Amazon Web Services ブログ
Category: Analytics

第一三共、AWSと連携しAIエージェント統合型創薬基盤の構築を開始 ー AI・クラウド・実験自動化技術の融合で次世代創薬研究プロセスを実現
第一三共株式会社(以下、第一三共)はAWSとの連携を強化し、AIエージェントシステムを統合した創薬研究基盤の構 […]

日本のヘルスケア・ライフサイエンス業界における戦略的ビジョン「Journey for 2030 データがつながる、価値を生む」を発表
データの分断を超えて、革新的な患者体験へ ヘルスケア・ライフサイエンス業界はセキュリティが極めて重要な業界であ […]

Amazon Connect Cost Insight Dashboard によるコストの可視化と最適化
コンタクトセンターのリーダーは常にコストの可視化を求めています。この記事ではコンタクトセンターのコスト情報を可視化する Amazon Connect Cost Insight Dashboard について紹介しています。このダッシュボードは月次コストトレンドの追跡、サービスコンポーネント別のコスト分析、通話料の分析などの機能を提供し、コンタクトセンターマネージャーが情報に基づいた適切な意思決定を行い、運用を最適化するためのデータを提供します。

Amazon QuickSight BIOps – パート3 : API を使用したアセットのデプロイ
このシリーズのパート3では、QuickSight における API 駆動型の BIOps 戦略を取り上げ、クロスアカウントおよび複数環境でのアセット展開、データセット更新時のコンフリクト検出と解決、そして異なる環境間での権限管理に焦点を当てています。

Amazon QuickSight BIOps – パート2 : API を使用したバージョン管理
本記事は、2025年8月6日に公開された Amazon QuickSight BIOps – Part 2: […]

Amazon QuickSight BIOps – パート1 : バージョン管理とコラボレーションのためのノーコードガイド
Amazon QuickSightでのダッシュボード管理をもっと安全・効率的にしませんか?
本記事では、コードを書かずにUI操作だけで実現できる「BIOps」ワークフローをご紹介!ダッシュボードのバージョン管理、安全な並行開発、ビジュアルの再利用により、BIチームのコラボレーションを加速させ、手作業によるミスを削減します。

国防総省の演習において AWS がレジリエントかつセキュアなエッジトゥクラウドを実証
本ブログは 2025 年 4 月 24 日に公開された AWS Public Sector ブログ「AWS d […]

Amazon SageMaker レイクハウスアーキテクチャによる Amazon S3 上の Apache Iceberg テーブルの最適化設定の自動化
本記事は、2025 年 8 月 8 日に公開された The Amazon SageMaker lakehous […]
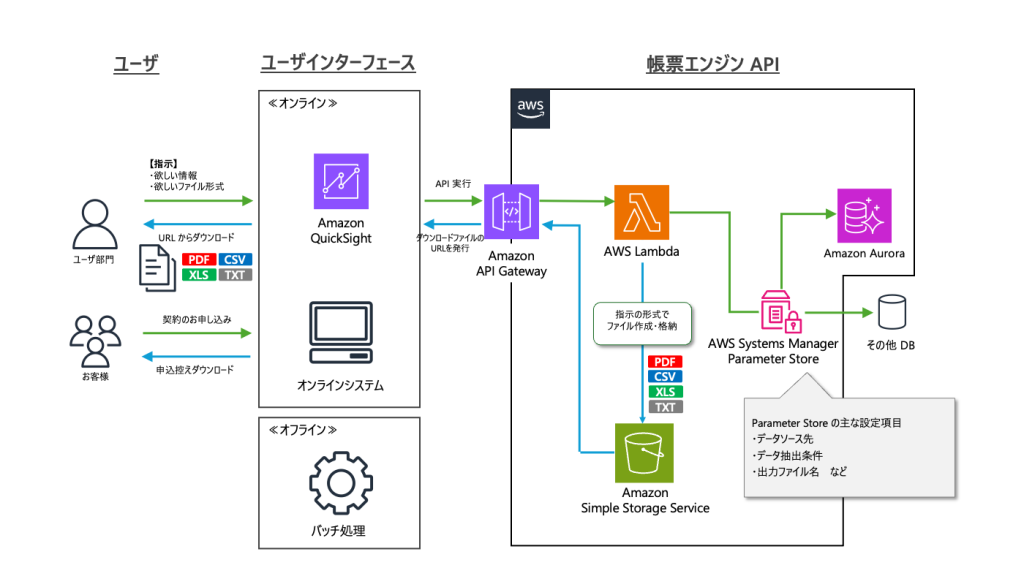
【寄稿】SBI生命保険株式会社における、Amazon QuickSight で実現する帳票業務改革
本記事は SBI生命保険株式会社 狩野泰隆氏から寄稿いただきました。
SBI生命保険は昨今の委託先による大規模情報漏洩事件とデジタルトランスフォーメーション (DX) 時代の帳票システム再構築という課題に取り組んできました。

【開催報告】店舗業務にフォーカス!小売業界向け AI エージェント活⽤ワークショップ
2025年9月4日に開催された小売業界向けAIエージェント活用ワークショップの開催報告です。ファッション、アパレル、コンビニエンスストア等の小売企業15社が参加。生成AIの最新動向から、在庫管理・売上分析エージェントのハンズオン、そして店舗業務効率化のハッカソンまで実践的な内容を体験いただきました。ハッカソンでは6つの具体的なユースケース(売れ筋商品の補充発注、シフト変更調整、週報作成、店舗コンシェルジュ、商品ポップ作成、滞留在庫商品の広告作成)を特定し、画面プロトタイプの作成まで実施いただきました。