本投稿は、 Manojit Saha Sardar と Chirantan Pandya による記事 「Group database tables under AWS Database Migration Service tasks for PostgreSQL source engine」を翻訳したものです。
AWS Database Migration Service (AWS DMS) は、データベースやデータウェアハウスを含むデータリポジトリの転送と複製を容易にするために設計されたクラウドベースのサービスです。同種および異種のデータベースシステム間でデータを転送するソリューションを提供し、さまざまなデータプラットフォーム間の移行を可能にします。
データ転送プロセスは通常、大きく2 つのフェーズがあります:
- 既存データの移行 (フルロード) – このフェーズでは、AWS DMS が全てのデータ転送を実行し、元のデータストアから転送先のデータストアへ既存のすべての情報を転送します。
- 継続的な同期 (変更データキャプチャ) – 初期のフルロードの後、AWS DMS は変更データキャプチャ (CDC) と呼ばれている方法を通じて、データ変更の継続的な同期を可能にします。これらの変更はリアルタイムまたはニアリアルタイムで宛先のデータストアに継続的に転送され、適用されます。これにより、宛先のデータストアと元のデータストアが同期した状態を維持します。
AWS DMS は、リレーショナルデータベース、データウェアハウス、NoSQL データベースなど、幅広いソースおよびターゲットデータリポジトリに対応しています。転送を成功させるには、データベースとアプリケーションの前提条件に取り組むことが不可欠であり、初期段階でのベースとなる準備と計画がこの目標達成に重要な役割を果たします。
AWS DMS はデータベース移行のための堅牢なサービスを提供していますが、移行はプロジェクト毎にユニークであり、それぞれ異なる課題を抱えています。移行を成功させるために不可欠なことは適切な準備と設計プロセスです。パフォーマンスの最適化や潜在的な遅延問題への対処は特に重要です。
このブログ記事では、プロセスの早い段階でフルロードと CDC 遅延の潜在的な根本原因を把握するためのガイダンスを提供し、AWS DMS タスクで最高のパフォーマンスを達成するためにテーブルを適切にクラスタリングする方法を提示します。この記事で説明する戦略に従うことで、データベース移行をより効果的に計画し、タスクの規模を見積もり、潜在的な問題を最小限に抑え、パフォーマンスを最大化させるための効率的な転送プロセスを設計することができます。
データの把握
データ移行プロジェクトに着手するためには、最初に転送するデータを理解する必要があります。フルロードによる転送フェーズでは、ソース情報の完全なレプリカをターゲットのデータベースに転送することが含まれます。この手順により、正確なデータのコピーが、ソースデータベースからコピー先のデータベースに確実に入力されます。
CDC は、ソースのデータベースからのデータおよびデータ構造 (スキーマ) に対して発生した変更をリアルタイムまたはニアリアルタイムで記録する方法です。CDC は、これらの変更を他のデータベースやアプリケーションに配信し、簡単にソースのデータベースと同期し続けることができます。
必要な移行タスクの数やテーブルのグルーピングについて見積もるために、データベースのサイズ、運用負荷、およびハードウェア仕様を調べることで、データベース再配置のフルロードと CDC の要件全体を評価できます。
AWS DMS を利用する際、データ転送の速度に直接的または間接的に影響を与える要因はいくつかあります。以下は、フルロードと CDC の両方に共通する典型的な要因の一部です:
- データベースオブジェクトの規模 – 巨大なテーブル( 2 TB を超えるもの)を専用の移行タスクで分離することで、移行効率を向上させることができます。大規模なデータセットの処理を特定のタスクや操作内で分離することで、転送プロセスがより効率的かつ効果的になる可能性があります。
- セグメント化されたオブジェクトとされていないオブジェクト – 複数のテーブルを同時に読み込むことで、大きなセグメント化されたテーブルを転送できます。AWS DMS では、複数の並列スレッドを使用して単一の大規模テーブルを読み込むこともできます。これは、複数のセグメントとサブセグメントを持つ数十億レコードのテーブルに特に有効です。
- 主キーとユニークキーがないオブジェクト – AWS DMS は、大規模なオブジェクトを持つソーステーブルを転送するために、主キーまたはユニークキーを必要とします。
- ラージオブジェクト( LOB ) – AWS DMS は、レプリケーションインスタンスに適切なメモリを割り当てるために必要な、列行ごとの LOB サイズを特定することができないため、LOB 列には特別な処理が必要です。AWS DMS は、LOB データを移行するためのフル、制限付き、インラインの LOB モードを提供しています。LOB を別のタスクに保持することで、転送アクティビティを効率的に管理できます。
- 変更量 – ワークロードに CDC の変更が大量に含まれる場合、同じレコードセットを繰り返し更新したり、同じレコードを挿入または更新して削除したりする場合は、バッチ適用を使用してターゲットへの適用スループットを向上させることができます。
ソリューションの概要
この投稿の目的は、ソースデータベースのデータディクショナリを分析し、その情報をハードウェアの詳細と組み合わせて、効率的なデータ移行タスクのための推奨事項を作成することです。この分析により、AWS DMS タスクの最適な数と、そのタスク内にあるテーブルのグループ分けを決定し、移行プロセス中の潜在的な遅延問題を軽減します。
このワークフローには、以下のステップが含まれます:
- ソースの PostgreSQL データベースにコントロールテーブルを作成します。
- データディクショナリテーブルとビューを使用して、テーブルサイズ、パーティション、インデックス、制約、データ型、LOB データを分析し、コントロールテーブルにデータを入力します。
- 受信する変更量をモニタリングして、テーブルの日次による増加量を把握します。
- ステップ番号でテーブルを分類します。
- テーブルをグループ化します。
以下の図は、本ソリューションのアーキテクチャを示しています。
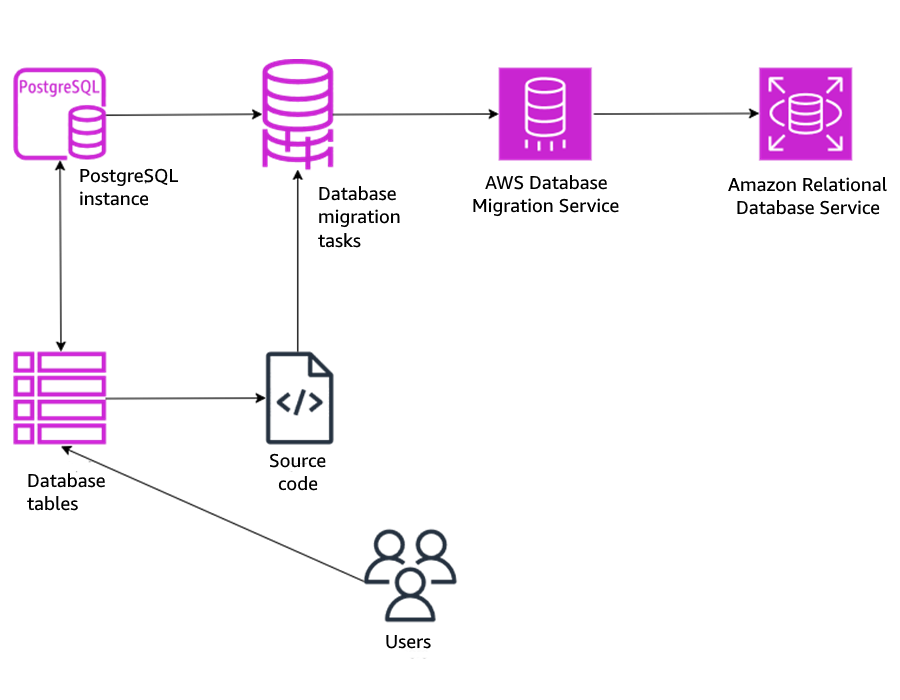
前提条件
以下の知識があると、このブログ記事が理解しやすくなります:
- AWS DMS
- PostgreSQL
- psql および plpgsql プロシージャ
1. ソースの PostgreSQL データベースでコントロールテーブル作成
この最初のステップでは、table_mapping という名前のコントロールテーブルを作成します。これにより、どのデータを移行しているかを一目で理解できるようになります。このテーブルは、システムカタログと統計ビューを参照して作成され、テーブルのサイズ、パーティション、パーティションサイズ (件数、平均、最小、最大)、LOB カラム、インデックス数、主キーまたはユニークキー制約、外部キー制約、およびテーブルに対する切り捨て、挿入、更新、削除操作の DDL (データ定義言語) / DML (データ操作言語) 操作回数に関する情報が含まれます。
このコントロールテーブルは、テーブルをグループ化する次のステップで使用するためのベースラインデータを提供します。
ソースの PostgreSQL データベースにコントロールテーブルを作成するには:
- ソースの PostgreSQL データベースに接続します。
- 以下の SQL ブロックを実行して、コントロールテーブルを作成します:
CREATE TABLE TABLE_MAPPING (
OWNER VARCHAR(30),
OBJECT_NAME VARCHAR(30),
OBJECT_TYPE VARCHAR(30),
SIZE_IN_MB NUMERIC(12,4),
STEP INTEGER,
IGNORE CHAR(3),
PARTITIONED CHAR(3),
PART_NUM INTEGER,
SPECIAL_HANDLING CHAR(3),
PK_PRESENT CHAR(3),
UK_PRESENT CHAR(3),
LOB_COLUMN INTEGER,
GROUPNUM INTEGER,
TOTAL_DML INTEGER
);
2. コントロールテーブルへの入力
コントロールテーブルが作成できたところで、PostgreSQLデータベース内のシステムカタログおよび統計ビューを用いてコントロールテーブルにデータを格納できます。これらはデータベースオブジェクトに関連するサイズ、タイプ、パーティショニング、制約、LOBデータに関する情報を提供します。具体的には、以下のデータディクショナリオブジェクトが挙げられます:
- PG_TABLES – PostgreSQL データベース内の各テーブルに関する有用な情報へのアクセスを提供します。
- PG_PARTITIONED_TABLE – このカタログテーブルは、テーブルがどのようにパーティション化されているかに関する情報を格納します。
