Amazon Web Services ブログ
Amazon SageMaker の自動モデルチューニングで、ランダム検索とハイパーパラメータスケーリングをサポート
Amazon SageMaker の自動モデルチューニングで強くお勧めできる 2 つの機能、ランダム検索とハイパーパラメータスケーリングを紹介します。この記事では、これらの機能について説明し、いつどのように有効にするかについて説明し、どのようにハイパーパラメータの検索におけるパフォーマンスを向上させることができるかを示します。お急ぎの場合は、デフォルト値で実行すると、ほとんどの場合はうまく機能します。しかし、もっと詳しく知りたい場合、もっと手動で制御したい場合は、読み続けてください。
Amazon SageMaker 自動モデルチューニングを初めて使用する場合は、「Amazon SageMaker 開発者ガイド」を参照してください。
ランダム検索とハイパーパラメータの対数スケーリング使用方法の実施例については、GitHub の Jupyter ノートブックの例を参照してください。
ランダム検索
ランダム検索を使用して、Amazon SageMaker に、ランダムな分布からハイパーパラメータ設定を選択するように指示します。
ランダム検索の主な利点は、すべてのジョブを並行して実行できることです。対照的に、デフォルトのチューニング手法であるベイズ最適化は、チューニングジョブの進行につれて過去のトレーニングから学習する順序アルゴリズムです。これにより、並列処理のレベルが大幅に制限されます。ランダム検索の欠点は、匹敵するモデル品質に到達するために、一般的にかなり多くのトレーニングジョブを実行する必要があることです。
Amazon SageMaker では、以下のように、チューニングジョブを作成するときに [戦略] フィールドを [ランダム] に設定するのと同じくらい簡単に、ランダム検索を有効にすることができます。
AWS SDK for Python (Boto) を使用している場合は、HyperparameterTuner クラスで strategy="Random" に設定します。
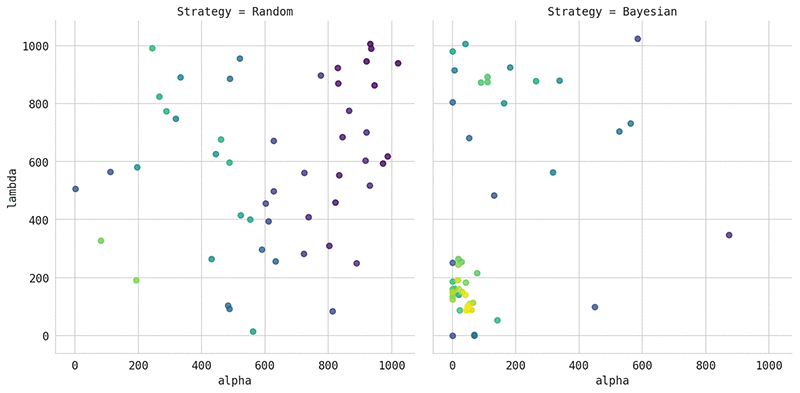
次のプロットは、左側のランダム検索で選択されたハイパーパラメータと、右側のベイズ最適化で選択されたハイパーパラメータを比較したものです。この例では、モデルチューニングのノートブックの例で作成した銀行マーケティングのデータセットを使用して、XGBoost アルゴリズムを調整しました。視覚化するために、alpha と lambda の 2 つのハイパーパラメータのみを調整しました。可視化されたポイントの色は対応するモデルの品質を示します。黄色は曲線下面積 (AUC) スコアがより良いモデルに対応しており、紫はより悪い AUC を示します。
プロットは、ベイズ最適化がトレーニングのほとんどを、最高のモデルを生成する検索スペースのリージョンに集中させることを明確に示しています。このアルゴリズムは時折、未探索の新しいリージョンを探索することがあります。一方、ランダム検索は、ハイパーパラメータを均等にランダムで選択します。
次のグラフは、前述の例でランダム検索とベイズ最適化の品質を比較したものです。線は、より多くのトレーニングジョブが実行されるにつれて (横軸)、これまでで最高のモデルスコアを示しています (縦軸、低いほどスコアが高い)。各実験を 50 回レプリケートし、これらのレプリケーションの平均値をプロットしました。モデルチューニングアルゴリズムのランダムな性質がチューニングパフォーマンスに大きな影響を与える可能性があるため、これは正確な結果を得るために必要な作業です。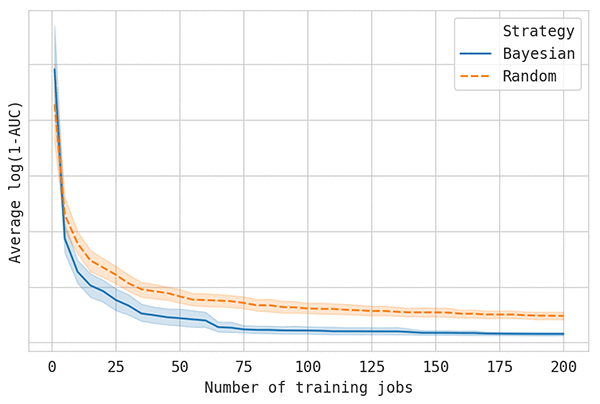
