Amazon Web Services ブログ
Apache MXNet バージョン 0.12 で Extends Gluon 機能を拡大、最先端の研究をサポート
先週、Apache MXNet コミュニティが MXNet バージョン 0.12 をリリースしました。このバージョンの主な機能は NVIDIA Volta GPU と Sparse Tensor のサポートです。同リリースには Gluon プログラミングインターフェイスの新機能がいくつも含まれています。こうした機能は特にディープラーニングモデルにおける最先端のリサーチを実装しやすくします。
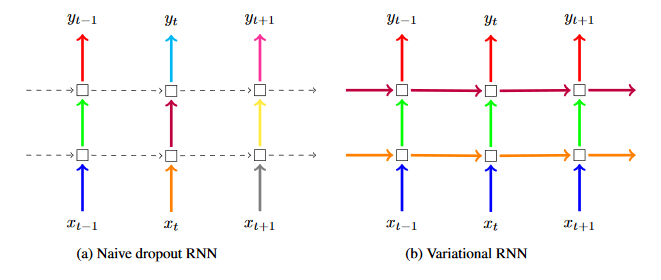
- 変分ドロップアウトは、オーバーフィッティングをリカレントニューラルネットワーク (RNN) に移行するために使うドロップアウト技術を効率的に適用できるようにします。
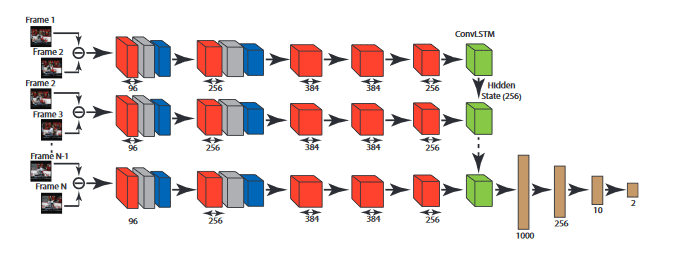
- 畳み込み RNN、Long short-term memory (LSTM)、Gated Recurrent Unit (GRU) セルは、時間ベースのシーケンスと空間ディメンションの両方を示すデータセットのモデリングを可能にします。
- 7 つの新しい損失関数、エクスポート機能、トレーナー機能の強化
変分ドロップアウト (VariationalDropoutCell) は最近のリサーチを足掛かりにして、RNN のオーバーフィッティングを移行させる新たなツールを提供しています。これは「リカレントニューラルネットワークのグランデッドアプリケーションの推論 (“A Theoretically Grounded Application of Recurrent Neural Networks”)」と「RNNDrop: ASR における RNN の新しいアプローチ (“RNNDrop: A Novel Approach for RNNs in ASR”)」を基盤にしています。オーバーフィッティングは、モデルがトレーニングデータセットに近すぎた状態でフィットしていることで発生するモデリングエラーです。そのため、新しいデータまたはテストデータセットが表れた場合に予測精度が低下してしまいます。ドロップアウトはランダムにモデルパラメータをゼロにするモデリング技術です。そのため、トレーニング中にモデルが必要以上に 1 つのインプットまたはパラメータに依存することがありません。とはいっても、この技術が RNN で適用されて成功したケースはまだありません。これまでの研究は、RNN のタイムステップ全体に渡りゼロになった完全なランダム性を持って、入力と出力に限りドロップアウトを適用することに集中してきました。変分ドロップアウトは、このタイムステップに渡るランダム性を除外し、同じランダムドロップアウト配列 (またはマスク) を各タイムステップで RNN の入力、出力そして非表示の状態に適用するようになっています。
畳み込み RNN、LSTM、GRU セル (例: Conv1DRNNCell、Conv1DLSTMCell、Conv1DGRUCell) は、徐々にキャプチャしたビデオやイメージなど配列と空間ディメンションの両方を持つデータセットをモデリングしやすくします。畳み込み LSTM モデルは「畳み込み LSTM ネットワーク: 降水量の短時間天気予報における Machine Learning を使用したアプローチ (“Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting.”)」で提示された研究において初めて適用に成功しました。LSTM ネットワークは、長期に渡る依存性を維持しながらシーケンシャルデータの分析を行うように設計されています。これは自然言語処理 (NLP) の最高水準をさらに進化させています。けれども、時間ベースシーケンスに加え、データセットに空間ディメンションがある時空ユースケースに適用した場合、このパフォーマンスの効率性には制限があります。時空ユースケースの例には、今後 6 時間以内で香港の異なる地域における降水量の予測 (先述の論文で取り上げられている内容) やビデオが暴力的であるか検出することも含まれています。イメージ認識において、畳み込みニューラルネットワーク (CNN) はイメージに畳み込み操作を適用することで最高水準を進化させています。これにより、モデルは空間的状況をキャプチャすることができます。畳み込み RNN、LSTM、GRU はこうした畳み込み操作を RNN、LSTM、GRU アーキテクチャにそれぞれ取り入れています。
また、今回の MXNet リリースは (1) sigmoid binary cross entropy loss、(2) connectionist temporal classification (CTC) loss、(3) Huber loss、(4) hinge loss、(5) squared hinge loss、(6) logistic loss、(7) triple loss といった Gluon の損失関数のセットを 7 つも展開しています。損失関数は一定の目的においてモデルがどれだけのパフォーマンスを実現できているか評価します。こうした損失関数は異なる数学的な計算を使用してパフォーマンスを評価するため、モデルトレーニング中の最適化プロセスにおいてはその効果が異なります。損失関数の選択はサイエンスというよりアートです。どれを選ぶか決定するためのシンプルでヒューリスティックな方法はありません。代わりに、損失関数それぞれに関する幅広い研究を詳しく調べ、いつこうした損失関数が上手く適用されたのか、そしてその逆についても見解を得ることをお勧めします。
今回のリリースには、エクスポート API やトレーナーオプティマイザ機能の学習レートのプロパティといった便利な追加機能も含まれています。エクスポート API は、ニューラルネットワークモデルのアーキテクチャと、それに関連するモデルパラメータを、後日または別の場所でモデルを読み込むために使用できる中間形式にエクスポートすることを可能にします。この API はまだ実験段階にあるため、まだすべての機能はサポートされていません。この他にも、新たに追加されたトレーナーの学習レートのプロパティを使用して、学習レートを設定したり読み取ることができるようになりました。
次のステップ
MXNet の使用開始は簡単です。今回のリリースで行われた変更の詳細リストについてはリリースノートをご覧ください。Gluon インターフェイスの詳細については MXNet の詳細ページまたはチュートリアルをご覧ください。
今回のブログの投稿者について
 Vikram Madan は AWS Deep Learning の上級製品マネージャーです。特にオープンソースの Apache MXNet エンジンに注目し、ディープラーニングエンジンを使いやすくする製品を担当しています。長距離のランニングやドキュメンタリー鑑賞が趣味です。
Vikram Madan は AWS Deep Learning の上級製品マネージャーです。特にオープンソースの Apache MXNet エンジンに注目し、ディープラーニングエンジンを使いやすくする製品を担当しています。長距離のランニングやドキュメンタリー鑑賞が趣味です。