Amazon Web Services ブログ
大容量テーブルの継続的レプリケーションを、AWS DMS の列フィルターによる並列化でパフォーマンス向上
本投稿は、Vanshika Nigam による記事 「Improve AWS DMS continuous replication performance by using column filters to parallelize high-volume tables」を翻訳したものです。
データベースの移行は難しく、特に、数十億件のエントリーを持つ巨大なテーブルで、頻繁に更新が行われる場合は尚更です。AWS Database Migration Service (AWS DMS) は、並列ロードやフィルタリング機能など、初期の一括データ転送プロセスを大幅に加速できる便利な機能を提供しています。
しかし、ソースデータベースで急速かつ継続的な変更が行われる高頻度の変更データキャプチャ (CDC) シナリオでは、特定の課題が残っています。
このようなシナリオでは、ターゲットデータベースは次のような課題に頻繁に直面します。
- 高レイテンシー – CDC プロセスが変更のペースに追いつけない可能性があります。大量の継続的な変更により、ソースとターゲットのデータベース間で大幅な遅延が生じ、CDC のパフォーマンスに影響を与える可能性があります。
- データ損失のリスク – Oracle などのデータベースでは、AWS DMS が処理する前に、redo ログやアーカイブログが消去される可能性があり、データ損失につながる恐れがあります。
- 保持期間の制限 – ストレージの制約や組織のポリシーにより、保持期間を延長することが常に可能というわけではありません。
- リソースの負荷 – 高頻度の CDC により、ターゲットデータベースと AWS DMS レプリケーションインスタンスの両方に負荷がかかり、レイテンシーの増加、スループットの低下、リソース消費の増加につながる可能性があります。
これらの課題に対処するには、通常、適切なサイズのレプリケーションインスタンスを選択する、タスクの並列化、AWS DMS のバッチ適用機能を使用する、AWS DMS タスク設定を最適化する、効率的なフィルタリング、そして時には独自のソリューションなど、多面的なアプローチが必要になります。
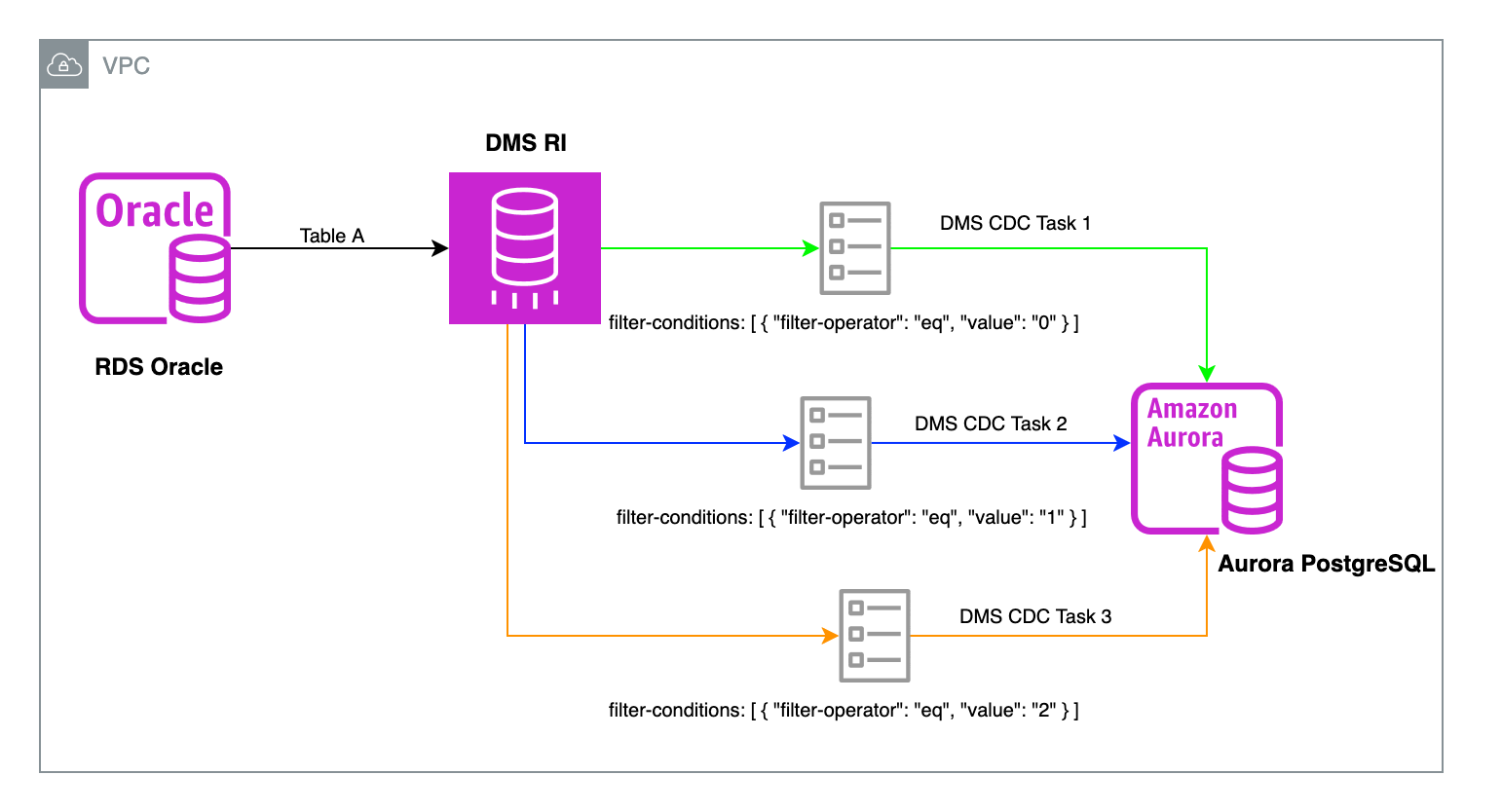
リレーショナルデータベースのターゲットでは、フルロード並列設定とは異なり、パフォーマンス向上のための並列 CDC スレッドを使用するオプションはありません。各タスクは単一のスレッドを使用します。AWS DMS の CDC を含むタスクが数百万の変更イベントを適用する必要がある場合は、論理的に独立したテーブルグループに対して複数の CDC タスクを使用することをお勧めします。これにより、複数の CDC スレッドを使用できます。さらに、適切なカラムフィルターを使用して、大規模なテーブルを複数の CDC タスクに分割することもできます。
