Amazon Web Services ブログ
Amazon OpenSearch Service が GPU アクセラレーションと自動最適化でベクトルデータベースのパフォーマンスとコストを改善
本記事は 2025年12月2日 に公開された「Amazon OpenSearch Service improves vector database performance and cost with GPU acceleration and auto-optimization」を翻訳したものです。
本日、Amazon OpenSearch Service において、サーバーレス GPU アクセラレーションとベクトルインデックスの自動最適化を発表しました。これにより、大規模なベクトルデータベースをより高速かつ低コストで構築でき、検索品質、速度、コストの最適なトレードオフを実現するようにベクトルインデックスを自動的に最適化できます。
本日発表された新機能は以下のとおりです。
- GPU アクセラレーション – GPU アクセラレーションを使用しない場合と比較して、最大 10 倍高速にベクトルデータベースを構築でき、インデックス作成コストを 4 分の 1 に削減できます。また、10 億規模のベクトルデータベースを 1 時間以内に作成できます。コスト削減と速度の大幅な向上により、市場投入までの時間、イノベーションの速度、大規模なベクトル検索の導入において優位性を得ることができます。
- 自動最適化 – ベクトルの専門知識がなくても、ベクトルフィールドの検索レイテンシー、品質、メモリ要件の最適なバランスを見つけることができます。この最適化により、デフォルトのインデックス設定と比較して、コスト削減と再現率の向上を実現できます。手動でのインデックスチューニングには数週間かかることがあります。
これらの機能を使用して、OpenSearch Service 上でベクトルデータベースをより高速かつコスト効率よく構築できます。生成 AI アプリケーション、製品カタログやナレッジベースの検索などに活用できます。GPU アクセラレーションと自動最適化は、新しい OpenSearch ドメインまたはコレクションを作成するとき、および既存のドメインまたはコレクションを更新するときに有効にできます。
