Amazon Web Services ブログ
AWS DataSync を使用して Azure Blob Storage から Amazon S3 へ移行する
UPDATE (2023/7/25): AWS DataSync において Azure Blob Storage へのデータコピーが一般提供開始となりました。詳細は What’s New や動画をご確認ください。
UPDATE (2024/3/26): AWS DataSync エージェントをデプロイする際、 Amazon Linux 2 ( AL2 ) 上で DataSync Agent の VHDX ファイルを VHD 形式に変換し、変換されたディスクを Azure にアップロードして Azure Virtual Machine を作成するためのスクリプトが公開されました。
UPDATE (2025/5/29): AWS DataSync は Enhanced モードをクラウド間転送でサポートしました。Enhanced モードでは DataSync エージェントが不要となり AWS と他のクラウド間のデータ転送を簡素化します。また、Basic モードと比較してより高いパフォーマンスとスケーラビリティを提供します。詳細については、What’s New やドキュメントを確認してください。
このブログは 2023 年 3 月 29 日に Rodney Underkoffler (シニアソリューションアーキテクト)、Aidan Keane (シニアスペシャリストソリューションアーキテクト) によって執筆された内容を日本語化したものです。原文はこちらを参照してください。
AWS サービス間のデータ転送、オンプレミスから AWS へのデータ移動、他のパブリッククラウドやストレージメディア間のデータ移行など、さまざまなデータ移行要件について、私たちは日々お客様とお話ししています。これらのリクエストに共通するテーマの 1 つは、AWS ネイティブでシンプルかつ費用対効果の高いデータ転送方法が必要だということです。お客様は、単にデータを別の場所に移動するためだけの、独自のスクリプト、スケジューリングツール、および監視ソリューションを作成して維持することを望んでいません。
その結果、AWS Snow ファミリー、AWS Transfer Family、AWS DataSync などのサービスが生まれました。また 2022 年には、AWS と他のパブリッククラウド間でデータを移動する AWS DataSync の機能の追加など、AWS は常に機能の追加や改善に取り組んでいます。これには、AWS DataSync における Azure Files の SMB 共有のサポートが含まれます。そして今回 AWS DataSync は、サポート対象のロケーションとして Azure Blob Storage のプレビュー版提供を開始しました。これにより、データを Amazon Simple Storage Service (Amazon S3)、Amazon Elastic File System (Amazon EFS) そして Amazon FSx などの AWS Storage サービスへ簡単に転送できるユースケースが増えました。
