Amazon Web Services ブログ
EMR Notebooks を使用して Python ライブラリをクラスターに実行時インストールする
AWS は昨年、オープンソースの Jupyter ノートブックアプリケーションを基礎としたマネージド型ノートブック環境である EMR Notebooks を発表しました。
本記事では、EMR Notebooks でノートブックスコープのライブラリをクラスターに直接、実行時インストールする方法についてご説明します。その前に、クラスターをプロビジョンする際、ブートストラップアクションを信頼するか、またはカスタム AMI を使用して、EMR AMI に事前パッケージ化されていないライブラリを追加でインストールする必要があります。本記事では、EMR Notebooks 内においてローカルで使用可能なプレインストール済みの Python ライブラリを使用して結果を分析、プロットする方法もご説明します。この機能は、PyPI リポジトリへのアクセス権限はないが、データセットを分析、可視化する必要があるような状況下で役立ちます。
EMR Notebooks を使用したノートブックスコープのライブラリの利点
ノートブックスコープのライブラリには、次のような利点があります。
- 実行時インストール – 必要なときに、オンザフライで、お気に入りの Python ライブラリを PyPI リポジトリからインポートしてリモートクラスターにインストールすることができます。このライブラリはお使いの Spark ランタイム環境でただちに使用可能です。ノートブックセッションの再起動やクラスターの再作成は必要ありません。
- 依存関係の分離 – EMR Notebooks を使用してインストールしたライブラリは、ノートブックセッションから分離されているため、ブートストラップされたクラスターライブラリや、他のノートブックセッションからインストールされたライブラリには干渉しません。ノートブックスコープのライブラリは、ブートストラップされたライブラリよりも優先されるためです。ノートブックユーザーが複数であっても、お気に入りのバージョンのライブラリをインポートできます。使用の際も、同じクラスターで依存関係がクラッシュすることはありません。
- ポータブルなライブラリ環境 – ライブラリパッケージは、ユーザーのノートブックファイルからインストールされます。そのため、ノートブックコードを再実行して別のクラスターにノートブックを切り替える際にはライブラリ環境を再作成できます。EMR Notebooks からインストールしたライブラリは、ノートブックセッションの終了時にホスティング元の EMR クラスターから自動的に削除されます。
前提条件
EMR Notebooks で本機能を使用するには、EMR リリース 5.26.0 以降を実行するクラスターにアタッチされたノートブックが必要です。クラスターには、ライブラリのインポート元となるパブリックまたはプライベートの PyPI リポジトリに対するアクセス権限が必要です。詳細については、「ノートブックの作成」をご覧ください。
