Amazon Web Services ブログ
Amazon CloudWatch で GPU 使用率をモニタリング
GPU には何千ものコアがあるため、ディープラーニングには大量のマトリックス乗算と GPU (グラフィックス処理ユニット) により並列化できるベクトルオペレーションが必要です。アマゾン ウェブ サービスでは P2 または P3 インスタンスにサインアップすることが可能です。このようなインスタンスは、大規模なディープニューラルネットワークのデプロイの加速化を強調する MXNet のようなディープラーニングフレームワークの実行に優れています。
データサイエンティストや開発者はネットワークを微調整する場合、適切なバッチサイズを使用できるように GPU 使用率を最適化したいと考えています。今回のブログでは、Amazon CloudWatch メトリクスを使用して GPU とメモリ使用量をモニタリングする方法をご説明します。Amazon マシンイメージ (AMI) では、インスタンスが Amazon Deep Learning AMI を使用することを勧めています。
GPU を有効にしたインスタンスのモニタリングや管理をサポートするために使用されている現在の一般的な方法は、コマンドラインユーティリティの NVIDIA システム管理インターフェイスを利用することです (nvidia-smi)。nvidia-smi の使用により、ユーザーは GPU 使用率、メモリ消費量、ファンの使用量、電力消費量、そして NVIDIA GPU デバイスの温度などの情報をクエリすることができます。
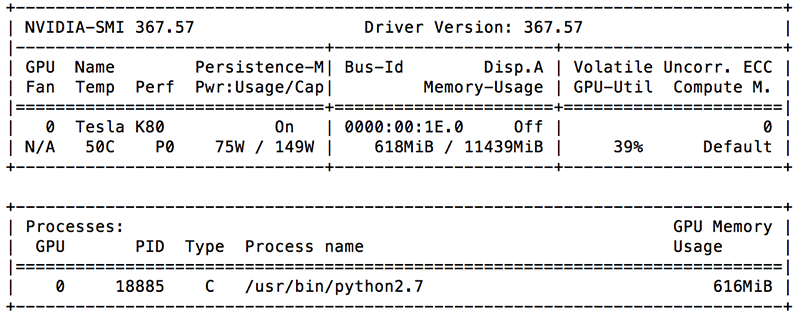
nvidia-smi は NVIDIA 管理ライブラリをベースにしているので (NVML)、C ベースの API ライブラリを使用し、カスタムメトリクスとして Amazon CloudWatch に送信するのと同じデータポイントをキャプチャできます。このライブラリに関する詳細については「リファレンスマニュアル (reference manual)」をご覧ください。このブログではライブラリに Python ラッパーの pyvnml を使用します。
Amazon CloudWatch は、システムやインフラストラクチャのセットアップ、管理、スケールを必要とせずに EC2 インスタンスでワークロードをモニタリングする場合に大変優れています。デフォルトにより、CloudWatch は CPUUtilization、DiskReadOps、DiskWriteOps、NetworkIn、NetworkOut といったメトリクスを提供するようになっています。(インスタンスのメトリクス一覧についてはこちらをご覧ください)
こうしたメトリクスの他にも API、SDK または CLI を使用し Amazon CloudWatch カスタムメトリクス を介して独自のデータポイントをプッシュすることもできます。Python Boto3 SDK を使用します。
Amazon CloudWatch 内でカスタムダッシュボードを作成し、リソースを見ることができます。メトリクスにアラームを作成することもできます。CloudWatch と併せて使用できる機能やサービスが他にもあります。Amazon EC2 インスタンスからログにアクセスしたり保存したい場合は Amazon CloudWatch Logs を使用できます。さらに Amazon CloudWatch Events では、モデルのトレーニングが完了する前に誰かがインスタンスを終了しようとしている場合にアラートが届くようにするなど、AWS リソース内の変更を表すデータのストリームを取得することも可能にします。
