Amazon Web Services ブログ
Amazon Redshift および AWS のサービスを使用してデータウェアハウスを構築する方法
12 これは、Cerberus Technologies のビッグデータと BI の責任者である Stephen Borg による顧客の投稿です。
これは、Cerberus Technologies のビッグデータと BI の責任者である Stephen Borg による顧客の投稿です。
Cerberus Technologies、言い換えると Cerberus は先見的な iGaming の専門家により 2017 年に創立された会社です。私たちの使命は簡単です – データ指向で顧客第一のアプローチを通じた最高の技術ソリューションにより、作業とプロセスの従来の形態とは異なる革新的なソリューションを提供することです。この指名は信頼性、柔軟性、およびセキュリティの確固たる基礎に基づいており、iGaming と業界がテクノロジーと対話する方法を基本的に変更することを目的としています。
過去数年間にわたり、私は何もないところから、多くのデータウェアハウスを開発し、作ってきました。最近、私は iGaming 業界のデータウェアハウスを単独で構築しました。そのために、私はAmazon Redshiftのパワーと柔軟性、およびより広い AWS データ管理エコシステムを利用しました。この投稿では、一般的には必要な大きな専門家チームなしに、堅牢でスケール自在なデータウェアハウスを構築できた方法を説明します。
最近の 2 つのプロジェクトでは、オンプレミスのインフラストラクチャを使用するデータウェアハウスをスケールするときに課題に遭遇しました。データが 1 日当たり何十ギガバイトにもふくらみ、クエリのパフォーマンスが損なわれていました。スケーリングではハードウェアとソフトウェアのライセンスに大きな資本投資が必要で、それを稼働させて、うまく機能させるには、メンテナンスと技術スタッフに大きな運用コストも必要でした。残念ながら、私はデータの成長に合わせてインフラストラクチャを拡大するために必要なリソースを取得できませんでしたので、これらのプロジェクトは破棄されました。クラウドデータハウジングのおかげで、インフラストラクチャリソース、資本費用、および運用費用のボトルネックは大幅に減るか、完全になくなりました。どれだけの大量のデータがあったとしても、過去のように意思決定者へのタイムリーな提示を遅らせる障害で言い訳する必要がなくなりました。
Amazon Redshift および AWS を使用して、私の小さなチームでクラウドデータウェアハウスをビジネスに非常に早く届けました。ハードウェアまたはソフトウェアを注文する必要はなく、パッチとバージョンのアップデートをインストール、設定、調整、または追いつく必要はありませんでした。代わりに、データ処理パイプラインを簡単にセットアップして、データを素早く取り込んで、分析しました。これで、私のデータウェアハウスチームは極度に集中して、より多くの時間を新しいデータの取り込みと洞察の提供にむけることができます。この投稿では、私が使用した AWS のサービスとアーキテクチャを示します。
データフィードの取り扱い
私は、ビジネスを稼働させるために必要だったすべてのものを提供するいくつかの種類のデータソースを持っています。そのデータには、iGaming プラットフォーム、ソーシャルメディアの投稿、クリックストリームデータマーケティングとキャンペーンのパフォーマンス、顧客サポートのエンゲージメントからのアクティビティが含まれます。