それでは、仕組みを見ていきましょう!
ベクトルインデックスの GPU アクセラレーション
OpenSearch Service ドメインまたはサーバーレスコレクションで GPU アクセラレーションを有効にすると、OpenSearch Service はベクトルインデックス作成ワークロードを高速化する機会を自動的に検出します。このアクセラレーションにより、OpenSearch Service ドメインまたはサーバーレスコレクション内のベクトルデータ構造の構築が高速化されます。
GPU インスタンスをプロビジョニングしたり、使用状況を管理したり、アイドル時間に対して支払ったりする必要はありません。OpenSearch Service は、アクセラレーションされたワークロードをアカウント内のドメインまたはコレクションの Amazon Virtual Private Cloud (Amazon VPC) に安全に分離します。OpenSearch Compute Units (OCU) – Vector Acceleration の料金を通じて、実際の処理に対してのみ支払います。
GPU アクセラレーションを有効にするには、OpenSearch Service コンソールに移動し、OpenSearch Service ドメインまたはサーバーレスコレクションを作成または更新するときに、Advanced features セクションで Enable GPU Acceleration を選択します。
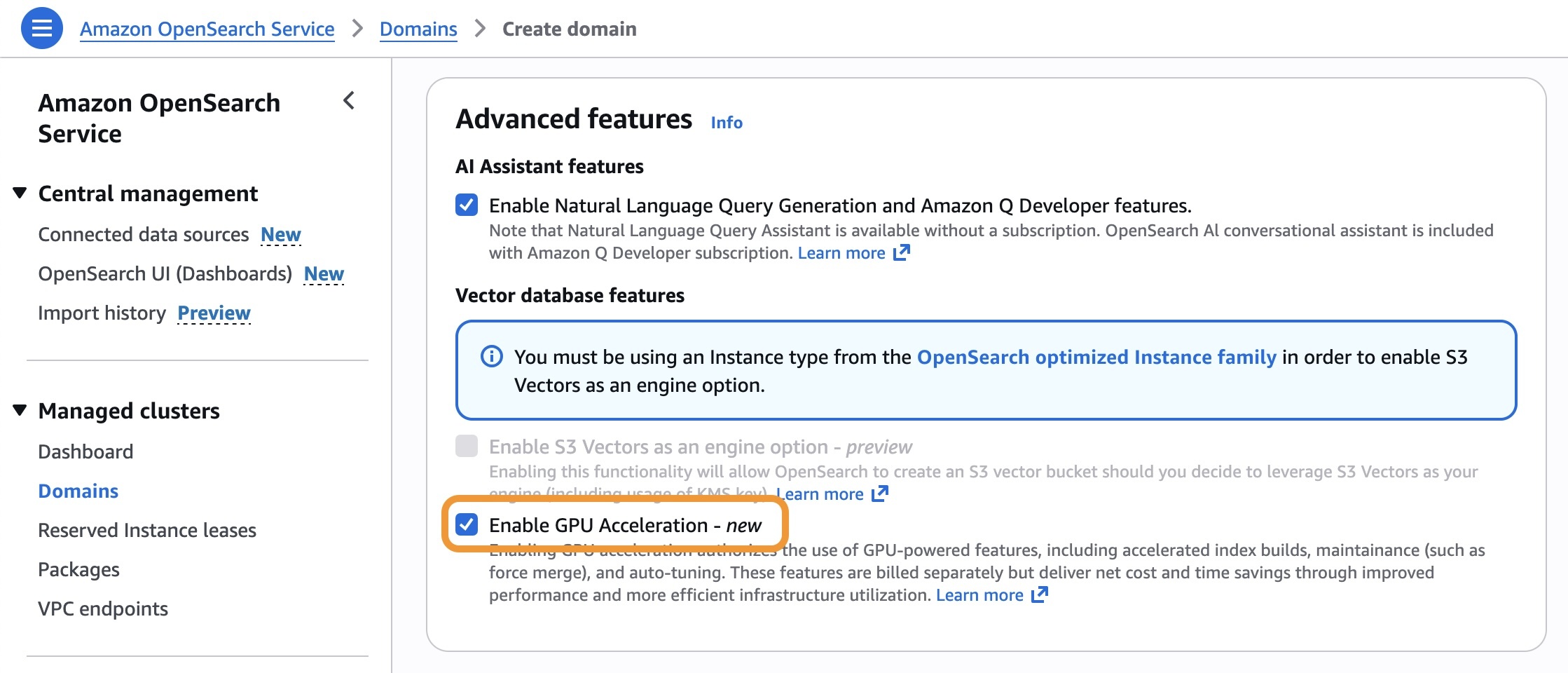
以下の AWS Command Line Interface (AWS CLI) コマンドを使用して、既存の OpenSearch Service ドメインで GPU アクセラレーションを有効にできます。
$ aws opensearch update-domain-config \
--domain-name my-domain \
--aiml-options '{"ServerlessVectorAcceleration": {"Enabled": true}}'