この投稿では、CDC フェーズでアクティビティの多いテーブルを複数のタスクに分割するために列フィルターを使用する方法について説明します。
この手法により、移行プロセスを加速し、ターゲットのレイテンシーを削減できます。
ソリューションの概要
AWS DMS のタスクは移行プロセスの中心となるものです。テーブルマッピングを通じて、移行対象の特定のテーブル、ビュー、スキーマを定義します。
このマッピングには、フィルタリング機能があり、WHERE句を適用することで、行数を制限したり、大きなテーブルを管理可能な小さなセグメントに分割することができます。
この機能は従来、フルロード操作に適用されてきましたが、このソリューションでは、CDC タスクの最適化における可能性を探ります。
この投稿では、Oracle から PostgreSQL への移行にこのソリューションを実装します。
同じアプローチを他のリレーショナルデータベース間の移行にも適用できます。
このソリューションを実装する手順は次のとおりです。
- Oracle データベースにサンプルテーブルを作成し (この投稿では、Amazon RDS for Oracle を使用)、代表的なデータを入力します。
- データベースとテーブルレベルでサプリメンタルロギングを確認して有効化します。
- 行をタスク間で均等に分散するのに適した不変カラムを特定します。不変カラムの詳細については、次のセクションを参照してください。そのような列が存在しない場合は、次の手順を実行します。そうでない場合は、ステップ 4 に進んでください。
- 一時的な不変カラムを NUMBER(1) データ型で追加します。
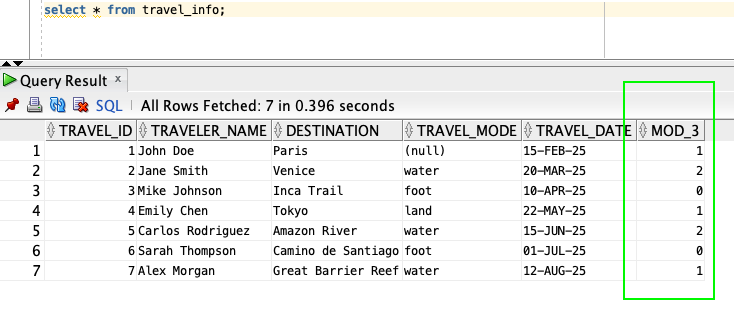
- 既存のデータについては、主キーに対する剰余演算を使用して、新しく作成した不変カラムに値を入力します。この投稿では、 3 で割った剰余を使用する例を示します。この操作により、データが 3 つの異なるグループに効果的に分割され、各グループは主キーを 3 で割った剰余で識別されます。
- 新しい不変カラムに対してサプリメンタルロギングを有効化します。
- 新規挿入時に自動的に剰余列を入力するトリガーを作成します。
- 剰余演算の結果に基づいて、列フィルターを使用して複数の AWS DMS タスクを作成します。これらは、要件に応じて、フルロードと CDC タスクまたは CDC のみのタスクのいずれかになります。この投稿では、3 で割った剰余に合わせて CDC のみの 3 つのタスクを作成します。
- 移行中にターゲットで一時的な不変カラムを除外するために、AWS DMS タスクに除外列フィルターを追加することを忘れないでください。
- 選択したターゲットデータベース (この投稿では、Amazon Aurora PostgreSQL 互換エディションをデータベースとして使用) に移行したデータを検証します。
- Amazon CloudWatch を使用して AWS DMS タスクのパフォーマンスを監視します。
次の図は、このソリューションのアーキテクチャを示しています。