- PG_INHERITS – このカタログテーブルは、テーブルとインデックスの継承階層に関する情報を記録します。データベース内の各直接的な親子テーブルまたはインデックスの関係に対して 1 つのエントリが存在します。
- PG_CLASS – このカタログテーブルは、列を持つテーブルやインデックス、シーケンス、ビュー、マテリアライズドビュー、複合型、TOAST テーブルなどのその他のオブジェクトについて説明します。
- PG_NAMESPACE – このカタログテーブルは名前空間を格納します。名前空間は SQL スキーマの基礎となる構造です。各名前空間は、名前の競合なしに、リレーションと型の個別のコレクションを持つことができます。
- INFORMATION_SCHEMA.COLUMNS – データベース内のテーブルとビューの列に関するメタデータを提供します。これは、異なるデータベースシステム間でテーブル構造に関する情報にアクセスするための標準的な方法です。
これらのカタログとビューオブジェクトをクエリすることで、データベースオブジェクトに関するメタデータを取得できます。これにより、データベース内のさまざまなオブジェクトの構造、サイズ、制約、および変更点を特定し分析することができます。
それでは、システムカタログと統計ビューからコントロールテーブルに読み込みます:
- 対象スキーマ (ここでは
'admin' を使用) にあるデータベーステーブルの詳細 (名前、サイズ、パーティションなど) をコントロールテーブルに挿入します:
INSERT INTO admin.table_mapping(OWNER, OBJECT_NAME, OBJECT_TYPE, SIZE_IN_MB, PART_NUM, PARTITIONED)
SELECT
schemaname,
tablename,
'TABLE',
pg_total_relation_size(schemaname || '.' || tablename) / 1024.0 / 1024.0,
CASE WHEN EXISTS (
SELECT 1 FROM pg_partitioned_table pt
JOIN pg_class c ON c.oid = pt.partrelid
WHERE c.relname = tablename
) THEN (
SELECT count(*) FROM pg_inherits
WHERE inhparent = (schemaname || '.' || tablename)::regclass
) ELSE 1 END,
CASE WHEN EXISTS (
SELECT 1 FROM pg_partitioned_table pt
JOIN pg_class c ON c.oid = pt.partrelid
WHERE c.relname = tablename
) THEN 'YES' ELSE 'NO' END
FROM pg_tables
WHERE schemaname = 'admin';
'admin' スキーマのマッピングテーブルから子テーブルデータをクリーンアップします:
DELETE FROM admin.table_mapping WHERE object_name IN (SELECT
child.relname AS child_table
FROM pg_inherits
JOIN pg_class parent ON pg_inherits.inhparent = parent.oid
JOIN pg_class child ON pg_inherits.inhrelid = child.oid
JOIN pg_namespace nmsp_parent ON nmsp_parent.oid = parent.relnamespace
JOIN pg_namespace nmsp_child ON nmsp_child.oid = child.relnamespace
WHERE parent.relkind = 'p' and nmsp_child.nspname ='admin');
- 親テーブルのパーティションテーブルサイズを設定します:
WITH partition_sizes AS (
SELECT
parent_schema,
parent_table,
SUM(partition_size)/(1024*1024) as size_mb -- バイトを MB に変換
FROM (
SELECT
nmsp_parent.nspname AS parent_schema,
parent.relname AS parent_table,
pg_total_relation_size(child.oid) AS partition_size
FROM pg_inherits
JOIN pg_class parent ON pg_inherits.inhparent = parent.oid
JOIN pg_class child ON pg_inherits.inhrelid = child.oid
JOIN pg_namespace nmsp_parent ON nmsp_parent.oid = parent.relnamespace
JOIN pg_namespace nmsp_child ON nmsp_child.oid = child.relnamespace
WHERE parent.relkind = 'p'
) subquery
GROUP BY parent_schema, parent_table
)
UPDATE admin.table_mapping tm
SET SIZE_IN_MB = ps.size_mb
FROM partition_sizes ps
WHERE tm.OWNER = ps.parent_schema
AND tm.OBJECT_NAME = ps.parent_table ;
- 主キーが定義されているコントロールテーブルの
PK_PRESENT フィールドを更新します:
UPDATE admin.table_mapping
SET PK_PRESENT = CASE
WHEN EXISTS (
SELECT 1 FROM information_schema.table_constraints
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND constraint_type = 'PRIMARY KEY'
) THEN 'YES' ELSE 'NO' END ;
- ユニークキーが定義されているコントロールテーブルの
UK_PRESENT フィールドを更新します:
UPDATE admin.table_mapping
SET UK_PRESENT = CASE
WHEN EXISTS (
SELECT 1 FROM information_schema.table_constraints
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND constraint_type = 'UNIQUE'
) THEN 'YES' ELSE 'NO' END ;
- 少なくとも 1 つの LOB カラムを持つコントロールテーブルの
LOB_COLUMN フィールドを更新します:
UPDATE admin.table_mapping
SET LOB_COLUMN = (
SELECT COUNT(*)
FROM information_schema.columns
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND data_type IN ('bytea', 'text', 'json', 'jsonb')
);
3. 時間経過に伴う DML 変更量の把握
PostgreSQL データベースの pg_stat_user_tables システムビューには、最後に統計情報が収集されてから、データベース内のすべてのテーブルに対して行われた変更に関する情報が含まれています。PostgreSQL は pg_stat_user_tables を使用して、PostgreSQL 統計コレクターに基づくテーブルの DML と統計情報を収集します。最後の自動バキューム( autovacuum )のタイムスタンプは、タイミング情報を取得するために使用されます。定期的な ANALYZE 操作がテーブルに対して実行され、DML の変更に関する情報と最後の分析時間で pg_stat_user_tables を更新します。
毎日のデータを確認することで、テーブルに加えられた日々の変更についてのインサイトを得ることができます。この情報は、パフォーマンスに影響を与えたり、統計の収集や再編成などのメンテナンスタスクが必要になったりする可能性のある、多数の変更が加えられたテーブルを特定するのに役立ちます。
時間経過に伴う DML の変更量を把握するには:
pg_stat_user_tables から詳細を取得するために、MST_DBA_TAB_MOD というステージングテーブルを作成します:
CREATE TABLE admin.mst_dba_tab_mod (
DATA_DATE DATE,
TABLE_OWNER VARCHAR(128),
TABLE_NAME VARCHAR(128),
PARTITION_NAME VARCHAR(128),