セットアップ
デフォルトでは、インスタンスで基本モニタリングが有効になります。Amazon EC2 コンソールがインスタンスを 1 分間隔でモニタリングを表示するように詳細モニタリングを有効にします。
注意: 基本モニタリングは無料ですが、詳細モニタリングは有料となります。新規および既存のお客様は毎月無料でメトリクス 10、アラーム 10、API リクエスト 100 万件 (PutMetricData を含む) をご利用いただけます。
Deep Learning AMI ですでにインスタンスを実行していると仮定します。この場合、メトリクスを Amazon CloudWatch にプッシュするための許可をインスタンスに与える IAM ロールを作成する必要があります。「ドキュメント (documentation)」で説明されているように、EC2 サービスロールを作成する必要があります。ロールで次のポリシーが許可されているか確認してください。
次に、インスタンスに Python コードをダウンロードします。このスクリプトを使用して、GPU 使用量、メモリ使用量、温度、電力消費量をカスタムの CloudWatch メトリクスとしてプッシュします。
コードに必要なパッケージをインストールします。
ワークロードに適合するように、名前空間と間隔を変更してください。GPU 使用量の 1 分未満の情報を取得できるように store_reso を変更することで、高解像度メトリクスを 1 秒で使用することも可能です。
デフォルトにより、トップにあるパラメーターは次のようになります。
次のスクリプトを実行します。
トレーニングが完了したら、ctrl-z または ctrl-c を押してスクリプトを終了します。
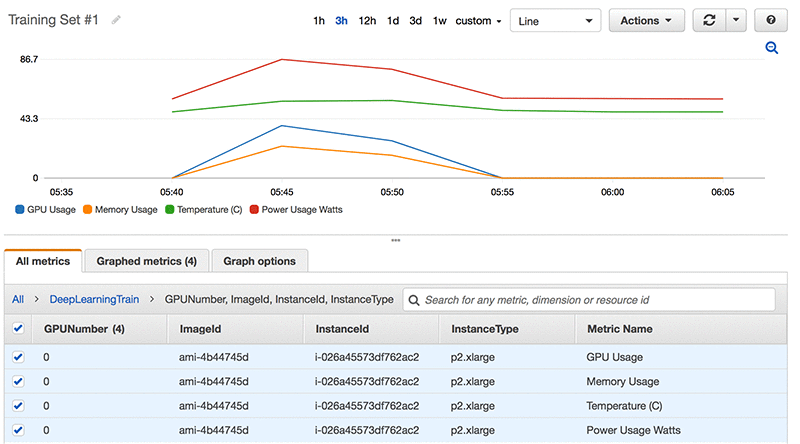
こちらは Amazon CloudWatch トレーニング実行の一例です。計算中に、どのようにすべてのメトリクスが関連付けられているか確認します。
まとめ
このブログ記事では NVIDIA GPU デバイスの GPU 使用率だけでなく、メモリ、温度、電力消費量も簡単にモニタリングする方法をご紹介しました。別のカスタムメトリクスを追加または削除したい場合のために、変更を可能にするコードもお見せしました。次は冒頭で触れたようにメトリクスで CloudWatch アラーム を作成してみてください。たとえば、Amazon SNS 通知をセットアップして、モデルトレーニングの間に GPU 使用率が 20% 以下になった場合にメールが届くようにすることができます。
その他の参考資料
AWS Deep Learning AMI を使用してディープラーニングを始めてみましょう!

今回のブログの投稿者について
 Keji Xu はサンフランシスコの AWS ソリューションアーキテクトです。Keji は AWS のお客様が高度なクラウドベースソリューションを理解しやすく、そして既存のワークロードをクラウドに移行してビジネス目的を達成できるようにサポートしています。余暇には音楽の演奏やニューイングランド地方のスポーツチームを応援しています。
Keji Xu はサンフランシスコの AWS ソリューションアーキテクトです。Keji は AWS のお客様が高度なクラウドベースソリューションを理解しやすく、そして既存のワークロードをクラウドに移行してビジネス目的を達成できるようにサポートしています。余暇には音楽の演奏やニューイングランド地方のスポーツチームを応援しています。