データベースのイミュータブルカラムの特定方法
イミュータブルカラムとは、一度設定された値を変更できないカラムのことです。ミュータブルカラムとは、初期挿入後に値を変更できるカラムのことです。
主キーは不変ですが、各行に固有のものです。しかし、私たちの焦点は、複数の行で同じ値を持つ可能性のある不変のカラムを特定することです。これにより、データの分割が均等になり、AWS DMS タスク間で負荷が可能な限り均等に分散されます。例としては、作成タイムスタンプ、カテゴリコード、エリアコード、部門識別子などが挙げられます。このようなカラムを使用することで、データをより均等に分割でき、効率的なレプリケーションと、データ整合性の維持が可能になります。
重要なのは、多数のレコードに関連しながらも一定の値を保つカラムを特定し、それをパーティション分割の基準として使うことで、データの均等な分布を実現することです。
前提条件
始めるには、次の前提条件を満たす必要があります。
- アクティブな AWS アカウント。
- Oracle インスタンス (この投稿では Amazon RDS for Oracle を使用) または、オンプレミスの Oracle Database。
- Aurora PostgreSQL または RDS for PostgreSQL データベース (この投稿では Aurora PostgreSQL 互換を使用)。まだ Aurora PostgreSQL クラスターを持っていない場合、作成します。手順については、Amazon Aurora DB クラスターの作成を参照してください。
- ソースとターゲットの両方のデータベースにアクセスできる レプリケーションインスタンス。詳細については、AWS Database Migration Service の概要を参照してください。
ソースでサンプルテーブルの構築
この記事では、RDS for Oracle のデータベースを使用して、次の DDL で TRAVEL_INFO という名前のサンプルテーブルを作成します。
- テーブル
TRAVEL_INFOを作成します: TRAVEL_INFOテーブルに代表的なデータを挿入します:
ソース Oracle データベースのセットアップ
次の手順に従って、ソースの Oracle データベースをセットアップしてください。
- AWS DMS では、データベースレベルのサプリメンタルロギングを有効にする必要があります。次のクエリを実行して、データベースレベルのサプリメンタルロギングを確認してください。
- 最小限のサプリメンタルロギング (supplemental_log_data_min) が
NOの場合は、次のクエリを実行して有効にしてください。 - CDC でレプリケーションされるスキーマのテーブルについて、テーブルレベルのサプリメンタルロギングが有効になっているかを確認してください。
- プライマリキーを持つテーブルについては、次のクエリを実行するか、後述の AWS DMS エンドポイント設定で追加の接続属性を追加して、サプリメンタルロギングを有効にしてください。
