Amazon Web Services ブログ
対話体験における生成系 AI の活用を探る: Amazon Lex, LangChain, SageMaker JumpStart による事始め
本記事は Exploring Generative AI in conversational experiences: An Introduction with Amazon Lex, Langchain, and SageMaker Jumpstart を日本語に翻訳したものです。
何もかもが速いペースで進む今日の世界で、人々がビジネスに期待するのは迅速かつ効率的なサービスです。ところが、サービスへの頻繁な問い合わせに対応できるだけの人的リソースが不足している場合、ビジネスが最高の顧客体験を提供することはとても困難です。しかしながら、昨今の大規模言語モデル (LLM) を活用した生成系 AI (Generative AI) の進歩により、ビジネスはそれぞれの顧客にパーソナライズされた効率的なカスタマーサービスを提供しつつ、この課題に立ち向かうことができます。
生成系 AI を用いたチャットボットは人間の知性を模倣できることで一躍有名になりました。タスク特化型のボットとは異なり、これらのボットは LLM を用いてテキストの分析と生成を行います。LLM は Transformer アーキテクチャに基づいています。Transformer とは、ラベル無しテキストから構成される大規模コーパスで学習することができる、2017 年 6 月に提案された深層ニューラルネットワークです。このアプローチにより、チャットボットはより人間らしい会話が可能になり、様々なトピックに対応できるようになりました。
本記事の執筆時点では、あらゆる規模の企業がこのテクノロジーを活用したいと考えていますが、どこから着手すれば良いか悩んでいます。そのように、生成系 AI、特に会話型 AI での LLM の活用を検討し始めている方々には、本記事がおすすめです。本記事には、事前学習済みのオープンソースの LLM を使用する Amazon Lex ボットを迅速にデプロイするためのサンプルプロジェクトも含まれています。さらに、そのコードではカスタムメモリマネージャーも実装されているので、LLM は以前のやりとりを思い出して、会話の背景情報やペースを保つことができます。本編に入る前に一つ強調しておきたいのは、一貫した品質の結果を得るためには、プロンプトや、 LLM のランダム性や決定性のパラメーターを微調整して実験することも重要ということです。
ソリューション概要
本ソリューションでは Amazon Lex ボットを Amazon SageMaker JumpStart で提供されるオープンソースの LLM と統合します。これらの LLM は、Amazon SageMaker エンドポイントとしてデプロイできます。また、LLM を利用したアプリケーションの実装を簡素化する、人気のフレームワーク LangChain も本ソリューションでは使用しています。さらに、QnABot を使用してチャットボットのユーザーインターフェイスを提供します。

はじめに、上で示した構成図のそれぞれの要素を説明します。
- SageMaker JumpStart は、多様なタスクに対応する、事前学習済みのオープンソースモデルを提供しています。これにより、機械学習 (ML) を迅速に開始できます。JumpStart が提供するオープンソースモデルの一つに、ディープラーニングコンテナにデプロイされた LLM である FLAN-T5-XL モデルがあり、本ソリューションではこのモデルを利用します。このモデルは、テキスト生成を含む様々な自然言語処理 (NLP) タスクで良い性能を発揮します。
- SageMaker のリアルタイム推論エンドポイントにより、ML モデルを迅速かつスケーラブルにデプロイできます。このエンドポイントを AWS Lambda 関数と統合することで、カスタムアプリケーションを構築できます。