SUBPARTITION_NAME VARCHAR(128),
INSERTS BIGINT,
UPDATES BIGINT,
DELETES BIGINT,
TIMESTAMP TIMESTAMP,
TRUNCATED VARCHAR(3),
TOTAL_DML BIGINT,
DROP_SEGMENTS BIGINT
);
- PostgreSQL の
pg_stat_user_tables システムビューから情報を収集し、テーブルの日次平均 DML カウントで MST_DBA_TAB_MOD テーブルを更新します。
カウントは最後に分析された日付から記録され、平均化されるため、最新のテーブル統計情報を持つことでカウントの精度が向上します。
INSERT INTO admin.mst_dba_tab_mod (
TABLE_OWNER,
TABLE_NAME,
INSERTS,
UPDATES,
DELETES,
TOTAL_DML,
TIMESTAMP
)
SELECT
schemaname AS TABLE_OWNER,
relname AS TABLE_NAME,
n_tup_ins AS INSERTS,
n_tup_upd AS UPDATES,
n_tup_del AS DELETES,
ROUND((n_tup_ins + n_tup_upd + n_tup_del)::numeric /
GREATEST(EXTRACT(EPOCH FROM (now() - last_autovacuum))::numeric / 86400, 1)) AS TOTAL_DML,
now() AS TIMESTAMP
FROM pg_stat_user_tables
WHERE schemaname = 'admin';
- 次に、前のステップで埋めた
MST_DBA_TAB_MOD からこの情報を収集する以下の UPDATE 文を実行して、コントロールテーブル table_mapping_mapping に DML 情報を入力します:
UPDATE admin.table_mapping a
SET TOTAL_DML = b.TOTAL_DML
FROM admin.mst_dba_tab_mod b
WHERE a.OWNER = b.TABLE_OWNER
AND a.OBJECT_NAME = b.TABLE_NAME
AND b.TABLE_OWNER = 'admin';
4. テーブルのステップ番号による分類
以下のコードに示すように、テーブルはデータ特性に関するさまざまな要因を基にデータベース内で分類されます。これらの要因には、テーブルがパーティション化されているかどうか、LOB を含むかどうか、テーブルサイズ、テーブルに対して実行された DML 操作の数などが含まれます。LOB フィールドを持たない非パーティション化テーブルはステップ 1 に分類され、LOB フィールドを持つ非パーティション化テーブルはステップ 2 に、LOB フィールドを持たないパーティション化テーブルはステップ 3 に分類され、以下同様に分類されます。例えば、SIZE_IN_MB が 0 と報告されるすべてのテーブルは、移行の対象外として分類されます。ユースケースに応じて、このステップに追加のテーブルを加えることができます。
これらの属性に基づくテーブルの分類は、最適化を目的として行われます。
UPDATE admin.table_mapping SET STEP = 1 WHERE LOB_COLUMN = 0 AND PARTITIONED = 'NO' AND STEP IS NULL ;
UPDATE admin.table_mapping SET STEP = 2 WHERE LOB_COLUMN > 0 AND PARTITIONED = 'NO' AND STEP IS NULL ;
UPDATE admin.table_mapping SET STEP = 3 WHERE LOB_COLUMN = 0 AND PARTITIONED = 'YES' AND STEP IS NULL ;
UPDATE admin.table_mapping SET STEP = 4 WHERE LOB_COLUMN > 0 AND PARTITIONED = 'YES' AND STEP IS NULL ;
UPDATE admin.table_mapping SET STEP = 5 WHERE TOTAL_DML > 9999999 ;
UPDATE admin.table_mapping SET STEP = 0 WHERE SIZE_IN_MB = 0 AND STEP IS NULL ;
5. データベーステーブルのグループ化
グループの推奨プロセスは、TABLE_MAPPING コントロールテーブルに格納された情報に基づいて TABLE_MAPPING_GROUPS テーブルを作成し、データを作成することから始まります。このプロセスは、3 つのパラメータを受け取るプロシージャによって開始されます。
- マッピングテーブル (
TABLE_MAPPING)
- ソースの移行スキーマ (
ADMIN)
- タスクごとのデータベースオブジェクトのサイズ (
600 GB)
タスクごとのデータベースオブジェクトのサイズ (600 GB) は、ソースおよびターゲットのレプリケーションインスタンスの CPU、ネットワーク、I/O 能力などの要因を考慮し、タスク間でテーブルを均等に分散するように選択されています。
シェルスクリプトを使用して admin.both ストアドプロシージャを呼び出し、テーブルをグループ化します。その後、プロシージャ内のセクションを使用して、パーティションテーブルと非パーティションテーブルの両方に対して step と groupnum を使用してグループ化されたテーブルをリストします。
CREATE OR REPLACE PROCEDURE admin.both (
IN p_n NUMERIC,
IN p_schema_name VARCHAR,
IN p_table_name VARCHAR
)
AS
$BODY$
DECLARE
vTab CHARACTER VARYING(30);
vDumpSize DOUBLE PRECISION := 0 ;
vSumBytes DOUBLE PRECISION := 0 ;
vGroupNum DOUBLE PRECISION := 0 ;
vPrevStep DOUBLE PRECISION := 1 ;
reggrouptabs RECORD ;
BEGIN
vDumpSize := 1024 * p_n ;
-- Dynamic SQL to truncate the table
EXECUTE format('TRUNCATE %I.%I_groups', p_schema_name, p_table_name);
-- Dynamic SQL to insert data
EXECUTE format('
INSERT INTO %I.%I_groups
SELECT owner, object_name, object_type, size_in_mb, step, ignore, partitioned
FROM %I.%I',
p_schema_name, p_table_name, p_schema_name, p_table_name);
FOR reggrouptabs IN
EXECUTE format('
SELECT *
FROM %I.%I_groups
ORDER BY step, size_in_mb',
p_schema_name, p_table_name)
LOOP
IF (reggrouptabs.step != vPrevStep) THEN
vGroupNum := 0 ;
vSumBytes := 0 ;
END IF ;
vSumBytes := vSumBytes + reggrouptabs.size_in_mb ;
IF (vSumBytes >= vDumpSize) THEN
vGroupNum := vGroupNum + 1 ;
vSumBytes := 0 ;
END IF ;
-- Dynamic SQL for UPDATE
EXECUTE format('
UPDATE %I.%I_groups
SET groupnum = $1
WHERE owner = $2 AND object_name = $3',
p_schema_name, p_table_name)
USING vGroupNum, reggrouptabs.owner, reggrouptabs.object_name ;
vPrevStep := reggrouptabs.step ;
END LOOP ;
COMMIT ;
END ;
$BODY$
LANGUAGE plpgsql ;
以下の select ステートメントを実行して、table_mapping_groups を繰り返し処理し、それぞれのグループ名ごとにテーブル名をリストすることで、最終的な plpgsql プロシージャの出力を収集できます。これは、対応する AWS DMS タスクを作成するために使用できます:
SELECT partitioned,step, groupnum, count(1) table_in_group,sum(size_in_mb) Total_group_size
