Amazon Web Services ブログ
Amazon Redshift の結果のキャッシュでクエリの応答時間を 1 秒未満に
お客様によると、データウェアハウスやビジネスインテリジェンスのユーザは、常に迅速な意思決定ができるように、非常に高速な応答時間を求めているということです。またユーザは、データが変わっていなくても、同じクエリを何度も繰り返すことがよくある、とも言います。クエリを繰り返すたびにコンピューティングリソースを消費するので、クエリ全体のパフォーマンスが低下します。
今回の記事では、Amazon Redshift のクエリ結果のキャッシュについて説明します。結果のキャッシュは、まさにその名前が示すことを実行します。つまり、クエリ結果をキャッシュに格納するのです。同じデータに対して同じクエリが行われると、同じクエリを再実行するのではなく、前の検索結果をキャッシュから読み取って即座に返します。結果のキャッシュによって、システムの使用が削減され、他のワークロードでより多くのリソースを利用できるようになります。これにより、ユーザーの応答時間が高速になり、クエリ全体のスループットが向上し、並行処理が増加します。
結果のキャッシュのオプション
データウェアハウスの結果のキャッシュを導入する方法には、主に 2 つの方法があります。1 番目は、データテーブルのサブセットを保存し、データウェアハウスの外側でクエリ結果をキャッシュする方法です。この方法では、データウェアハウスの外側に、ロジックとメモリを追加する必要があります。テーブルデータが修正されたときは必ず、キャッシュを無効にし、クエリを再実行することに細心の注意を払う必要があります。
2 番目は、データウェアハウス内にクエリ結果をキャッシュし、次に同じクエリがあった場合にキャッシュされた結果を返す方法です。同じクラスター内にデータをキャッシュしてそれを提供する方が早いので、こちらの方がパフォーマンスは高くなります。
Amazon Redshift では、クラスター内にクエリ結果をキャッシュする 2 番目の方法を採用して、より高いクエリのスループットを実現しています。Amazon Redshift の結果のキャッシュは、データやワークロードの変化に自動的に対応し、ユーザーに意識させることなく、多くの BI アプリケーションや SQL ツールの役割を果たしています。Amazon Redshift のお客様はすべて、追加料金を支払わず、デフォルトで利用できます。
Amazon Redshift が結果のキャッシュを導入して以来、この機能によって、お客様は 1 日数千時間の実行時間を節約してきました。サンフランシスコの AWS Summit で、「Amazon Redshift の結果のキャッシュを使って、今ではクエリの 20 パーセントが 1 秒未満で完了します」と Edmunds の Greg Rokita 技術担当取締役が述べました。 当社のクラスターはディスクへの依存が少なくなり、結果的にクラスターは残りのクエリー処理を改善できます。特に、Redshift ではこうした高速化をするのに何も変更する必要がなく、ミッションクリティカルなワークロードをサポートします。
動作の詳細
Amazon Redshift でクエリが実行されると、クエリと結果の両方がメモリにキャッシュされます。その後クエリが発生すると、クエリは正規化され、キャッシュ内のクエリと比較され、同じクエリがあるかどうか判定します。この比較では、Amazon Redshift は、元のデータに何らかの変更があったかということも判定します。テーブルまたは関数のデータ変更言語 (DML) またはデータ定義言語 (DDL) があれば、それを参照するキャッシュエントリだけを削除します。そうしたステートメントの例として、INSERT、DELETE、UPDATE、COPY、および TRUNCATEがあります。Amazon Redshift は、キャッシュメモリを管理し、古いエントリを削除し、キャッシュのメモリ利用が確実に最適化されるように維持します。
結果のキャッシュは Amazon Redshift によって完全に管理されているため、お使いのアプリケーションプログラムを変更する必要はありません。Amazon Redshift では、クラスター特有の条件に基づいて、自動的に最適な設定を選択するので、最も効率的な設定にするために、ユーザーがチューニングをする必要はありません。
