Amazon Web Services ブログ
Category: Analytics

Octus が Amazon OpenSearch Service へのゼロダウンタイム移行でインフラストラクチャコストを 85% 削減した方法
データ量が指数関数的に増加し続ける中、ミッションクリティカルなワークロードが求める高いパフォーマンスと信頼性を維持しながら、検索インフラストラクチャのコストを最適化するプレッシャーが高まっています。多くの企業は、運用オーバーヘッドが大きく、効率的なスケーリングを制限する複雑で高コストな検索システムを管理しています。検索システム間の移行が必要な場合、この課題はさらに深刻になります。従来、移行には大幅なダウンタイム、複雑なデータ同期、ビジネス運用への大きな影響が伴います。エンタープライズアプリケーションは、カスタマーエクスペリエンス、ビジネスインテリジェンス、運用継続性に影響を与えるサービス中断を許容できません。移行戦略は、移行プロセス全体を通じてゼロダウンタイムを維持し、完全なデータ整合性を確保しながら、コスト最適化と運用改善を実現する必要があります。
2013年に設立された Octus(旧 Reorg)は、世界をリードするバイサイド企業、投資銀行、法律事務所、アドバイザリー企業向けの重要なクレジットインテリジェンスおよびデータプロバイダーです。比類のない人間の専門知識を実績のあるテクノロジー、データ、AI ツールで補完することで、Octus は金融業界全体で決定的なアクションを促す強力なインサイトを提供しています。
この記事では、Octus が Elastic Cloud で実行していた Elasticsearch ワークロードを Amazon OpenSearch Service に移行した方法を紹介します。複数のシステムを管理する状態から、OpenSearch Service を活用したコスト効率の高いソリューションへの移行の道のりをたどります。また、移行を成功させたアーキテクチャの選択と実装戦略を共有します。その結果、移行中もサービスの可用性を中断することなく、パフォーマンスの向上とコスト効率の改善を実現しました。

Amazon OpenSearch Service が GPU アクセラレーションと自動最適化でベクトルデータベースのパフォーマンスとコストを改善
本日、Amazon OpenSearch Service において、サーバーレス GPU アクセラレーションとベクトルインデックスの自動最適化を発表しました。これにより、大規模なベクトルデータベースをより高速かつ低コストで構築でき、検索品質、速度、コストの最適なトレードオフを実現するようにベクトルインデックスを自動的に最適化できます。
本日発表された新機能は以下のとおりです。
GPU アクセラレーション – GPU アクセラレーションを使用しない場合と比較して、最大 10 倍高速にベクトルデータベースを構築でき、インデックス作成コストを 4 分の 1 に削減できます。また、10 億規模のベクトルデータベースを 1 時間以内に作成できます。コスト削減と速度の大幅な向上により、市場投入までの時間、イノベーションの速度、大規模なベクトル検索の導入において優位性を得ることができます。
自動最適化 – ベクトルの専門知識がなくても、ベクトルフィールドの検索レイテンシー、品質、メモリ要件の最適なバランスを見つけることができます。この最適化により、デフォルトのインデックス設定と比較して、コスト削減と再現率の向上を実現できます。手動でのインデックスチューニングには数週間かかることがあります。

Cluster Insights のご紹介: Amazon OpenSearch Service クラスター向け統合モニタリングダッシュボード
Amazon OpenSearch Service クラスターは、CloudWatch や Amazon OpenSearch Service コンソールを通じてアクセスできる豊富な運用メトリクスを提供し、効果的なパフォーマンスモニタリングとアラート作成をサポートします。しかし、クラスター内の回復力やパフォーマンスの課題を特定することは困難な場合があります。リソースを大量に消費するクエリを特定したり、パフォーマンス低下の傾向を把握したりするプロセスには時間がかかることがあります。
これらの課題に対処するため、私たちは Cluster Insights をリリースしました。これは、厳選されたインサイトと実行可能な緩和手順を提供する統合ダッシュボードです。このダッシュボードは、ノード、インデックス、シャードレベルの詳細なメトリクスを表示し、最高の回復力と可用性を維持するためのセキュリティと回復力のベストプラクティスの簡潔なサマリーを提供します。
このブログでは、主要な機能とメトリクスを含む Cluster Insights のセットアップと使用方法について説明します。最後まで読むと、Cluster Insights を使用して OpenSearch Service クラスター内のパフォーマンスと回復力の問題を認識し、対処する方法を理解できるようになります。