- AWS Lambda 関数は Amazon Lex ボットまたは QnABot からのリクエストを使用して、SageMaker エンドポイントに対するリクエストを準備します。このときに LangChain を利用します。LangChain は、開発者が LLM を利用したアプリケーションを簡単に作成できるようにするフレームワークです。
- Amazon Lex V2 ボットには組み込みインテントタイプとして
Amazon.FallbackIntentがあります。これは、ユーザーの入力が、ボットのいずれのインテントとも一致しない場合にトリガーされます。 - QnABot は Amazon Lex ボットにユーザーインターフェイスを提供する、オープンソースの AWS ソリューションです。QnABot の
CustomNoMatchesアイテムに Lambda フック関数を設定し、QnABot が回答を見つけられない場合に Lambda 関数をトリガーするようにしました。本ソリューションでは、すでに QnABot をデプロイ済みの状態を前提としています。追加の設定手順は以降のセクションをご確認ください。
本ソリューションのシーケンス図は以下の通りです。

※訳註: 上図は原文の記事に掲載されている図中の文章を日本語に翻訳したものです。
ソリューションが実施する主なタスク
このセクションでは、ソリューションが実施する主なタスクについて説明します。このソリューションのソースコードは、GitHub リポジトリ で参照できます。
チャットボットのフォールバック処理
Lambda 関数は Amazon Lex V2 の Amazon.FallbackIntent と QnABot の CustomNoMatches アイテムを通じて「わからない」(“Don’t know”) と判定された回答を処理します。トリガーされると、この関数はセッションのリクエストとフォールバックインテントを調べます。セッションのリクエストがフォールバックインテントの場合、リクエストは Lex V2 ディスパッチャーに渡されます。そうでない場合は、QnABot ディスパッチャーがリクエストを使用します。以下のコードを参照してください。(訳註: これ以降、本記事で引用するコードでは、コメントのみ日本語に翻訳しています)
def dispatch_lexv2(request):
"""Summary
Args:
request (dict): ユーザーの入力チャットメッセージとコンテキスト (過去の会話) を含む Lambda イベント。
LexV2 セッション API を使用して過去の入力を管理する。 https://docs.thinkwithwp.com/lexv2/latest/dg/using-sessions.html
Returns:
dict: Lex V2 ディスパッチャーの返り値。LLM のレスポンス等を含む。
"""
lexv2_dispatcher = LexV2SMLangchainDispatcher(request)
return lexv2_dispatcher.dispatch_intent()
def dispatch_QnABot(request):
"""Summary
Args:
request (dict): ユーザーの入力チャットメッセージとコンテキスト (過去の会話) を含む Lambda イベント
Returns:
dict: QnABot の「わからない」という返答に対する Lambda フックの返り値。LLM のレスポンス等を含む。
詳細は https://docs.thinkwithwp.com/solutions/latest/QnABot-on-aws/specifying-lambda-hook-functions.html 参照。
"""
request['res']['message'] = "Hi! This is your Custom Python Hook speaking!"
qna_intent_dispatcher = QnASMLangchainDispatcher(request)
return qna_intent_dispatcher.dispatch_intent()
def lambda_handler(event, context):