Amazon Redshift が、過去に結果をキャッシュしたクエリをクエリで再利用するのに適しているかどうか判定するときは、クエリ計画、ワークロードマネージャー (WLM) およびクエリ実行エンジンはすべてバイパスします。キャッシュ結果は、1 秒未満の性能で即座にクライアントアプリケーションに返されます。この方法によって、コンピューティングリソースを必要とする ETL (抽出、変換、ロード) などのワークロードのために、クラスターリソースが解放されます。
設計と利用
次の図は、Amazon Redshift の結果キャッシュのアーキテクチャを示しています。
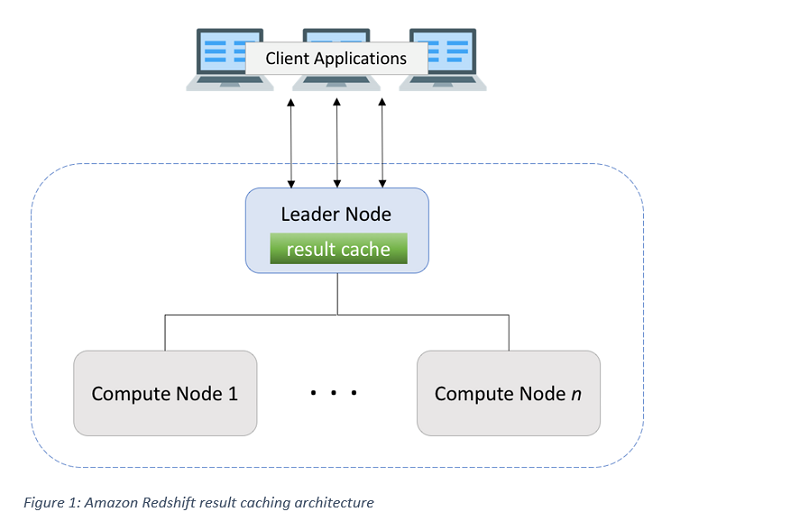
クエリ結果のキャッシュはリーダーノードに存在し、同じデータベースに対するさまざまなユーザーセッションで共有されます。この機能はユーザーが意識する必要はなく、ユーザー設定の必要もなく、デフォルトで動作します。結果のキャッシュは、Amazon Redshift の多版型同時実行制御 (MVCC) に準拠しています。複数のユーザーセッションが同時に 1 つのテーブルオブジェクトを読み取り/書き込みする場合、そのテーブルオブジェクトに適切なロックを取得し、キャッシュエントリのライフサイクルを管理します。さらに、キャッシュ結果のアクセス制御が管理されていて、キャッシュから結果行を検索するクエリで使用されるオブジェクトに必要なアクセス許可を、ユーザーが保持している必要があります。
結果キャッシュを利用できるクエリ
読み取り専用クエリは、若干の例外はあるものの、キャッシュに適しています。クエリの結果は次の状況ではキャッシュされません。
- クエリが、getdate() など、実行されるたびに評価する必要がある関数を使用する場合。
- クエリがシステムのテーブルやビューを参照する場合。
- クエリが外部のテーブル、つまり Amazon Redshift Spectrum テーブルを参照する場合。
- クエリがリーダーノードだけで実行する場合、または結果が大きすぎる場合。
クエリに current_date などの関数が含まれていて結果キャッシュの利用を望んでいると仮定します。current_date の値を (たとえば、ユーザーの JDBC アプリケーションで) 具体化することでクエリを書き換え、そのクエリの文字列を使用し、必要に応じてリフレッシュするということは検討できます。
実行したクエリのどれがキャッシュの結果を利用したかを判断するために、新しい列 source_query をシステムビュー SVL_QLOG に追加し、キャッシュからのクエリが実行されたとき、ソースクエリ ID を記録します。キャッシュされた結果を使用したクエリを調べるのに、次のクエリの例が使用できます。
結果キャッシュの詳細については、Amazon Redshift ドキュメントの結果のキャッシュを参照してください。
まとめ
Amazon Redshift の結果のキャッシュによって、繰り返しのクエリにコンピューティングリソースが浪費されることは確実になくなります。意思決定のサポートや業績の改善をするために、より少ない時間でより多くの分析を実行することが可能となります。この記事では、Amazon Redshift での結果のキャッシュの動作方法について説明し、Amazon Redshift のお客様への重要な影響について考察しました。結果のキャッシュは自動的に有効となりますので、お使いの環境で生まれる違いについてご理解ください。
その他の参考資料
この記事が役立つと思いましたら、データ ウェアハウジングをエクサバイト級に拡張する Amazon Redshift Spectrum、Collect Data Statistics Up to 5x Faster by Analyzing Only Predicate Columns with Amazon Redshift および Amazon Redshift – 2017 Recap も参照してください。
著者について