VPC 内のクラスターを外部リポジトリと接続できるように VPC ネットワークを設定するには、さまざまな方法があります。詳細については、Amazon VPC ユーザーガイドの「シナリオと例」をご覧ください。
ノートブックスコープのライブラリの使用例
ここでは、公開されている Amazon カスタマーレビューデータセット (対象: 書籍) の分析をとおして、EMR Notebooks のノートブックスコープのライブラリの特徴をご説明します。詳細については、Registry of Open Data for AWS の Amazon Customer Reviews Dataset をご覧ください。
ノートブックを開いて、カーネルを PySpark に設定しておきます。ノートブックセルから次のコマンドを実行します。
次のように出力されます。
次のコマンドを実行して、現在のノートブックセッションの設定を検査します。
次のように出力されます。

ノートブックセッションはデフォルトで (spark.pyspark.python により) Python 3 向けに設定されています。Python 2 を使用したい場合は、ノートブックセルから次のコマンドを実行して、ノートブックセッションを再設定します。
さらに、次のコードを実行して、現在のノートブックセッションで使用されている Python バージョンを検証します。
次のように出力されます。
![]()
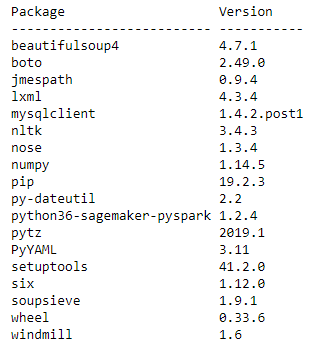
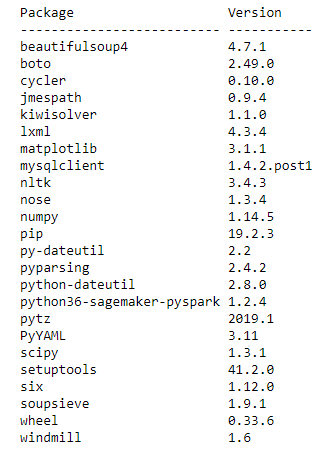
分析を始める前に、クラスターで使用可能なライブラリをチェックします。list_packages() PySpark API を使用すると、クラスター上の Python ライブラリが一覧表示されます。次のコードを実行します。
次のコードと同様の出力が得られ、クラスター上で使用可能な Python 3 互換パッケージのすべてが一覧表示されます。
次のコードを実行して、Amazon カスタマーレビューデータ (対象: 書籍) を Spark DataFrame にロードします。
これで、データを検討する準備ができました。次のコードを実行して、データセットで使用可能な列のスキーマおよび数を決定します。
次のコードが、その出力です。

このデータセットは、合計 15 列でした。さらに、次のコードを実行して、データセットの総行数をチェックします。
次のように出力されます。
![]()
次のコードを実行して、総書籍数をチェックします。
次のように出力されます。
![]()
さらに、各年の書籍レビュー数を分析したり、カスタマーによる星評価の分布を見たりもできます。これには、Pandas ライブラリのバージョン 0.25.1 および最新の Matplotlib ライブラリをパブリック PyPI リポジトリからインポートします。インポートしたら、install_pypi_package API を使用して、ノートブックにアタッチされたクラスターにインストールします。次のコードをご覧ください。
次のように出力されます。
