Amazon Web Services ブログ
AWS Clean Rooms が ML モデルトレーニング用のプライバシーを強化する合成データセットの生成を開始します
2025 年 11 月 30 日、AWS Clean Rooms 向けのプライバシーを強化する合成データセットの生成を発表しました。これは、組織とそのパートナーが収集データからプライバシーを強化する合成データセットを生成し、回帰および分類機械学習(ML)モデルをトレーニングするために使用できる新機能です。この機能を使用すると、モデルが元のレコードにアクセスしなくても、元のデータの統計的パターンを保持する合成トレーニングデータセットを生成できます。これにより、以前はプライバシー上の懸念から不可能だったモデルトレーニングの新しい機会が生まれます。
ML モデルを構築する際、データサイエンティストやアナリストは通常、データユーティリティとプライバシー保護の間に生じる基本的な問題に直面します。傾向を認識し、エクスペリエンスをパーソナライズし、ビジネス成果を促進できる正確なモデルをトレーニングするには、高品質で詳細なデータへのアクセスが不可欠です。ただし、複数の関係者からのユーザーレベルのイベントデータといった詳細なデータを使用すると、プライバシーに関する重大な懸念やコンプライアンス上の課題が生じます。組織は、「どのような特徴が顧客のコンバージョン率の高さを示しているのか」などの質問に答えたいと考えています。しかし、個人レベルのシグナルに基づくトレーニングは、プライバシーポリシーや規制要件と衝突することがよくあります。
カスタム ML のプライバシーを強化する合成データセット生成
この課題に対処するために、AWS Clean Rooms ML のプライバシーを強化する合成データセットの生成を導入します。組織はこれを使用して、ML モデルトレーニングで安全に使用できる機密データセットの合成バージョンを作成できます。この機能では、高度な機械学習技術を使用し、元のデータの統計的特性を維持しながらも、元のソースデータから被験者の識別が不可能な新しいデータセットを生成します。