GPU 処理用に最適化されたベクトルインデックスを作成できます。この例のインデックスは、index.knn.remote_index_build.enabled を有効にすることで、テキスト埋め込み用の 768 次元ベクトルを格納します。
PUT my-vector-index
{
"settings": {
"index.knn": true,
"index.knn.remote_index_build.enabled": true
},
"mappings": {
"properties": {
"vector_field": {
"type": "knn_vector",
"dimension": 768,
},
"text": {
"type": "text"
}
}
}
}これで、標準の OpenSearch Service オペレーションを使用して、bulk API でベクトルデータを追加し、インデックスを最適化できます。GPU アクセラレーションは、インデックス作成と force-merge オペレーションに自動的に適用されます。
POST my-vector-index/_bulk
{"index": {"_id": "1"}}
{"vector_field": [0.1, 0.2, 0.3, ...], "text": "Sample document 1"}
{"index": {"_id": "2"}}
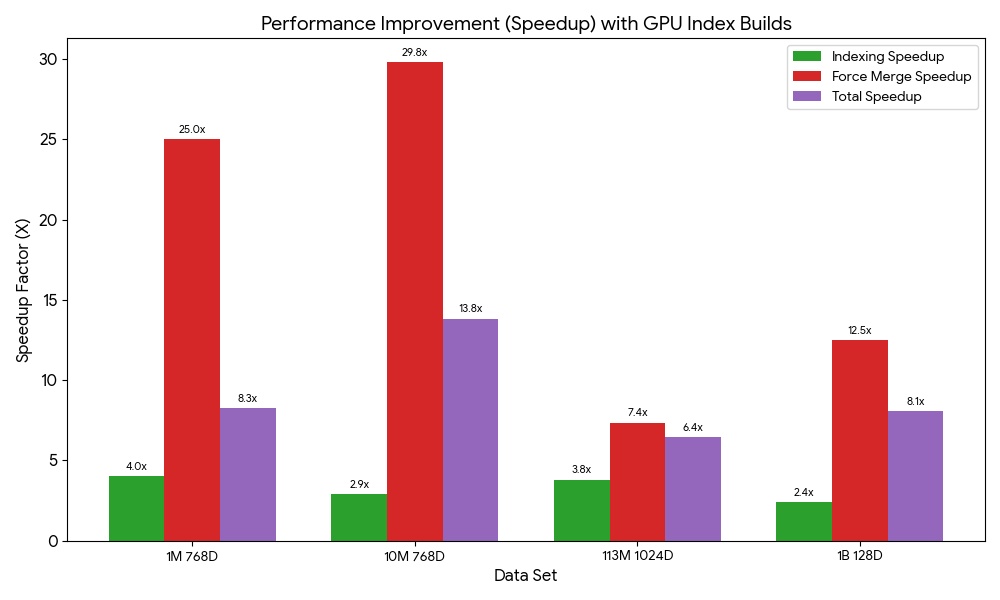
{"vector_field": [0.4, 0.5, 0.6, ...], "text": "Sample document 2"}インデックス構築のベンチマークを実行したところ、GPU アクセラレーションによる速度向上は 6.4 倍から 13.8 倍の範囲でした。今後の投稿で、さらなるベンチマークと詳細をお届けする予定です。
詳細については、Amazon OpenSearch Service デベロッパーガイドの「GPU acceleration for vector indexing」を参照してください。
ベクトルデータベースの自動最適化
