Amazon Web Services ブログ
新機能 – AWS Glue を使用したサーバーレスストリーミング ETL
アプリケーションが本番環境にあるとき、何が起こっているか、どのようにアプリケーションが使われているかを把握する必要があります。データ分析の最初のアプローチはバッチ 処理モデルで、一連のデータを一定期間収集し、分析ツールで実行します。迅速に対応したい場合には、ストリーミングモデルを使用します。このモデルでは、データの到着時にデータ処理し、一度に 1 レコードずつ、または数十、数百、数千のレコードのマイクロバッチで処理します。
継続的な取り込みパイプラインの管理や即時的なデータ処理は、管理、パッチ適用、スケーリング、一般的な対応を必要とする常時オンのシステムであるため、大変複雑です。現在、拡張 (AWS Glue ジョブを Apache Spark に基づいて ) によってこうした機能をより簡単でコスト効率の高い方法で実装し、ストリーミングプラットフォーム (Amazon Kinesis Data Streams や Apache Kafka (完全マネージド Amazon MSK を含む)) などからデータを継続的に実行し使用しています。
このように、Glue はデータレイク (Amazon S3 の)、Amazon Redshift などのデータウェアハウス、またはその他のデータストアにデータを取り込むために必要なインフラストラクチャをプロビジョニング、管理、スケーリングします。たとえば、ストリーミングデータを DynamoDB テーブルに保存してすばやく検索したり、Elasticsearch に保存して特定のパターンを検索したりすることが可能となります。この手順は通常、抽出、変換、読み込み (ETL) と言います。
Glue ジョブでストリーミングデータを処理すると、Spark Structured Streaming の全機能にアクセスして、集約、パーティション化、フォーマット、他のデータセットとの結合といったデータ変換を実行し、データに情報を追加または修正して分析を容易にします。たとえば、外部システムにアクセスしてリアルタイムで不正を特定したり、機械学習アルゴリズムを使用してデータを分類したり、異常や異常値を検出したりできます。
AWS Glue を使用したストリーミングデータの処理
この新しい機能を試すには、IoT センサーからデータを収集し、すべてのデータポイントを S3 データレイクに保存します。Raspberry Pi と Sense HAT を使用し、温度、湿度、気圧、空間内の位置をリアルタイムで (一体化したジャイロスコープ、加速度計、磁力計を使用して) 収集します。こちらに構築中のアーキテクチャを表示しています。
まず、デバイスを AWS IoT Core に登録し、次の Python コードを実行してセンサーデータを含む JSON メッセージを毎秒 1 回、ストリーミングデータの MQTT トピックに送信します。この設定では単一のデバイスを使用していますが、デバイスの数が多い場合は、デバイスごとにサブトピック (streaming-data/{client_id}) を使用してください。
import time
import datetime
import json
from sense_hat import SenseHat
from awscrt import io, mqtt, auth, http
from awsiot import mqtt_connection_builder
sense = SenseHat()
topic = "streaming-data"
client_id = "raspberrypi"
# Callback when connection is accidentally lost.
def on_connection_interrupted(connection, error, **kwargs):
print("Connection interrupted. error: {}".format(error))
# Callback when an interrupted connection is re-established.
def on_connection_resumed(connection, return_code, session_present, **kwargs):
print("Connection resumed. return_code: {} session_present: {}".format(
return_code, session_present))
if return_code == mqtt.ConnectReturnCode.ACCEPTED and not session_present:
print("Session did not persist.Resubscribing to existing topics...")
resubscribe_future, _ = connection.resubscribe_existing_topics()
