Amazon Web Services ブログ
Amazon S3 Vectors がスケールとパフォーマンスを向上させて一般提供開始
本記事は 2025 年 12 月 2 日 に公開された「Amazon S3 Vectors now generally available with increased scale and performance」を翻訳したものです。
Amazon S3 Vectors がスケールとパフォーマンスを大幅に向上させて一般提供を開始しました。S3 Vectors は、ベクトルデータの保存とクエリをネイティブにサポートする初のクラウドオブジェクトストレージです。専用のベクトルデータベースソリューションと比較して、ベクトルの保存とクエリの総コストを最大 90% 削減できます。
7 月に S3 Vectors のプレビューを発表して以来、ベクトルデータの保存とクエリにこの新機能をいかに早く採用いただいたかに感銘を受けています。わずか 4 か月余りで、25 万以上のベクトルインデックスが作成され、400 億以上のベクトルが取り込まれ、10 億以上のクエリが実行されました(11 月 28 日時点)。
単一のインデックスで最大 20 億のベクトルを保存および検索できるようになりました。これはプレビュー時のインデックスあたり 5,000 万から 40 倍の増加であり、ベクトルバケットあたり最大 20 兆のベクトルを格納できます。これにより、ベクトルデータセット全体を 1 つのインデックスに統合でき、複数の小さなインデックスにシャーディングしたり、複雑なクエリフェデレーションロジックを実装したりする必要がなくなります。
クエリパフォーマンスも最適化されました。頻度の低いクエリは引き続き 1 秒未満で結果を返し、頻度の高いクエリでは約 100 ミリ秒以下のレイテンシーを実現しています。これにより、会話型 AI やマルチエージェントワークフローなどのインタラクティブなアプリケーションに適しています。また、クエリあたり最大 100 件の検索結果を取得できるようになり(以前は 30 件)、検索拡張生成(RAG)アプリケーションにより包括的なコンテキストを提供できます。
書き込みパフォーマンスも大幅に向上し、インデックスへの単一ベクトル更新のストリーミング時に最大 1,000 PUT トランザクション/秒をサポートし、小さなバッチサイズでの書き込みスループットが大幅に向上しました。この高いスループットにより、新しいデータをすぐに検索可能にする必要があるワークロードをサポートし、小規模なデータコーパスを迅速に取り込んだり、同じインデックスに同時に書き込む多数の並行ソースを処理したりできます。
完全なサーバーレスアーキテクチャにより、インフラストラクチャのオーバーヘッドが排除されます。セットアップするインフラストラクチャやプロビジョニングするリソースはありません。ベクトルの保存とクエリに応じて使用した分だけ支払います。この AI 対応ストレージにより、初期の実験やプロトタイピングから大規模な本番デプロイメントまで、AI 開発ライフサイクル全体をサポートするために、任意の量のベクトルデータに迅速にアクセスできます。S3 Vectors は、AI エージェント、推論、セマンティック検索、RAG アプリケーション全体で本番ワークロードに必要なスケールとパフォーマンスを提供するようになりました。
プレビューで開始された 2 つの主要な統合が一般提供になりました。S3 Vectors を Amazon Bedrock ナレッジベースのベクトルストレージエンジンとして使用できます。特に、本番グレードのスケールとパフォーマンスで RAG アプリケーションを構築するために使用できます。さらに、S3 Vectors と Amazon OpenSearch の統合が一般提供になりました。これにより、OpenSearch を検索および分析機能に使用しながら、S3 Vectors をベクトルストレージレイヤーとして使用できます。
S3 Vectors は、プレビュー時の 5 つの AWS リージョンから拡大し、14 の AWS リージョンで使用できるようになりました。
使い方を見てみましょう
この記事では、AWS コンソールと CLI を使用して S3 Vectors を使用する方法を説明します。
まず、S3 ベクトルバケットとインデックスを作成します。
echo "Creating S3 Vector bucket..."
aws s3vectors create-vector-bucket \
--vector-bucket-name "$BUCKET_NAME"
echo "Creating vector index..."