新しいベクトル取り込み機能を使用して、Amazon Simple Storage Service (Amazon S3) からドキュメントを取り込み、ベクトル埋め込みを生成し、インデックスを自動的に最適化し、大規模なベクトルインデックスを数分で構築できます。取り込み中に、自動最適化は OpenSearch Service ドメインまたはサーバーレスコレクションのベクトルフィールドとインデックスに基づいて推奨事項を生成します。これらの推奨事項のいずれかを選択して、手動でマッピングを設定する代わりに、ベクトルデータセットをすばやく取り込んでインデックスを作成できます。
開始するには、OpenSearch Service コンソールの左側のナビゲーションペインにある Ingestion メニューの下の Vector ingestion を選択します。
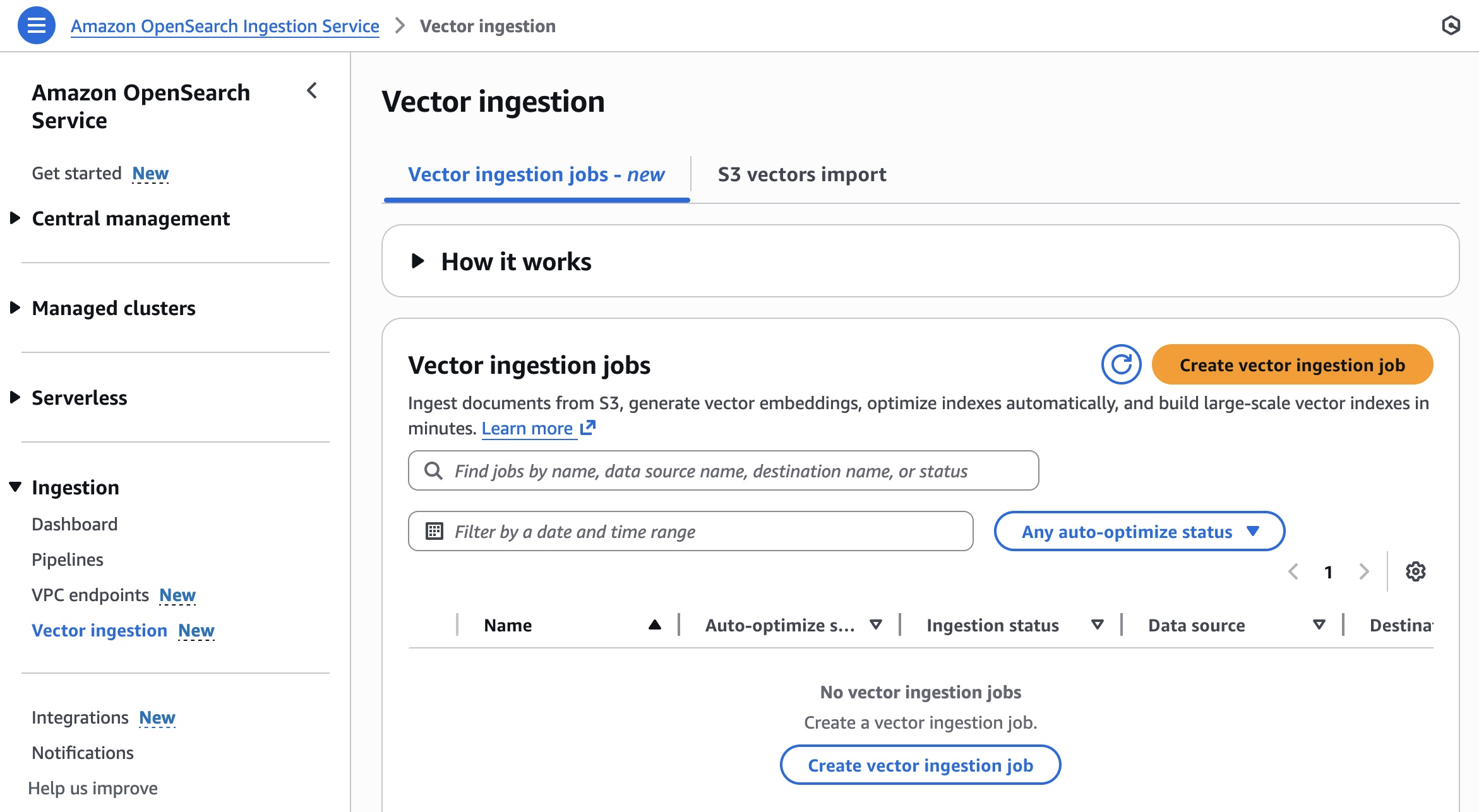
以下の手順で新しいベクトル取り込みジョブを作成できます。
- データセットの準備 – S3 バケットに OpenSearch Service parquet ドキュメントを準備し、宛先としてドメインまたはコレクションを選択します。
- インデックスの設定と最適化の自動化 – ベクトルフィールドを自動最適化するか、手動で設定します。
- 取り込みとインデックス作成の高速化 – OpenSearch Ingestion パイプラインを使用して、Amazon S3 から OpenSearch Service にデータをロードします。大規模なベクトルインデックスを最大 10 倍高速に、4 分の 1 のコストで構築できます。
ステップ 2 では、自動最適化ベクトルフィールドを使用してベクトルインデックスを設定します。自動最適化は現在、1 つのベクトルフィールドに制限されています。自動最適化ジョブが完了した後に、追加のインデックスマッピングを入力できます。
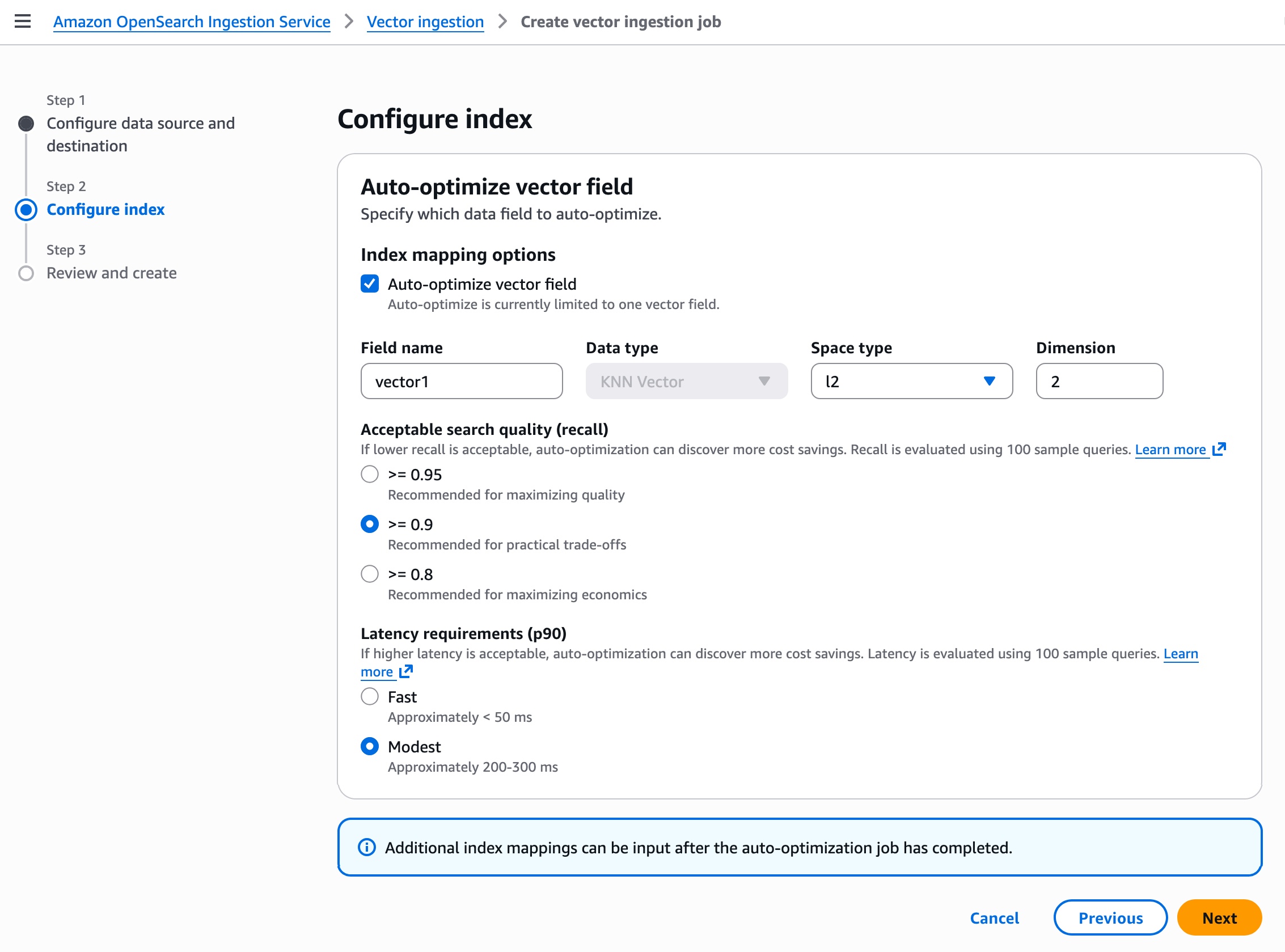
ベクトルフィールドの最適化設定は、ユースケースによって異なります。たとえば、高い検索品質(再現率)が必要で、より高速な応答が不要な場合は、Latency requirements (p90) で Modest を選択し、Acceptable search quality (recall) で 0.9 以上を選択します。ジョブを作成すると、ベクトルデータの取り込みとベクトルインデックスの自動最適化が開始されます。処理時間はベクトルの次元数によって異なります。