このブログでは、AWS DataSync を使用して Azure Blob Storage オブジェクトを Amazon S3 に移行する方法について説明します。この記事の執筆時点 (2023 年 4 月 18 日) では、Azure で使用可能なネイティブの AWS DataSync エージェントは存在しておりません。そのため、既存の Hyper-V AWS DataSync エージェントを使用した、Azure Blob Storage から Amazon S3 へのデータ移行を高速化する方法を紹介します。AWS DataSync エージェントは Amazon EC2 にデプロイすることもできますが、転送元ストレージの近くにデプロイすることで、インライン圧縮などのネットワーク最適化により、Azure から Amazon S3 にデータを移動する際の Azure データ送信料金を削減できます。
AWS DataSync が Azure Blob Storage からのデータコピーをサポート
AWS DataSync は、大規模なデータ転送を簡単に自動化できるフルマネージド型のオンラインデータ転送サービスです。AWS DataSync は、数回のクリックまたはコマンドラインでエージェントをデプロイできます。これにより、独自のユーティリティソフトウェアをデプロイしたり、スケジュールされたカスタムスクリプトを管理することなく、安全で信頼性の高いデータ転送タスクを実行できます。
転送元ロケーションとして Azure Blob Storage コンテナーを選択すると、AWS DataSync は最大 5 TB の Azure Blob Storage オブジェクトを、2 KB 以下のオブジェクトメタデータと共に転送します。Azure Blob Storage メタデータとは、作成者名、ドキュメントタイプ、ドキュメントクラスなどのユーザーが定義した名前と値のペアや、システムプロパティなどの追加情報です。
Azure Blog Storage は、ホットアクセス層、クールアクセス層、アーカイブアクセス層の 3 つのアクセス層を提供します。ホットアクセス層とクールアクセス層はオンラインアクセス層と呼ばれ、お客様の要求に応じてすぐにデータにアクセスできることを意味します。アーカイブアクセス層は、ほとんどアクセスされないデータを対象としています。アーカイブデータを AWS ストレージに転送する場合、それらのオブジェクトをアーカイブアクセス層からオンラインアクセス層にリハイドレートする必要があります。AWS DataSync は、アーカイブアクセス層に格納されている Azure Blob Storage オブジェクトについて、エラーを生成するのではなく単にスキップします。
ソリューションの概要と AWS DataSync の用語
AWS DataSync には、データ移動のための 4 つのコンポーネント (エージェント、ロケーション、タスク、およびタスク実行) があります。図 1 は、このチュートリアルで使用するコンポーネントと構成設定の関係を示しています。

図 1: AWS DataSync の主要コンポーネント
- エージェント : ロケーションからデータを読み取る、またはデータを書き込む仮想マシン (VM) です。このチュートリアルでは、Azure 仮想ネットワーク内の Azure VM に AWS DataSync エージェントをデプロイします。
