Amazon Web Services ブログ
AWS Glue – 一般提供開始
本日、AWS Glue の一般提供開始がアナウンスされました。Glue はフルマネージドでサーバレス、そして、クラウド最適化された ETL(extract, transform, load) サービスです。Glue は他の ETL サービスやプラットフォームと、いくつかのとても重要な点で違いがあります。第1に、Glue はサーバレスです — リソースのプロビジョニングや管理を行う必要はありません。ジョブ、もしくは、クローリングを実行している間に Glue が使用したリソースに対する支払いのみで利用可能です(分単位課金) 。第2に、Glue のクローラです。 Glue のクローラは、複数のデータソース、データタイプ、そして、様々な種類のパーティションを跨いで、スキーマを自動的に検出・推測することができます。クローラは生成されるスキーマを編集・版管理・クエリ実行・分析で利用するため、一元的に Data Catalog に保存します。第3に、Glue はデータを元々のフォーマットから目的のフォーマットに変換する Python で記述された ETL スクリプトを自動的に生成することができます。最後に、Glue は開発者がお気に入りのツールセットを使用して ETL スクリプトを組み立てることができるように、開発者向けのエンドポイントを作成できるようになっています 。それでは詳細を具体的に見ていきましょう!
私は開発者向けエヴァンジェリストとしての仕事の中で、飛行機での移動に多くの時間を費やします。そこで、フライトデータで何かできたらかっこいいのではと考えました。ありがたいことに、アメリカ交通統計局(Bureau of Transportations Statistics: BTS) はこのサイトを利用し、全てのデータを誰にでも共有してくれます。私たちは簡単にデータをダウンロードし、Amazon Simple Storage Service (S3) に保存することができます。このデータが今回の基礎データとなります。
Crawlers

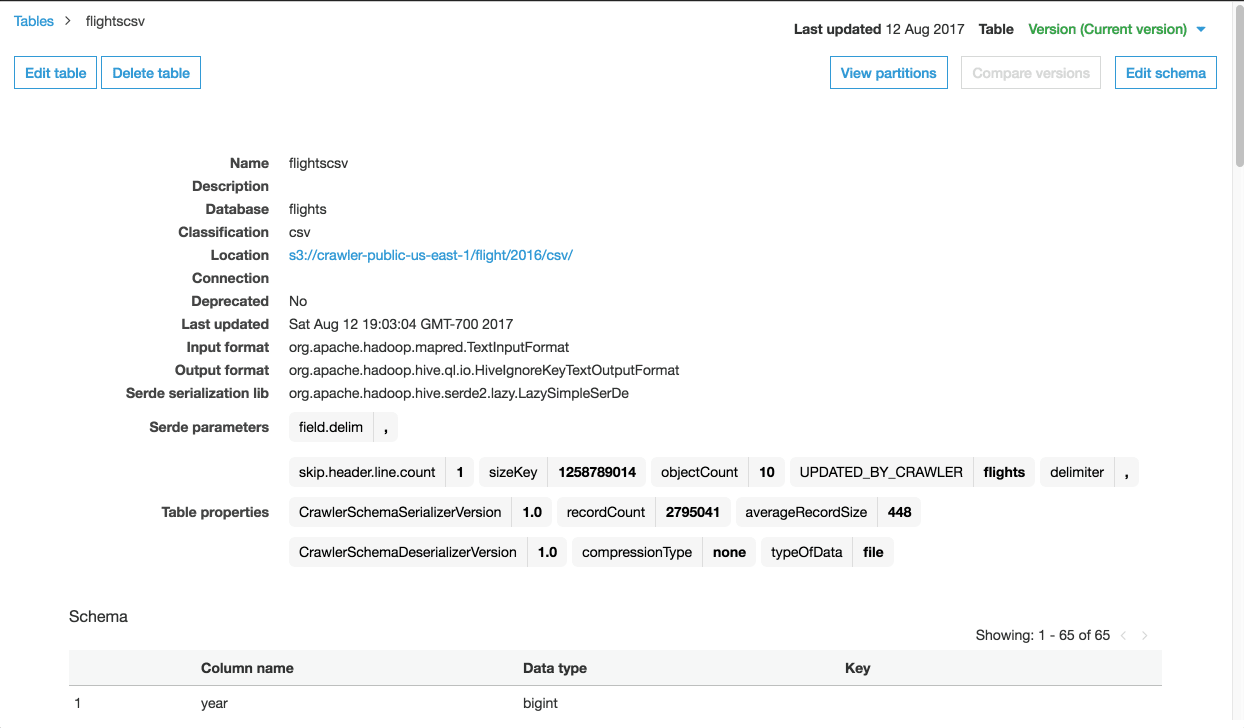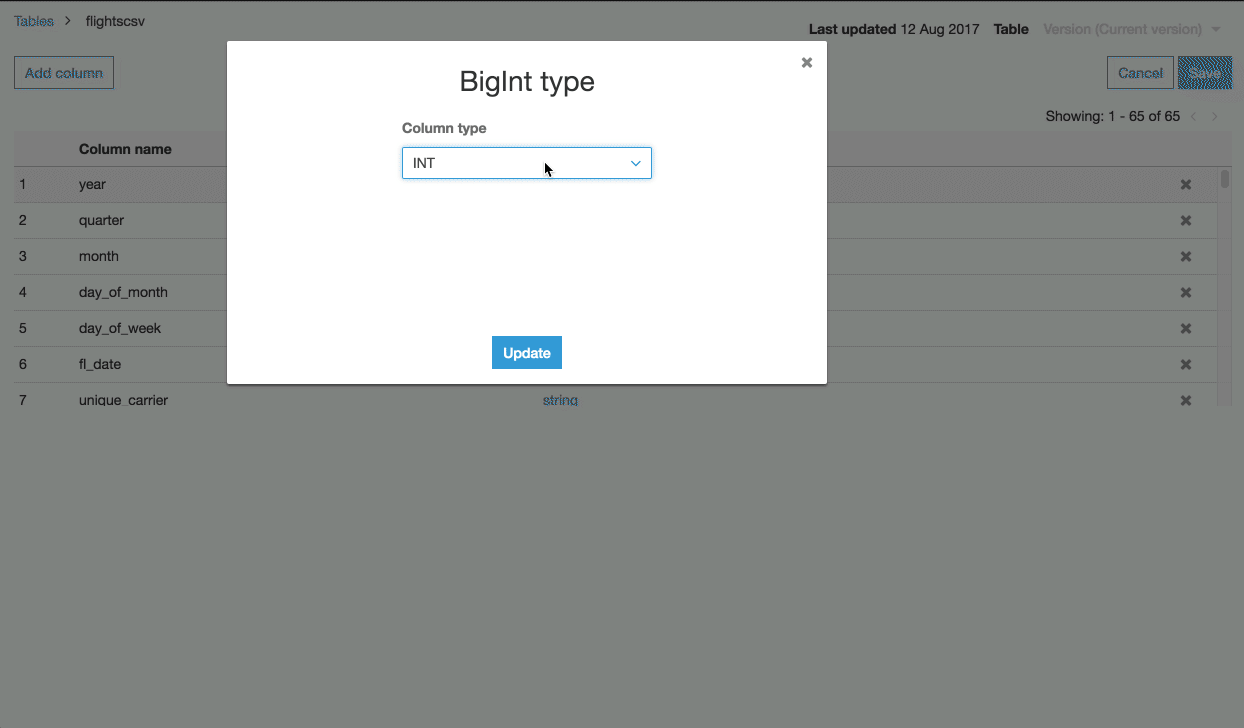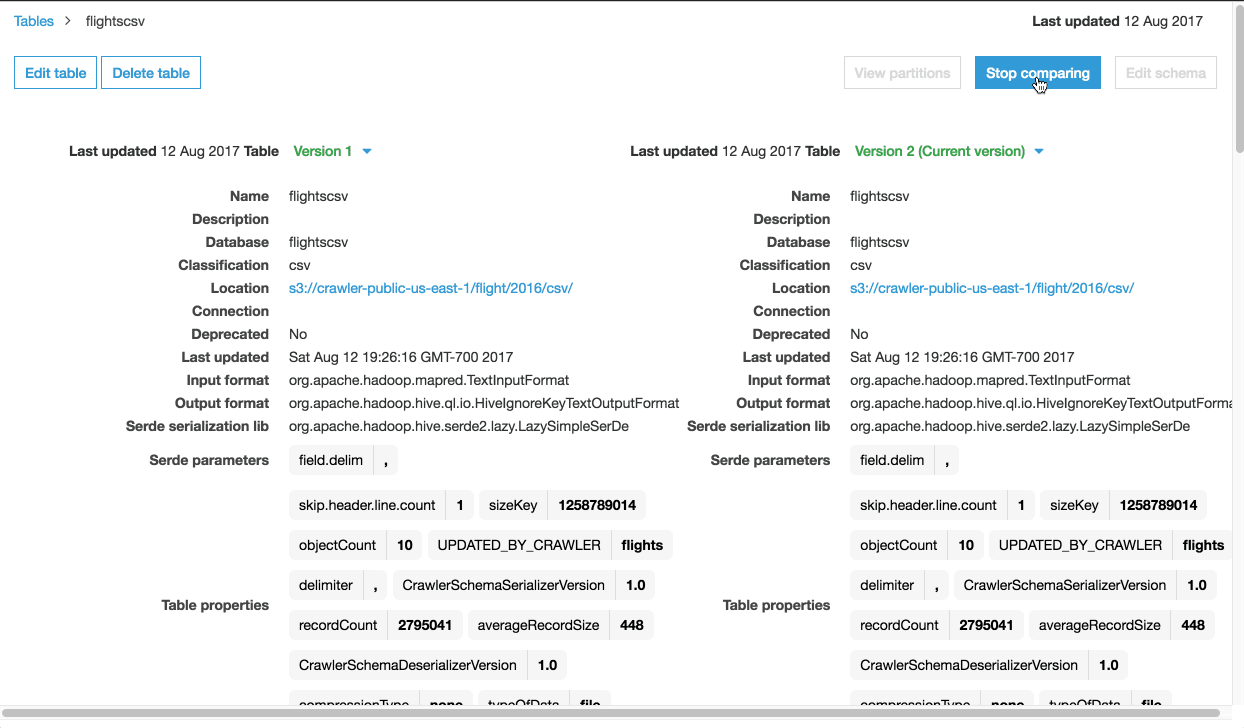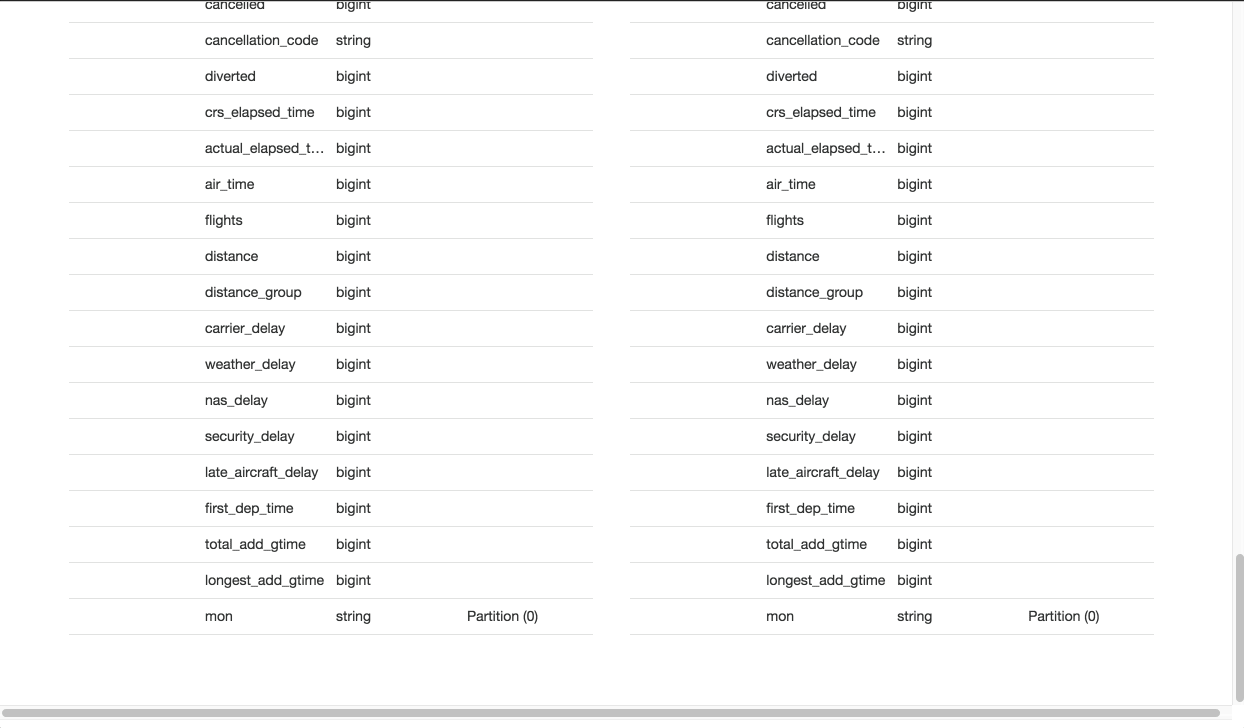
まず、私たちは S3 にあるフライトデータに対して、クローラを生成する必要があります。Glue のコンソールでクローラを選択し、画面の指示に従って進めます。最初のデータソースとして s3://crawler-public-us-east-1/flight/2016/csv/を指定します(データは必要に応じて追加か可能です)。次に、”flights” データベースを作成し、各テーブルに同様の “flights” 接頭語を付けるようにします。
クローラはデータセットを調べ、様々なフォルダーからパーティション(この例の場合は、年月)やスキーマを検出し、テーブルを構成します。クローラに別のデータソースやジョブを追加することや、同じデータベースにデータを登録する別のクローラを作成することもできますが、ここでは自動生成されたスキーマを見ていきましょう。