ベイズ最適化で、ランダム検索と同じレベルのパフォーマンスを達成するために、必要なトレーニングジョブは 4 分の 1 であることがわかります。ほとんどのチューニングジョブで同様の結果が期待できます。
信頼性の高い結果を得るために、複数のレプリケーションを平均化することが重要です。その理由を確認するには、次のシングルレプリケーションのグラフを参照してください。実行ごとに設定は同じで、すべての変化は異なるランダムシードの内部使用によるものです。5 つのサンプルは、前述の議論で平均化された曲線から取得できます。
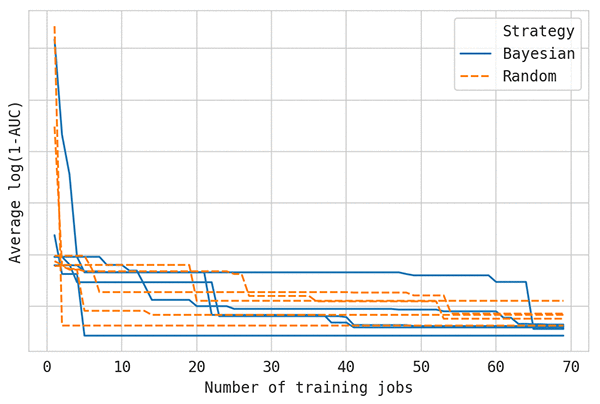
ご覧のとおり、ハイパーパラメータのチューニング曲線は、機械学習で見られる他の一般的な学習曲線とは大きく異なります。特に、それらははるかに大きな差異を示します。これら 5 つのサンプルだけでは、結論を出せません。ハイパーパラメータのチューニング方法を比較している状況では、この点に留意してください。
グリッド検索はどうですか? グリッド検索は、ハイパーパラメータ設定を盲目的に選択するという点でランダム検索と似ています。ただし、結果に大きな影響を与えない一部のハイパーパラメータの場合、トレーニングジョブがほぼ重複してしまうため、通常はあまり効果的な方法ではありません。
ハイパーパラメータのスケーリング
実際は、その値が何桁にもわたって大きく変わるハイパーパラメータが多数あります。このハイパーパラメータの変化による効果を調べるために、深層学習アルゴリズムに対していくつかの異なるステップサイズを手動で試すように頼まれたとします。この場合、等距離の値 (0.1、0.2、0.3、…) ではなく 10 の累乗数 (1.0、0.1、0.01、…) を選択してください。私たちは経験から、後者がアルゴリズムの動作を大きく変える可能性が低いことを知っています。多くのハイパーパラメータでは、桁を変えると、もっと興味深い変化をもたらします。
桁によって変化する値を試すには、ハイパーパラメータのスケーリングタイプを [対数] に設定してください。
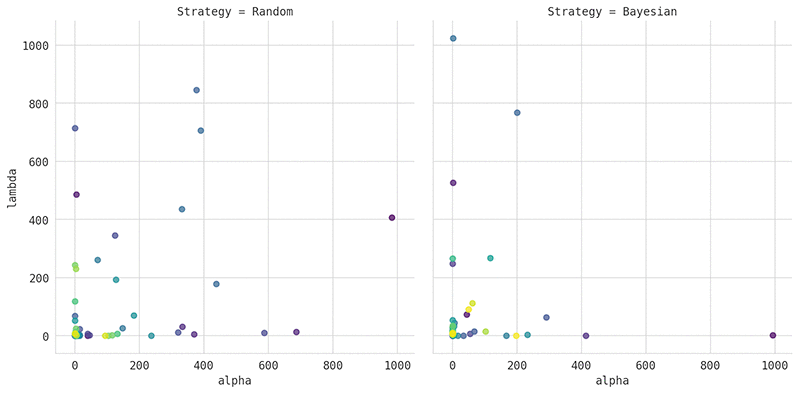
次のグラフは、前述の例で使用したハイパーパラメータに対数スケーリングを適用した結果を示しています。左のプロットは、ランダム検索を使用した結果を示しています。右のプロットは、ベイズ最適化を使用した結果を示しています。
スケーリングタイプを手動で指定するには、ハイパーパラメータ範囲の [ScalingType] を [Logarithmic] または [ReverseLogarithmic] に設定します (このタイプの詳細については後で説明します)。チューニングジョブ設定の範囲を定義すると、次のようになります。
AWS SDK for Python (Boto) の場合、同等のものは次のとおりです。
逆対数
深層学習では、一般的な運動量のハイパーパラメータは、線形スケーリングや単純対数スケーリングではうまく機能しません。一般的に、お客様は 0.9、0.99、0.999 などの値を調べたいはずです。言い換えれば、ますます 1.0 に近い値に興味を持っているということです。この場合、ScalingType を ReverseLogarithmic に設定することをお勧めします。 これにより、Amazon SageMaker に、すべての値で内部的に変換対数 (1.0 - 値) を適用するように指示します。
