能にします。リコメンデーションモデルは、CMB の中心的なコンポーネントの 1 つであり、これを使用することで、ユーザーに対して高品質のマッチングを作成できます。
リアルタイムコンポーネントは、ウェブサーバーやウェブワーカーなど、コアインフラストラクチャによって使用され、CMB の主要なデータストアとやり取りします。このアプリのバッチコンポーネントがリコメンデーションモデルをトレーニングして特徴を抽出するのに対し、オンラインコンポーネントは適格なユーザーのペアのマッチングをスコア化する仕事をします。このコンポーネントは、ユーザーごとに複数のリコメンデーションのキューを作成/維持する役割を果たします。Redis の「リコメンデーション」データストアには、これらのキューがソート済みセットの形式で含まれています。当社のウェブアプリは、リコメンデーションをこのデータストアから読み取り、リアルタイムで顧客に提供します。
ElastiCache を使用してユーザー間の類似性を効率的に計算する
CMB では、潜在的な (または隠れている) 特徴を利用して、ユーザー間の類似性を計算しています。
潜在的な特徴の概要
大半の人は機械学習における「特徴」の概念に精通しています。そこでいう特徴とは、人間である私たちがユーザーに帰属させるメタデータです。私たちは、私たちが定義する特徴がアルゴリズムの学習プロセスに良い影響を与えると考えています (私たちの文脈では、アルゴリズムがより高品質のマッチングを予測する方法を学ぶと想定しています)。
CMB の文脈では、以下のような特徴の例があります。
- 年齢
- 性別
- 場所
ほとんどの場合、人間として私たちが選択する特徴は、直接観測可能であるため、高品質のマッチングを予測するための最も強力なインジケータ―ではありません。一方で、過去のマッチングのデータを見ることによって ML アルゴリズムの特定のサブセットによって作成される (隠れている、または潜在的な) 一連の特徴があります。これらの特徴は、非常に予測に役立ちます。直接観測することはできませんが、高品質のマッチングの予測では非常に強力です。
CMB は、潜在的な特徴をどのように使用するか
CMB は、潜在的な特徴を使ってユーザーのグループ間の類似性を予測します (項目ベースの協調フィルタリング)。2 つのバッチタスクが、すべてのアクティブなユーザーの潜在的な特徴の計算を担当します。タスクは、浮動小数として表現される潜在的な特徴を、ユーザーあたり 100 件計算します。
こうした特徴は、すべてのユーザーに対して何百日ものマッチングの履歴を分析することによって学習されます。ユーザーの (潜在的な) 特徴をトレーニングした後 (通常 1 日に 6 〜 7 時間かかります)、それらを JSON 形式で ElastiCache に保存します。
次の例は、ユーザー ID 905755 の潜在的な特徴を取得した結果を示しています。
たった 1 つのコマンドで、ユーザーの潜在的な特徴を読み込むことができます。これらの値が明示的に何を表しているのかは分かりませんが、複数のユーザー間で整合性があることは分かります (たとえば、配列の最初の値は、すべてのユーザーに対して同じ属性を表しています)。
協調フィルタリングによるリコメンデーションの作成
ユーザーに対するリコメンデーションを作成する方法の 1 つは、そのユーザーが気に入った最後のマッチングに似ている相手のユーザーを見つけることです。
例: Daniel という名前の男性が、サンフランシスコで女性を探しています。Daniel はたまたまハイキングやテニスをするのが好きであり、彼が「気に入った」履歴は明らかにこの好みを反映しています。実際に、Daniel が気に入った最近の 5 件のマッチングのうち 3 件の相手は野外活動好きでスポーツをしていました。次回、Daniel へのリコメンデーションを作成するときは、Daniel が気に入った最後の 5 人の女性にできるだけ似ている女性の候補者をデータベースで検索します。この操作の結果は、関連性によってソートされたリコメンデーションの候補リストです。リストの先頭には、おそらく野外活動好きであるか、スポーツを楽しんでいる女性が並んでいるでしょう。
単純にユーザーのベクトル間の類似度を測定することで、2 人のユーザー間の類似度を計算することができます。
たった 3 行の Python コードで、すべてのユーザーの潜在的な特徴がコードベースに存在すると仮定すると、2 人のユーザーの任意の組み合わせの間の類似性を効率的に見つけることができます。次に、以前に気に入ったユーザーとの類似性によって対象となるマッチングをランク付けし、それらを「リコメンデーション」の Redis データストアに保持します。
潜在的な特徴を保存するために Redis を使用するメリットは何か?