AWS Well-Architected フレームワーク用 Amazon OpenSearch レンズのご紹介
今年初め、AWS は AWS Well-Architected ホワイトペーパーである Amazon OpenSearch Service レンズをリリースしました。AWS Well-Architected フレームワークは、アーキテクチャを評価し、スケーラブルな設計を実装するための一貫したアプローチを提供します。このフレームワークを使用して、Amazon OpenSearch Service レンズは AWS Well-Architected レビューを実施し、OpenSearch Service デプロイメントの技術的リスクを評価・特定する方法を概説しています。
この記事では、Amazon OpenSearch Service レンズを使用して、OpenSearch Service ワークロードをアーキテクチャのベストプラクティスに照らして評価する方法を紹介します。

Amazon Kinesis Data Streams で 10 倍大きなレコードサイズをサポート: リアルタイムデータ処理の簡素化
Amazon Kinesis Data Streams で、レコードサイズの上限が従来の 10 倍となる 10MiB までサポートされるようになりました。この機能強化により、既存の Kinesis Data Streams API をそのまま使用しながら、断続的に発生する大きなデータペイロードをデータストリームに送信できるようになりました。また、PutRecords リクエストの最大サイズも 5MiB から 10MiB に 2 倍に拡大され、IoT 分析、変更データキャプチャ(CDC)、生成 AI ワークロードにおけるデータパイプラインの簡素化と運用オーバーヘッドの削減が実現します。

Amazon MSK Express ブローカーが Intelligent Rebalancing をサポートし、操作パフォーマンスが 180 倍高速に
本日より、Amazon Managed Streaming for Apache Kafka (Amazon MSK) Provisioned クラスターで Express ブローカーを使用するすべての新規クラスターで、追加料金なしで Intelligent Rebalancing がサポートされます。この新機能により、Apache Kafka クラスターのスケールアップまたはスケールダウン時に自動的なパーティションバランシング操作を実行できます。Intelligent Rebalancing は、Express ブローカーを使用する Amazon MSK クラスターの Kafka リソースを最適にリバランスすることで、キャパシティ使用率を最大化し、パフォーマンスを向上させます。これにより、パーティションを個別に管理したり、サードパーティツールを使用したりする必要がなくなります。Amazon MSK Express ブローカーの Intelligent Rebalancing は、Standard ブローカーと比較して最大 180 倍高速にこれらの操作を実行します。