 Entong Shen は、Amazon Redshift クエリ処理チームのソフトウェアエンジニアです。5 年以上 MPP データベースの研究をしており、クエリの最適化、統計データ、SQL 言語の機能に重点的に取り組んでいます。余暇は、あらゆるジャンルの音楽を聴いたり、多肉植物庭園で庭仕事をして過ごします。
Entong Shen は、Amazon Redshift クエリ処理チームのソフトウェアエンジニアです。5 年以上 MPP データベースの研究をしており、クエリの最適化、統計データ、SQL 言語の機能に重点的に取り組んでいます。余暇は、あらゆるジャンルの音楽を聴いたり、多肉植物庭園で庭仕事をして過ごします。
 Larry Heathcote は、アマゾン ウェブ サービスのプリンシパルプロダクトマーケティングマネージャーで、データ ウェアハウジングと分析を担当しています。 データに基づいてビジネスの業績を洞察し、その結果を理解することに情熱を傾けています。家族との時間、家事、バーベキューとその昔ながらの味わいを楽しんでいます。
Larry Heathcote は、アマゾン ウェブ サービスのプリンシパルプロダクトマーケティングマネージャーで、データ ウェアハウジングと分析を担当しています。 データに基づいてビジネスの業績を洞察し、その結果を理解することに情熱を傾けています。家族との時間、家事、バーベキューとその昔ながらの味わいを楽しんでいます。
 Maor Kleider は、Amazon Redshift のシニアプロダクトマネージャーです。Amazon Redshift は、高速、シンプルかつコスト効率のよいデータウェアハウスです。お客様やパートナーの皆様と協働し、彼ら特有のビッグデータユースケースについて学び、その利用体験をよりよくすることに情熱を傾けています。余暇は、家族とともに旅行やレストラン開拓を楽しんでいます。
Maor Kleider は、Amazon Redshift のシニアプロダクトマネージャーです。Amazon Redshift は、高速、シンプルかつコスト効率のよいデータウェアハウスです。お客様やパートナーの皆様と協働し、彼ら特有のビッグデータユースケースについて学び、その利用体験をよりよくすることに情熱を傾けています。余暇は、家族とともに旅行やレストラン開拓を楽しんでいます。
 Meng Tong は、Amazon Redshift クエリ処理チームのソフトウェアエンジニアです。仕事は、rewriter、optimizer と executor、Redshift Spectrum、そして最近では Redshift 結果のキャッシュのクエリパフォーマンスを改善することに重点的に取り組んでいます。ビッグデータシステムのお客様のニーズに対して、シンプルかつエレガントなソリューションを見つけることに情熱を傾けています。Rafael Nadal の大ファンで、余暇はテニスを見たり、テニスをしたりして過ごします。
Meng Tong は、Amazon Redshift クエリ処理チームのソフトウェアエンジニアです。仕事は、rewriter、optimizer と executor、Redshift Spectrum、そして最近では Redshift 結果のキャッシュのクエリパフォーマンスを改善することに重点的に取り組んでいます。ビッグデータシステムのお客様のニーズに対して、シンプルかつエレガントなソリューションを見つけることに情熱を傾けています。Rafael Nadal の大ファンで、余暇はテニスを見たり、テニスをしたりして過ごします。
 Naresh Chainani は Amazon Redshift のシニアソフトウェア開発マネージャーでクエリ処理チームを率いています。お客様がタイムリーに物事の実態を見抜く力を獲得し、重要なビジネス上の意思決定ができるようにするための高性能のデータベースを構築することに情熱を傾けています。余暇は、テニスの本を読んだり、テニスをして過ごします。
Naresh Chainani は Amazon Redshift のシニアソフトウェア開発マネージャーでクエリ処理チームを率いています。お客様がタイムリーに物事の実態を見抜く力を獲得し、重要なビジネス上の意思決定ができるようにするための高性能のデータベースを構築することに情熱を傾けています。余暇は、テニスの本を読んだり、テニスをして過ごします。