- この例で使用するテーブルには不変カラムがありません。そのため、AWS DMS タスクで WHERE 句を使用するための一時的な不変カラムを追加します。
- この新しい列にプライマリキーの剰余演算の結果を設定するため、テーブルを更新します。
- 新しい列に値が正しく設定されたことを確認するため、テーブルを問い合わせます。
- この新しい列にサプリメンタルロギングを追加します。サプリメンタルロギングが有効になっていない場合、AWS DMS タスクは失敗します。
- 新しい行が挿入されるたびに剰余演算の列を設定するトリガーを作成します。
サンプルテーブルのターゲットへの構築
この投稿では、travel_id カラムの Oracle データ型 NUMBER を PostgreSQL のデータ型 INTEGER にマッピングしました。これは、ターゲットで正しい精度を維持するためです。Oracle の NUMBER カラムから PostgreSQL の理想的なデータ型カラムへの正確なデータ型マッピングを行うには、Oracle の NUMBER データ型を PostgreSQL に変換するを参照してください。
ターゲットでテーブル構造を作成するには、次のクエリを実行します。ソースで作成した mod_3 カラムは含まれていないことに注意してください。
ターゲットにテーブルが存在しない場合、AWS DMS は AWS DMS タスクで選択されたテーブル準備モードに関係なく、ターゲットにテーブルを作成します。この場合、DMS が余分な不要カラム (mod_3 カラムなど) を含むテーブルを作成してしまうことに注意が必要です。
AWS DMS を使用したデータ移行
このセクションでは、データを移行する手順を説明します。
AWS DMS エンドポイントの作成
ソースとターゲットのデータベースに対して AWS DMS エンドポイントを作成します。AWS DMS エンドポイントは、データストアへの接続情報、データストアの種類、場所を提供します。
Oracle ソースエンドポイントを作成する手順については、AWS DMS での Oracle データベースのソース利用を参照してください。
デフォルトの接続設定に加えて、オプションで AddSupplementalLogging=true エンドポイント設定を追加すると、この投稿の前半で説明したクエリを実行してサプリメンタルロギングを明示的に追加していない場合に、AWS DMS が Oracle データベースにテーブルレベルのサプリメンタルロギングを設定します。
PostgreSQL ターゲットエンドポイントを作成する手順については、AWS Database Migration Service のターゲットとして PostgreSQL データベースを使用するを参照してください。
AWS DMS タスクの作成
最初に RDS for Oracle から Aurora PostgreSQL 互換データベースへの別個のフルロードタスクを使用して、初期データ移行を実行したことに注意してください。フルロードが完了した後、このブログの ソース Oracle データベースのセットアップ セクションで説明されているように、フィルタリングに使用する新しい列をソースに追加しました。