# Cannot synchronously wait for resubscribe result because we're on the connection's event-loop thread,
# evaluate result with a callback instead.
resubscribe_future.add_done_callback(on_resubscribe_complete)
def on_resubscribe_complete(resubscribe_future):
resubscribe_results = resubscribe_future.result()
print("Resubscribe results: {}".format(resubscribe_results))
for topic, qos in resubscribe_results['topics']:
if qos is None:
sys.exit("Server rejected resubscribe to topic: {}".format(topic))
# Callback when the subscribed topic receives a message
def on_message_received(topic, payload, **kwargs):
print("Received message from topic '{}': {}".format(topic, payload))
def collect_and_send_data():
publish_count = 0
while(True):
humidity = sense.get_humidity()
print("Humidity: %s %%rH" % humidity)
temp = sense.get_temperature()
print("Temperature: %s C" % temp)
pressure = sense.get_pressure()
print("Pressure: %s Millibars" % pressure)
orientation = sense.get_orientation_degrees()
print("p: {pitch}, r: {roll}, y: {yaw}".format(**orientation))
timestamp = datetime.datetime.fromtimestamp(
time.time()).strftime('%Y-%m-%d %H:%M:%S')
message = {
"client_id": client_id,
"timestamp": timestamp,
"humidity": humidity,
"temperature": temp,
"pressure": pressure,
"pitch": orientation['pitch'],
"roll": orientation['roll'],
"yaw": orientation['yaw'],