- ロケーション : データの転送元と転送先です。このチュートリアルでは、転送元は Azure Blob Storage コンテナー、転送先は Amazon S3 バケットです。
- タスク : タスクは、1 つの転送元ロケーションと 1 つの転送先ロケーションから構成され、データの転送方法を定義するタスク設定が含まれます。タスクは転送元から転送先へ、データを常に同期させます。設定には、include/exclude フィルター、タスクスケジュール、帯域幅の制限などのオプションが含まれます。
- タスク実行 : これはタスクを個別に実行したもので、開始時刻、終了時刻、書き込まれたバイト数、ステータスなどの情報が含まれます。
次の図は、AWS DataSync を使用して Azure Blob Storage から Amazon S3 にデータを移行する方法を示しています。
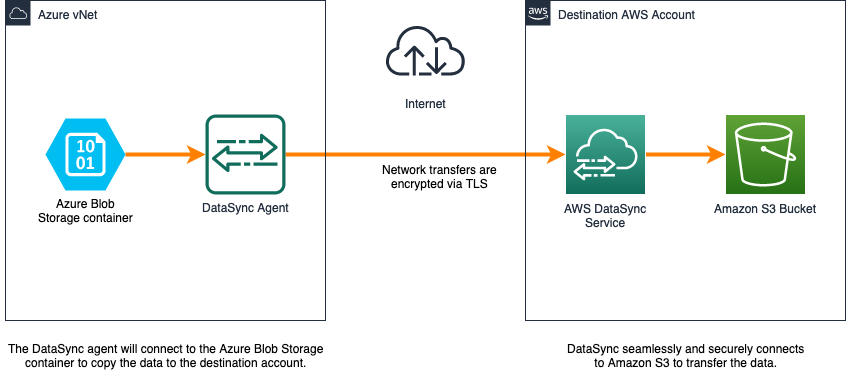
図 2: Azure Blob Storage コンテナーを転送元とする AWS DataSync のアーキテクチャ
AWS DataSync エージェントのサイジングガイド
Azure に AWS DataSync エージェントをデプロイする場合は、 転送するファイル数に応じたインスタンスサイズを選択してください。
以下は推奨される最小限のリソースです。
- 仮想プロセッサ – VM に割り当てられた 4 つの仮想プロセッサ。
- ディスク容量 – VM イメージとシステムデータのインストール用に 80 GB のディスク容量。
- RAM – データストアの構成に応じて、次のようになります。
- 最大 2,000 万ファイルを転送するタスク – VM に割り当てられた 32 GB の RAM。
- 2,000 万を超えるファイルを転送するタスク – VM に割り当てられた 64 GB の RAM。
Amazon EC2 インスタンスに AWS DataSync エージェントをデプロイして Azure ストレージにアクセスすることも可能です。一方で、転送元ストレージと同じネットワークに AWS DataSync エージェントをデプロイすることで、ネットワークレイテンシが減少し、AWS が設計した転送プロトコルによってインラインデータ圧縮が利用可能となり、Azure ストレージアカウントのパブリックエンドポイントが不要になります。
Transport Layer Security (TLS) 1.2 は、転送元と転送先の間で送信されるすべてのデータを暗号化します。さらに、データが AWS DataSync 自体に永続化されることはありません。さらにこのサービスは、Amazon S3 バケットのデフォルト暗号化をサポートしています。
前提条件
このチュートリアルの手順を完了するには、以下が必要です。
- AWS アカウント
- Azure アカウントサブスクリプション
- Amazon S3 バケット
- Azure Blob Storage コンテナー
- PowerShell
- Azure CLI
- AzCopy
- 次の Windows 機能をローカルマシンで有効にする必要があります。
- Windows PowerShell 用 Hyper-V モジュール