aws s3vectors create-index \
--vector-bucket-name "$BUCKET_NAME" \
--index-name "$INDEX_NAME" \
--data-type "float32" \
--dimension "$DIMENSIONS" \
--distance-metric "$DISTANCE_METRIC" \
--metadata-configuration "nonFilterableMetadataKeys=AMAZON_BEDROCK_TEXT,AMAZON_BEDROCK_METADATA"ディメンションメトリクスは、ベクトルの計算に使用されるモデルのディメンションと一致する必要があります。距離メトリクスは、ベクトル間の距離を計算するアルゴリズムを示します。S3 Vectors はコサイン距離とユークリッド距離をサポートしています。
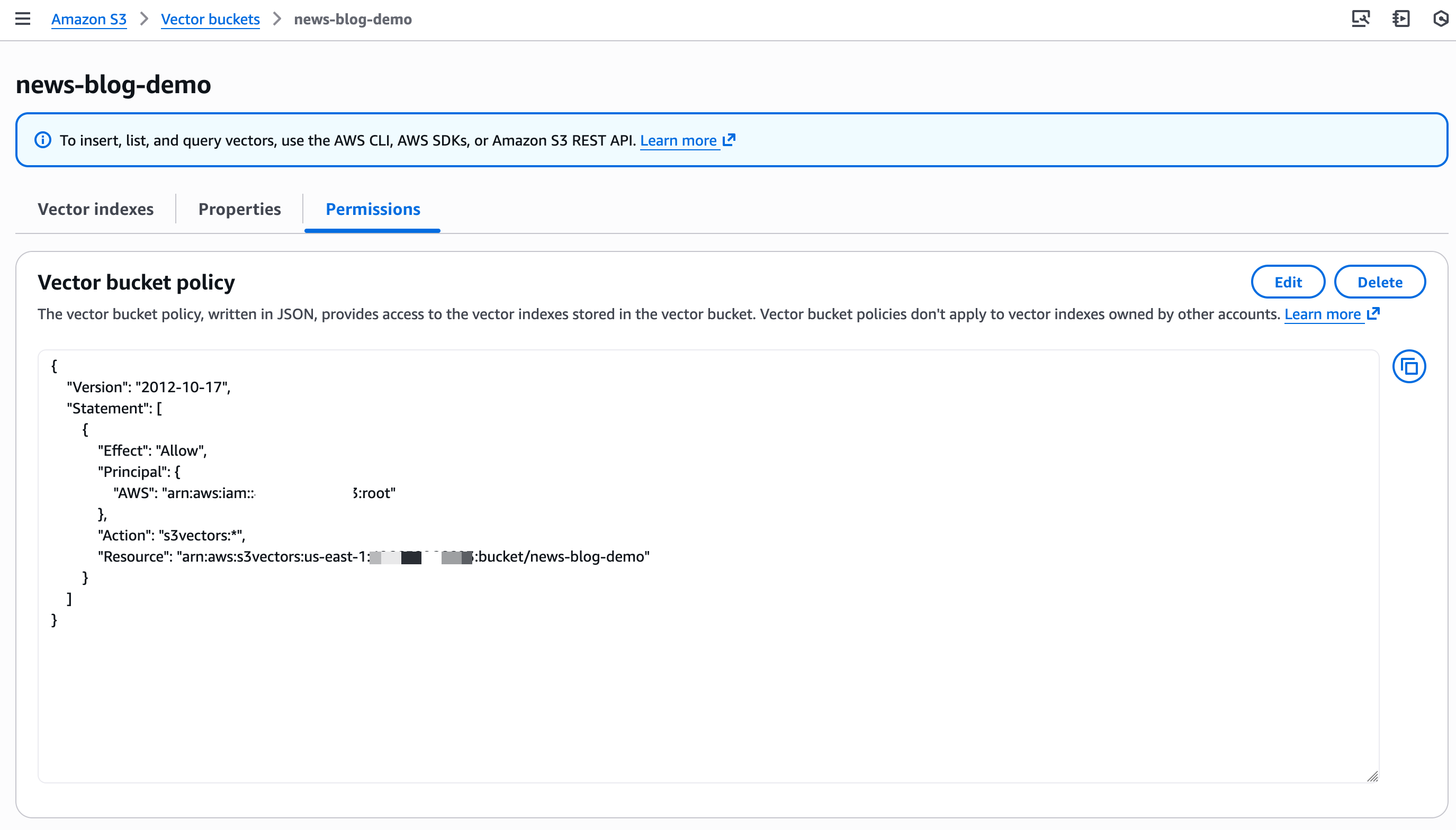
コンソールを使用してバケットを作成することもできます。作成時に暗号化パラメータを設定する機能が追加されました。デフォルトでは、インデックスはバケットレベルの暗号化を使用しますが、カスタムの AWS Key Management Service (AWS KMS) キーを使用して、インデックスレベルでバケットレベルの暗号化をオーバーライドできます。
ベクトルバケットとベクトルインデックスにタグを追加することもできます。ベクトルインデックスのタグは、アクセス制御とコスト配分に役立ちます。
また、コンソールで直接プロパティとアクセス許可を管理できるようになりました。
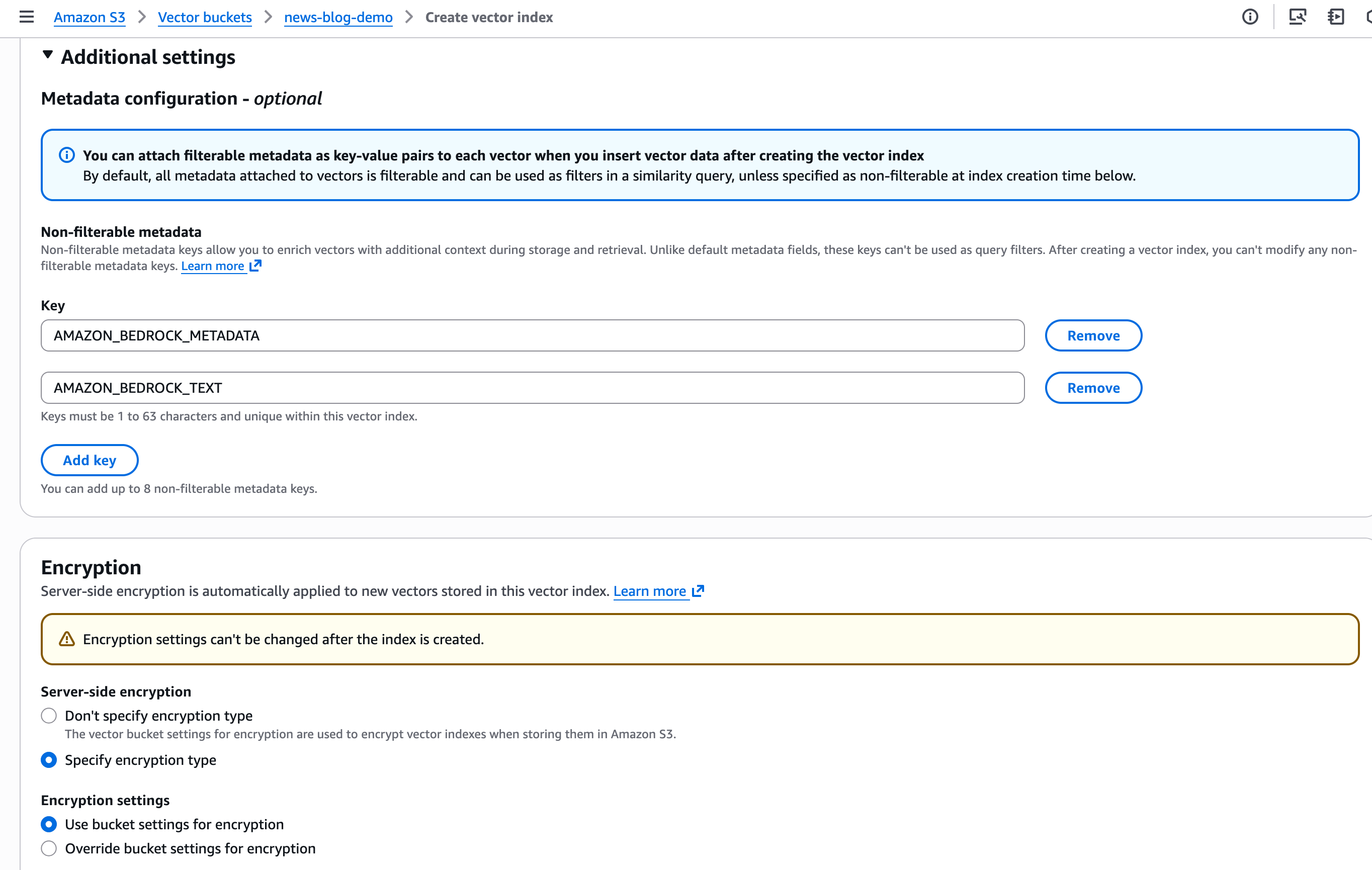
同様に、フィルタリング不可のメタデータを定義し、ベクトルインデックスの暗号化パラメータを設定します。
次に、埋め込み(ベクトル)を作成して保存します。このデモでは、私の常に手元にある AWS スタイルガイドを取り込みます。これは、AWS での投稿、技術ドキュメント、記事の書き方を説明する 800 ページのドキュメントです。
Amazon Bedrock ナレッジベースを使用して、汎用 S3 バケットに保存された PDF ドキュメントを取り込みます。Amazon Bedrock ナレッジベースはドキュメントを読み取り、チャンクと呼ばれる断片に分割します。次に、Amazon Titan Text Embeddings モデルを使用して各チャンクの埋め込みを計算し、ベクトルとそのメタデータを新しく作成したベクトルバケットに保存します。このプロセスの詳細な手順はこの記事の範囲外ですが、ドキュメントの手順を参照できます。