"count": publish_count
}
print("Publishing message to topic '{}': {}".format(topic, message))
mqtt_connection.publish(
topic=topic,
payload=json.dumps(message),
qos=mqtt.QoS.AT_LEAST_ONCE)
time.sleep(1)
publish_count += 1
if __name__ == '__main__':
# Spin up resources
event_loop_group = io.EventLoopGroup(1)
host_resolver = io.DefaultHostResolver(event_loop_group)
client_bootstrap = io.ClientBootstrap(event_loop_group, host_resolver)
mqtt_connection = mqtt_connection_builder.mtls_from_path(
endpoint="a1b2c3d4e5f6g7-ats.iot.us-east-1.amazonaws.com",
cert_filepath="rapberrypi.cert.pem",
pri_key_filepath="rapberrypi.private.key",
client_bootstrap=client_bootstrap,
ca_filepath="root-CA.crt",
on_connection_interrupted=on_connection_interrupted,
on_connection_resumed=on_connection_resumed,
client_id=client_id,
clean_session=False,
keep_alive_secs=6)
connect_future = mqtt_connection.connect()
# Future.result() waits until a result is available
connect_future.result()
print("Connected!")
# Subscribe
print("Subscribing to topic '{}'...".format(topic))
subscribe_future, packet_id = mqtt_connection.subscribe(
topic=topic,
qos=mqtt.QoS.AT_LEAST_ONCE,
callback=on_message_received)
subscribe_result = subscribe_future.result()
print("Subscribed with {}".format(str(subscribe_result['qos'])))
collect_and_send_data()
こちらは、デバイスが送信した JSON メッセージの例です。
{