FROM admin.table_mapping_groups
group by partitioned,step, groupnum
ORDER BY 1,2,3 ;
デモンストレーション
この投稿のソリューションを実証するために、6.2 TB のデータ転送用の PostgreSQL ソースインスタンスを使用し、DMS タスクごとに 600 GB のサイズ内でテーブルをグループ化します。構成には、8 コア、16 vCPU、64 GiB のメモリを備えた db.m5.4xlarge インスタンスを使用しています。CPU 使用率、ネットワークスループット、および運用負荷の評価に基づき、600 GB 単位でタスクを作成することが、このワークロードに最適であると判断されました。ただし、各ソースには固有の特性があるため、適切なクラスターサイズを決定するには、特定のソースデータベースの規模、ワークロード、CPU、メモリ、およびネットワーク使用率を徹底的に分析する必要があります。
このプロセスは、ループテーブルからステップ情報を降順に整理し、その後、定義されたサイズパラメータに従って整理されたデータをクラスタリングする方法を実装しています。
個々のステップを手動で実行する必要がないように、以下の手順をシェルスクリプトに統合しました。
- ソースの PostgreSQL データベースにコントロールテーブルを作成します。
- データディクショナリのテーブルとビューを使用して、テーブルサイズ、パーティション、インデックス、制約、データ型、LOB データを分析し、コントロールテーブルにデータを投入します。
- 受信する変更の量をモニタリングすることで、テーブルの日次による増加量を把握します。
- ステップ番号でテーブルを分類します。
以下のコードは、対応するシェルスクリプトです:
#!/bin/bash
# Collect database connection details
echo "Please enter database connection details:"
read -p "Database name [postgres]: " DB_NAME
DB_NAME=${DB_NAME:-postgres}
read -p "Database user [postgres]: " DB_USER
DB_USER=${DB_USER:-postgres}
read -p "Database host [localhost]: " DB_HOST
DB_HOST=${DB_HOST:-localhost}
read -p "Database port [5432]: " DB_PORT
DB_PORT=${DB_PORT:-5432}
read -s -p "Database password: " password
DB_PASSWORD=$password
# Export variables for psql to use
export PGPASSWORD="$DB_PASSWORD"
# Function to execute psql query and return result
execute_query() {
psql -U "$DB_USER" \
-h "$DB_HOST" \
-p "$DB_PORT" \
-d "$DB_NAME" \
-t -A \
-c "$1"
}
# Test connection
echo -e "\nTesting database connection..."
if ! execute_query "SELECT 1 ;" > /dev/null 2>&1 ; then
echo "Error: Could not connect to the database. Please check your credentials."
exit 1
fi
echo "Connection successful!"
# Example 1: Simple SELECT query
#echo -e "\nExample 1: List of users"
#users=$(execute_query "SELECT usename FROM pg_catalog.pg_user ;")
#echo "$users"
echo -e "\nCreating the control table"
table_ddl=$(execute_query "CREATE TABLE TABLE_MAPPING (
OWNER VARCHAR(30),
OBJECT_NAME VARCHAR(30),
OBJECT_TYPE VARCHAR(30),
SIZE_IN_MB NUMERIC(12,4),
STEP INTEGER,
IGNORE CHAR(3),
PARTITIONED CHAR(3),
PART_NUM INTEGER,
SPECIAL_HANDLING CHAR(3),
PK_PRESENT CHAR(3),
UK_PRESENT CHAR(3),
LOB_COLUMN INTEGER,
GROUPNUM INTEGER,
TOTAL_DML INTEGER
);")
echo "$table_ddl"
echo -e "\nCleaning up the old control table"
clean_ddl=$(execute_query "TRUNCATE TABLE admin.table_mapping ;")
echo "$clean_ddl"
echo -e "\nInsert into the control table the database table details "
table_insert=$(execute_query "INSERT INTO admin.table_mapping(OWNER, OBJECT_NAME, OBJECT_TYPE, SIZE_IN_MB, PART_NUM, PARTITIONED)
SELECT
schemaname,
tablename,
'TABLE',
pg_total_relation_size(schemaname || '.' || tablename) / 1024.0 / 1024.0,
CASE WHEN EXISTS (
SELECT 1 FROM pg_partitioned_table pt
JOIN pg_class c ON c.oid = pt.partrelid
WHERE c.relname = tablename
) THEN (
SELECT count(*) FROM pg_inherits
WHERE inhparent = (schemaname || '.' || tablename)::regclass
) ELSE 1 END,
CASE WHEN EXISTS (
SELECT 1 FROM pg_partitioned_table pt
JOIN pg_class c ON c.oid = pt.partrelid
WHERE c.relname = tablename
) THEN 'YES' ELSE 'NO' END
FROM pg_tables
WHERE schemaname = 'admin';")
echo "$table_insert"
echo -e "\nCleaning up child table data"
clean_dml=$(execute_query "DELETE FROM admin.table_mapping WHERE object_name IN (SELECT
child.relname AS child_table
FROM pg_inherits
JOIN pg_class parent ON pg_inherits.inhparent = parent.oid
JOIN pg_class child ON pg_inherits.inhrelid = child.oid
JOIN pg_namespace nmsp_parent ON nmsp_parent.oid = parent.relnamespace
JOIN pg_namespace nmsp_child ON nmsp_child.oid = child.relnamespace
WHERE parent.relkind = 'p' and nmsp_child.nspname ='admin') ;
;")
echo "$clean_dml"
echo -e "\nPopulate partition table size"
pop_part=$(execute_query "WITH partition_sizes AS (
SELECT
parent_schema,
parent_table,
SUM(partition_size)/(1024*1024) as size_mb -- Convert bytes to MB
FROM (
SELECT
nmsp_parent.nspname AS parent_schema,
parent.relname AS parent_table,
pg_total_relation_size(child.oid) AS partition_size
FROM pg_inherits
JOIN pg_class parent ON pg_inherits.inhparent = parent.oid