以下のようないくつかのメリットがあるため、潜在的な特徴を保存するために Redis を使用しています。
実装の簡単さ
ソフトウェアエンジニアとして、ほんの数行のコードで些細ではない操作を実行できることはとても助けになります。Redis コマンドは明示的で理解しやすいため、コードが単純になり、(うまくいけば) バグが減ります。Redis が非常に単純であり、非常に基本的なデータ構造で機能するため、隠れた罠が少なくなり、コードが単純になります。事実上、スキーマ、結合、インデックス、クエリについて考える必要はありません。
ここで単純さを強調する理由は、非常に単純でよく知られているデータ構造を扱うことによって、コードが最小限になるからです。
CMB のランダムな読み取り/書き込みの効率的な処理
いつでも、どんな日でも、私たちのインフラストラクチャは、ユーザーのために絶えずリコメンデーションを更新しています。これは、リコメンデーションを最新 (学習した最新の情報を考慮に入れる) で、関連性があるもの (ユーザーが指定した基準の範囲内) に保つためです。キーを読み書きする順番は、決定論的ではありません。
このシナリオでは、ディスクベースのデータストアを使用している誰かが、いつでもディスクのランダムで隣接していない部分にアクセスしたり、常にメモリからキャッシュを削除したりしてパフォーマンスを低下させます。これに反して、Redis はインメモリにあり、この問題の影響を受けません。
懸念の分離
潜在的な特徴の最大の特性の 1 つは、計算された後は、単なる数のリストであることです。潜在的な特徴は依存関係を持たず、依存関係を使用する必要もありません。 この場合、Redis はオフラインアルゴリズムコンポーネント (Apache Spark、NumPy、Pandas、Amazon S3、またはApache Parquet) とオンラインウェブコンポーネント (Django) の間の「仲介者」です。
Redis を使用する表示済みリコメンデーションの除外
CMB では、すでに表示されたリコメンデーションを顧客に表示したくありません… 以前に誰かをパスした場合、おそらく同じ人をまたパスするからです。 これは事実上、親子関係の問題です。
Redis を使用して、表示済みリコメンデーションの除外を設定する
CMB のユーザーに既に見たことがある人を見せないようにする 1 つの方法は、毎回新しいマッチングが表示されるようにセットを更新することです。
次の例では、ユーザー 522168 を 905655 の除外リストに追加しました。
905755 がすでに 52216 と 212123 を見ているか確認したい場合は、次のようにします。
この例が示すように、522168 はヒットしましたが、212123 はヒットしませんでした。したがって、ユーザー 905755 への今後のリコメンデーションから 522168 を削除することができます。
このアプローチから生じる最大の問題は、二次空間を保存しなければならなくなることです。実際には、オーガニックなユーザーの増加によって除外リストの数が増えると、どのセットにも含まれる項目の数が増えます。
セットの実装に必要な合計空間 = n_users * n_users
ブルームフィルターを使用して表示済みリコメンデーションをフィルタリングする
ブルームフィルターは、親子関係を効率的にチェックできる確率的データ構造です。セットと比較すると、偽陽性のリスクがあります。このシナリオでの偽陽性とは、ブルームフィルターが、実際にはセットに入っていないときに何かがセット内にあると知らせる可能性があることを意味します。これは、ここでのシナリオでは許容できる妥協です。同じユーザーを 2 回表示しないことを保証できるのであれば、まだ表示されていないユーザーを他のユーザーに表示しないリスク (低い確率で) を冒してもやむをえません。
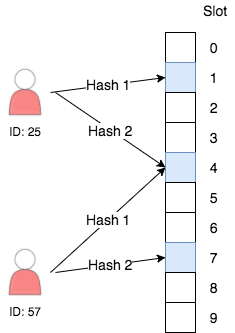
内部的には、すべてのブルームフィルターはビットベクトルによって支えられています。ブルームフィルターに追加した各項目について、いくつかのハッシュを計算します。すべてのハッシュ関数は、ブルームフィルター内の 1 に設定したビットを指しています。
メンバーシップをチェックするときは、同じハッシュ関数を計算し、すべてのビットが 1 に等しいかどうかをチェックします。この場合、その項目はセット内にあり、一定の確率 (ビットベクトルのサイズとハッシュの数によって調整可能) で正しくない可能性があります。
Redis でブルームフィルターを実装する
Redis はそのままではブルームフィルターをサポートしていませんが、キーの特定のビットを設定するコマンドを提供しています。以下は、CMB でブルームフィルターを使用する 3 つの主なシナリオと、Redis を使用してそれらを実装する方法です。読みやすくするために Python コードを使用します。
新しいブルームフィルターの作成
この操作は、アプリで新しいユーザーが作成されるたびに行われます。
注意: Bloom Filter Calculator を使用して、2 ** 17 をブルームフィルターとして選択しました。すべてのユースケースは、空間と偽陽性の要件が異なります。
