Amazon Web Services ブログ
Zendesk がレガシーシステムを Amazon Aurora と Amazon Redshift に移動してパフォーマンスを 3 倍にした方法
この記事は、Zendesk のエンジニアリングリーダーである James Byrne 氏によるゲスト投稿です。Zendesk は、Zendesk Explore アナリティクス製品のデータパイプラインにおける開発と運用、および AWS ソリューションアーキテクトの Giedrius Praspaliauskas に焦点を当てています。
Zendesk は、より良い顧客関係を促進するために設計されたサポート、販売、顧客エンゲージメントソフトウェアを構築する CRM 企業です。規模、業界、または野心に関係なく、大企業からスタートアップ企業にいたるまで、強力で革新的な顧客体験がすべての企業に届くと、私たちは信じています。Zendesk は、さまざまな業界の 150,000 社以上の顧客に 30 以上の言語でサービスを提供しています。Zendesk はサンフランシスコに本社を置き、世界中に 17 ヵ所のオフィスを展開しています。
Zendesk Explore は、企業が顧客体験全体を測定して改善できるように分析を提供します。Zendesk Explore を使用すれば、企業は重要な顧客分析にすぐにアクセスでき、顧客とその関連ビジネスについてより深く理解できます。
この記事では、レガシーシステムを Amazon Aurora と Amazon Redshift に移行する方法について説明します。新しいデータストアと 3 倍のパフォーマンスを構築できるプロセスとアーキテクチャについて詳しく説明します。
移行を決定する
2015 年、Zendesk はビジネスインテリジェンスのスタートアップ企業である BIME Analytics を買収しました。BIME 製品は、現在のレポート製品である Zendesk Explore の構成要素として機能していました。Zendesk Explore は、Zendesk サポート、トーク、チャット、ガイドなど、さまざまな Zendesk 製品の複数のデータタイプを処理して分析します。各製品からデータを抽出し、非正規化、変換して、データストアに読み込みます。可視化レイヤーはこのデータストア上にあり、分析のためにデータにアクセスするためのユーザーインターフェイスを Zendesk の顧客に提供します。ユーザーは、ポイントとクリックをするだけで、独自のデータ視覚化とダッシュボードを作成できます。
Zendesk チームが Explore の基盤を構築し始めたとき、AWS にデータの抽出、変換、読み込み (ETL) および分析を実装するために利用可能なツールを検討することから始めました。保有しているデータ量を処理するために Amazon Aurora PostgreSQL に、より大規模なデータセットと高速分析クエリのために Amazon Redshift に専念しました。データの抽出に必要な製品や API に接続し、データを非正規化してパフォーマンスを向上させることができます。
1 年以内に、Aurora PostgreSQL を使用して、特定の規模までのお客様向けに完全な ETL パイプラインを構築できました。広範囲の負荷、ストレス、およびパフォーマンスのテストを行った結果、1 つの Aurora クラスター (CPU の 80% で実行) あたり約 6,000 万の顧客チケットがスイートスポットに達しました。最大顧客のデータセットのごく一部が Aurora PostgreSQL に適切でないことはわかっていました。これは、複雑なクエリと並行してデータ変換を実行し、ETL と複雑な分析のために最適化されたツールが最大スケールでのパターンにより適しているためです。
私たちは、顧客のためのバックエンドデータストレージおよびクエリソリューションとして、Amazon Redshift を使用しています。このアプローチにより、さまざまなサイズの複数の顧客が基盤となる Amazon Redshift または Aurora クラスターを共有するマルチテナント実装の場合でも、最も費用対効果の高い方法で負荷を処理できました。
アプローチ
次の図は、Zendesk Explore チームがデータの取り込み、変換、読み込み、分析をどのように実装したかについて高レベルで示しています。次のサービスは、さまざまな機能を実行します。
- Amazon EMR、AWS Step Functions、および AWS Lambda は、Zendesk Incremental API から静的データを取り込み、変換します。
- Apache Flink、Amazon Kinesis、および Amazon ECS は、データベースのバイナリログからほぼリアルタイムのデータを取り込みます
- Aurora と Amazon Redshift はデータストレージとして機能します
- Amazon ECS は、ユーザーが Elastic Load Balancing を介してアクセスするカスタムクエリエンジンをホストします
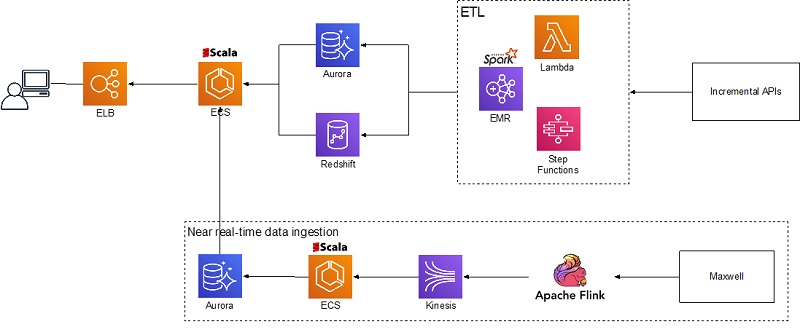
データの取り込み