install_pypi_package PySpark API を使用すると、ライブラリおよび関連するすべての依存関係がインストールされます。デフォルトで、現在お使いの Python バージョンと互換性のある最新バージョンのライブラリがインストールされます。また、先ほどの Pandas の例で使用したバージョンのライブラリを指定すると、ある特定のバージョンのライブラリをインストールできます。
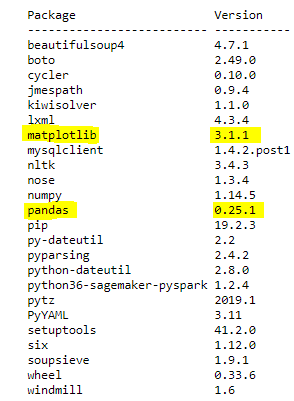
次のコードを実行して、インポートしたパッケージが正しくインストールされたかを検証します。
次のように出力されます。
複数年にわたるレビュー数の推移も分析できます。‘toPandas()’ を使用して、Spark データフレームを Pandas データフレームに変換すると、Matplotlib で可視化することができます。次のコードをご覧ください。
前述のコマンドにより、アタッチされた EMR クラスター上にプロットがレンダリングされます。そのプロットをノートブック内で可視化するには、%matplot マジックを使用します。次のコードをご覧ください。
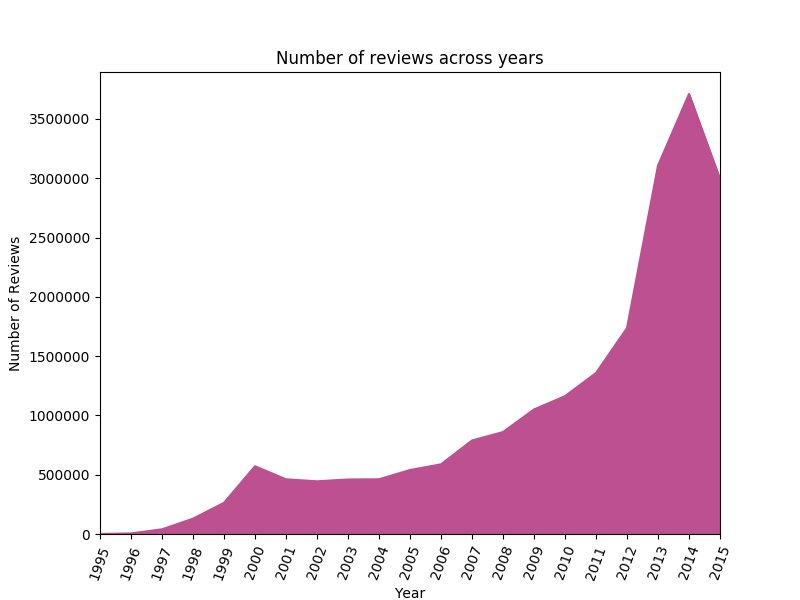
次のグラフでは、カスタマーレビュー数が 1995 年から 2015 年にかけて指数関数的に増加していることが示されています。おもしろいことに、2001 年、2002 年、2015 年はレビュー数が前年度比で落ちており、全体の傾向からは異常値となっています。
星評価の分布の分析や円グラフによる可視化も可能です。次のコードをご覧ください。
%matplot マジックを使用して円グラフで表示し、次のコードを実行してノートブックから可視化します。
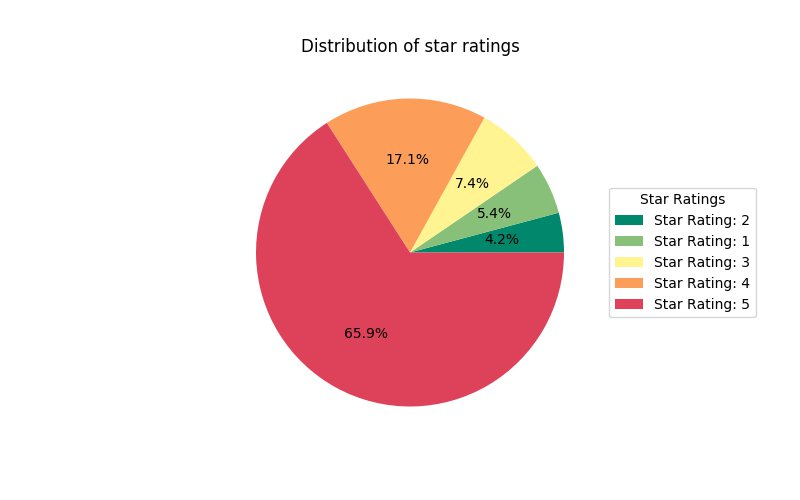
次の円グラフでは、ユーザーの 80% が星 4 つかそれ以上の評価をしていることが示されています。購入した本を星 2 つかそれ以下に評価しているのは、ユーザーの約 10% でした。たいていのお客様は Amazon で購入した本に満足しているということです。
最後に、install_package API でインストールした Pandas ライブラリを、‘uninstall_package’ Pyspark API を使用してアンインストールします。これは、EMR Notebooks でインストールした異なるバージョンのライブラリを使用したいような状況下で役立ちます。次のコードをご覧ください。
次のように出力されます。

次に、以下のコードを実行します。
次のように出力されます。
ノートブックを終了したら、install_pypi_package API を使用してクラスターにインストールした Pandas および Matplot ライブラリは不要となり、クラスターから削除されます。
EMR Notebooks におけるローカル Python ライブラリの使用例