次のステップとして、フィルターとしてmod_3を使用してテーブルを 3 つのタスクに分割します。以下の JSON は、AWS DMS タスクのマッピングルールの例を示しています。剰余列をターゲットから除外するために、remove-columnフィルターを追加することを忘れずに、3 つの別々の CDC タスクを作成してください。
レプリケーションタスクには、次の設定を使用してください:
- タスク識別子には、識別可能な名前を入力してください。
- ソースデータベースエンドポイントでは、作成した Oracle エンドポイントを選択してください。
- ターゲットデータベースエンドポイントでは、作成した Aurora PostgreSQL エンドポイントを選択してください。
- タスクモードでは、[プロビジョンド] を選択してください。
- レプリケーションインスタンスでは、作成したプロビジョンドインスタンスを選択してください。
- レプリケーションタイプを [複製のみ] に設定してください。
- ターゲットテーブル準備モードを [何もしない] に設定してください。
- タスク設定の下で[CloudWatch ログをオンにする] を有効にすると、問題をデバッグすることができます。
- テーブルマッピングでは、編集モードで JSON エディタ を選択してください。
- DMS タスクのマッピングルールには、次の JSON を使用してください。スキーマ名は、テーブルが作成されたスキーマ名に置き換えてください。
- 移行前評価チェックボックスをオフにしてください。
- 移行タスクのスタートアップ設定では、[後で手動で行う] を選択してください。
- 他の設定はデフォルトのままにして、[タスクを作成] を選択してください。
- 同じ設定で他の 2 つのタスク を作成してください。各タスクで、
mod_3カラムのfilter-conditions値を 0、1、2 に置き換えることを忘れずに行ってください。 - 3 つのタスクを同時に実行してください。
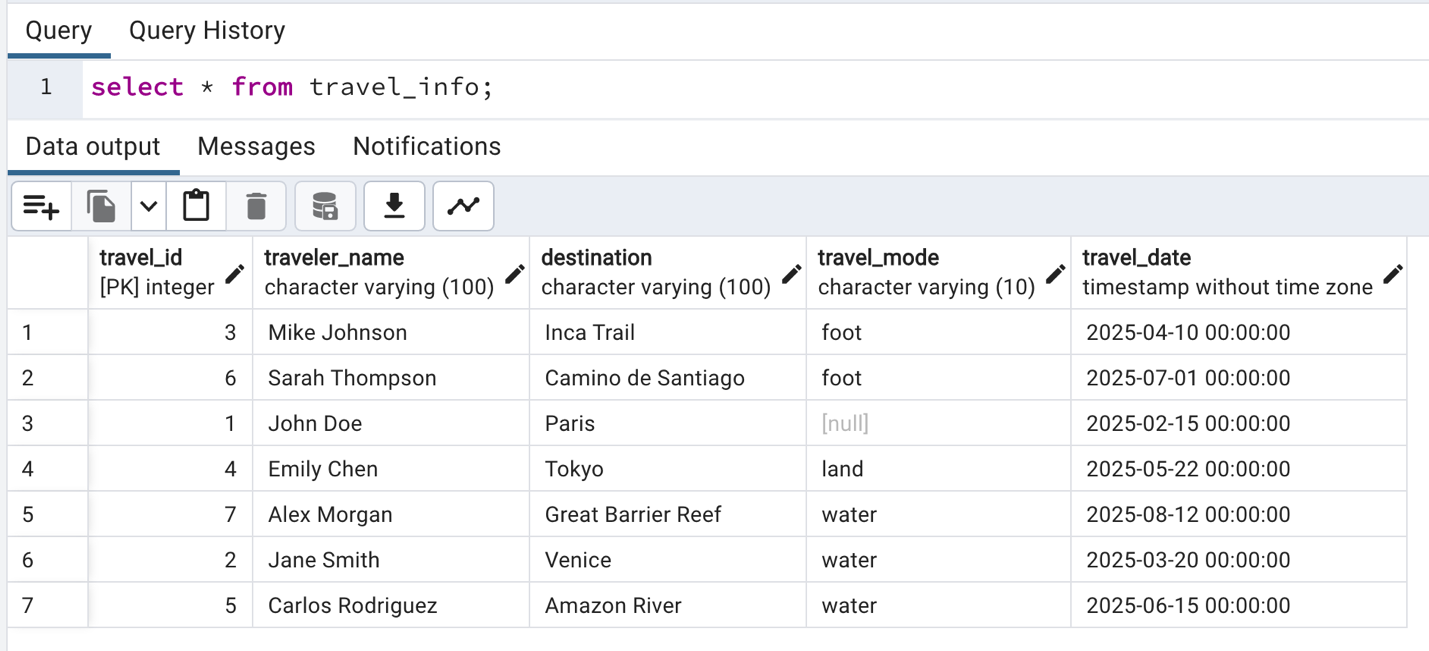
- Aurora PostgreSQL に移行されたデータを select クエリを実行して確認してください。
- ソースデータベースで DML 操作を実行し、これらの変更がターゲットテーブルにどのように反映されるか、そして DMS タスクが剰余フィルターに対応する行をどのようにピックアップするかを監視してください。
個々のタスクは自身のトランザクションの順序性を維持していますが、3 つのタスク全体でのトランザクションの順序が必ずしも保たれるわけではないことに注意が必要です。この順序の不整合は、タスクの開始と実行が独立していることに起因します。したがって、ターゲットテーブルに現れるトランザクションの最終的な順序は、同じソーステーブルに関係するものであっても、各 CDC のみタスクの開始タイミングの影響を受ける可能性があります。