自動スケーリング
自動スケーリング (自動設定) を選択すると、ハイパーパラメータの範囲から明らかに適切な選択ができる場合、Amazon SageMaker はいつでも対数スケーリングまたは逆対数スケーリングを使用します。そうでない場合は、線形スケーリングに戻ります。
自動スケーリングを使用しているときに、ハイパーパラメータの最小値として 0 を指定した場合、Amazon SageMaker が対数スケーリングの使用を選択することは決してありません。代わりに、対数スケーリングを明示的に選択し、0 より大きい最小値を使用することをお勧めします。たとえば、最小正則化値に 0 を使用しないでください。代わりに、1e-8 のような値を使用してください。これはほぼ同等で、対数スケーリングを使用できます。
ワープ
Amazon SageMaker ベイズ最適化エンジンには、ワープと呼ばれる追加の内部機能があります。ワープは、この記事で説明している設定可能なスケーリングオプションと密接な関係があります。Amazon SageMaker は、指定されたスケーリングタイプとともに、各ハイパーパラメータに内部ワープ関数を適用します。データを最もよく表すものに応じてチューニングジョブが進むにつれて、ワープ関数が学習されます。これは、チューニングジョブが進行するにつれてこのワープ関数が向上する一方で、ハイパーパラメータのスケーリングが最初から適用されることを意味します。
次の図に示すように、内部ワープは、ハイパーパラメータのスケーリングでサポートされている 3 つの変換と比較して、はるかに大きな種類の変換を学習できます。左側の図は、スケーリングタイプを設定すると指定できる 3 つの変換を示しています。右側の図は、ワープを通して内部的に学習できる変換の例をいくつか示しています。これは、選択したスケーリングタイプに加えて学習されます。
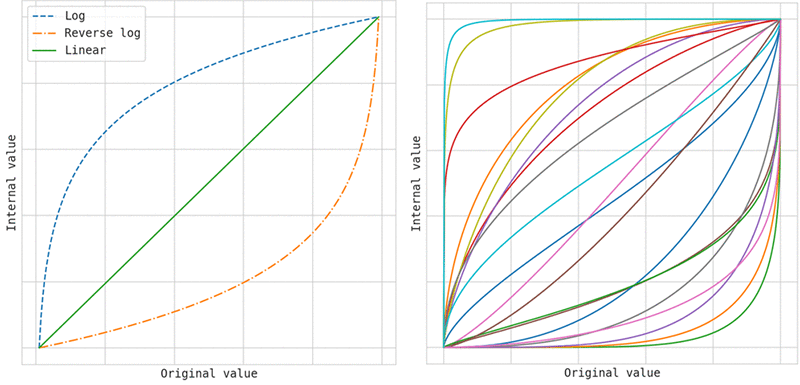
ランダム検索を使用する場合、Amazon SageMaker は内部ワープを適用しないため、ランダム検索を使用するときに正しいスケーリングタイプを選択することは、特に重要です。
まとめ
ベイズ最適化でサポートされているよりも高度の並列処理が必要な場合は、ランダム検索を使用できます。ただし、ほとんどの場合、デフォルトのベイズ最適化戦略を使用する方がより費用対効果が高いことに注意してください。
どのハイパーパラメータのスケーリングタイプを使用するべきかわからない場合は、自動スケーリングを使用してください。ハイパーパラメータが何桁にもわたって大きく変わる場合は、対数スケールを使用してください。1.0 に近い値に興味がある場合は、逆対数スケーリングを使用してください。正しいスケーリングタイプを使用すると、パフォーマンスの高いハイパーパラメータ検索のスピードが大幅に上がります。
著者について
 Fela Winkelmolen は Amazon AI の応用科学者であり、Amazon SageMaker の自動モデルチューニング機能を発表したチームの一員でした。
Fela Winkelmolen は Amazon AI の応用科学者であり、Amazon SageMaker の自動モデルチューニング機能を発表したチームの一員でした。