マスキングなどの従来の匿名化手法では、依然としてデータセット内の個人が再識別されるリスクが伴います。郵便番号や生年月日などの個人に関する属性を知っているだけでも、国勢調査データによって個人を識別できます。プライバシーを強化する合成データセット生成では、根本的に異なるアプローチを通じてこのリスクに対処します。システムは、元のデータセットの基本的な統計パターンを学習するモデルをトレーニングし、次に元のデータセットからサンプリングされた値とそのモデルを使用して合成レコードを生成して予測値列を予測します。このシステムでは単に元のデータをコピーしたり混乱させたりするのではなく、モデルキャパシティ削減手法を使用して、モデルが個人に関する情報をトレーニングデータに記憶するリスクを軽減します。生成された合成データセットは、元のデータと同じスキーマと統計的特性を備えているため、分類モデルや回帰モデルのトレーニングに適しています。このアプローチにより、再識別のリスクを定量的に減少させます。
この機能を使用する組織は、適用されるノイズの量や、トレーニングセットが特定の個人のデータが含むかどうかを判断しようとする攻撃者からのメンバーシップ推論攻撃に対する保護レベルなど、プライバシーパラメータを制御できます。AWS Clean Rooms は、合成データセットを生成した後、元のデータへの忠実性とプライバシー保護という 2 つの重要な側面に関し、お客様とそのコンプライアンスチームが合成データセットの品質を理解するのに役立つ詳細なメトリクスを提供します。忠実度スコアは KL-Divergence を使用して合成データが元のデータセットとどの程度類似しているかを測定し、プライバシースコアはデータセットがメンバーシップ推論攻撃からどの程度保護されているかを定量化します。
AWS Clean Rooms での合成データの使用
プライバシーを強化する合成データセットの生成を始めるには、確立された AWS Clean Rooms ML カスタムモデルワークフローに従い、プライバシー要件を指定して品質メトリックスを確認するための新しい手順を実行します。組織はまず、好みのデータソースを使用して分析ルールが設定されたテーブルを作成し、次にパートナーとコラボレーションに参加またはコラボレーションを作成して、テーブルをそのコラボレーションに関連付けます。