ベクトルをクエリする際、ベクトルごとに最大 50 個のメタデータキーを保存でき、そのうち最大 10 個をフィルタリング不可としてマークできます。フィルタリング可能なメタデータキーを使用して、特定の属性に基づいてクエリ結果をフィルタリングできます。したがって、ベクトル類似性検索とメタデータ条件を組み合わせて結果を絞り込むことができます。また、より大きなコンテキスト情報のために、より多くのフィルタリング不可のメタデータを保存することもできます。Amazon Bedrock ナレッジベースはベクトルを計算して保存します。また、大きなメタデータ(元のテキストのチャンク)も追加します。このメタデータは検索可能なインデックスから除外します。
ベクトルを取り込む他の方法もあります。S3 Vectors Embed CLI を試すことができます。これは、Amazon Bedrock を使用して埋め込みを生成し、直接コマンドで S3 Vectors に保存するのに役立つコマンドラインツールです。また、OpenSearch のベクトルストレージエンジンとして S3 Vectors を使用することもできます。
これでベクトルインデックスをクエリする準備ができました。「open source」の書き方について疑問があるとしましょう。ハイフン付きの「open-source」なのか、ハイフンなしの「open source」なのか?大文字を使うべきかどうか?「open source」に関連する AWS スタイルガイドの関連セクションを検索したいと思います。
# 1. Create embedding request
echo '{"inputText":"Should I write open source or open-source"}' | base64 | tr -d '\n' > body_encoded.txt
# 2. Compute the embeddings with Amazon Titan Embed model
aws bedrock-runtime invoke-model \
--model-id amazon.titan-embed-text-v2:0 \
--body "$(cat body_encoded.txt)" \
embedding.json
# Search the S3 Vectors index for similar chunks
vector_array=$(cat embedding.json | jq '.embedding') && \
aws s3vectors query-vectors \
--index-arn "$S3_VECTOR_INDEX_ARN" \
--query-vector "{\"float32\": $vector_array}" \
--top-k 3 \
--return-metadata \