print(event)
if 'sessionState' in event:
if 'intent' in event['sessionState']:
if 'name' in event['sessionState']['intent']:
if event['sessionState']['intent']['name'] == 'FallbackIntent':
return dispatch_lexv2(event)
else:
return dispatch_QnABot(event)LLM にメモリ保持機能を追加
マルチターンの会話、つまり複数回のやり取りがある会話で LLM が過去の会話の記録 (メモリ) を保つために、Lambda 関数には LangChain のカスタムメモリクラスが実装されています。このメカニズムは Amazon Lex V2 Sessions API を使用して、進行中のマルチターンの会話メッセージのセッション属性を追跡し、それまでの会話履歴を用いることで LLM にコンテキストを提供します。以下のコードを参照してください。
class LexConversationalMemory(BaseMemory, BaseModel):
"""Lex の会話履歴を使用する、LangChain のカスタムメモリクラス
Attributes:
history (dict): LangChain でメモリとして機能する会話履歴を保存する辞書
lex_conv_context (str): 会話履歴への入力として利用する LexV2 セッション API。
メモリはここから読み込まれる。
memory_key (str): LangChain で会話履歴を保存するメモリ変数のキー - "history"
"""
history = {}
memory_key = "chat_history" #pass into prompt with key
lex_conv_context = ""
def clear(self):
"""Clear chat history
"""
self.history = {}
@property
def memory_variables(self) -> List[str]:
"""メモリ変数
Returns:
List[str]: LangChain のメモリを保持しているキーのリスト
"""
return [self.memory_key]
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, str]:
"""Lex から現在の LangChain セッションメモリにメモリをロードする
Args:
inputs (Dict[str, Any]): 現在の LangChain セッションへのユーザー入力
Returns:
Dict[str, str]: LangChain メモリオブジェクト
"""
input_text = inputs[list(inputs.keys())[0]]
ccontext = json.loads(self.lex_conv_context)
memory = {
self.memory_key: ccontext[self.memory_key] + input_text + "\nAI: ",
}
return memoryLangChain の ConversationChain で上記のカスタムメモリクラスを利用するサンプルコードは以下の通りです。
# プロンプト、SageMaker でホストされた LLM、
# カスタムメモリクラスを利用して conversation chain を作成する
self.chain = ConversationChain(
llm=sm_flant5_llm,
prompt=prompt,
memory=LexConversationalMemory(lex_conv_context=lex_conv_history),
verbose=True
)プロンプトを定義