Oracle から移行する際は、Oracle マテリアライズドビューを活用して、選択したカラムに基づいてフィルタリングされたマテリアライズドビューを作成し、必要なデータサブセットのみを PostgreSQL に移行することができます。データ変換には便利ですが、マテリアライズドビューではソース側で更新のオーバーヘッドが発生し、移行のパフォーマンスに影響を与える可能性があります。
可変カラムを使用してテーブルを分割した場合の観察
既存の travel_mode カラムを AWS DMS タスクのフィルターとして使用する代わりに、テーブルに不変カラムを導入するとします。この場合でも、陸路、空路、水路の移動手段に対応する 3 つの CDC タスクを作成することになります。
このシナリオをテストするには、travel_mode 列のサプリメンタルロギングを有効にする必要があります。これは、次の SQL コマンドを使用して行えます。
タスクをセットアップした後、タスクを開始し、ソースでフィルターに使用されているカラムを更新してみてください。
AWS DMS がこの変更を検出できないことがわかります。その結果、更新がターゲットデータベース (この場合は Aurora PostgreSQL 互換) に伝播されません。このカラムの更新は頻繁ではないかもしれませんが、発生した更新はすべて見落とされます。この動作は予期されたものですが、データの不整合につながる可能性があります。
したがって、効果的なデータレプリケーションを行うには、作成後に変更されない不変な列にフィルターを適用することが重要です。
パフォーマンス比較
この投稿では、ビジーなテーブルに対する大量の CDC シナリオにおける AWS DMS のパフォーマンスを評価します。AWS DMS は、Oracle をソースとする CDC 操作中のRedo ログの読み取りに、Oracle LogMiner と AWS DMS Binary Reader の 2 つのアプローチを提供しています。この実験では、LogMiner (オンラインおよびアーカイブされた Redo ログファイルを読み取るために設計された Oracle API) を使用することにしました。このソリューションは Binary Reader とも互換性があります。テストプロセスは 2 つの異なるフェーズに分かれていました。最初に単一の CDC タスクを評価し、次にカラムフィルターを使用して複数の CDC タスクに分割しました。
次のインフラストラクチャを使用しました。
- ソース: RDS for Oracle インスタンス
- インスタンスクラス: db.r6i.xlarge
- ストレージ: 50 GB (3000 IOPS の gp3)
- Oracle バージョン: 19 (19.0.0.0.ru-2024-10.rur-2024-10.r1)
- ターゲット: Aurora PostgreSQL 互換エディション
- インスタンスクラス: db.r6i.xlarge
- Aurora PostgreSQL 互換エディションのバージョン: 16.1