- Hyper-V サービス
Azure Blob Storage コンテナーを構成する方法については、こちらを参照してください。Amazon S3 バケットについても用意する必要があり、作成方法についてはこちらを参照いただけます。このチュートリアルの後半で登場しますが、Amazon S3 バケットを「datasynctest1234」、Azure ストレージ アカウントを「awsblobdatasync」と命名しています。
AWS DataSync エージェントのデプロイ
このセクションでは、AWS DataSync エージェントのデプロイと設定を行います。
ステップ 1: デプロイ用の AWS DataSync エージェントイメージを準備する
- https://console.thinkwithwp.com/datasync/ にアクセスし、AWS DataSync コンソールを開きます。
- コンソールの「エージェントを作成する」ページにある「ハイパーバイザー」ドロップダウンメニューから「Microsoft Hyper-V」を選択します。
- 「エージェントをデプロイする」で「イメージをダウンロードする」を選択すると、仮想ハードディスク v2(VHDX)イメージファイルを含む .zip ファイルにてエージェントがダウンロードされます。
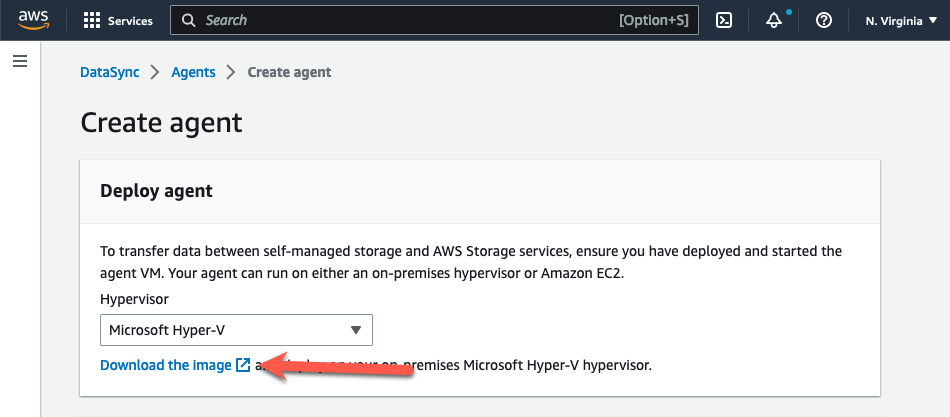
図 3: AWS DataSync エージェントのダウンロード
- VHDX イメージファイルを含んだ zip ファイルを、ローカルマシンにて解凍します。
- Azure との互換性のために、VHDX ファイルを固定サイズの VHD ファイルに変換する必要があります。Azure へのアップロード用に VHDX を準備する方法の詳細については、こちらを参照してください。パスとファイル名を更新して次のコマンドを実行します。
Convert-VHD -Path .\<path to vhdx>\aws-datasync-2.0.1678813931.1-x86_64.xfs.gpt.vhdx -DestinationPath .\<path to vhdx>\ aws-datasync-2016788139311-x86_64.vhd -VHDType Fixed
ステップ 2: VHD をマネージドディスクにアップロードする
- 空のマネージドディスクを過不足なく作成するために、VHD ファイルのサイズを確認します。VHD ファイルを含むディレクトリで「ls -l」コマンドを実行します。これにより、VHD ファイルのバイト数がわかります。これは、後ほど「–upload-bytes-parameter」で必要になります。

図 4: AWS DataSync VHD ファイルのサイズ確認
- 次のコマンドを実行して、空のマネージドディスクを作成します。この時、パラメータを自身の環境に基づいて変更します。
az disk create -n <yourdiskname> -g <yourresourcegroupname> -l <yourregion> --upload-type Upload --upload-size-bytes 85899346432--sku standard_lrs