LLM のプロンプトとは、生成される応答の元となる質問や説明文のことです。プロンプトは、ユーザーが求めている応答をモデルが生成するよう誘導するのに役立ちます。以下のコードを参照してください。
# プロンプト定義
prompt_template = """The following is a friendly conversation between a human and an AI. The AI is
talkative and provides lots of specific details from its context. If the AI does not know
the answer to a question, it truthfully says it does not know. You are provided with information
about entities the Human mentions, if relevant.
Chat History:
{chat_history}
Conversation:
Human: {input}
AI:"""※訳註: 本記事で利用する FLAN-T5-XL モデルは 2023 年 6 月時点では日本語に対応していませんが、上記プロンプトテンプレートの日本語訳は以下の通りです。
# プロンプト定義
prompt_template = """以下は人間と AI の友好的な会話です。
AI はよく話し、会話の文脈を踏まえて、多くの具体的な情報を詳細に教えてくれます。
質問に対する答えを知らない場合、AI は誠実に「分かりません」と答えます。
AI が返答をするために、人間が言及する事柄に関する情報が補足されることもあります。
会話の履歴:
{chat_history}
会話:
人間: {input}
AI:"""Amazon Lex V2 セッションを利用し LLM にメモリ保持機能を追加
Amazon Lex V2 は、ユーザーがボットと対話し始めた時にセッションを開始します。手動で停止またはタイムアウトしない限り、セッションは長期間持続します。セッションには、メタデータと、セッション属性と呼ばれるアプリケーション固有のデータが格納されます。Amazon Lex は、Lambda 関数がセッション属性を追加または変更したときにクライアントアプリケーションを更新します。QnABot には、Amazon Lex V2 上でセッション属性を設定および取得するためのインターフェイスが含まれています。
私たちのコードでは、この仕組みを使って LangChain にカスタムメモリクラスを構築し、会話履歴をトラッキングし、LLM が短期的および長期的なやりとりを思い出せるようにしました。以下のコードを参照してください。
class LexV2SMLangchainDispatcher():
def __init__(self, intent_request):
# 詳細は Lex ボットの Lambda に対するリクエスト形式を参照: https://docs.thinkwithwp.com/lex/latest/dg/lambda-input-response-format.html
self.intent_request = intent_request
self.localeId = self.intent_request['bot']['localeId']
self.input_transcript = self.intent_request['inputTranscript'] # user input
self.session_attributes = utils.get_session_attributes(
self.intent_request)
self.fulfillment_state = "Fulfilled"
self.text = "" # response from endpoint
self.message = {'contentType': 'PlainText','content': self.text}
class QnABotSMLangchainDispatcher():