- AWS DMS レプリケーションインスタンス
- インスタンスクラス: dms.c5.xlarge
- 割り当てられたストレージ: 50 GB
- エンジンバージョン: 3.5.4
50 カラムと 20 インデックスを持つサンプルテーブルを作成しました。このテーブルには、ソースとターゲットの両側で最初に 50,000 行のデータが格納されました。次に、進行中の変更を複製するための単一の CDC のみのタスクを設定しました。負荷の高い本番環境をシミュレートするために、一連の DML 操作を実行しました。100 万件の新規レコードを挿入し、同時に 10 万件の既存レコードを更新し、その後 10 万件の更新スクリプトを 2 回実行し、最後にランダムに選択された 10,000 件のレコードに対して CDC トラフィックを生成しました。このテストにより、テーブルに急激で大規模な変更が加えられるシナリオを模倣することができました。この一連のプロセスにより、1 時間の期間で約 5GB のアーカイブログが生成されました。ソースデータベースでの変更率が高いため、このプロセスには時間がかかる可能性があります。AWS DMS がソースデータベースから大量のワークロードを受信すると、CDC ターゲットレイテンシーメトリクスが急上昇することがあります。私たちのテストシナリオでは、激しい活動期間中に CDC の待ち時間がピーク時で約 600 秒に達していることが、次のスクリーンショットに示されています。
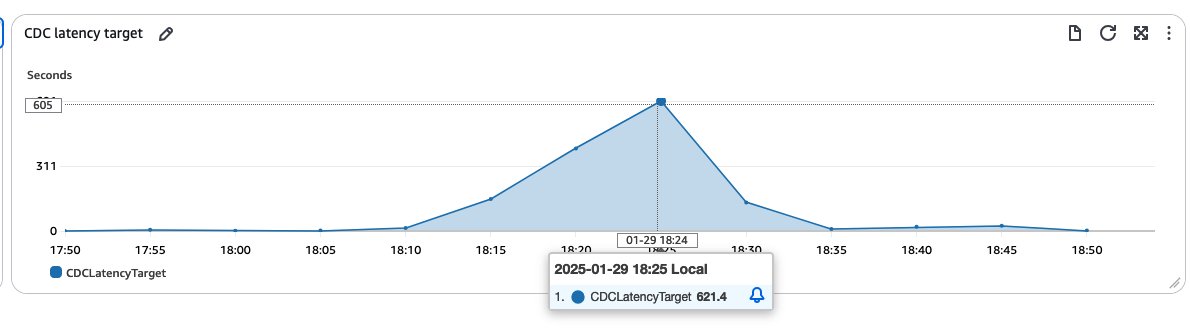
この最初のテストでは、単一の CDC タスクを使用する場合の、高ボリューム、高頻度変更シナリオにおけるパフォーマンスへの影響の可能性が浮き彫りになりました。これにより、カラムフィルターを使ってタスクを分割し、ワークロードを分散してレイテンシーを低減することを目的とした後続の実験の舞台が整いました。次のグラフは、単一の CDC タスクと同じワークロードを 3 つの CDC のみタスクに分割した場合のターゲットレイテンシーを示しています。
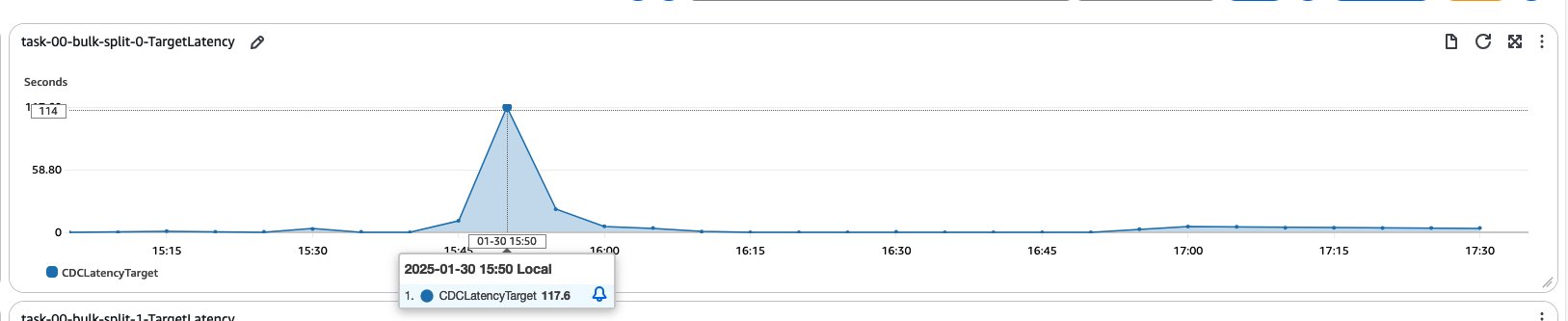

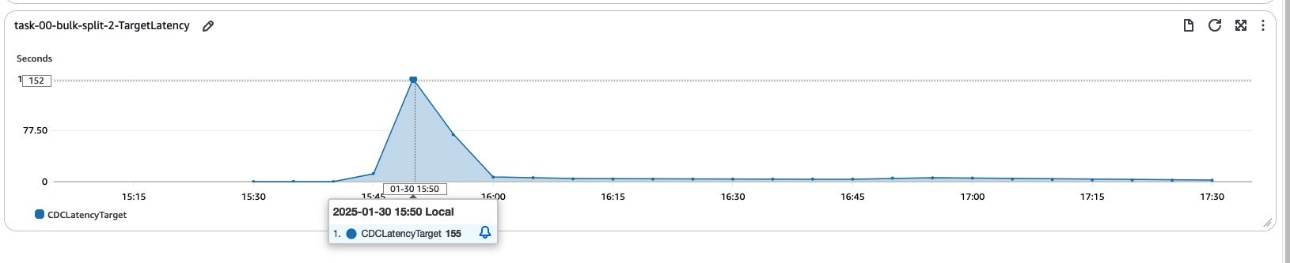
結果は、ターゲットでのレイテンシが低減されたことを示しています。この改善は、移行プロセスが高速化したことを示しています。従来の CDC は単一スレッド操作でしたが、今回は CDC フェーズで複数のスレッドを作成し、ソースからターゲットへのデータ移行を行えるようになったためです。
実験で使用したデータ量は実際のシナリオを代表するものではないかもしれませんが、CDC 操作でカラムフィルターを使用することのメリットを効果的に示しています。
具体的には、移行プロセスを加速できることを示しており、これは大量のデータ移行には不可欠です。
考慮事項
このアプローチを実装する際には、次の重要な点に留意する必要があります。