- 共有アクセス署名 (SAS) を生成し、書き込みを許可します。
az disk grant-access -n <yourdiskname> -g <yourresourcegroupname> --access-level Write --duration-in-seconds 86400
- AWS DataSync VHD ファイルを空のマネージドディスクにアップロードします。
AzCopy.exe copy "c:\somewhere\mydisk.vhd" "sas-URI"--blob-type PageBlob
- アップロードが完了したら SAS を削除して、ディスクを新しい VM にマウントする準備をします。
az disk revoke-access -n <yourdiskname> -g <yourresourcegroupname>
ステップ 3: AWS DataSync エージェント VM を作成する
az vm create --resource-group myResourceGroup --location eastus --name myNewVM --size Standard_E4as_v4 --os-type linux --attach-os-disk myManagedDisk
- ブート診断を有効にします。
- シリアル接続で接続し、エージェントのローカルコンソールにログインします。
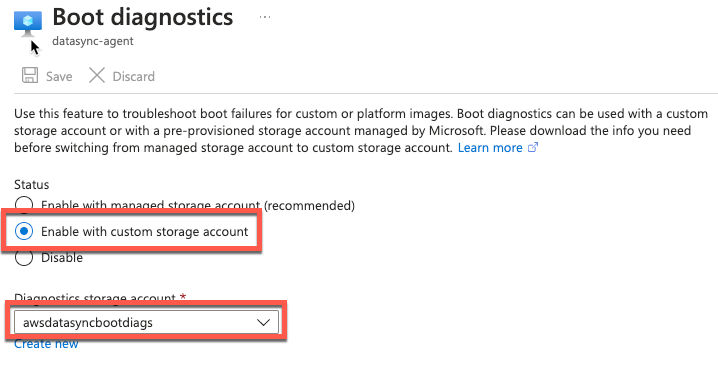 図 5: ブート診断を有効化
図 5: ブート診断を有効化
- AWS DataSync Activation – Configuration メインメニューで、0 を入力してアクティベーションキーを取得します。
- エージェントをアクティブにする AWS リージョンを入力します。
- エージェントが使用するサービスエンドポイントタイプを入力します。オプションには、パブリック、FIPS、および AWS PrivateLink を使用した VPC が含まれます。この例ではパブリックオプションを使用します。
- アクティベーションキーが自動的に生成され、画面に表示されます。この値は次のステップで使用します。
ステップ 4: AWS DataSync エージェント VM をアクティブ化する
- https://console.thinkwithwp.com/datasync/ で AWS DataSync コンソールを開きます
- コンソールの「エージェントを作成する」ページにある「ハイパーバイザー」ドロップダウンメニューから「Microsoft Hyper-V」を選択します。
- 「サービスエンドポイント」セクションは、エージェントをアクティブ化するリージョンで「公開サービスエンドポイント」オプションを選択します。
- 「アクティベーションキー」で、「エージェントのアクティベーションキーを手動で入力する」を選択し、エージェントのローカルコンソールからコピーした値を貼り付けます。
- 必要に応じてエージェントに一意の名前を入力し、「エージェントを作成する」ボタンをクリックします。
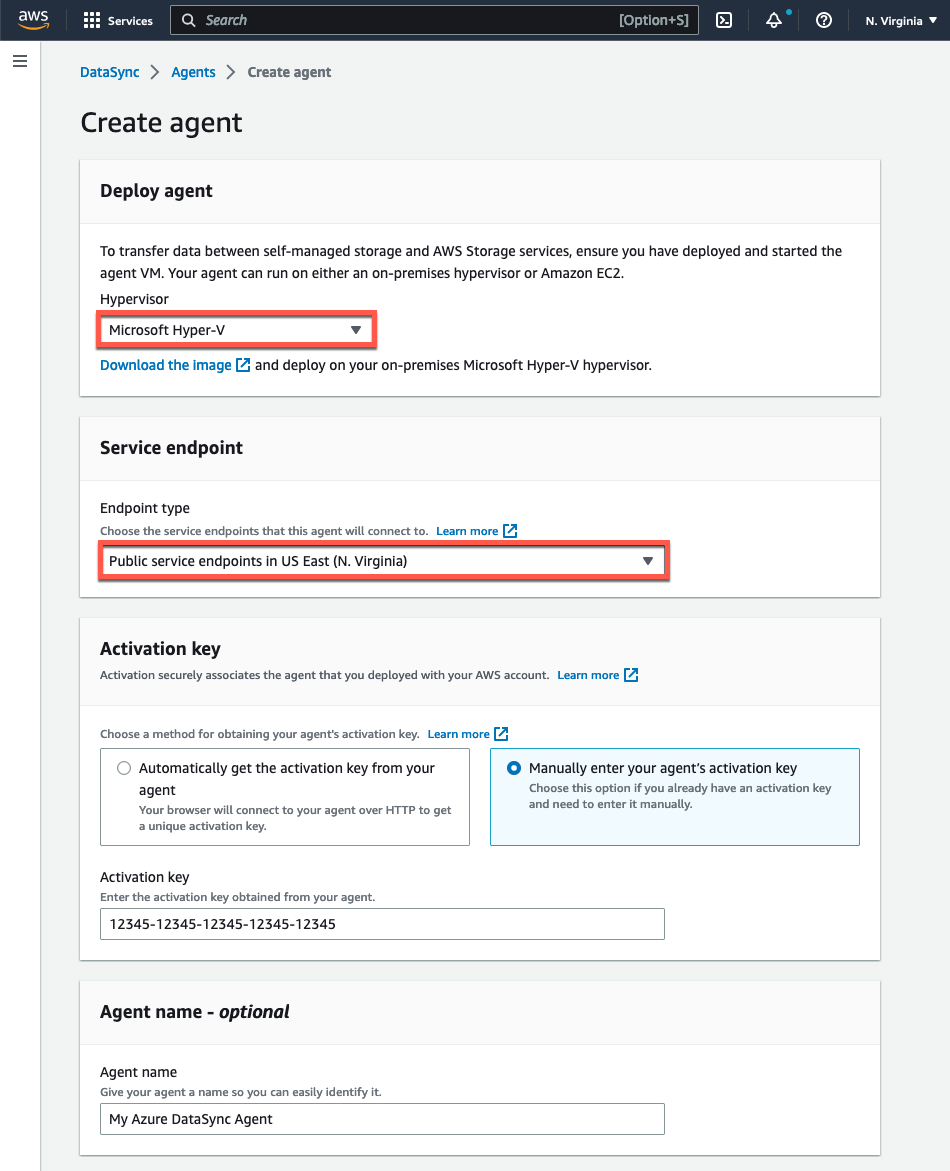
図 6: AWS DataSync エージェントの作成
データレプリケーションの設定