def __init__(self, intent_request):
# QnABot Session attributes
self.intent_request = intent_request
self.input_transcript = self.intent_request['req']['question']
self.intent_name = self.intent_request['req']['intentname']
self.session_attributes = self.intent_request['req']['session']前提条件
デプロイを開始するには、次の前提条件を満たす必要があります。
- AWS CloudFormation スタックを起動できるユーザーで AWS マネジメントコンソールにアクセスできること
- AWS Lambda と Amazon Lex のコンソール操作に慣れていること
ソリューションのデプロイ
ソリューションをデプロイするには、次の手順に従ってください。
- Launch Stack を選択して us-east-1 リージョンでソリューションを起動します:
![[Launch Stack]](https://d2908q01vomqb2.cloudfront.net/f1f836cb4ea6efb2a0b1b99f41ad8b103eff4b59/2023/05/21/ML-14328-cloudformation-launch-stack.png)
- スタック名 (Stack name) には、一意のスタック名を入力します。
- HFModel には、JumpStart で入手可能な
Hugging Face FLAN-T5-XLモデルを使用しています。 - HFTask には、
text2textと入力します。 - S3BucketName はそのままにしておきます
これらの設定項目は、ソリューションのデプロイに必要な Amazon Simple Storage Service (Amazon S3) アセットの検索に使用され、今後の本記事の更新に伴い変更される可能性があります。

- 機能 (Capabilities) 以下に記載されている注意書きを承認します。
- スタックの作成 (Create stack) を選択します。
合計で 4 つのスタックの作成が完了するはずです。

Amazon Lex V2 ボットの設定
Amazon Lex V2 ボットに関して追加の操作は必要ありません。CloudFormation テンプレートで面倒な作業は実施済みです。
QnABot の設定
本記事では、お客様の AWS 環境には既に QnABot がデプロイされていることを前提としています。もしまだデプロイしていない場合は、こちらのドキュメントに沿ってデプロイしてください。
- AWS CloudFormation コンソールで、上述のソリューションをデプロイしたメインスタックに移動します。
- 出力 タブの
LambdaHookFunctionArnの値をメモしておきます。これは後の手順で QnABot に入力する必要があります。

- QnABot Designer ユーザーインターフェイス (UI) に管理者としてログインします。
- Questions UI で、ADD (追加) を選択し、新しい質問を追加します。

- 次の値を入力します。
- ID –
CustomNoMatches - Question –
no_hits - Answer – 答えが分からない場合のデフォルトの返答
- ID –
- Advanced (詳細設定) を選択し、Lambda Hook セクションに移動します。
- 事前にメモしておいた Lambda 関数の Amazon Resource Name (ARN) を入力します。
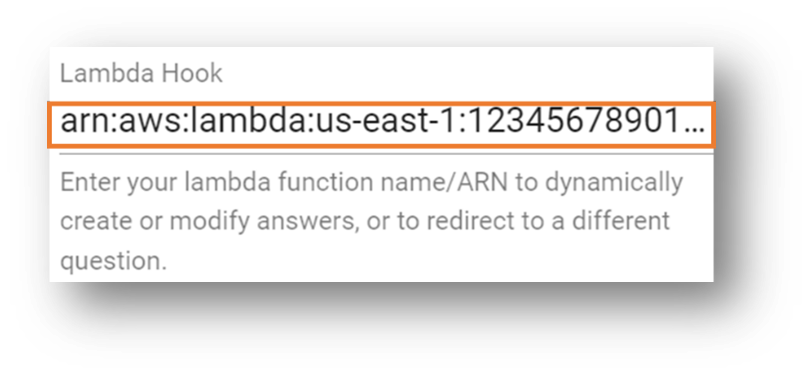
- セクションの一番下までスクロールして、Create (作成) を選択します。
成功したことを示すポップアップが表示されます。

登録した質問が、Questions (質問) ページ に表示されるようになりました。