多様なデータフィードを扱うために、私はAmazon EC2 Container Service (Amazon ECS) で実行される Docker を使用するアブストラクト統合アプリケーションを開発し、データを Amazon Kinesis データストリームにフィードします。これらのデータストリームは、リアルタイムの分析で使用できます。私のシステムでは、Kinesis の各レコードは AWS Lambda 機能により事前処理され、情報を浄化し、集積します。私のシステムはそれを、Amazon Kinesis Data Firehose により Amazon S3 で必要な場所に保存するように導きます。同じタスクを行うために、オンプレミスのアーキテクチャを使用することを考えてみましょう。データエンジニアのチームは、Kafka クラスタを維持して監視し、データをストリーミングするためのアプリケーションを開発し、Hadoop クラスタとデータストレージのためにその下にあるインフラストラクチャを維持しなければなりません。私のストリーム処理アーキテクチャでは、管理するサーバーはなく、交換するディスクドライブもなく、書き込むサービスの監視もありません。
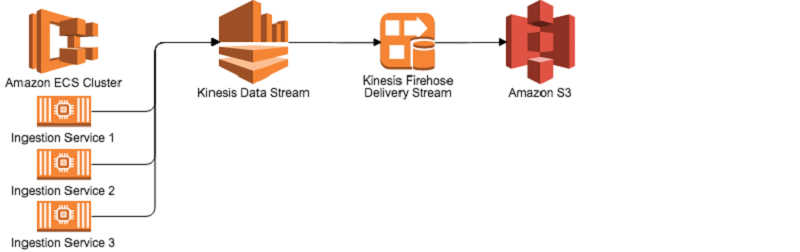
Kinesis ストリームのセットアップは数回のクリックで行うことができ、Kinesis Firehose についても同様です。Firehose は Kinesis データストリームからのデータを自動的に消費し、圧縮データを N 秒ごとに Amazon S3 に書き込むように設定できます。Kinesis データストリームを処理するとき、Lambda 関数を設定して受信した各メッセージに実行することが非常に簡単です。以下に示す通り、AWS Lambda マネジメントコンソールからトリガーを設定することができます。
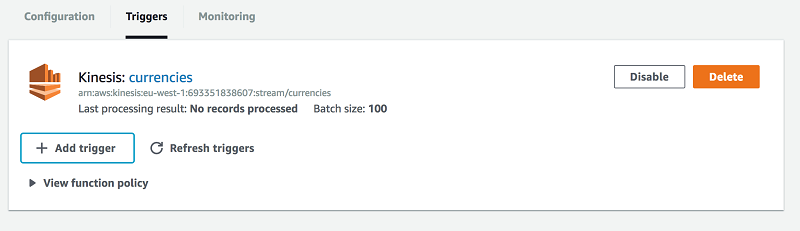
私はまた、Amazon CloudWatch および AWS X-Ray を使用して関数の実行時間も監視できます。
パートナーから受け取るデータの形式に関わらず、それを Kinesis に独自のフォーマッターを使用して JSON データとして送信できます。Firehose がこれを Amazon S3 に書き込んだ後で、私はすべてを受け取ったものとほぼ同じ構造でもちますが、読み取りのために、圧縮され、暗号化され、最適化されます。
このデータは自動的に AWS Glue でクロールされ、AWS Glue データカタログに配置されます。このことは、Amazon Athena を使用するか、Amazon Redshift Spectrum を通じて、S3 で直接データを直ちにクエリできることを意味します。以前、私はカタログ管理のために Apache Hive の Amazon EMR と Amazon RDS ベースのメタストアを使用しました。今は Hive Metastore カタログの複雑な維持を避けることができます。Glue は高い可用性と運用側に注意し、エンドユーザーが常に生産性を上げることができるようにします。
分析のために Amazon Athena と Amazon Redshift を操作する
私は Amazon Athena が特別な分析のために、とても便利ですぐに利用できることがわかりました。当社のエンジニア (私) は、Athena を使用して受け取った新しいデータセットを理解し、長期的なクエリの効率性に必要な変換を理解します。
当社のデータ分析者とデータ科学者に対しては、Amazon Redshift を選択しました。Amazon Redshift は、何回も繰り返し正しいツールであることを実証しました。それはテーブルのサイズやビジネスに必要な分析の種類にかかわらず、1 日当たり 2000 万以上のトランザクションを簡単に処理します。遅延は低く、クエリのパフォーマンスは期待を超えるものでした。Redshift Spectrum を長期間のデータ保持に使用することで、Amazon Redshift の分析能力をローカルデータを超えてS3に保存されたものに拡張できるようにし、データをロードすることは求めません。Redshift Spectrum は希望の場所に、希望の形式でデータを保存する自由を与え、必要な時に処理するために利用できるようにします。