- 新しいカラムを追加するオーバーヘッド – 既存のテーブル構造に適切な不変カラムが見つからない場合、この目的のために新しいカラムを追加すると、いくらかのオーバーヘッドが発生する可能性があります。この変更はデータベーススキーマに影響を与え、特にコードが全テーブルをフェッチする場合は、アプリケーションロジックの変更が必要になる可能性があります。クエリでこの新しいカラムのフィルタリングを実装する必要があり、クライアントアプリケーションに影響を与える可能性があります。進める場合は、運用への影響を最小限に抑えるため、指定のメンテナンスウィンドウ中にこれらの変更をスケジュールしてください。
- ソースレイテンシーの潜在的な増加 – 同時スレッド数が増えると、ソースレイテンシーの増加が観測される可能性があります。これは、複数の並列読み取り操作によってソースシステムに追加の負荷がかかるためです。
- レプリケーションインスタンスの適切なサイジング – AWS DMS レプリケーションインスタンスが、インスタンスクラスとストレージ容量の点で適切にサイズ設定されていることを確認してください。各タスクは、ソースデータベースからすべての REDO ログを読み取り、適用できるまでそれらを格納する必要があるため、十分なリソースが不可欠です。
- バランスの取れた負荷分散 – タスク分割のためのカラムを選択する際は、作成するタスク間で作業負荷をできるだけ均等に分散するものを選んでください。この均等な分散は、CDC フェーズ中の並列処理による効率化の利点を最大限に活かすための鍵となります。
これらの点を慎重に検討することで、大規模な移行シナリオに対しても、潜在的な問題や予期しない副作用を最小限に抑えるような最適な AWS DMS を構築することができます。
クリーンアップ
この設計で作成したリソースで不要になったものは、料金が発生しないように削除してください:
- Aurora PostgreSQL クラスターを削除します。
- RDS for Oracle データベースを削除します。
- AWS DMS レプリケーションインスタンス、ソースとターゲットのエンドポイント、タスクを削除します。
- この実験を既存のデータベースで実施し、運用を続ける予定の場合は、実験が完了したら、ソースとターゲットの両方のデータベースからテストテーブルを明示的に削除してください。
結論
この投稿では、不変のカラムに基づいて複数の CDC タスクにワークロードを分散し、DMS カラムフィルターを使用して大規模で頻繁に使用されるアクティブテーブルを移行する方法を示しました。
この手法を活用することで、データの整合性を維持しながら移行時間を短縮できることを示しました。
この戦略は、フルロードと CDC プロセスの両方を最適化するため、同様の制約に直面する様々な大規模移行に適用できます。
AWS DMS とその機能の詳細については、AWS DMS ドキュメントを参照してください。AWS DMS フルロード移行のパフォーマンスを改善するためのベストプラクティスについては、並列読み込みとフィルターオプションを使用して AWS DMS によるデータベース移行を高速化するを参照してください。