このセクションでは、ストレージのロケーションを作成し、データレプリケーションをセットアップするための必要な手順を実施します。
ステップ 1: 転送元 Azure Blob Storage のロケーションを設定する
転送元 Azure Blob Storage コンテナーを AWS DataSync のロケーションとして設定します。左側のナビゲーションパネルから 「ロケーション」を選択し、「ロケーションを作成する」を選択します。次に、「ロケーションタイプ」 として「Microsoft Azure Blob Storage」を選択します。前のステップで作成したエージェントが選択されていることを確認してください。

図 7: Azure Blob Storage ロケーションの作成
次に、コンテナー URL と SAS トークンを指定します。オプションでコンテナー内のフォルダパスを指定して、転送するフォルダを指定することもできます。次の手順に従って、コンテナー URL を取得し、Azure SAS トークンを生成します。
Azure SAS トークンは、ストレージアカウント内のリソースに対して委任されたアクセスを提供します。アクセスできるリソース、アクセス権限、および Azure SAS トークンの有効期間を定義することで、きめ細かく定義されたデータへのアクセスを可能にします。ストレージ アカウントレベルまたは Blob コンテナーレベルで Azure SAS トークンを生成できます。Azure Blob Storage コンテナーレベルでトークンを生成すると、アクセスを 1 つのコンテナーに制限することができます。
Azure SAS トークンは、Azure portal、Azure Storage Explorer、または Azure CLI を使用して生成できます。今回のチュートリアルでは、Azure portal メソッドを使用して、アカウントレベルのトークンを作成します。
- Azure portal 内からストレージアカウントに移動し、ページの左側から「Shared access signature」を選択します。Blob 以外の許可されたサービスをクリアします。
- 「Allowed resource types」から「Container」と「Object」を選択します。「Allowed permissions」から「read」と「list」を割り当てます。タグをコピーするために、「Allowed blob index permissions」セクションから Read/Write アクセス許可を割り当てます。Azure SAS トークンのアクセス許可の詳細については、こちらを参照してください。
- 署名された鍵の開始、および終了日時を指定します。トークンの有効期間がデータを移行するのに十分であることを確認してください。
- 設定を確認し、「Generate SAS and connection string」を選択します。
- Azure SAS トークンと Blob Service SAS URL の値が画面下部に表示されます。Azure SAS トークン の値を、AWS DataSync コンソールの Azure SAS トークンフィールドに貼り付けます。
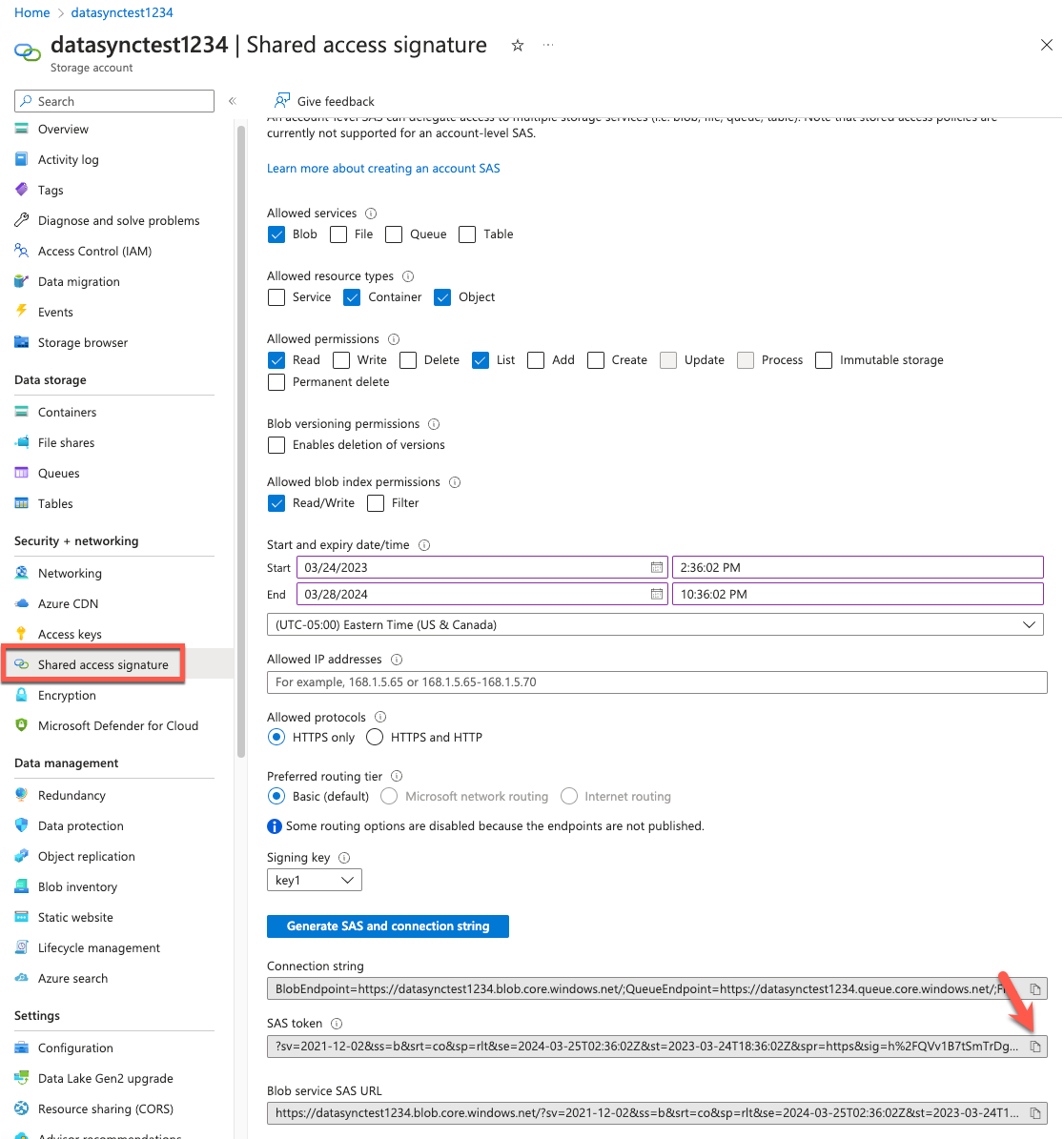