この新機能では、データ所有者がデータセットを作成する SQL クエリを定義するだけでなく、データセットの合成の必要性を指定する分析テンプレートが強化されました。このテンプレートでは、組織は列を分類して、ML モデルが予測する列と、カテゴリ値と数値を含む列を示します。重要なのは、テンプレートには、生成された合成データをトレーニングに利用できるようにするための基準となるプライバシーのしきい値も含まれていることです。これらには、再識別から保護するために合成データにどれだけのノイズが含まれうるかを指定するイプシロン値や、メンバーシップ推論攻撃に対する最低保護スコアが含まれます。これらのしきい値を適切に設定するには、組織固有のプライバシーとコンプライアンス要件を理解する必要があります。よってこのプロセスでは、法務チームやコンプライアンスチームと連携することをお勧めします。
すべてのデータ所有者が分析テンプレートを確認して承認した後、コラボレーションメンバーはテンプレートを参照する機械学習入力チャネルを作成します。その後、AWS Clean Rooms は合成データセットの生成プロセスを開始します。データセットのサイズと複雑さにもよりますが、通常は数時間以内に完了します。生成された合成データセットが分析テンプレートで定義されている必要なプライバシー閾値を満たしている場合、詳細な品質指標と併せて合成機械学習入力チャネルが利用可能になります。データサイエンティストは、シミュレートされたメンバーシップ推論攻撃に対して達成された実際の保護スコアを確認できます。
品質指標に満足したら、組織は AWS Clean Rooms コラボレーション内の合成データセットを使用し、ML モデルのトレーニングを始めることができます。ユースケースによっては、トレーニング済みのモデルウェイトをエクスポートしたり、コラボレーション内で推論ジョブを引き続き実行することができます。
試してみましょう
新しい AWS Clean Rooms コラボレーションを作成するときに、合成データセット生成の費用を誰が支払うかを設定できるようになりました。
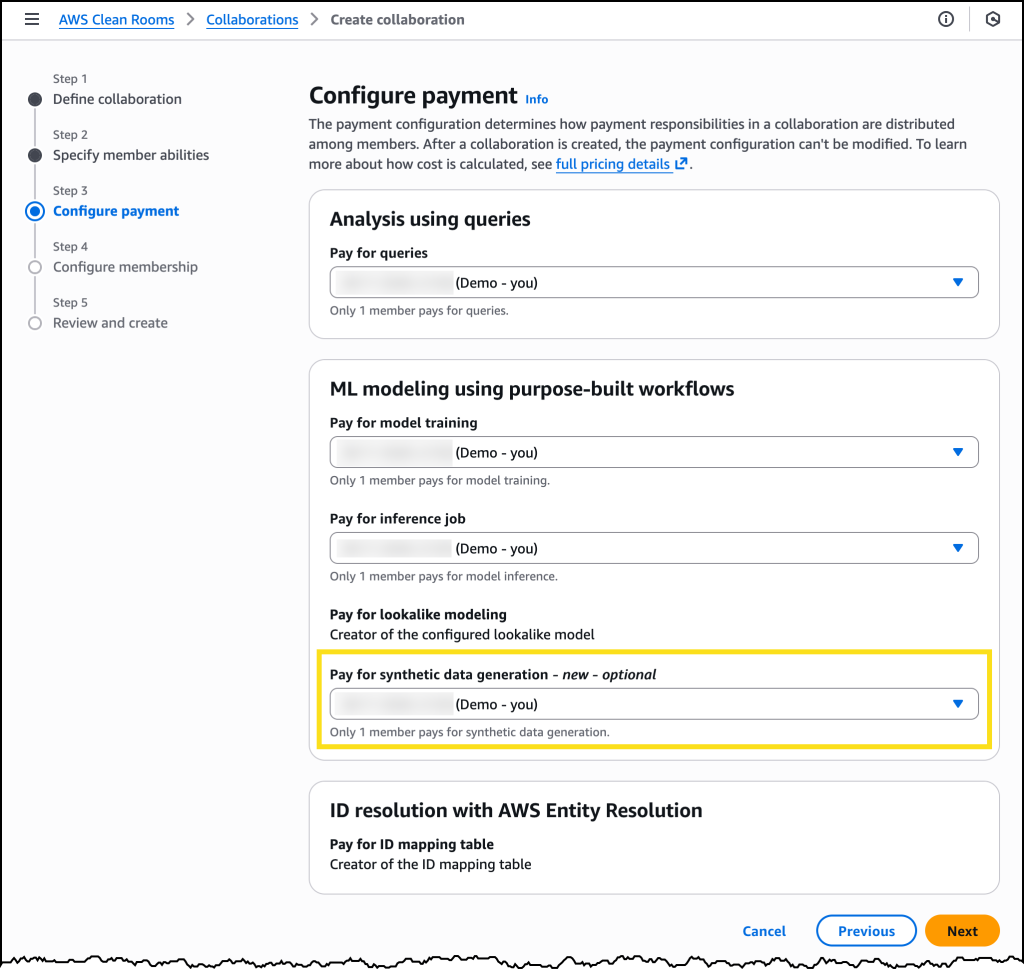