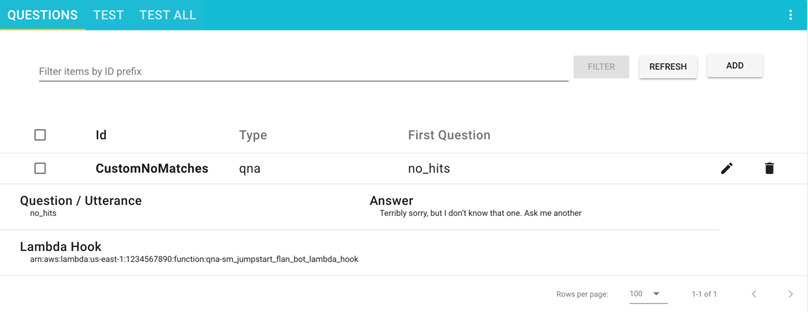
ソリューションのテスト
ソリューションのテストを進めましょう。まず注意事項として、今回は JumpStart が提供する FLAN-T5-XL モデルをファインチューニング無しに利用しています。そのため、モデルが予測できない挙動をする場合があり、その結果として応答に若干のばらつきが生じる可能性があります。
Amazon Lex V2 ボット統合のテスト
このセクションでは、SageMaker エンドポイントにデプロイされた LLM を呼び出す Lambda 関数と Amazon Lex V2 ボットの統合をテストします。
- Amazon Lex コンソールで、
Sagemaker-Jumpstart-flan-llm-fallback-botというタイトルのボットに移動します。このボットは、ボットに登録されたどのインテントとも入力が一致しない場合に、フォールバックインテントとして、LLM をホストする SageMaker エンドポイントを呼び出す Lambda 関数を実行するように設定されています。 - 画面左側のナビゲーションペインで インテント を選択します。

画面右上には、「英語 (US) has not built changes.」と、英語 (US) は変更がまだビルドされていないことを知らせるメッセージが表示されています。
- ビルドを選択します。
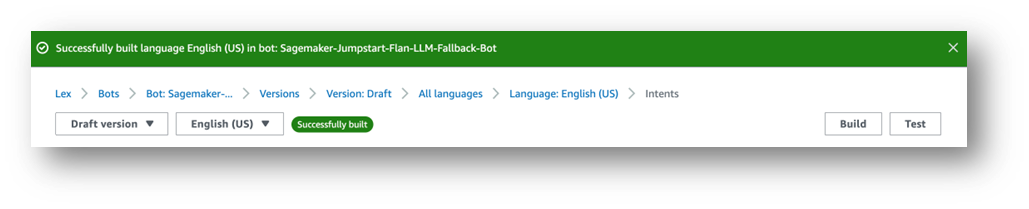
- ビルドが完了するまで待ちます。
最後に、以下のスクリーンショットの通り成功メッセージが表示されます。
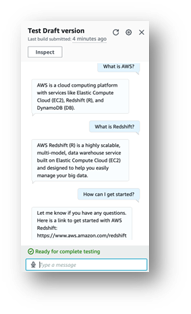
- テスト を選択します。
チャットウィンドウが表示され、モデルとの対話を試すことができます。
Amazon Connect と Amazon Lex ボットの統合を試してみることもおすすめします。また、Amazon Connect だけでなく、メッセージングプラットフォーム(Facebook、Slack、Twilio SMS)や、Amazon Chime SDK や Genesys Cloud を使用するサードパーティのコンタクトセンターなどとも統合できます。
QnABot 統合のテスト
このセクションでは、SageMaker エンドポイントにデプロイされた LLM を呼び出す Lambda 関数と QnABot on AWS の統合をテストします。
- QnABot の左上にあるメニューを開きます。
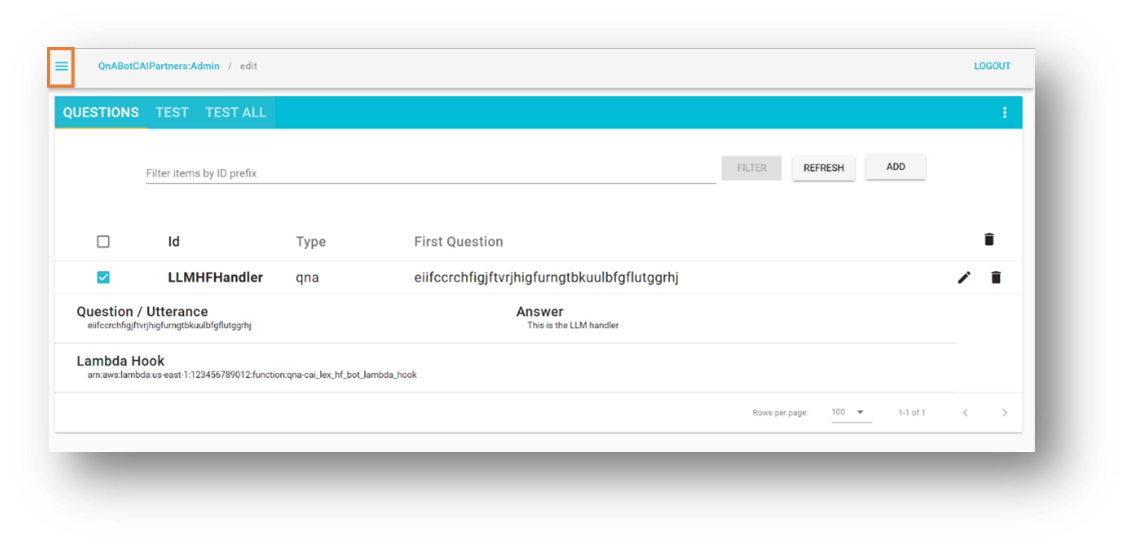
- QnABot Client を選択します。
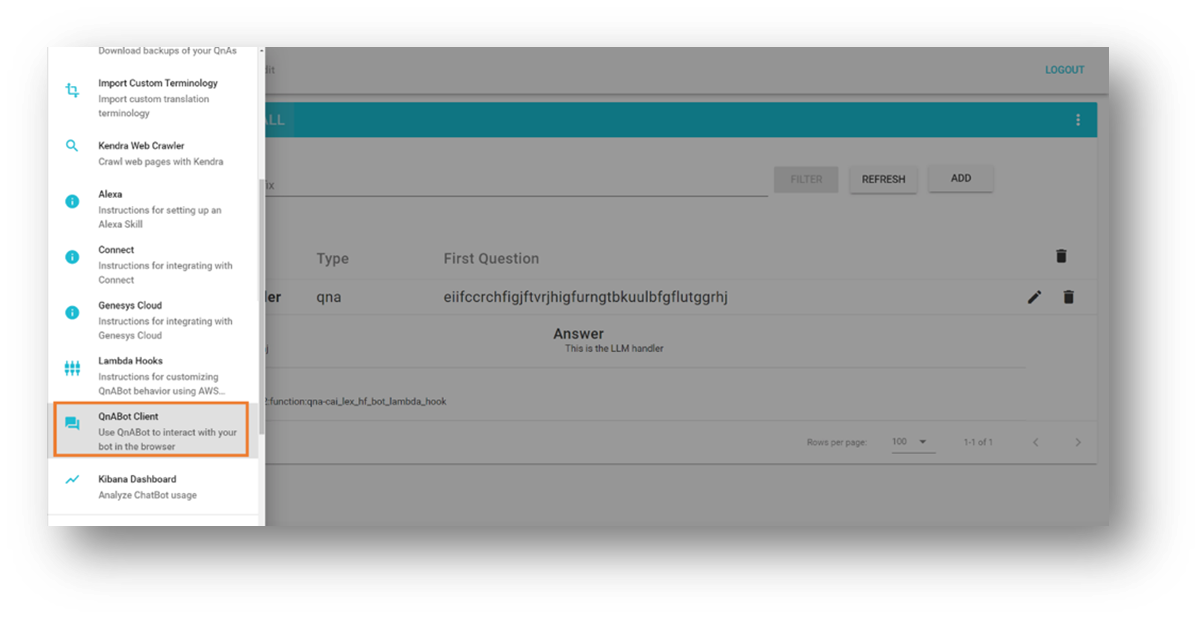
- Sign In as Admin (管理者としてサインイン) を選択します。

- ユーザーインターフェースに質問を入力します。
- ボットの応答を評価してください。

後片付け
今後追加の料金が発生しないように、以下の手順に従って、本ソリューションによって作成されたリソースを削除してください。
- AWS CloudFormation コンソールで、
SageMakerFlanLLMStackという名前のスタック (またはスタックに設定したカスタム名) を選択します。 - 削除を選択します。
- QnABot を今回のテスト用にデプロイした場合は、QnABot スタックを選択します。
- 削除を選択します。
結論
本記事では、タスク指向型のチャットボットに対するユーザーのリクエストをオープンソースの大規模言語モデル (LLM) にルーティングすることで、チャットボットにオープンドメインの対話に対応できる機能を追加する方法を検討しました。
次のステップとしては、以下をご提案します。
- 会話履歴を保存し永続化するメカニズムを構築する — 例えば会話履歴を Amazon DynamoDB または S3 バケットに保存し、Lambda 関数フックで取得することができます。この方法では、Amazon Lex が提供する非永続のセッション属性の管理に頼る必要はありません。