Zendesk Explore は、静的データのパブリック API (1 時間以上経過) とほぼリアルタイムのログストリーム (10 秒〜1 時間) の 2 つの主要なソースからデータを取り込みます。増分エクスポート API エンドポイントをクエリするスケジュール済みのプロセスがあり、最後の実行以降に変更されたデータをプルします。Amazon EMR で実行されるデータ探索 ETL プロセスはデータを消費します。
ログストリームは、Maxwell を使用して Amazon Kinesis にストリーミングされ、Apache Flink を使用して処理または集約されるデータベース binlog として発生します。データはビンに集約され、Explore ETL プロセスが 10 秒ごとに取得して、Aurora クラスターに保存されます。
ETL
Zendesk Explore は、顧客ごとに何千もの顧客に対して ETL を実行します (顧客ごとに、一部の ETL ロジックが実行されます)。数億行をたった数列で構成された数千のレコードに変換できます。たとえば、顧客が 1,000 万レコード (チケットの更新) を持っている場合、変換中にそれらを他のテーブルと結合し、データを集計して、この集計を 1,000 レコードだけで表示します。
当社のレガシー ETL プロセスは、PostgreSQL クラスターでデータ変換を実行する Scala と SQL クエリを使用していました。リファクタリングの一環として、データの読み込みと変換のレガシー実装を Amazon EMR の Spark に移動し、ETL により適したツールにその処理をオフロードしました。このようにして、Aurora と Amazon Redshift を完全にデータストレージとクエリ専用に使うことができます。これにより、データ変換を並行して実行することによりパフォーマンスを低下させることなく、クラスター上で複数のテナントをホストできました。このアプローチにより、初期制限である 100〜200 と比較して、単一の Aurora クラスターに最大 600 のテナントを共存させることができました。
Step Functions と Lambda を使用して、データ変換プロセスを大きなグラフに変換します。これにより、Amazon EMR で実行される Apache Spark アプリケーションとして実行されるデータ変換ステップがトリガーされます。このプロセスは、増分 API を使用して取得したデータを処理するために、すべての顧客に対して 1 時間ごとに繰り返されます。
データストレージ
データストレージの探索には、Aurora PostgreSQL と Amazon Redshift を使用します。使用するストレージソリューションは、お客様のデータセットのサイズ、使用パターン、および結果のパフォーマンスに基づいて決定されます。Aurora PostgreSQL は、中小規模のお客様 (最大 300〜600 万チケット) をホストします。Amazon Redshift は大規模な顧客をホストしています。クエリパフォーマンスのトレースを使用し、内部管理ツールを使用してコアクエリのパフォーマンス (顧客の待機時間) を調べます。顧客のデータセットが拡大するにつれて、1 つのデータストレージから別のデータストレージに移動する場合があります。
Aurora PostgreSQL と Amazon Redshift はどちらもマルチテナントアプローチを使用しており、単一のクラスターに最大数百の顧客が共存しています。このアプローチにより、クエリのパフォーマンスに影響を与えることなく、費用対効果の高い顧客データのストレージが可能になります。また、単一の大きな Amazon Redshift クラスターに複数の顧客を配置すると、単一のウェブページに対して複数の並列クエリが実行されているダッシュボードに必要な並列クエリのパフォーマンスが向上します。
分析
Zendesk Explore は、静的データとほぼリアルタイムのデータの両方のダッシュボードを提供します。ビルド済みのダッシュボード、視覚化、クエリを使用するか、クエリビルダーを使用して、複数のテーブル間でデータを使用して選択したメトリックで視覚化を構築できます。これらのクエリを最適化するために、Zendesk Explore は、クエリを書き直したり、使用された述語に基づいて異なるテーブルにクエリをルーティングしたり、アプリケーションキャッシュを備えたりする中間カスタムアプリケーションレイヤーを使用します。このクエリエンジンは Scala で記述され、ECS クラスターで実行されます。
まとめ
この記事では、Zendesk のマルチテナント分析ソリューションの実装について説明しました。複数のデータベースと分析ソリューションを使用して、さまざまなサイズと温度のデータセットを費用対効果の良い方法で柔軟に提供する方法を示しました。re:Invent 2019 で発表された最新の AWS 開発である Amazon Redshift 横串検索機能、Amazon Redshift 向け Advanced Query Accelerator (AQUA)、およびマネージドストレージを備えた Amazon Redshift RA3 インスタンスを使用することで、このアプローチをさらに進化させることができます。
ご質問またはご提案は、コメント欄にお寄せください。