--return-distance | jq -r '.vectors[] | "Distance: \(.distance) | Source: \(.metadata."x-amz-bedrock-kb-source-uri" | split("/")[-1]) | Text: \(.metadata.AMAZON_BEDROCK_TEXT[0:100])..."'最初の結果は次の JSON を示しています。
{
"key": "348e0113-4521-4982-aecd-0ee786fa4d1d",
"metadata": {
"x-amz-bedrock-kb-data-source-id": "0SZY6GYPVS",
"x-amz-bedrock-kb-source-uri": "s3://sst-aws-docs/awsstyleguide.pdf",
"AMAZON_BEDROCK_METADATA": "{\"createDate\":\"2025-10-21T07:49:38Z\",\"modifiedDate\":\"2025-10-23T17:41:58Z\",\"source\":{\"sourceLocation\":\"s3://sst-aws-docs/awsstyleguide.pdf\"",
"AMAZON_BEDROCK_TEXT": "[redacted] open source (adj., n.) Two words. Use open source as an adjective (for example, open source software), or as a noun (for example, the code throughout this tutorial is open source). Don't use open-source, opensource, or OpenSource. [redacted]",
"x-amz-bedrock-kb-document-page-number": 98.0
},
"distance": 0.63120436668396
}AWS スタイルガイドの関連セクションが見つかりました。「open source」はハイフンなしで書く必要があります。元のドキュメントの関連する段落と提案を照合するのに役立つように、元のドキュメントのページ番号も取得されました。
もう 1 つ
S3 Vectors は統合機能も拡張されました。AWS CloudFormation を使用してベクトルリソースをデプロイおよび管理したり、AWS PrivateLink を使用してプライベートネットワーク接続を行ったり、コスト配分とアクセス制御のためにリソースタグ付けを使用したりできるようになりました。
料金と利用可能なリージョン