JOIN pg_class child ON pg_inherits.inhrelid = child.oid
JOIN pg_namespace nmsp_parent ON nmsp_parent.oid = parent.relnamespace
JOIN pg_namespace nmsp_child ON nmsp_child.oid = child.relnamespace
WHERE parent.relkind = 'p'
) subquery
GROUP BY parent_schema, parent_table
)
UPDATE admin.table_mapping tm
SET SIZE_IN_MB = ps.size_mb
FROM partition_sizes ps
WHERE tm.OWNER = ps.parent_schema
AND tm.OBJECT_NAME = ps.parent_table ;")
echo "$pop_part"
echo -e "\nUpdate the PK_PRESENT field of the control table"
pk_present=$(execute_query "UPDATE admin.table_mapping
SET PK_PRESENT = CASE
WHEN EXISTS (
SELECT 1 FROM information_schema.table_constraints
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND constraint_type = 'PRIMARY KEY'
) THEN 'YES' ELSE 'NO' END ;")
echo "$pk_present"
echo -e "\nUpdate the UK_PRESENT field of the control table "
uk_present=$(execute_query "UPDATE admin.table_mapping
SET UK_PRESENT = CASE
WHEN EXISTS (
SELECT 1 FROM information_schema.table_constraints
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND constraint_type = 'UNIQUE'
) THEN 'YES' ELSE 'NO' END ;")
echo "$uk_present"
echo -e "\nUpdate the LOB_COLUMN field of the control table "
lob_column=$(execute_query "UPDATE admin.table_mapping
SET LOB_COLUMN = (
SELECT COUNT(*)
FROM information_schema.columns
WHERE table_schema = OWNER
AND table_name = OBJECT_NAME
AND data_type IN ('bytea', 'text', 'json', 'jsonb')
);")
echo "$lob_column"
echo -e "\nCreate a staging table called MST_DBA_TAB_MOD to get the details from pg_stat_user_tables"
table_ddl=$(execute_query "CREATE TABLE admin.mst_dba_tab_mod (
DATA_DATE DATE,
TABLE_OWNER VARCHAR(128),
TABLE_NAME VARCHAR(128),
PARTITION_NAME VARCHAR(128),
SUBPARTITION_NAME VARCHAR(128),
INSERTS BIGINT,
UPDATES BIGINT,
DELETES BIGINT,
TIMESTAMP TIMESTAMP,
TRUNCATED VARCHAR(3),
TOTAL_DML BIGINT,
DROP_SEGMENTS BIGINT
);")
echo "$table_ddl"
echo -e "\nPopulate the MST_DBA_TAB_MOD table with the daily average DML count for the tables "
table_dml=$(execute_query "INSERT INTO admin.mst_dba_tab_mod (
TABLE_OWNER,
TABLE_NAME,
INSERTS,
UPDATES,
DELETES,
TOTAL_DML,
TIMESTAMP
)
SELECT
schemaname AS TABLE_OWNER,
relname AS TABLE_NAME,
n_tup_ins AS INSERTS,
n_tup_upd AS UPDATES,
n_tup_del AS DELETES,
ROUND((n_tup_ins + n_tup_upd + n_tup_del)::numeric /
GREATEST(EXTRACT(EPOCH FROM (now() - last_autovacuum))::numeric / 86400, 1)) AS TOTAL_DML,
now() AS TIMESTAMP
FROM pg_stat_user_tables
WHERE schemaname = 'admin';")
echo "$table_dml"
echo -e "\nPopulate the DML information in the control table_mapping_mapping table "
load_dml=$(execute_query "UPDATE admin.table_mapping a
SET TOTAL_DML = b.TOTAL_DML
FROM admin.mst_dba_tab_mod b
WHERE a.OWNER = b.TABLE_OWNER
AND a.OBJECT_NAME = b.TABLE_NAME
AND b.TABLE_OWNER = 'admin';
")
echo "$load_dml"
echo -e "\nCategorize the tables by step number"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 1 WHERE LOB_COLUMN = 0 AND PARTITIONED = 'NO' AND STEP IS NULL ;")
echo "$update_dml"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 2 WHERE LOB_COLUMN > 0 AND PARTITIONED = 'NO' AND STEP IS NULL ;")
echo "$update_dml"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 3 WHERE LOB_COLUMN = 0 AND PARTITIONED = 'YES' AND STEP IS NULL ;")
echo "$update_dml"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 4 WHERE LOB_COLUMN > 0 AND PARTITIONED = 'YES' AND STEP IS NULL ;")
echo "$update_dml"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 5 WHERE TOTAL_DML > 9999999 ;")
echo "$update_dml"
update_dml=$(execute_query "UPDATE admin.table_mapping SET STEP = 0 WHERE SIZE_IN_MB = 0 AND STEP IS NULL ;")
echo "$update_dml"
# Clear password from environment
unset PGPASSWORD
echo -e "\nScript execution completed"
以下はスクリプトを実行した結果で、簡単に参照できるように実行のさまざまなステップを示しています。
[ec2-user@ip-10-0-0-40 ~ ]$ ./pg_table_grouping.sh
Please enter database connection details:
Database name [postgres]:
Database user [postgres]:
Database host [localhost]: pg-dms-target.caub0zqkqtdt.us-east-1.rds.amazonaws.com
Database port [5432]:
Database password:
Testing database connection...
Connection successful!