スキーマ変更(型を BIGINT から INT に変更する)を “year” に対して実施します。その時、必要であれば2つのスキーマバージョンを比較することができます。
これで、正しくデータをパースする方法を把握したので、次はいくつか変換処理を試してみましょう。
ETL Jobs
さあ、Job用のサブコンソール画面に移動し、”Add Job” をクリックしましょう。画面の指示に従い、Job に名前、選択するデータソース、そして、テンポラリファイルを配置する S3 ロケーションを設定します。次に、”Create tables in your data target” を指定することでターゲットを追加し、ターゲットとしてParquet フォーマットで出力されるデータを配置する S3 ロケーションを指定します。

”Next” をクリックすると、Glue によって提案される様々なデータの対応関係を表示する画面に遷移します。必要に応じてカラムのマニュアル調整を行うことができます — ここでは、必要のない幾つかのカラムを “X” ボタンを使って消していきましょう。

次の画面で提供される機能が私達を私の好きなパートに誘います。これが Glue について絶対的に好きなところです。

Glue は今までに設定してきた情報に基づき、データを変換するための PySpark スクリプトを生成します。左側のダイアグラムで、ETL ジョブのフローを確認することができます。右上には、注釈付きのデータソースやターゲット、trasnsform、spigot、そしてその他機能を追加するために使えるボタン一式が見て取れます。次の画面が、”transform” をクリックすると表示されるインタフェースです。
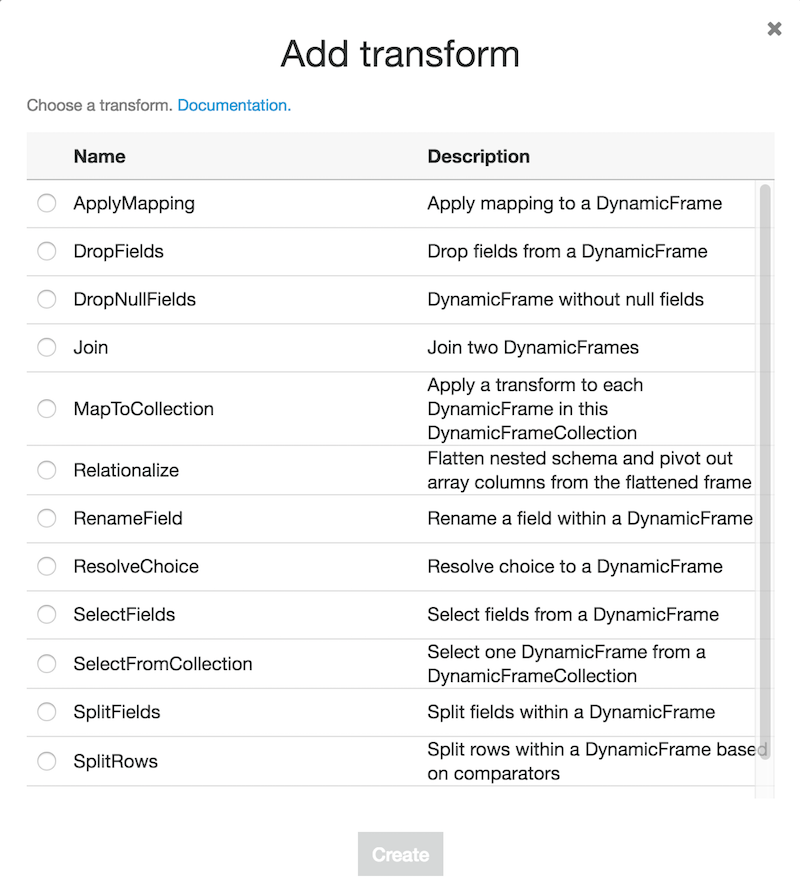
これら変換処理のどれか、もしくは、追加データソースを追加すると、Glueはインターフェースの左側に表示されている、データフローを確認できる便利で視覚的なダイアグラムを更新します。コンソールに独自コードを直接記述し、実行することもできます。このジョブに別のジョブやスケジュールの完了時に実行されるトリガー、もしくは、オンデマンドで実行されるトリガーを追加することができます。その方法により、より多くのフライトデータを追加する際、必要なフォーマットで S3 に戻されたデータをリロードすることができます。
ここで、なぜ、コードとして ETL ジョブが保存されることがとても有益であると私が考えているかをちょっと考えてみましょう。コードはポータブルで、テスト可能で、版管理可能、そして、人が読むことができます。私達の多くは毎日コードを書いています。私達はコードに精通しており、コードを簡単に操作できます。Glue は開発者としての私に、セットアップに費やしてきた数え切れないほどの時間を節約し、私は重要なコードを得ることができます。job コンソールのパワーと多機能性について記述することに丸一日かけてしまいましたが、Glue は対応して欲しいより多くの機能を持っています。例えば、私はスクリプトを編集するコンソールが好きな一方で、多くの人々が自分たちの開発環境やツール、IDE などを好んでいることも知っています。それでは、Glue でそれらを利用する方法を確認してみましょう。