"client_id": "raspberrypi",
"timestamp": "2020-04-16 11:33:23",
"humidity": 39.35261535644531,
"temperature": 30.10732078552246,
"pressure": 1020.447509765625,
"pitch": 4.044007304723748,
"roll": 7.533848064912158,
"yaw": 77.01560798660883,
"count": 104
}Kinesis コンソールで、my-data-stream データストリームを作成します (1 シャードでワークロードを十分に処理できます)。AWS IoT コンソールに戻り、IoT ルールを作成し、MQTT トピックからこの Kinesis データストリームにすべてのデータを送信します。
これで、すべてのセンサーデータが Kinesis に送信されて、新しい Glue 統合を利用して到着したデータを処理できるようになりました。Glue コンソールで、Glue データカタログに手動でテーブルを追加します。 ソースのタイプとして Kinesis を選択し、ストリーム名と Kinesis Data Streams サービスのエンドポイントを入力します。 Kafka ストリームの場合、テーブルを作成する前に、Glue 接続を作成する必要があることに注意してください。

データ形式として JSON を選択し、ストリーミングデータのスキーマを定義します。ここで列を指定しないと、ストリームの処理時に無視されます。
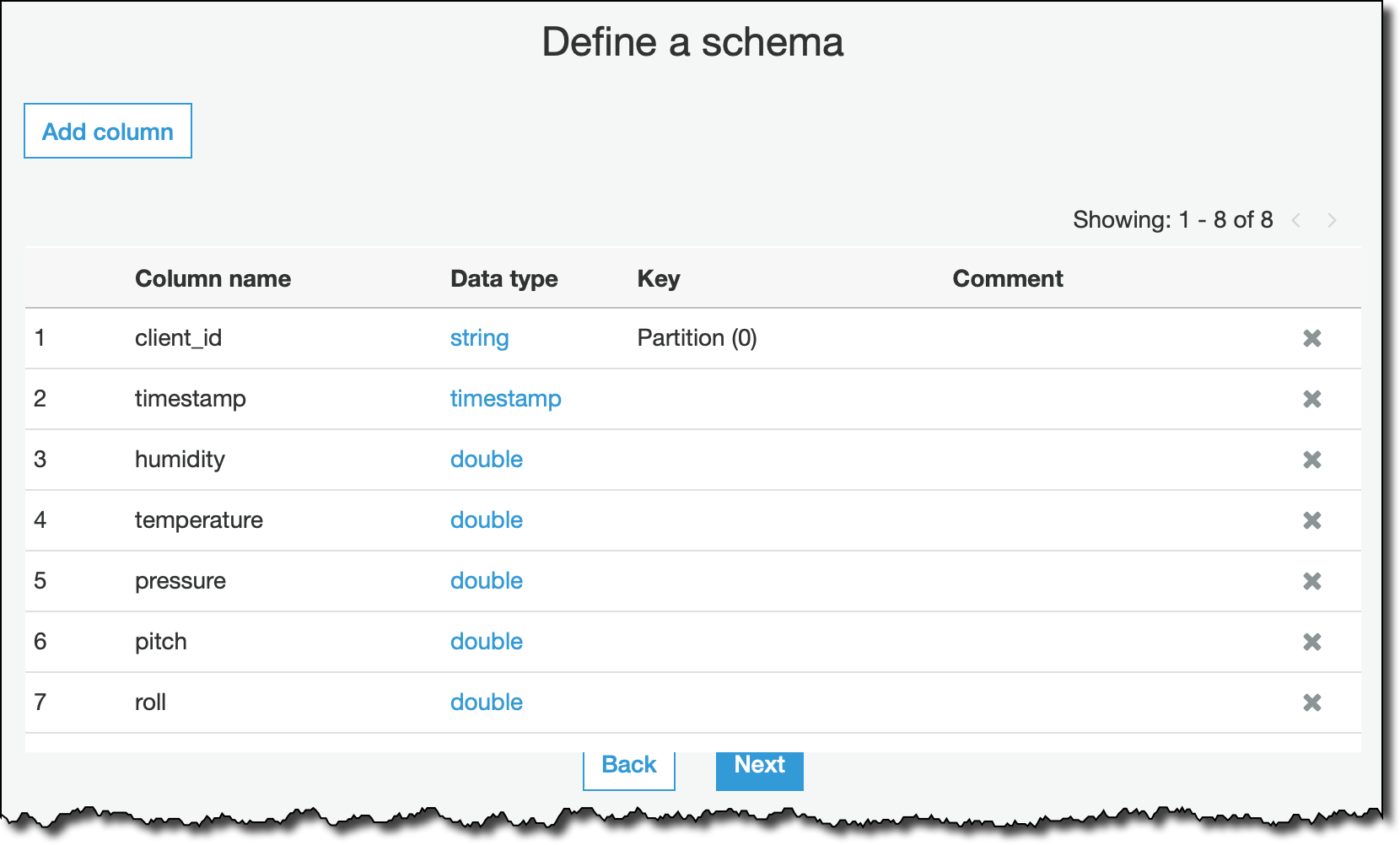
次に、最終確認をして、my_streaming_data テーブルを作成します。現在、ストリーミング ETL ジョブにスキーマ推論を追加する作業に取り組んでいます。これで、スキーマ全体を事前に指定する必要がなくなります。どうぞご期待下さい。
ストリーミングデータを処理するには、Glue ジョブを作成します。IAM ロールについては、AWSGlueServiceRole および AmazonKinesisReadOnlyAccess 管理ポリシーを添付する新しいロールを作成します。ユースケースと AWS アカウントの設定によっては、より詳細に設定したアクセスが可能なロールの使用を考えるかもしれません。
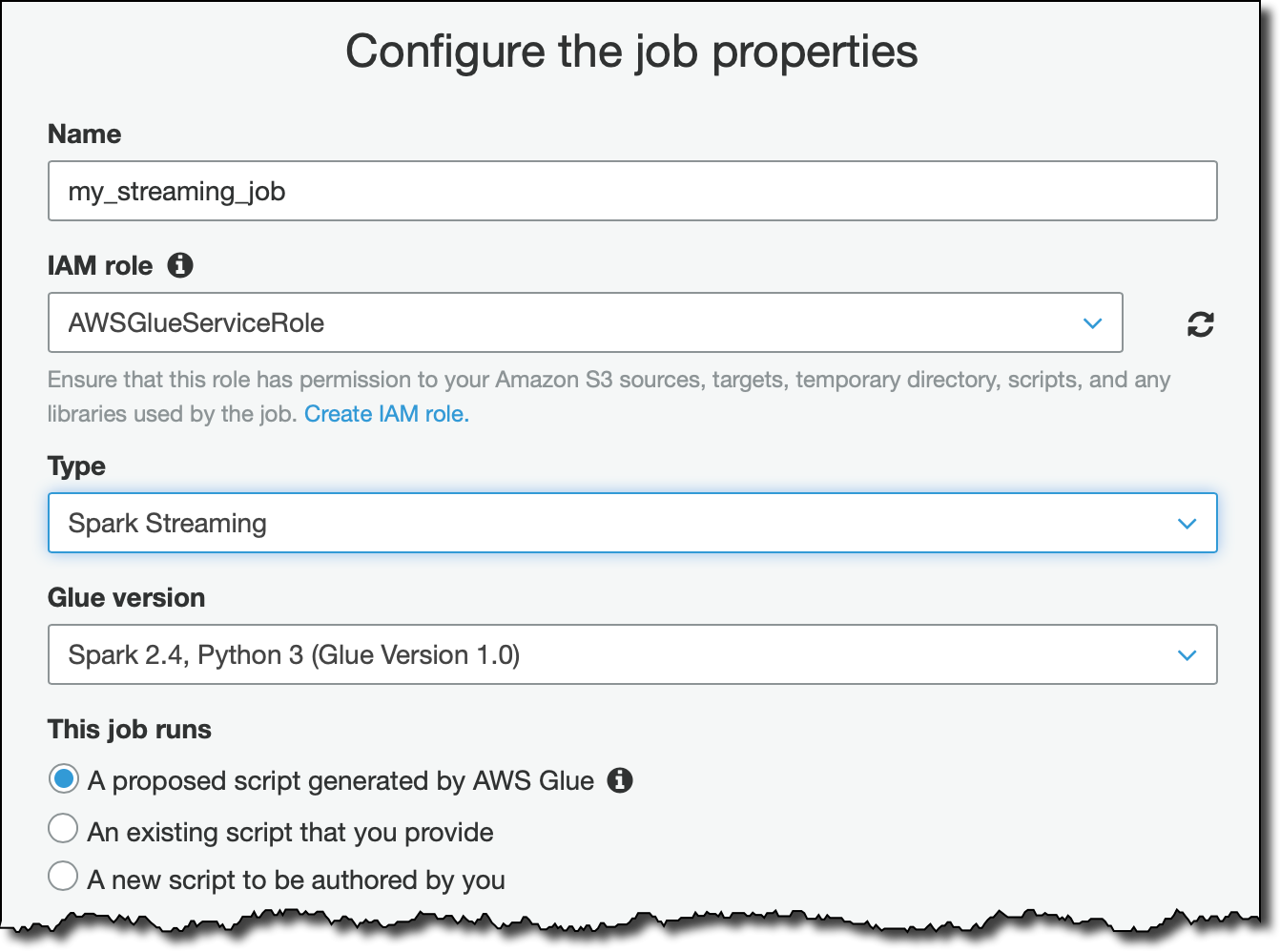
データソースで、作成したばかりのテーブルを選択し、Kinesis ストリームからデータを受信します。

Glue が作成したスクリプトを取得するには、スキーマの変更変換タイプを選択します。ターゲットで、Apache Parquet のような効率的なフォーマットを使用し、Glue データカタログに新しいテーブルを作成します。このジョブが作成した Parquet ファイルは、名前が aws-glue- で始まる (最後のハイフンを含む) S3 バケットに保存されます。AWSGlueServiceRole ポリシーで指定されたリソースの命名規則に従うと、このジョブにそれらのリソースにアクセスするために必要なアクセス許可が付与されます。