ここまでご説明してきたノートブックスコープのライブラリには、ユーザーの EMR クラスターに PyPI リポジトリに対するアクセス権限を付与することが必須でした。EMR クラスターをリポジトリに接続できない場合は、EMR Notebooks に事前パッケージ化された Python ライブラリを使用して、ノートブック内においてローカルで結果を分析、可視化します。こういったローカルライブラリはノートブックスコープのライブラリとは異なり、Python カーネルに対してのみ使用可能で、クラスター上の Spark 環境に対しては使用できません。こうしたローカルライブラリを使用するには、クラスターの Spark ドライバーからノートブックに結果をエクスポートし、ノートブックマジックを使用して結果をローカルでプロットします。ユーザーがプロットの分析とレンダリングに使っているのはクラスターではなくノートブックであるため、ノートブックにエクスポートするデータセットは小さいサイズである必要があります (100 MB 未満を推奨)。
ローカルライブラリの一覧を見るには、次のコマンドをノートブックセルから実行します。
これで、ノートブックで使用できるライブラリ一覧が入手できます。この一覧は長大なため、ここでは割愛します。
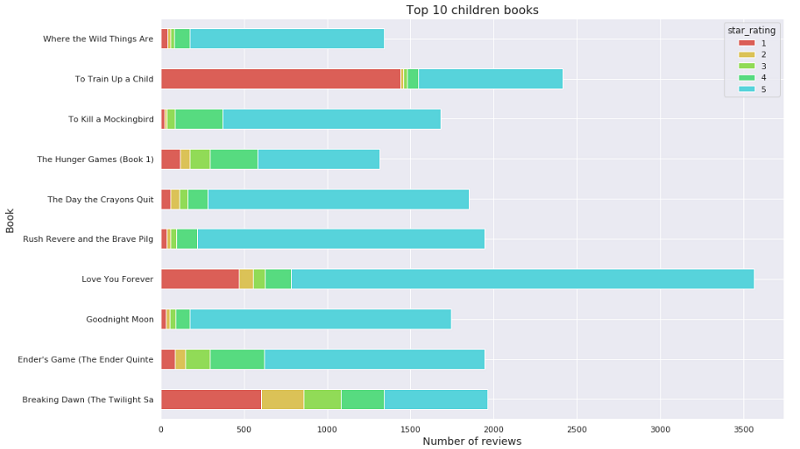
この分析では、書籍レビューデータセットから児童書上位 10 冊を見つけて、その星評価の分布を分析します。
次のコードを実行すると、カスタマーレビューから児童書を特定できます。
次のコードを実行して、カスタマーレビュー数から児童書上位 10 冊をプロットします。
次のように出力されます。

次のコードを実行して、これらの本に対する星評価の分布を分析します。
次のように出力されます。

この結果をノートブック内においてローカルでプロットするには、データを Spark ドライバーからエクスポートし、ローカルノートブック内に Pandas DataFrame としてキャッシュします。このためには、まず次のコードを実行して、一時テーブルを登録します。
次のコードを実行して、ローカル SQL マジックで一時テーブルからデータを抽出します。
これらのマジックコマンドの詳細については、GitHub リポジトリをご覧ください。
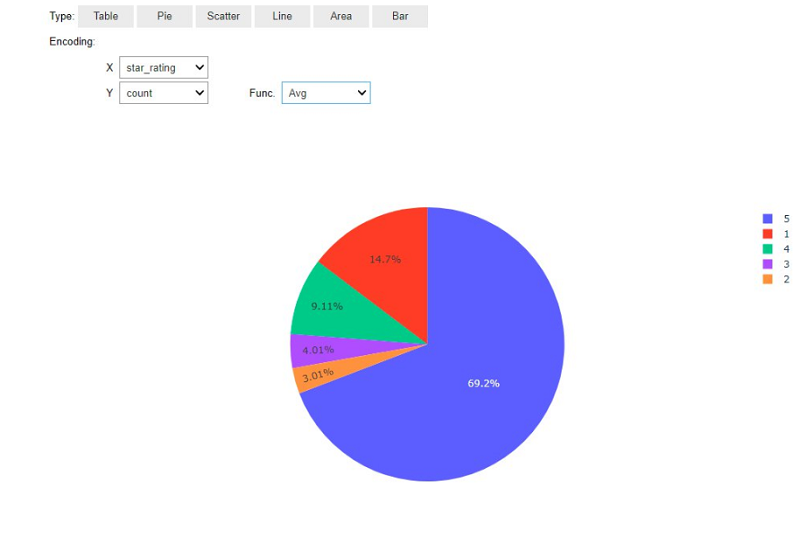
コードを実行すると、結果をインタラクティブにプロットできるユーザーインターフェイスが利用可能になります。次の円グラフでは、星評価の分布が示されています。
EMR Notebooks で利用できるローカル Matplot および seaborn ライブラリを使えば、もっと複雑なグラフでもプロットできます。次のコードをご覧ください。
次のように出力されます。
まとめ
本記事では、EMR Notebooks のノートブックスコープのライブラリ機能を解説しました。お気に入りの Python ライブラリを実行中の EMR クラスターにインポートおよびインストールして、データ分析の強化や、リッチなグラフィカルプロットによる結果の可視化に使用する方法をおわかりいただけたことでしょう。さらに、EMR Notebooks で利用可能な事前パッケージ化されたローカル Python ライブラリを使って、分析および分析結果のプロットを行う方法についてもご覧いただきました。
著者について
 Parag Chaudhari は、AWS のソフトウェア開発エンジニアです。
Parag Chaudhari は、AWS のソフトウェア開発エンジニアです。