Creating the control table
ERROR: relation "table_mapping" already exists
Cleaning up the old control table
TRUNCATE TABLE
Insert into the control table the database table details
INSERT 0 287
Cleaning up child table data
DELETE 192
Populate partition table size
UPDATE 19
Update the PK_PRESENT field of the control table
UPDATE 95
Update the UK_PRESENT field of the control table
UPDATE 95
Update the LOB_COLUMN field of the control table
UPDATE 95
Create a staging table called MST_DBA_TAB_MOD to get the details from pg_stat_user_tables
ERROR: relation "mst_dba_tab_mod" already exists
Populate the MST_DBA_TAB_MOD table with the daily average DML count for the tables
INSERT 0 287
Populate the DML information in the control table_mapping_mapping table
UPDATE 95
Categorize the tables by step number
UPDATE 56
UPDATE 20
UPDATE 6
UPDATE 13
UPDATE 0
UPDATE 0
Script execution completed
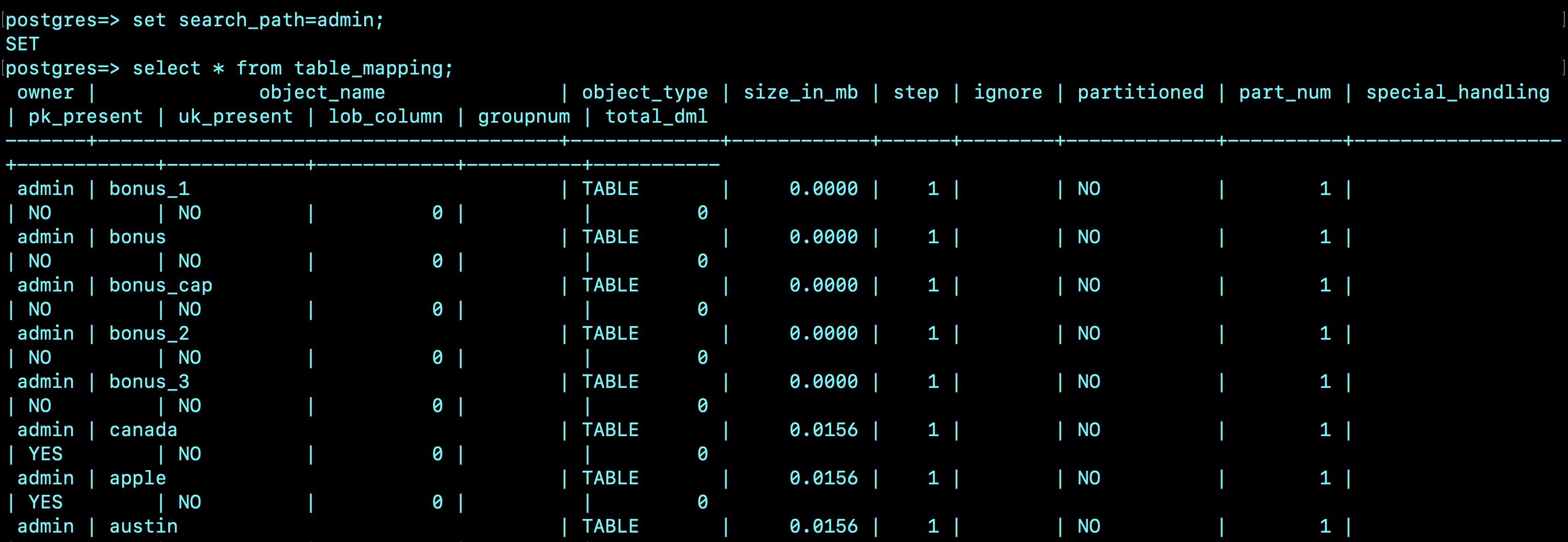
以下のコードは、コントロールテーブル table_mapping のスニペットです。このテーブルは、このセクションで先ほど示したシェルスクリプトを実行した後、データディクショナリから入力されます。
owner | object_name | object_type | size_in_mb | step | ignore | partitioned | part_num | special_handling
| pk_present | uk_present | lob_column | groupnum | total_dml
-------+----------------------------------------+-------------+------------+------+--------+-------------+----------+------------------
+------------+------------+------------+----------+-----------
admin | bonus_1 | TABLE | 0.0000 | 1 | | NO | 1 |
| NO | NO | 0 | | 0
admin | bonus | TABLE | 0.0000 | 1 | | NO | 1 |
| NO | NO | 0 | | 0
admin | bonus_cap | TABLE | 0.0000 | 1 | | NO | 1 |
| NO | NO | 0 | | 0
admin | bonus_2 | TABLE | 0.0000 | 1 | | NO | 1 |
| NO | NO | 0 | | 0
admin | bonus_3 | TABLE | 0.0000 | 1 | | NO | 1 |
| NO | NO | 0 | | 0
admin | canada | TABLE | 0.0156 | 1 | | NO | 1 |
| YES | NO | 0 | | 0
admin | apple | TABLE | 0.0156 | 1 | | NO | 1 |
| YES | NO | 0 | | 0
admin | austin | TABLE | 0.0156 | 1 | | NO | 1 |
| YES | NO | 0 | | 0
admin | dept_2 | TABLE | 0.0078 | 1 | | NO | 1 |
| YES | NO | 0 | | 0
admin | dept_1 | TABLE | 0.0078 | 1 | | NO | 1 |
| YES | NO | 0 | | 0
admin | dept_3 | TABLE | 0.0078 | 1 | | NO | 1 |
| YES | NO | 0 | | 0
admin | dept_cap | TABLE | 0.0078 | 1 | | NO | 1 |
| YES | NO | 0 | | 0
admin | dummy | TABLE | 0.0078 | 1 | | NO | 1 |
| NO | NO | 0 | | 0
admin | mango | TABLE | 0.0078 | 1 | | NO | 1 |
| YES | NO | 0 | | 0
admin | lob_col_info | TABLE | 0.0078 | 1 | | NO | 1 |
| NO | NO | 0 | | 0
admin | emp | TABLE | 0.0000 | 1 | | NO | 1 |
| NO | NO | 0 | | 0
admin | emp_1 | TABLE | 0.0078 | 1 | | NO | 1 |
| YES | NO | 0 | | 0
admin | emp_3 | TABLE | 0.0078 | 1 | | NO | 1 |
以下は、table_mappingを出力したスクリーンショットです。:
テーブルグループ化スクリプトを実行すると、最終的な出力は6つの初期ステップ番号、0 – 5 で構成されます:
- 0 は特別な処理を行うテーブルを無視またはスキップする場合
- 1 は LOB フィールドのない非パーティション化テーブルの場合
- 2 は LOB フィールドのある非パーティション化テーブルの場合
- 3 は LOB フィールドのないパーティション化テーブルの場合
- 4 は LOB フィールドのあるパーティション化テーブルの場合
- 5 は DML 操作が多いテーブルの場合
次に、テーブルグループ化シェルスクリプトを実行して、最終的なテーブルごとのグループを作成します。グループの一部であるテーブルは、単一の AWS DMS タスクに含まれます。このコードの詳細については、このブログ投稿の前のセクションを参照してください。
以下のシェルスクリプトは、テーブルの最終的なグループ化を作成します:
#!/bin/bash
# Collect database connection details
echo "Please enter database connection details:"
read -p "Database name [postgres]: " DB_NAME
DB_NAME=${DB_NAME:-postgres}
read -p "Database user [postgres]: " DB_USER
DB_USER=${DB_USER:-postgres}
read -p "Database host [localhost]: " DB_HOST
DB_HOST=${DB_HOST:-localhost}
read -p "Database port [5432]: " DB_PORT
DB_PORT=${DB_PORT:-5432}
read -s -p "Database password: " password
DB_PASSWORD=$password
# Export variables for psql to use
export PGPASSWORD="$DB_PASSWORD"
# Function to execute psql query and return result
execute_query() {
psql -U "$DB_USER" \
-h "$DB_HOST" \
-p "$DB_PORT" \
-d "$DB_NAME" \
-t -A \
-c "$1"
}
# Test connection
echo -e "\nTesting database connection..."
if ! execute_query "SELECT 1 ;" > /dev/null 2>&1 ; then
echo "Error: Could not connect to the database. Please check your credentials."
exit 1
fi
echo "Connection successful!"