図 8: Azure SAS トークンの発行
- Azure Blob Storage コンテナーのプロパティから、コンテナーの URL をコピーします。
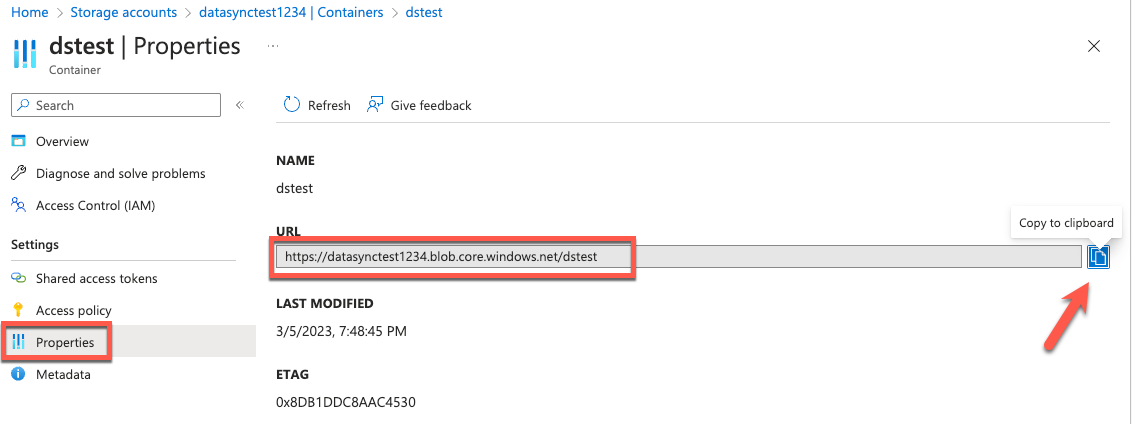
図 9: コンテナー URL の取得
ステップ 2: 転送先のロケーションを設定する
転送先のロケーションを Amazon S3 として設定します。左側のナビゲーションメニューから「ロケーション」を選択し、「ロケーションを作成する」をクリックします。転送先となる Amazon S3 バケットと、Amazon S3 ストレージクラス、フォルダー、および Amazon S3 バケットにアクセスするための許可を持つ IAM ロールを選択します。AWS DataSync は、すべての Amazon S3 ストレージクラスにデータを直接転送できます。転送ごとに、ニーズに合った最も費用対効果の高いAmazon S3 ストレージクラス を選択することもできます。AWS DataSync は、転送先ファイルシステムまたはバケット内の、既存のファイルまたはオブジェクトを検出します。一度転送が完了した後、転送元と転送先の間で変更されたデータは、AWS DataSync タスクの連続的な実行で転送できます。

図 10: Amazon S3 ロケーションの作成
ステップ 3: レプリケーションタスクを作成する
ステップ 1 で作成した転送元 Azure Blob Storage のロケーション、ステップ 2 で作成した転送先 Amazon S3 バケットのロケーションをそれぞれ割り当て、タスク設定を構成します。タスク設定とオプションの詳細については、AWS DataSync の転送設定を参照してください。

図 11: 転送元ロケーションを設定する
転送元ロケーションを設定したら、「次へ」をクリックして、転送先 Amazon S3 バケットのロケーションを選択します。

図 12: 転送先ロケーションを構成する
以下は、上記手順を反映した設定の例です。
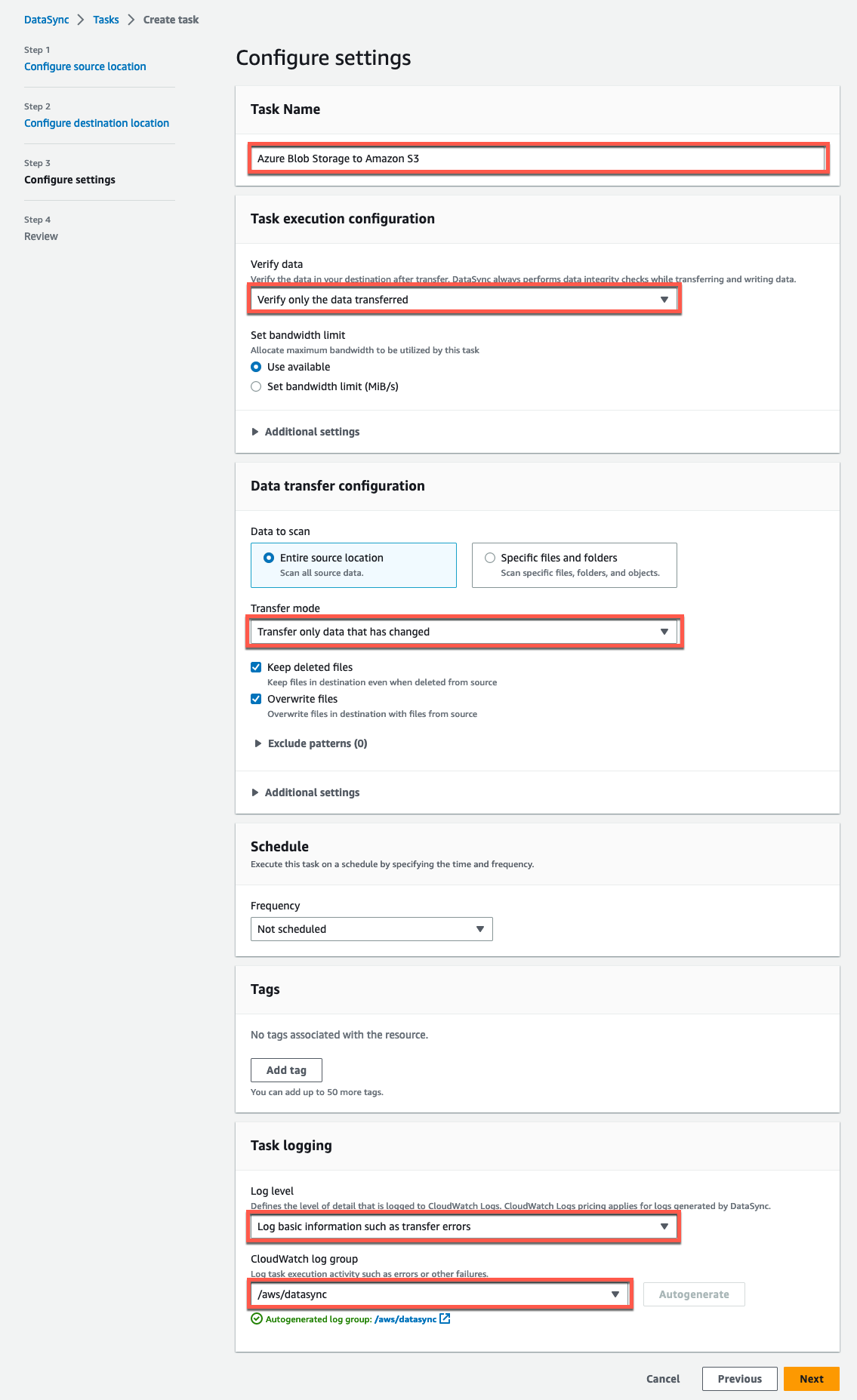 図 13: AWS DataSync タスクの設定
図 13: AWS DataSync タスクの設定
ステップ 4: AWS DataSync タスクを開始する
タスクリストまたはタスク概要内の「開始」をクリックして、AWS DataSync によるデータ転送をスタートします。詳細については、AWS DataSync タスクの実行や Amazon CloudWatch を使用した AWS DataSync タスクのモニタリングを参照してください。
このチュートリアルの手順を完了すると、Azure Blob Storage のデータを Amazon S3 に移動するための効率的かつ安全なデータパイプラインが作成されます。AWS DataSync タスクが実行されるたびに、転送元と転送先のロケーションで変更がないかスキャンし、データとメタデータの差分がコピーがされます。AWS DataSync タスクには、起動、準備、転送、および検証という複数のフェーズがあります。準備フェーズにかかる時間は、転送元と転送先のロケーションにあるファイル数によって異なりますが、通常数分から数時間かかります。AWS DataSync タスクにおけるフェーズの詳細については、AWS DataSync の仕組みを参照してください。