データを直接、Amazon Redshift にロードするためには、AWS Data Pipeline を使用して、データのワークフローを調整します。私はAmazon EMRクラスタを日中に作成し、1 日を通して必要に応じて多かれ少なかれ実行するように簡単に調整できます。EMR クラスタは Amazon RDS、Apache Spark 2.0、および S3 ストレージと共に使用されます。データパイプラインアプリケーションは、AWS Elastic Beanstalk でホストされている Spring RESTful サービスから ETL 設定をロードします。アプリケーションは S3 からのデータをメモリーにロードし、データを集計してクリーニングし、データの最終バージョンを Amazon Redshift に書き込みます。このデータはその後、分析のために使用できる準備ができます。Spark on EMR はまた、さまざまなビジネス ユーザーのための使用例を推奨し、パーソナライズすることでも支援し、これによりユーザーが必要としているものを容易にセットアップし、提供できることがわかりました。最後に、ビジネスユーザーはセルフサービスの BI に対して Amazon QuickSight を使用して、要件に応じてデータをスライス、ダイス、視覚化します。
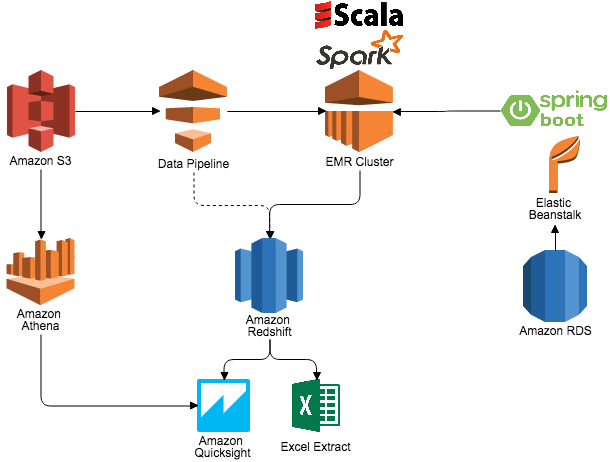
このアーキテクチャの各 AWS のサービスは、配布のために重要な貴重な時間を節約し、ビジネスの異なる部門を軌道に乗せる役割を果たします。私はサービスのセットアップと使用が容易であり、すべてのことが当社の生産環境として使用するために非常に信頼性があることが証明されました。アーキテクチャが整っていれば、スケールアウトはサービスによって完全に処理されるか、単純な API 呼び出しの問題であり、決定的には、1 行のコードを変更することは求められません。Kinesis の断片はストリームを編集することで増やすことができます。Lambda 関数の容量を増大させることは、処理用に割り当てられたメガバイトを編集し、並行処理は自動的に処理されることで達成されます。EMR クラスタの容量は、データパイプラインのマスターノードとスレーブノードのタイプを変更するか、Auto Scaling を使用して簡単に増やすことができます。最後に、RDS と Amazon Redshift は当社のチームによりメジャーなタスクを実行せずに容易にアップグレードできます。
最後に、Kinesis、Lambda、データパイプライン、Amazon Redshift などの AWS のサービスを使用して、私のチームを集中させ、生産性を高めることができます。私は資本インフラストラクチャの費用と遅延、そして深夜や週末のサポートの必要性を排除しました。このことにより、運用コストを抑えながら、ビジネスに最大の価値を与えることができます。私のチームは、敏捷で反応性の高いデータウェアハウスソリューションを記録的な速度で提供し、変化するビジネス要件を素早く処理し、新しいデータや新しいユーザー要求に迅速に対応できます。
その他の参考資料
この記事を有用に感じた安倍は、Deploy a Data Warehouse Quickly with Amazon Redshift, Amazon RDS for PostgreSQL and Tableau Server と Top 8 Best Practices for High-Performance ETL Processing Using Amazon Redshift をご覧ください。

著者について

Stephen Borgは、Cerberus Technologies のビッグデータと BI の責任者です。 同氏はプラットフォーム ソフトウェアエンジニアリングのバックグラウンドを持ち、最初に一般的な RDBMS、SQL、ETL、および BI ツールを使用するデータウェアハウジングに関与しました。すぐに、他の人がビジネスを最適化し、パーソナライゼーションを製品に加えるのを助けるための洞察力を提供することに熱中しました。同氏は、Cerberus Technologies のビッグデータと BI の責任者です。