# Step 1: Create the plpgsql procedure
echo -e "\nCreating plpgsql procedure..."
create_procedure_query=$(cat << EOF CREATE OR REPLACE PROCEDURE admin.both ( IN p_n NUMERIC, IN p_schema_name VARCHAR, IN p_table_name VARCHAR ) AS \$BODY\$ DECLARE vTab CHARACTER VARYING(30); vDumpSize DOUBLE PRECISION := 0 ; vSumBytes DOUBLE PRECISION := 0 ; vGroupNum DOUBLE PRECISION := 0 ; vPrevStep DOUBLE PRECISION := 1 ; reggrouptabs RECORD ; BEGIN vDumpSize := 1024 * p_n ; -- Dynamic SQL to truncate the table EXECUTE format('TRUNCATE %I.%I_groups', p_schema_name, p_table_name); -- Dynamic SQL to insert data EXECUTE format(' INSERT INTO %I.%I_groups SELECT owner, object_name, object_type, size_in_mb, step, ignore, partitioned FROM %I.%I', p_schema_name, p_table_name, p_schema_name, p_table_name); FOR reggrouptabs IN EXECUTE format(' SELECT * FROM %I.%I_groups ORDER BY step, size_in_mb', p_schema_name, p_table_name) LOOP IF (reggrouptabs.step != vPrevStep) THEN vGroupNum := 0 ; vSumBytes := 0 ; END IF ; vSumBytes := vSumBytes + reggrouptabs.size_in_mb ; IF (vSumBytes >= vDumpSize) THEN
vGroupNum := vGroupNum + 1 ;
vSumBytes := 0 ;
END IF ;
-- Dynamic SQL for UPDATE
EXECUTE format('
UPDATE %I.%I_groups
SET groupnum = \$1
WHERE owner = \$2 AND object_name = \$3',
p_schema_name, p_table_name)
USING vGroupNum, reggrouptabs.owner, reggrouptabs.object_name ;
vPrevStep := reggrouptabs.step ;
END LOOP ;
COMMIT ;
END ;
\$BODY\$
LANGUAGE plpgsql ;
EOF
)
execute_query "$create_procedure_query"
echo "Procedure created successfully!"
# Step 2: Execute the plpgsql procedure
echo -e "\nExecuting the procedure..."
read -p "Enter p_n value: " p_n
read -p "Enter p_schema_name: " p_schema_name
read -p "Enter p_table_name: " p_table_name
execute_procedure_query="CALL admin.both($p_n, '$p_schema_name', '$p_table_name');"
execute_query "$execute_procedure_query"
echo "Procedure executed successfully!"
# Step 3: Execute the SELECT query and display results
echo -e "\nExecuting SELECT query..."
select_query="
SELECT partitioned, step, groupnum as substep,
count(1) as table_in_group,
round(sum(size_in_mb)/1024, 2) as Total_size_GB
FROM admin.table_mapping_groups
GROUP BY partitioned, step, groupnum
ORDER BY 1,2,3 ;
"
echo "
*********************************************************
Tables are grouped based on ${p_n}GB size
*********************************************************
1(10,11,...) --> Non Partition Table.
2(20,21....) --> Non Partition Table(LOB)
3(30,31...) --> Partition Table.
4(40,41...) --> Partition Table(LOB).
5(50,51...) --> High DML Table.
0(0,99) --> Ignore or Skip/Special Handling table.
**********************************************************
"
# First display the traditional output
result=$(execute_query "$select_query")
echo -e "\nQuery Results:"
echo -e "partitioned\tstep\tsubstep\ttable_in_group\tTotal_size_GB"
echo "$result" | sed 's/|/\t/g'
# Now generate the formatted output
echo -e "\nDetailed Group Summary:"
formatted_query="
WITH grouped_data AS (
SELECT
concat(step, groupnum) as group_number,
count(1) as table_count,
round(sum(size_in_mb)/1024, 2) as size_gb,
CASE
WHEN step = 0 THEN ' comprising of ignored objects'
WHEN step = 1 THEN ' with no partitions'
WHEN step = 2 THEN ' with no partitions but containing lob fields'
WHEN step = 3 THEN ' with partitions'
WHEN step = 4 THEN ' with partitions and containing lob fields'
WHEN step = 5 THEN ' with high DML change'
ELSE ''
END as description
FROM admin.table_mapping_groups
GROUP BY step, groupnum
ORDER BY concat(step, groupnum)
)
SELECT format('Group number %s will have %s table%s with size of %s GB%s.',
group_number,
table_count,
CASE WHEN table_count = 1 THEN '' ELSE 's' END,
to_char(size_gb, 'FM999,999'),
description)
FROM grouped_data
WHERE group_number != '099';
"
execute_query "$formatted_query" | while read -r line ; do
echo "$line"
done
# Clear password from environment
unset PGPASSWORD
echo -e "\nScript execution completed"
この plpgsql プロシージャは、データテーブルの移行に関する最終的な推奨事項を生成します。これには、以下のステップを含む plpgsql ブロックの実行が含まれます:
- 既存の
table_mapping_groups という名前のテーブルを確認し、削除して新しいテーブルを作成します。
TABLE_MAPPING から新しい table_mapping_groups テーブルを作成します。- LOB 列と非 LOB 列を持つパーティション化されたテーブルを、600 GB のグループサイズに基づいてグループ化し、10、11、12、13 などのグループを作成します。
- 同様の手順で、LOB 列と非 LOB 列を持つ非パーティション化テーブルをグループ化します。
このプロセスでは、特別な処理が必要なテーブルを個別のグループに分けたり、特定の要件に基づいて移行から除外したりすることで対応します。ここで説明する移行プロセスはユニークであり、ケースの要件によって異なる場合があります。以下のコード例では、テーブルを ${groupsize} の 600 GB に基づいてグループ化しています:
[ec2-user@ip-10-0-0-40 ~ ]$ ./pg_both.sh
Please enter database connection details:
Database name [postgres]:
Database user [postgres]:
Database host [localhost]: pg-dms-target.caub0zqkqtdt.us-east-1.rds.amazonaws.com
Database port [5432]:
Database password:
Testing database connection...
Connection successful!
Creating plpgsql procedure...
CREATE PROCEDURE
Procedure created successfully!
Executing the procedure...
Enter p_n value: 600
Enter p_schema_name: admin
Enter p_table_name: table_mapping
CALL
Procedure executed successfully!
Executing SELECT query...
*********************************************************
Tables are grouped based on 600GB size
*********************************************************
1(10,11,...) --> Nonpartitioned table
2(20,21....) --> Nonpartitioned table(LOB)
3(30,31...) --> Partitioned table
4(40,41...) --> Partitioned table(LOB)
5(50,51...) --> High DML table
0(0,99) --> Ignore or skip/special handling table
**********************************************************
Query Results:
partitioned step substep table_in_group Total_size_GB
NO 0 0 2 0.00
NO 1 0 52 332.71
NO 1 1 2 837.89
NO 2 0 13 413.36
NO 2 1 2 467.77
NO 2 2 1 408.13
NO 2 3 1 648.07
NO 2 4 1 1440.51
NO 2 5 1 1620.33
NO 5 0 1 7.57
YES 3 0 6 0.62
YES 4 0 12 147.91
YES 5 0 1 28.99
Detailed Group Summary:
Group number 00 will have 2 tables with size of 0 GB comprising ignored objects.
Group number 10 will have 52 tables with size of 333 GB with no partitions.
Group number 11 will have 2 tables with size of 838 GB with no partitions.
Group number 20 will have 13 tables with size of 413 GB with no partitions but containing lob fields.
Group number 21 will have 2 tables with size of 468 GB with no partitions but containing lob fields.
Group number 22 will have 1 table with size of 408 GB with no partitions but containing lob fields.
Group number 23 will have 1 table with size of 648 GB with no partitions but containing lob fields.
Group number 24 will have 1 table with size of 1,441 GB with no partitions but containing lob fields.
Group number 25 will have 1 table with size of 1,620 GB with no partitions but containing lob fields.
Group number 30 will have 6 tables with size of 1 GB with partitions.
Group number 40 will have 12 tables with size of 148 GB with partitions and containing lob fields.