S3 Vectors は、プレビューからの既存の 5 つのリージョン(米国東部(オハイオ、バージニア北部)、米国西部(オレゴン)、アジアパシフィック(シドニー)、欧州(フランクフルト))に加えて、アジアパシフィック(ムンバイ、ソウル、シンガポール、東京)、カナダ(中部)、欧州(アイルランド、ロンドン、パリ、ストックホルム)が追加され、14 の AWS リージョンで利用可能になりました。
Amazon S3 Vectors の料金は 3 つの要素に基づいています。PUT 料金は、アップロードするベクトルの論理 GB に基づいて計算されます。各ベクトルには、論理ベクトルデータ、メタデータ、キーが含まれます。ストレージコストは、インデックス全体の合計論理ストレージによって決まります。クエリ料金には、API ごとの料金と、インデックスサイズ(フィルタリング不可のメタデータを除く)に基づく $/TB 料金が含まれます。インデックスが 100,000 ベクトルを超えてスケールすると、$/TB 料金が低くなるメリットがあります。詳細は Amazon S3 料金ページをご覧ください。
S3 Vectors を使い始めるには、Amazon S3 コンソールにアクセスしてください。ベクトルインデックスを作成し、埋め込みの保存を開始し、スケーラブルな AI アプリケーションの構築を始めることができます。詳細については、Amazon S3 ユーザーガイドまたは AWS CLI コマンドリファレンスをご覧ください。
これらの新機能で何を構築されるか楽しみにしています。AWS re:Post または通常の AWS サポート連絡先を通じてフィードバックをお寄せください。
著者について
 Sébastien Stormacq Seb は 80 年代半ばに初めて Commodore 64 に触れて以来、コードを書いています。情熱、熱意、顧客擁護、好奇心、創造性を独自にブレンドして、ビルダーが AWS クラウドの価値を引き出すよう刺激を与えています。彼の関心はソフトウェアアーキテクチャ、開発者ツール、モバイルコンピューティングです。何かを売り込みたい場合は、API があることを確認してください。Bluesky、X、Mastodon などで @sebsto をフォローしてください。
Sébastien Stormacq Seb は 80 年代半ばに初めて Commodore 64 に触れて以来、コードを書いています。情熱、熱意、顧客擁護、好奇心、創造性を独自にブレンドして、ビルダーが AWS クラウドの価値を引き出すよう刺激を与えています。彼の関心はソフトウェアアーキテクチャ、開発者ツール、モバイルコンピューティングです。何かを売り込みたい場合は、API があることを確認してください。Bluesky、X、Mastodon などで @sebsto をフォローしてください。