AWS Clean Rooms が ML モデルトレーニング用のプライバシーを強化する合成データセットの生成を開始します
2025 年 11 月 30 日、AWS Clean Rooms 向けのプライバシーを強化する合成データセット […]
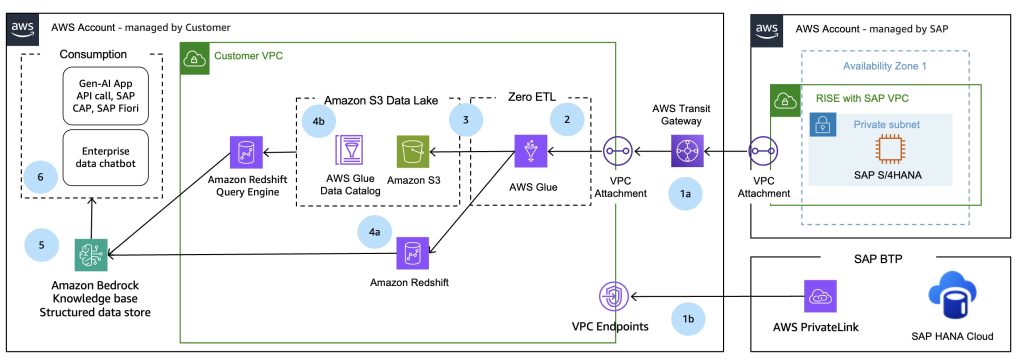
Amazon Bedrock Knowledge BasesでSAPおよびエンタープライズデータから新たな可能性を解き放つ
生成AI(Generative AI)の力とエンタープライズデータインテリジェンスを組み合わせた新しいソリューションを見てみましょう。この記事では、Amazon Bedrock Knowledge Basesが組織のSAPおよびエンタープライズデータの活用方法をどのように革新し、イノベーション、効率性、戦略的意思決定のための新たな可能性を創出しているかを探ります。自然言語クエリから自動化されたドキュメント処理、インテリジェントなインサイト生成まで、このソリューションが企業のSAP投資をAI時代の戦略的資産に変革する方法をご紹介します。
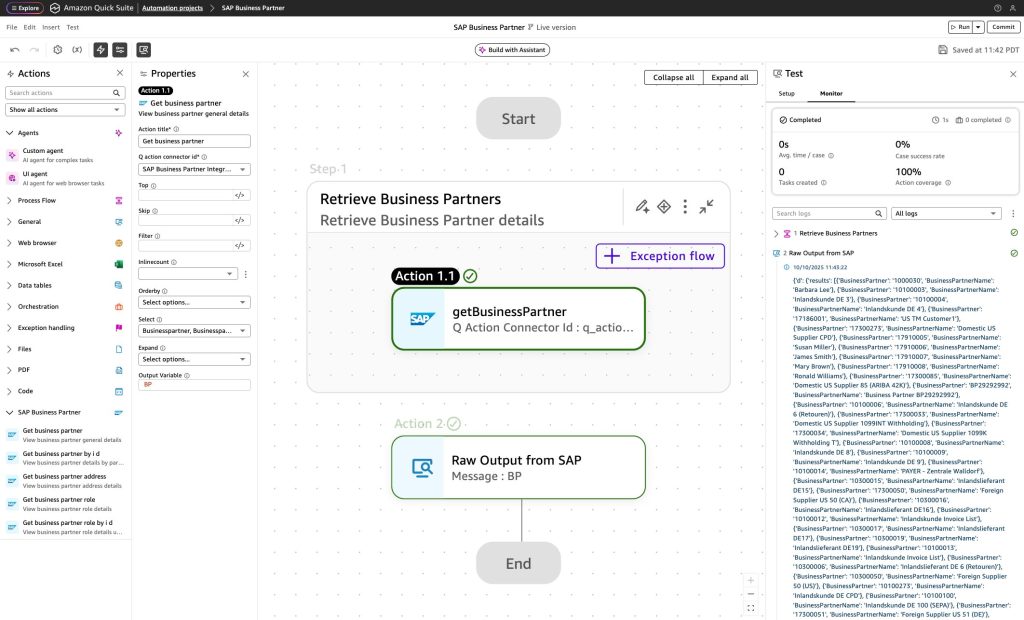
Amazon Quick AutomateでAI駆動のSAP自動化をシームレスに構築
このブログでは、Quick Suite内で利用可能なSAP用の組み込みコネクタと、お客様がAmazon Quick Automateを使用してこれらのコネクタを活用し、ビジネスオペレーションを合理化する強力な自動化を構築する方法について説明します。Quick Automateは、企業が大規模で回復力のある自動化を構築、展開、維持できるようにするQuick Suiteの機能です。AWS Action Connectors for SAPは、お客様がライブSAPデータに対してリアルタイムの読み取り操作を実行できるようにし、Quick AutomateがSAP S/4HANAなどのSAP ERPシステムとシームレスに対話できるようにします。

AWSとパートナーソリューションによるセキュアなデータメッシュの構築
このブログでは、AWS ネイティブの分析サービスとサードパーティエンジンを同時に活用することを目的としたデータメッシュアーキテクチャを実装するための 3 つの重要な要件を探ります:(1)クロスカタログメタデータフェデレーション、(2)クロスアカウント&クロスエンジンでの認証と認可、(3)分散ポリシーの反映
AWS をデータプロデューサーとコンシューマーの両方として実用的な実装パターンを検討し、Databricks や Snowflake などのパートナーとの統合アプローチを代表例として紹介します。
これらのパターンは、組織が企業全体のガバナンスを維持しながら、データメッシュの中核原則をサポートする柔軟で安全かつスケーラブルなデータアーキテクチャをどのように構築するかを示しています。