Amazon Web Services ブログ
In the Research Spotlight: Zornitsa Kozareva
これは、ドイツのポツダム市にある Hasso-Plattner-Institut の Haojin Yang、Martin Fritzsche、Christian Bartz、Christoph Meinel 各氏によるゲスト投稿です。低パワーデバイスでのディープラーニングの実際の実装に関する研究を見るのはわくわくします。この作業は、強力で知的な機能を毎日の生活に拡大するうえで重要な役割を果たします。
近年、ディープラーニングテクノロジは非常に優れたパフォーマンスと多くのブレークスルーを学会と業界の両方で達成しています。しかし、最新鋭のディープモデルは計算コストが高く、大きなストレージ容量を消費します。ディープラーニングは、モバイルプラットフォーム、ウェアラブルデバイス、自律ロボット、IoT デバイスなどの領域で多数のアプリケーションによって強く要求されています。このような低パワーデバイスにおいてディープモデルをどのように効率的に適用するかが課題となります。
最近提案されたバイナリニューラルネットワーク (BNN) は、標準の算術演算ではなくビット単位演算を提供することで、メモリサイズとアクセスを大幅に減らします。最新鋭のディープラーニングモデルは、実行時に効率を大幅に向上させ、エネルギー消費を低くすることで、低パワーデバイスで実装することができます。この手法を開発者フレンドリーな OpenCL と組み合わせることで (VHDL/Verilog と比較した場合)、FPGA がディープラーニング用の実行可能なオプションとなります。
この投稿では、BMXNet についてご紹介します。これは Apache MXNet に基づくオープンソースの BNN (バイナリニューラルネットワーク) です。開発された BNN レイヤーは他の標準ライブラリコンポーネントにシームレスに適用でき、GPU および CPU モードの両方で機能します。BMXNet は Hasso Plattner Institute のマルチメディア研究グループによって管理、開発され、Apache ライセンスに基づいてリリースされています。このライブラリ、いくつかのサンプルプロジェクト、およびトレーニング済みバイナリモデルのコレクションは、https://github.com/hpi-xnor からダウンロードして入手可能です。
フレームワーク
BMXNet は、入力データと重みのバイナリ化をサポートするアクティベーション、畳み込み、および完全に接続されたレイヤーを提供します。これらのレイヤーは、対応する MXNet バリアントに対するドロップインリプレースメントとして設計されていて、QActivation、QConvolution、および QFullyConnected と呼ばれます。さらに、レイヤーによって計算されるビット幅を制御する追加のパラメータ act_bit を提供します。MXNet と比較した、提案のバイナリレイヤーの Python での使用例をリスト 1 およびリスト 2 に示します。当社は、ネットワークの最初のレイヤーおよび最後のレイヤーにバイナリレイヤーは使用しません。使用すると正確性が大幅に低下する可能性があるためです。BMXNet での BNN の標準ブロック構造は、次のリストに示すように、QActivation-QConvolution または QFullyConnected-BatchNorm-Pooling として実行されます。

従来のディープラーニングモデルでは、完全に接続された畳み込みレイヤーはマトリックスのドット製品に大きく依存していて、それにより膨大な浮動小数点演算が必要になります。一方、バイナリ化された重みと入力データの操作では、CPU 命令 xnor および popcount を利用することで、高パフォーマンスのマトリックス乗算が可能になります。最新のほとんどの CPU は、これらのタイプの演算に最適化されています。2 つのバイナリマトリックス A◦B のドット積を計算するために、乗算演算は不要になります。A の各行と B の各列との要素単位の乗算と要約は、最初にそれらを xnor 演算で組み合わせ、次に結果でビット数を 1 (母集団の数) に設定してカウントすることで概算されます。この方法により、こうしたビット単位演算のハードウェアサポートを活用できます。この概算カウント命令は SSE4.2 をサポートする x86 および x64 CPU で利用でき、ARM アーキテクチャでは NEON 命令セットに含まれています。これらの命令を利用した、最適化されていない GEMM (General Matrix Multiplication) 実装をリスト 3 に示します。