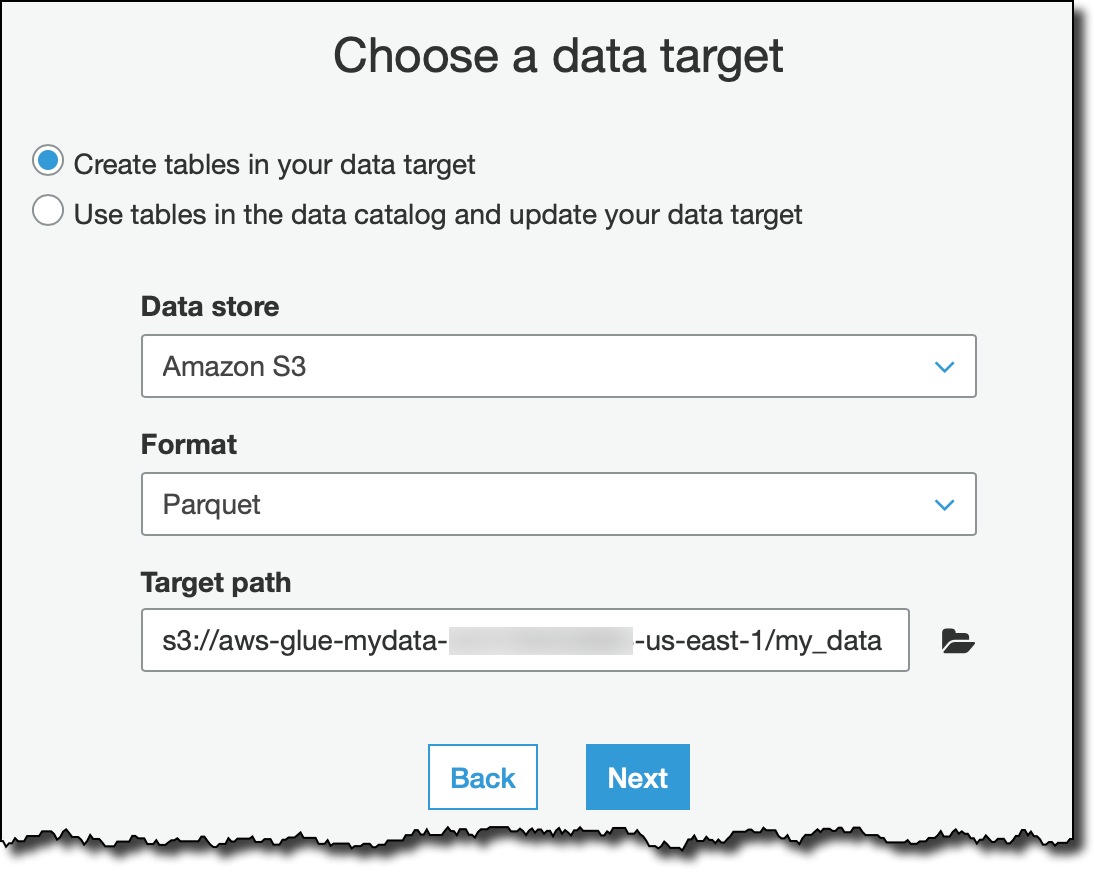
ソースストリームのすべての列を出力に保持するデフォルトのマッピングはそのままにしておきます。これで、コードを 1 行も記述することなく、仮のスクリプトを使用してすべてのレコードを取り込むことができます。

仮のスクリプトをさっと確認し、保存します。各レコードは DynamicFrame として処理されます。Glue PySpark 変換または Spark Structured Streaming がサポートしている変換を適用できます。この設定のデフォルトでは、ApplyMapping のみ使用します。

ジョブを開始して数分後、ジョブの出力を含む Parquet ファイルが出力 S3 バケットに表示されます。これらのファイルは、取り込み日 (年、月、日、時間) で分割されます。
S3 バケットのコンテンツに基づくテーブルを Glue データカタログに入力するには、クローラを追加して実行します。クローラの設定で、処理済みデータを追跡するために Glue が使用するチェックポイントフォルダーを除外します。1 分も経たないうちに、新しいテーブルが追加されました。
Amazon Athena コンソールで、データベースとテーブルを更新し、今年の取り込みデータを含む output_my_data のプレビューを選択します。テーブルの最初の 10 件のレコードが表示されるので、セットアップが機能していることを確認します。

これで、データが取り込まれるようになったので、より複雑なクエリを実行できます。 たとえば、デバイスセンサーから収集した最低温度と最高温度、Parquet ファイルに保存しているレコードの総数を取得できます。
結果を見ると、8,000 件を超えるレコードが処理されています。最高気温は摂氏 31 度 (華氏約 88 度) です。実際に、それほど暑くはありませんでした。温度はデバイスの近くにあるこれらのセンサーによって測定されますが、動作によりデバイス自体が温まるにつれて温度が上がります。

このセットアップでは単一のデバイスを使用していますが、ここで実装したソリューションは、データソースの数に応じて簡単に拡張できます。
今すぐご利用いただけます
AWS リージョン表で説明されているように、Glue を提供しているすべてのリージョンでストリーミングソースのサポートをご利用いただけます。詳細については、ドキュメントをご覧ください。
Glue を使用してサーバーレス ETL パイプラインを管理することで、ストリーミングの取り込みプロセスの設定と管理がより簡単に、かつコスト効率も高くなり、実装の労力が軽減されるため、ビジネス分析に集中して取り組めます。このチュートリアルで行ったように、コードを記述せずに取り込みパイプライン全体をセットアップしたり、あるいは、仮のスクリプトを必要に応じてカスタマイズしたりできます。
これらの新しい機能を皆さんがどのように活用しているか、ぜひお知らせください。