詳細については、OpenSearch Service デベロッパーガイドの「Auto-optimize vector index」を参照してください。
提供開始
Amazon OpenSearch Service の GPU アクセラレーションは、米国東部 (バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (シドニー)、アジアパシフィック (東京)、欧州 (アイルランド) リージョンで利用可能になりました。OpenSearch Service の自動最適化は、米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (ムンバイ)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、アジアパシフィック (東京)、欧州 (フランクフルト)、欧州 (アイルランド) リージョンで利用可能になりました。
OpenSearch Service は、ベクトルデータベースのインデックス作成に使用された OCU – Vector Acceleration に対してのみ別途課金されます。詳細については、OpenSearch Service の料金ページをご覧ください。
ぜひお試しいただき、AWS re:Post for Amazon OpenSearch Service または通常の AWS サポート窓口を通じてフィードバックをお寄せください。
— Channy
著者について
 Channy Yun (윤석찬) は、AWS News Blog のリードブロガーであり、AWS Cloud のプリンシパルデベロッパーアドボケイトです。オープンウェブの愛好家であり、根っからのブロガーとして、コミュニティ主導の学習とテクノロジーの共有を大切にしています。
Channy Yun (윤석찬) は、AWS News Blog のリードブロガーであり、AWS Cloud のプリンシパルデベロッパーアドボケイトです。オープンウェブの愛好家であり、根っからのブロガーとして、コミュニティ主導の学習とテクノロジーの共有を大切にしています。