コンパイラの組み込み popcount は gcc および clang コンパイラの両方でサポートされ、サポートされるハードウェアではマシン命令に翻訳されます。BINARY_WORD は 32 (x86 および ARMv7) または 64 (x64) マトリックス要素を格納するパッケージ化されたデータタイプで、それぞれは単一ビットで表されます。当社は xnor GEMM カーネルの複数の最適化バージョンを実装しました。それによりデータをブロックおよびパッケージ化し、展開と並行化の手法を使用して、プロセッサのキャッシュ階層の活用を試みました。
トレーニングと推論
トレーニングステージでは、重みと入力を離散値 -1 および +1 に制限するときに、MXNet の組み込みレイヤーの出力に完全に一致するようにバイナリ化されたレイヤーを慎重に設計しました (BLAS ドット積演算で計算)。次の等式に示すように、ドット積の計算後、提案された xnor スタイルのドット積の値範囲に結果をマッピングし直しました。
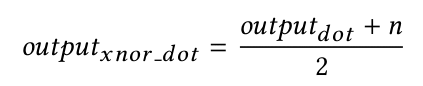
ここで、n は値範囲パラメータです。この設定により、CuDNN を適用して GPU サポートにより膨大な並行トレーニングが可能になります。次に、トレーニング済みモデルを能力が低いモデルで推論を実行するために使用できます (GPU サポートなし、少ないストレージスペースを使用)。ここで予測の前方パスが、標準の算術演算ではなく xnor および popcount 演算を使用してドット積を計算します。
BMXNet でネットワークをトレーニングした後で、重みは 32 ビットの浮動小数点変数に格納されます。これは 1 ビットのビット幅でトレーニングされたネットワークにも当てはまります。当社は、バイナリトレーニングされたモデルファイルを読み取り、QConvolution および QFullyConnected レイヤーの重みをパッケージ化する model_converter を提供しています。変換後は、重みあたり 1 ビットのストレージと実行時メモリのみが使用されます。たとえば、完全な精度の重みをもつ ResNet-18 ネットワーク (CIFAR-10 上) のサイズは 44.7 MB です。当社のモデルコンバーターによる変換では 29 倍の圧縮が達成され、ファイルサイズは 1.5 MB になります。
分類の精度
MNIST (手書きの数字認識)、CIFAR-10 (イメージ分類) データセットで、当社 BNN による実験を行いました。実験は Intel(R) Core(TM) i7-6900K CPU、64 GB RAM、および 4 TITAN X (Pascal) GPU を備えたワークステーションで実行されました。

この表は、バイナリの分類テストの正確性と、MNIST および CIFAR-10 でトレーニングされた完全精度モデルを表しています。表は、バイナリモデルのサイズが大幅に減ったことを示しています。それと同時に、正確性は競争力を維持しています。また、バイナリ化されたモデル、部分的にバイナリ化されたモデル、および完全な精度モデルの実験を ImageNet データセットで行いました。ここで、部分的にバイナリ化されたモデルは有望な結果を示しますが、完全にバイナリ化されたモデルにはまだ改善領域が多くあります (詳細については当社のペーパーをご覧ください)。
効率の分析
Ubuntu16.04/64 ビットプラットフォームと Intel 2.50GHz × 4 CPU、popcnt in-struction (SSE4.2) および 8 G の RAM で、さまざまな GEMM 手法の効率を測定する実験を行いました。この測定は畳み込みレイヤー内で実行されました。ここで、パラメータを次のように修正しました。フィルタ番号=64、カーネルサイズ=5×5、バッチサイズ=200、マトリックスサイズ M、N、K はそれぞれ 64、12800、kernel_w × kernel_h ×inputChannelSize。下の図に結果を示します。
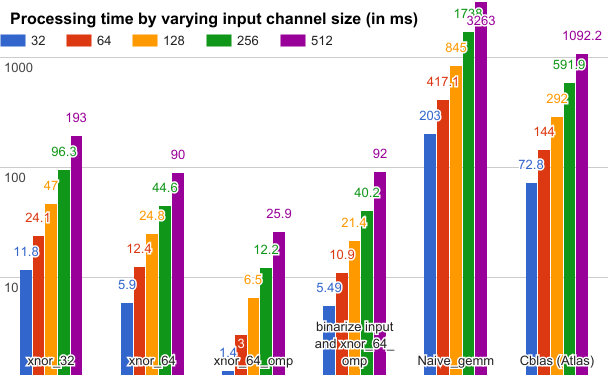
色の付いた列は、さまざまな入力チャネルサイズでのミリ秒単位の処理時間を示します。xnor_32 および xnor_64 は 32 ビットと 64 ビットの xnor gemm 演算子を示します。xnor_64_omp は、OpenMP 並行プログラミングライブラリを使用して高速化された 64 ビットの xnor gemm を示します。入力のバイナリ化と xnor_64_omp により、入力データのバイナリ化の処理時間がさらに累積されました。それでも、入力データのバイナリ化時間を累積することで、Cblas 手法に比べて約 13 倍の高速化を達成しました。
まとめ
当社は MXNet に基づいて、オープンソースのバイナリニューラルネットワークの実装である BMXNet を C/C++ に導入しました。現在の実験で、最大 29 倍のモデルサイズの低減と、はるかに効率的なバイナリ gemm 計算を達成しました。バイナリ化された ResNet-18 モデルを使用して、Android および iOS でイメージ分類用のサンプルアプリケーションを開発しました。ソースコード、ドキュメント、トレーニング済みモデル、およびサンプルプロジェクトは GitHub で公開されています。次のステップとして、異なるディープアーキテクチャで正確性と効率の両方の観点からより体系的な調査を実行し、Q_Conv レイヤーで unpack_patch2col メソッドを再実装して、CPU モードの推論速度をさらに向上させたいと考えています。