コラボレーションを設定した後で、新しい分析テンプレートを作成するときに、分析テンプレートの出力を合成するように要求する を選択できます。
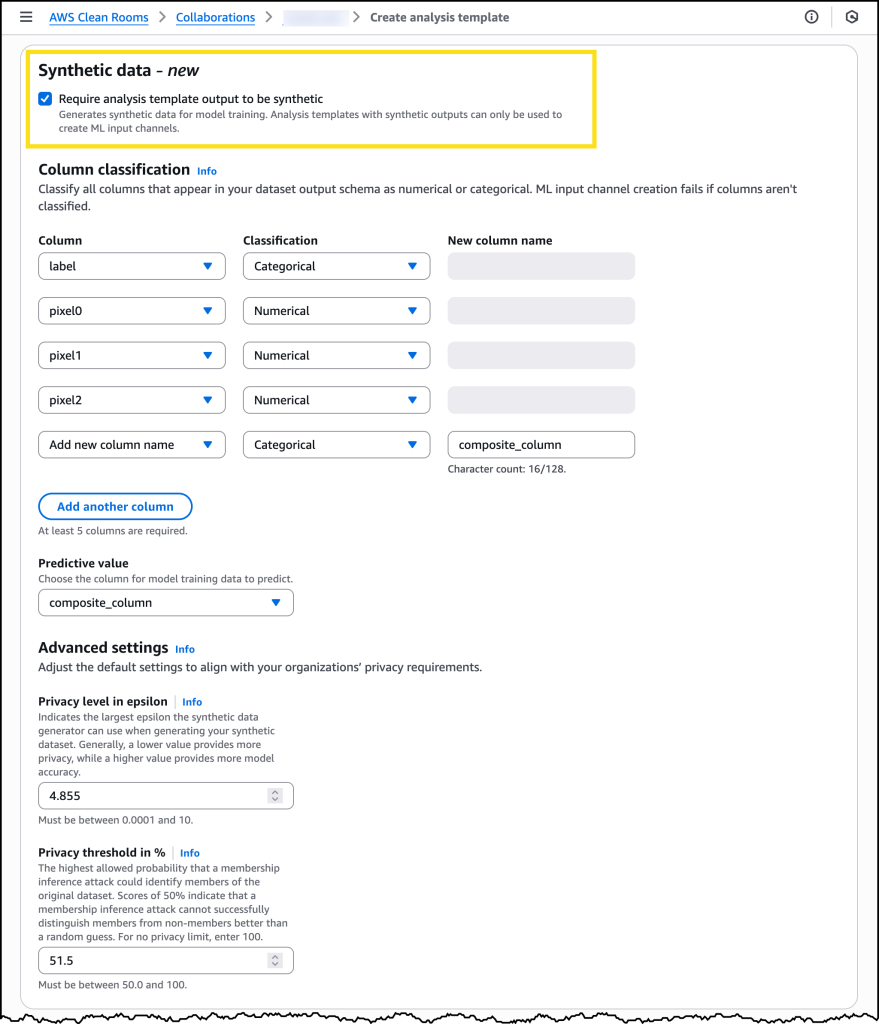
合成分析テンプレートの準備が整ったら、保護されたクエリを実行したり、関連するすべての ML 入力チャネルの詳細を表示させることができます。
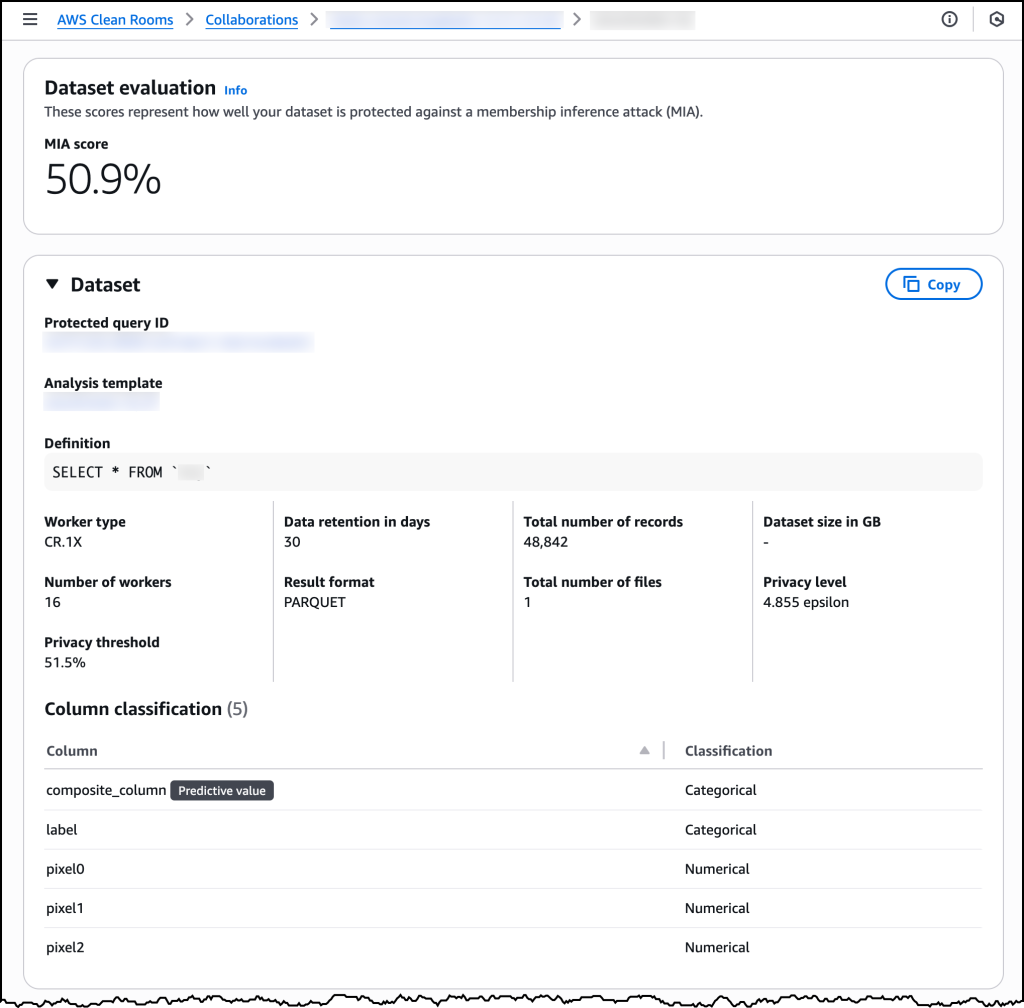
今すぐご利用いただけます
今すぐ AWS Clean Rooms でプライバシーを強化する合成データセットの生成を開始できます。この機能は、AWS Clean Rooms が利用できるすべての商用のAWS リージョンで利用できます。AWS Clean Rooms の詳細については、AWS ドキュメントをご覧ください。
プライバシーを強化する合成データセットの生成は、使用量に応じて個別に請求されます。お支払いいただくのは、合成データセットの生成に使用されたコンピューティング分のみで、合成データ生成ユニット (SDGU) として請求されます。SDGU の数は、元のデータセットのサイズと複雑さによって異なります。この手数料は支払い者設定として構成できます。つまり、コラボレーションメンバーなら誰でも費用の支払いに同意できます。料金の詳細については、AWS Clean Rooms 料金表ページをご参照ください。
初期リリース版では、表形式データでの分類モデルと回帰モデルのトレーニングがサポートされています。合成データセットは標準の ML フレームワークと連携し、ワークフローを変更することなく既存のモデル開発パイプラインと統合できます。
この機能には、プライバシーが強化された機械学習の大幅な進歩が導入されています。組織は、個々のユーザーの機密情報が漏洩するリスクを軽減しながら、モデルトレーニングに役立つ機密ユーザーレベルのデータの価値を引き出すことができます。広告キャンペーンの最適化、保険見積もりのパーソナライズ、不正検知システムの強化のいずれを行う場合でも、プライバシー強化型合成データセット生成により、個人プライバシーを尊重しつつデータ連携を通じてより高精度なモデルの学習が可能になります。
原文はこちらです。