- 要約を試してみる — 複数回にわたる会話では、要約を生成してプロンプトで使用できるようにしておくと便利です。これにより、コンテキストを追加したり、会話履歴の使用を制限したりできます。また、ボットのセッションサイズを削減し、Lambda 関数のメモリ消費量を低く抑えることもできます。
- 様々なプロンプトを試してみる — 実験の目的に合わせて、元のプロンプトを変更してください。
- 最適な結果が得られるように言語モデルを調整する — アプリケーションに応じて、ランダム性 (
temperature) や決定性 (top_p) などの高度な LLM パラメータを変更して言語モデルを微調整できます。今回は事前学習済みのモデルとサンプルのパラメータを使用して例を示しましたが、ユースケースに合わせてパラメータを調整してみてください。
次回の記事では、トレーニング済みの LLM を搭載したチャットボットを、お客様ご自身のデータでファインチューニングする方法の例をご説明する予定です。
みなさんは AWS で LLM チャットボットを試していますか? ぜひコメント欄でお知らせください! (訳註: コメント欄は原文のブログ記事にのみ用意されています)
出典・参考
- この記事で扱ったソリューションのソースコード
- Amazon Lex V2 デベロッパーガイド
- AWS ソリューションライブラリー:QnABot on AWS
- FLAN T5 モデルを用いた Text2Text Generation
- LangChain – LLM を用いたアプリケーションの構築
- Amazon SageMaker JumpStart の基盤モデルを活用するサンプル
- Amazon BedRock – 最も簡単に基盤モデル (FM) を使用して生成系 AI アプリケーションを構築およびスケーリング
- 高精度な生成系 AI アプリケーションを Amazon Kendra、LangChain、大規模言語モデルを使って作る
執筆者について
 Marcelo Silva は最先端の製品の設計、開発、実装に長けている経験豊富な技術のプロフェッショナルです。Cisco でキャリアをスタートさせた Marcelo は、史上初のキャリアルーティングシステムの導入や ASR9000 の展開の成功など、さまざまな注目を集めるプロジェクトに取り組みました。彼の専門分野はクラウドテクノロジー、分析、製品管理にまで及んでおり、GenAI に取り組む前は、Cisco、Cape Networks、AWS などの複数の企業でシニアマネージャーを務めていました。現在、会話型AI/GenAI のプロダクトマネージャーである Marcelo は、様々な業界に革新的なソリューションを引き続き提供しています。
Marcelo Silva は最先端の製品の設計、開発、実装に長けている経験豊富な技術のプロフェッショナルです。Cisco でキャリアをスタートさせた Marcelo は、史上初のキャリアルーティングシステムの導入や ASR9000 の展開の成功など、さまざまな注目を集めるプロジェクトに取り組みました。彼の専門分野はクラウドテクノロジー、分析、製品管理にまで及んでおり、GenAI に取り組む前は、Cisco、Cape Networks、AWS などの複数の企業でシニアマネージャーを務めていました。現在、会話型AI/GenAI のプロダクトマネージャーである Marcelo は、様々な業界に革新的なソリューションを引き続き提供しています。
 Victor Rojo は、最新の AI、ML、ソフトウェア開発に情熱を注ぐ経験豊富なテクノロジストです。その専門知識を活かして、Amazon Alexa を米国およびメキシコ市場に導入する上で極めて重要な役割を果たしたほか、AWS パートナーへの Amazon Textract と AWS コンタクトセンターインテリジェンス (CCI) の立ち上げを成功に導きました。現在、会話型 AI コンピテンシーパートナープログラムの主任技術リーダーとして、Victor はイノベーションを推進し、業界の進化するニーズを満たす最先端のソリューションを提供することに全力を注いでいます。