既存のブルームフィルターへの項目の追加
この操作は、ユーザー exclude_id を profile_id の除外リストに追加する必要があるたびに行われます。この操作は、ユーザーが CMB を開いてマッチングのリストをスクロールするたびに行われます。
注意: make_hash_positions() 関数は、プロファイル exclude_id にマップされるビットインデックスを表す整数のリストを返します。
この例が示すように、操作をバッチ処理することでウェブサーバーと Redis サーバー間のラウンドトリップ数が最小限に抑えられるため、Redis パイプライン処理を使用します。パイプライン処理の利点を説明する素晴らしい記事については、Redis のウェブサイトの「Using pipelining to speed up Redis queries」を参照してください。
候補のマッチングのセットについて Redis ブルームフィルターのメンバーシップをチェックする
この操作は、特定のプロファイルに対して候補のマッチングのリストがあり、すでに表示されたすべての候補を除外したい場合に必ず行います。表示された候補はすべてブルームフィルターに正しく挿入されていると仮定します。
この最後の操作は他の操作よりも少し複雑なので、何が起こっているのかを段階的に見てみましょう。
Redis では、ブルームフィルターは単なるビットベクトルです。この操作では、ブルームフィルター全体を一度メモリに取り込み、Python 内ですべてのフィルターの一括操作を実行します。
hash_position のビットが 1 に設定されているかどうかを確認するために、前述のチェックが行われます。いずれかのビットが 1 に設定されていない場合は、その項目がブルームフィルターに存在しないことが確実にわかります。
ブルームフィルターの実装に必要な合計空間 = n_users * bloom_filter_size
ブルームフィルターの保存に Redis を使用する利点は何か?
Redis を使用してブルームフィルターを保存すると、次のような利点があります。
パフォーマンス
パイプおよび SETBIT 操作を使用すると、ブルームフィルターに項目を追加することは非常に効率的で簡単です。また、読み取り操作が 1 回しかないため、一括フィルタリングの実行も非常に効率的です。現在のインフラストラクチャでは、約 170 ミリ秒で何万もの候補を効率的にフィルタリングすることができます。
将来においても有効
私たちのブルームフィルターはサイズが固定されているので、ユーザーベースが拡大しても、二次成長について心配する必要はありません。実際に、Redis クラスターを使用すると、データを分割してもブルームフィルターをメモリに保持できます。
ブルームフィルターの保存に Redis を使用する欠点は何か?
主な欠点は、コードの複雑さです。ブルームフィルターの Redis 部分は非常に単純ですが、ブルームフィルターの実際の実装は複雑になる可能性があります。また、ブルームフィルターはデバッグがかなり難しいので、できれば有名なライブラリを入手するようにしてください。
なお現在は、Redis にブルームフィルターのサポートを提供できるモジュールがあります。Redis のドキュメントの「Bloom Filter Datatype for Redis」を参照してください。
結論
Redis はしばしばキャッシュと考えられていますが、すべての機能を備えているので、CMB ではファーストクラスのデータベースであると考えています。私たちのリコメンデーション、除外リスト、ミッションクリティカルなキューはすべて、Redis と小さな Python スクリプトの組み合わせを使って実装されています。この記事が、Redis のクリエイティブで革新的な使用方法について、CMB がどのように考えているかについて説明になれば幸いです。この記事が、新しいビジネスや開発者にさらに実験し革新する力を与えてくれることを願っています!
著者について
 Daniel Pyrathon 氏は、Coffee Meets Bagel のシニア機械学習エンジニアです。空き時間には、Daniel は SF Python と PyBay の主催者の 1 人でもあり、そこで Python 業界のリーダーと活気に満ちたベイエリアコミュニティを結びつけようと活動しています。
Daniel Pyrathon 氏は、Coffee Meets Bagel のシニア機械学習エンジニアです。空き時間には、Daniel は SF Python と PyBay の主催者の 1 人でもあり、そこで Python 業界のリーダーと活気に満ちたベイエリアコミュニティを結びつけようと活動しています。
 David O’Steen 氏は、Coffee Meets Bagel のデータチームのリーダーです。 彼は、当社のユーザーの間に有意義なつながりを作り出すことに向けて組織を推進する責任を負っています。
David O’Steen 氏は、Coffee Meets Bagel のデータチームのリーダーです。 彼は、当社のユーザーの間に有意義なつながりを作り出すことに向けて組織を推進する責任を負っています。