Developer Endpoints and Notebooks
開発者エンドポイントは Glue のスクリプトを開発し、テストするために利用される環境です。Glueコンソールの “Dev endpoints” に移動し、右上にある “Add endpoint” をクリックすることで設定を開始します。次に、VPC、自分自身を参照する セキュリティグループを選択し、プロビジョンするのを待ちます。
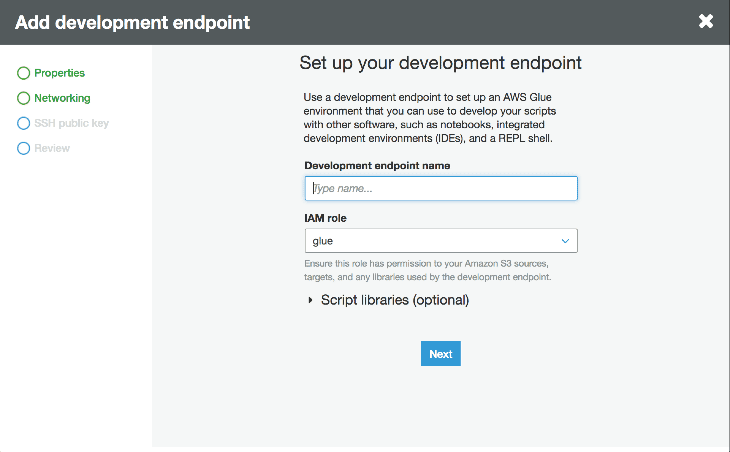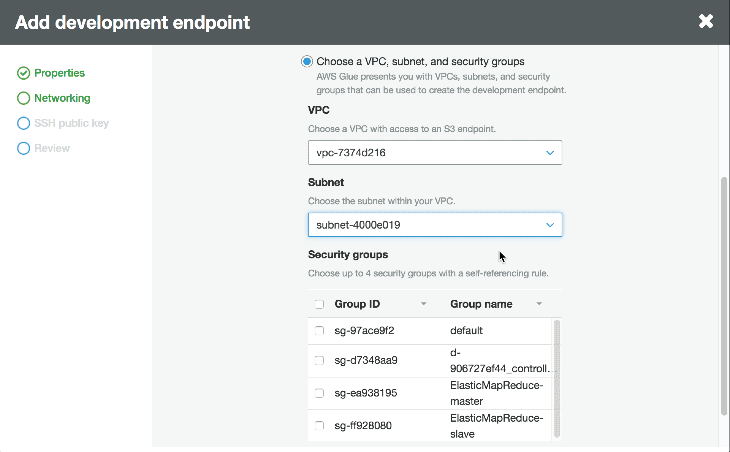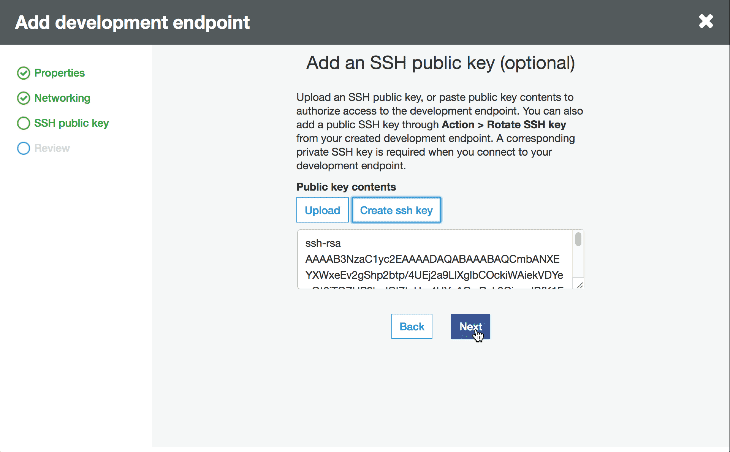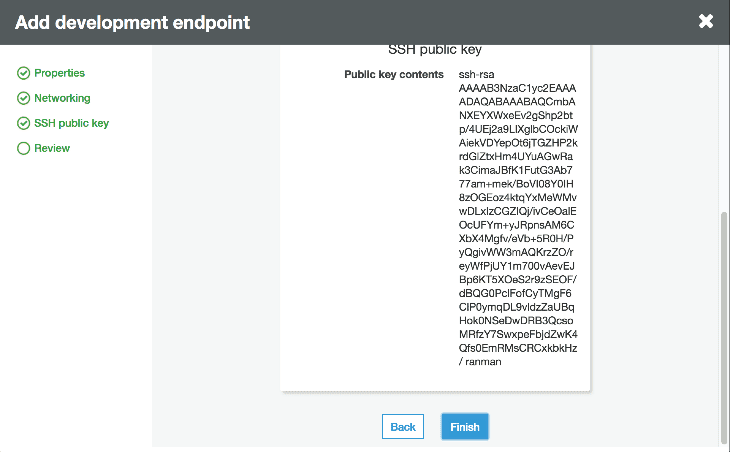
一度開発者エンドポイントがプロビジョンされると、何回かの操作と”create notebook server” をクリックすることにより、Apache Zeppelin notebook server を作成することができます。インスタンスに IAM ロールを渡し、データソースと連携するパーミッションを持っているかどうか確認します。そうすると、インタラクティブにスクリプトを開発するために、サーバーに SSH 接続できたり、notebook に接続できます。