クリーンアップ
AWS 料金の詳細については、AWS DataSync のドキュメントを参照してください。AWS におけるインバウンドデータ転送に追加料金は発生しませんが、Azure のソースアカウントにおいてデータ転送料金が発生する場合があります。アウトバウンドデータ転送の料金詳細については、ベンダーの価格設定サイトを参照してください。作成したリソースに対する継続的な課金を回避するには、次の手順に従います。
- データレプリケーションの設定のステップ 3 で作成した、AWS DataSync タスクを削除します。
- データレプリケーションの設定のステップ 1 と 2 で作成した、転送元と転送先のロケーションを削除します。
- AWS DataSync エージェントのデプロイのステップ 3 で作成した、AWS DataSync エージェントを削除します。
- AWS DataSync エージェントのデプロイで作成した、 Azure VM と接続されたリソースを削除します。
- データレプリケーションの設定のステップ 2 にて指定した、Amazon S3 バケット内のすべてのオブジェクトを削除します。バケットの削除手順に従って、バケットを削除する前に中身を空にする必要があります。
まとめ
このブログでは、Azure 上に AWS DataSync エージェントをデプロイする方法について、順を追って説明しました。カスタマイズされたスクリプトやユーティリティを使用せずに、オブジェクトデータを Azure Blob Storage コンテナーから AWS 上の Amazon S3 バケットにコピーする AWS DataSync タスクを作成しました。
お客様は、Azure Blob Storage から Amazon S3、Amazon Elastic File System、およびサポートされている任意の Amazon FSx ファイルシステム等の AWS ストレージサービスに、簡単にデータを移行できます。AWS ストレージサービスから Azure Blob Storage へのデータコピーのサポートは、一般提供開始時 (GA) に機能の一部として追加される予定です。AWS DataSync のようなマネージドサービスを活用すると、追加のインフラストラクチャを管理する負担がなくなり、運用時間が短縮され、大規模なデータ移動の複雑さが軽減されます。
AWS DataSync の使用を開始するのに役立つその他のリソースを次に示します。
- AWS DataSync のリソース
- AWS DataSync ユーザーガイド
- AWS re:Post
- AWS DataSync Primer – 無料で 1 時間の自習用オンラインコース
- AWS DataSync を使用して Azure Files の SMB 共有から AWS にデータを移行する方法
AWS DataSync を使用した Azure Blob Storage から Amazon S3 への移行に関する本ブログをお読みいただき、ありがとうございました。ぜひ今日からこのソリューションをお試しください。
翻訳はネットアップ合同会社の藤原 善基、監修は吉澤 巧が担当しました。