Victor Rojo は、最新の AI、ML、ソフトウェア開発に情熱を注ぐ経験豊富なテクノロジストです。その専門知識を活かして、Amazon Alexa を米国およびメキシコ市場に導入する上で極めて重要な役割を果たしたほか、AWS パートナーへの Amazon Textract と AWS コンタクトセンターインテリジェンス (CCI) の立ち上げを成功に導きました。現在、会話型 AI コンピテンシーパートナープログラムの主任技術リーダーとして、Victor はイノベーションを推進し、業界の進化するニーズを満たす最先端のソリューションを提供することに全力を注いでいます。
 Justin Leto は、機械学習を専門とするアマゾンウェブサービスのシニアソリューションアーキテクトです。彼が情熱を注ぐのは、お客様が機械学習とAI の力を活用してビジネスの成長を促進できるよう支援することです。Justin は、AWS Summits を含むグローバル AI カンファレンスで発表したり、大学で講義をしたりしています。彼はニューヨーク市の機械学習と AI のミートアップをリードしています。余暇には、オフショアセーリングやジャズ演奏を楽しんでいます。彼は妻と赤ん坊の娘と一緒にニューヨークに住んでいます。
Justin Leto は、機械学習を専門とするアマゾンウェブサービスのシニアソリューションアーキテクトです。彼が情熱を注ぐのは、お客様が機械学習とAI の力を活用してビジネスの成長を促進できるよう支援することです。Justin は、AWS Summits を含むグローバル AI カンファレンスで発表したり、大学で講義をしたりしています。彼はニューヨーク市の機械学習と AI のミートアップをリードしています。余暇には、オフショアセーリングやジャズ演奏を楽しんでいます。彼は妻と赤ん坊の娘と一緒にニューヨークに住んでいます。
 Ryan Gomes は AWS プロフェッショナルサービスインテリジェンスプラクティスのデータ & ML エンジニアです。クラウドの分析と機械学習ソリューションを通じて、お客様がより良い成果を達成できるよう支援することに情熱を注いでいます。仕事以外では、フィットネス、料理、友人や家族との充実した時間を楽しんでいます。
Ryan Gomes は AWS プロフェッショナルサービスインテリジェンスプラクティスのデータ & ML エンジニアです。クラウドの分析と機械学習ソリューションを通じて、お客様がより良い成果を達成できるよう支援することに情熱を注いでいます。仕事以外では、フィットネス、料理、友人や家族との充実した時間を楽しんでいます。
 Mahesh Birardar はアマゾンウェブサービスのシニアソリューションアーキテクトで、DevOps とオブザーバビリティを専門としています。彼は、拡張可能な費用対効果の高いアーキテクチャをお客様が実装できるよう支援することにやりがいを感じています。仕事以外では、映画鑑賞やハイキングを楽しんでいます。
Mahesh Birardar はアマゾンウェブサービスのシニアソリューションアーキテクトで、DevOps とオブザーバビリティを専門としています。彼は、拡張可能な費用対効果の高いアーキテクチャをお客様が実装できるよう支援することにやりがいを感じています。仕事以外では、映画鑑賞やハイキングを楽しんでいます。
 Kanjana Chandren はアマゾンウェブサービス (AWS) のソリューションアーキテクトで、機械学習に情熱を注いでいます。彼女はお客様の AWS ワークロードの設計、実装、管理を支援しています。仕事以外では、旅行、読書、家族や友人と過ごすのが大好きです。
Kanjana Chandren はアマゾンウェブサービス (AWS) のソリューションアーキテクトで、機械学習に情熱を注いでいます。彼女はお客様の AWS ワークロードの設計、実装、管理を支援しています。仕事以外では、旅行、読書、家族や友人と過ごすのが大好きです。
翻訳は AWS ソリューション・アーキテクトの安藤が担当しました。原文はこちらです。