Pricing and Documentation
ここから利用料金情報の詳細を確認することができます。Glue のクローラ、ETLジョブ、そして、開発エンドポイントは DPU(Data Processing Unit) 時間で課金されます。米国東部(バージニア北部) では、1 DPU時間のコストは 0.44 USD となります。1 DPU あたり、4vCPU と 16GB メモリを利用できます。
ここでは Glue の持っている機能の半分ほどしか説明できていないので、blog を読み終えた皆さんに、ドキュメント、サービスの FAQ を読むことを推奨します。Glue はコンソールで実施できること以上の機能を提供可能なリッチでパワフルな API も持っています。
本日、新しい2つのプロジェクトもリリースします。aws-glue-libs は Glue と接続し、連携するためのユーティリティ群を提供します。aws-glue-samples repo にはETL ジョブのサンプルコードがまとめられています。
私は Glue を使うことが、データを利用して何かを始める際に必要となる時間を削減するという事実をあなたが見出すことを期待します。AWS Glue に関する別の投稿がすぐにアップされるのをご期待下さい。なぜって、私はこの新しいサービスをいじくるのをやめられないのです!
– Randall
(翻訳: SA川村/SA八木,原文:https://thinkwithwp.com/blogs/aws/launch-aws-glue-now-generally-available/)