Group number 50 will have 2 tables with size of 37 GB with high DML change.
plpgsql プロシージャが異なるステップとグループ(substep) 毎にテーブルをグループ化したので、次に各グループに含まれるテーブルのリストを生成する必要があります。これは AWS DMS タスクを作成するために使用できます。最終的なグループ番号は、step と substep の 2 つの列を連結して生成されます。例えば、ステップ 1 とサブステップ 0 を組み合わせるとグループ番号 10 となり、52 個のテーブルと 340 GB のサイズを持ちます。
同様に、以下のグループも作成されます:
Group number 00 will have 2 tables with size of 0 GB comprising of ignored objects.
Group number 10 will have 52 tables with size of 333 GB with no partitions.
Group number 11 will have 2 tables with size of 838 GB with no partitions.
Group number 20 will have 13 tables with size of 413 GB with no partitions but containing lob fields.
Group number 21 will have 2 tables with size of 468 GB with no partitions but containing lob fields.
Group number 22 will have 1 table with size of 408 GB with no partitions but containing lob fields.
Group number 23 will have 1 table with size of 648 GB with no partitions but containing lob fields.
Group number 24 will have 1 table with size of 1,441 GB with no partitions but containing lob fields.
Group number 25 will have 1 table with size of 1,620 GB with no partitions but containing lob fields.
Group number 30 will have 6 tables with size of 1 GB with partitions.
Group number 40 will have 12 tables with size of 148 GB with partitions and containing lob fields.
前述の出力では、テーブルは可能な限り希望のグループサイズである 600 GB に近くなるようにグループ化されています。例えば、グループ 10 には 52 個のテーブルが含まれており、合計サイズは 333 GB です。838 GB のサイズの 2 つの巨大なテーブルは、単一のテーブルを分割しないように、グループ 11 として別の AWS DMS タスクに保持されています。テーブルの数とサイズに応じて、一部のグループは希望のグループサイズである 600 GB よりも小さくなったり大きくなったりします。したがって、データベースはパーティション、非パーティション LOB、および DML ボリュームに基づいてグループ化することで 11 のタスクを持つことになります。
次に、以下のスクリプトを使用して、異なるグループの下にあるテーブルをそれぞれのファイルに抽出します:
#!/bin/bash
# Collect database connection details
echo "Please enter database connection details:"
read -p "Database name [postgres]: " DB_NAME
DB_NAME=${DB_NAME:-postgres}
read -p "Database user [postgres]: " DB_USER
DB_USER=${DB_USER:-postgres}
read -p "Database host [localhost]: " DB_HOST
DB_HOST=${DB_HOST:-localhost}
read -p "Database port [5432]: " DB_PORT
DB_PORT=${DB_PORT:-5432}
read -p "Schema name for table_mapping_groups: " usr
usr=${usr:-admin}
read -s -p "Database password: " password
DB_PASSWORD=$password
# Export variables for psql to use
export PGPASSWORD="$DB_PASSWORD"
# Function to execute psql query and return result
execute_query() {
psql -U "$DB_USER" \
-h "$DB_HOST" \
-p "$DB_PORT" \
-d "$DB_NAME" \
-t -A \
-c "$1"
}
# Test connection
echo -e "\nTesting database connection..."
if ! execute_query "SELECT 1 ;" > /dev/null 2>&1 ; then
echo "Error: Could not connect to the database. Please check your credentials."
exit 1
fi
echo "Connection successful!"
# Generate parfile equivalent
echo "Generating step/group combinations..."
execute_query "SELECT DISTINCT concat(step, groupnum)
FROM ${usr}.table_mapping_groups
WHERE owner = '${usr}'
AND step IS NOT NULL" > parfile.lst
# Remove any existing files
rm -rf ADMIN_TAB*
# Process each combination
while IFS= read -r combination
do
echo "Generating table list for step and group ${combination}"
execute_query "
SELECT object_name
FROM ${usr}.table_mapping_groups
WHERE concat(step, groupnum) = '${combination}'
" > "${usr}_TAB_${combination}.lst"
done < parfile.lst
# Clear password from environment
unset PGPASSWORD
echo -e "\nScript execution completed"
スクリプトの実行後、テーブル名を含む以下のファイルが生成されます:
-rw-rw-r-- 1 ec2-user ec2-user 16 Jul 22 00:04 admin_TAB_21.lst
-rw-rw-r-- 1 ec2-user ec2-user 584 Jul 22 00:04 admin_TAB_10.lst
-rw-rw-r-- 1 ec2-user ec2-user 43 Jul 22 00:04 admin_TAB_11.lst
-rw-rw-r-- 1 ec2-user ec2-user 13 Jul 22 00:04 admin_TAB_00.lst
-rw-rw-r-- 1 ec2-user ec2-user 20 Jul 22 00:04 admin_TAB_50.lst
-rw-rw-r-- 1 ec2-user ec2-user 9 Jul 22 00:04 admin_TAB_24.lst
-rw-rw-r-- 1 ec2-user ec2-user 115 Jul 22 00:04 admin_TAB_30.lst
-rw-rw-r-- 1 ec2-user ec2-user 232 Jul 22 00:04 admin_TAB_40.lst
-rw-rw-r-- 1 ec2-user ec2-user 8 Jul 22 00:04 admin_TAB_23.lst
-rw-rw-r-- 1 ec2-user ec2-user 165 Jul 22 00:04 admin_TAB_20.lst
-rw-rw-r-- 1 ec2-user ec2-user 9 Jul 22 00:04 admin_TAB_25.lst
-rw-rw-r-- 1 ec2-user ec2-user 9 Jul 22 00:04 admin_TAB_22.lst
次のコードに示すように、同じファイルの一部であるテーブル名は、単一のタスクにグループ化する必要があります:
[ec2-user@ip-10-0-0-40 ~ ]$ cat admin_TAB_00.lst
canada
usail
[ec2-user@ip-10-0-0-40 ~ ]$ cat admin_TAB_22.lst
montreal
[ec2-user@ip-10-0-0-40 ~ ]$ cat admin_TAB_25.lst
edmonton
[ec2-user@ip-10-0-0-40 ~ ]$ cat admin_TAB_20.lst
print_media_hash_cap_a
d_storage
t
print_media_cap_dal
print_media
print_media_cap
tbl_clob
print_media_cap_a
document_storage
doc_storage
doc_store
storeage
quebec
クリーンアップ
このデモンストレーションの一環として、ソースの PostgreSQL データベースにいくつかのテーブルと 1 つのプロシージャを作成しました。タスクのグループ化が記録された後、以下の DROP ステートメントを使用して、これらのテーブルを削除し、プロシージャをドロップすることができます:
DROP TABLE TABLE_MAPPING ;
DROP PROCEDURE admin.both ;
DROP TABLE MST_DBA_TAB_MOD ;
DROP TABLE TABLE_MAPPING_GROUPS ;
まとめ
この投稿では、システムカタログと統計ビューを活用して、データベースの規模、運用負荷、ハードウェア構成を調査する方法について説明しました。これらの方法は、AWS DMS を使用した効果的なデータベース転送に必要なタスク数とテーブルクラスターの理想的な数を決定するのに役立ちます。データベースオブジェクト情報とソースデータベースのハードウェア仕様を統合することで、移行設計フェーズで十分な情報に基づいた選択を行うことができます。移行タスクを最適化するために、AWS Database Migration Service ユーザーガイドのベストプラクティスも併せて確認することをお勧めします。
著者について