Amazon Web Services ブログ
Amazon Kinesis Data Streams で 10 倍大きなレコードサイズをサポート: リアルタイムデータ処理の簡素化
本記事は 2025年10月28日 に公開された「Amazon Kinesis Data Streams now supports 10x larger record sizes: Simplifying real-time data processing | AWS Big Data Blog」を翻訳したものです。
Amazon Kinesis Data Streams で、レコードサイズの上限が従来の 10 倍となる 10MiB までサポートされるようになりました。この機能強化により、既存の Kinesis Data Streams API をそのまま使用しながら、断続的に発生する大きなデータペイロードをデータストリームに送信できるようになりました。また、PutRecords リクエストの最大サイズも 5MiB から 10MiB に 2 倍に拡大され、IoT 分析、変更データキャプチャ(CDC)、生成 AI ワークロードにおけるデータパイプラインの簡素化と運用オーバーヘッドの削減が実現します。
この記事では、Amazon Kinesis Data Streams の大規模レコードサポートについて、主なユースケース、最大レコードサイズの設定、スロットリングの考慮事項、最適なパフォーマンスのためのベストプラクティスを解説します。
実際のユースケース
データ量の増加とユースケースの進化に伴い、ストリーミングワークロードでより大きなレコードサイズをサポートする需要が高まっています。従来、1MiB を超えるレコードを処理する必要がある場合、以下の 2 つの選択肢がありました。
- プロデューサーアプリケーションで大きなレコードを複数の小さなレコードに分割し、コンシューマーアプリケーションで再構成する
- 大きなレコードを Amazon Simple Storage Service (Amazon S3) に保存し、メタデータのみを Kinesis Data Streams 経由で送信する
これらのアプローチは有用ですが、データパイプラインに複雑さを加え、追加のコードが必要となり、運用オーバーヘッドが増加し、特に断続的に大きなレコードをストリーミングする必要がある場合にエラー処理やデバッグが複雑になります。
この機能強化により、さまざまな業界やユースケースで断続的なデータペイロードを扱うお客様の使いやすさが向上し、運用オーバーヘッドが削減されます。IoT 分析の分野では、コネクテッドカーや産業機器が生成するセンサーテレメトリデータの量が増加しており、個々のテレメトリレコードのサイズが従来の Kinesis の 1MiB 制限を超えることがあります。これにより、お客様は大きなレコードを複数の小さなレコードに分割したり、大きなレコードを別途保存してメタデータのみを Kinesis 経由で送信するなど、複雑な回避策を実装する必要がありました。同様に、データベースの変更データキャプチャ(CDC)パイプラインでは、特に一括操作やスキーマ変更時に大きなトランザクションレコードが生成されることがあります。機械学習と生成 AI の分野では、より豊富な特徴セットや音声・画像などのマルチモーダルデータタイプをサポートするために、より大きなペイロードの取り込みが求められるようになっています。Kinesis のレコードサイズ制限が 1MiB から 10MiB に引き上げられたことで、これらの複雑な回避策の必要性が軽減され、IoT、CDC、高度な分析のユースケースにおけるデータパイプラインの簡素化と運用オーバーヘッドの削減が実現します。お客様は、使い慣れた Kinesis API を使用して、これらの断続的な大規模データレコードをより簡単に取り込み、処理できるようになりました。
仕組み
より大きなレコードの処理を開始するには:
- AWS コンソール、AWS CLI、または AWS SDK を使用して、ストリームの最大レコードサイズ制限(
maxRecordSize)を更新します。 - プロデューサーでは引き続き同じ
PutRecordおよびPutRecordsAPI を使用します。 - コンシューマーでは引き続き同じ
GetRecordsまたはSubscribeToShardAPI を使用します。
ストリームは数秒間 Updating ステータスになった後、より大きなレコードを取り込む準備が整います。
使用開始
Kinesis Data Streams でより大きなレコードの処理を開始するには、AWS マネジメントコンソール、CLI、または SDK を使用して最大レコードサイズを更新できます。
AWS マネジメントコンソールでの手順:
- Kinesis Data Streams コンソールに移動します。
- ストリームを選択し、設定タブを選択します。
- 最大レコードサイズの横にある編集を選択します。
- 希望する最大レコードサイズ(最大 10MiB)を設定します。
- 変更を保存します。
注意:この設定は、この Kinesis データストリームの最大レコードサイズのみを調整します。この制限を引き上げる前に、すべてのダウンストリームアプリケーションがより大きなレコードを処理できることを確認してください。
Kinesis Client Library(バージョン 2.x 以降)、Amazon Data Firehose から Amazon S3 への配信、AWS Lambda など、一般的なコンシューマーのほとんどは 1MiB を超えるレコードの処理をサポートしています。詳細については、大規模レコードに関する Amazon Kinesis Data Streams のドキュメントを参照してください。
AWS CLI を使用してこの設定を更新することもできます:
または AWS SDK を使用する場合:
スロットリングと最適なパフォーマンスのためのベストプラクティス
大規模レコードのサポートにおいても、個々のシャードのスループット制限(書き込み 1MiB/秒、読み取り 2MiB/秒)は変更されません。大規模レコードを扱うために、スロットリングの仕組みを理解しましょう。ストリーム内の各シャードは 1MiB/秒のスループット容量を持っています。大規模レコードに対応するため、各シャードは一時的に最大 10MiB/秒までバーストし、最終的には平均 1MiB/秒に収束します。この動作を視覚化するために、各シャードが 1MiB/秒で補充される容量タンクを持っていると考えてください。大きなレコード(例えば 10MiB のレコード)を送信した後、タンクはすぐに補充を開始し、容量が利用可能になるにつれて小さなレコードを送信できるようになります。大規模レコードをサポートするこの容量は、ストリームに継続的に補充されます。補充速度は、大規模レコードのサイズ、ベースラインレコードのサイズ、全体的なトラフィックパターン、選択したパーティションキー戦略によって異なります。大規模レコードを処理する際、各シャードはバースト容量を活用してこれらの大きなペイロードを処理しながら、ベースライントラフィックの処理を継続します。
Kinesis Data Streams が異なる割合の大規模レコードをどのように処理するかを説明するために、簡単なテストの結果を見てみましょう。テスト構成として、オンデマンドストリーム(デフォルトで 4 シャード)に 1 秒あたり 50 レコードの速度でデータを送信するプロデューサーを設定しました。ベースラインレコードは 10KiB、大規模レコードは 2MiB です。大規模レコードの割合を総ストリームトラフィックの 1% から 5% まで段階的に増加させる複数のテストケースと、大規模レコードを含まないベースラインケースを実施しました。一貫したテスト条件を確保するため、大規模レコードを時間的に均等に分散させました。例えば、1% のシナリオでは、100 件のベースラインレコードごとに 1 件の大規模レコードを送信しました。以下のグラフは結果を示しています:
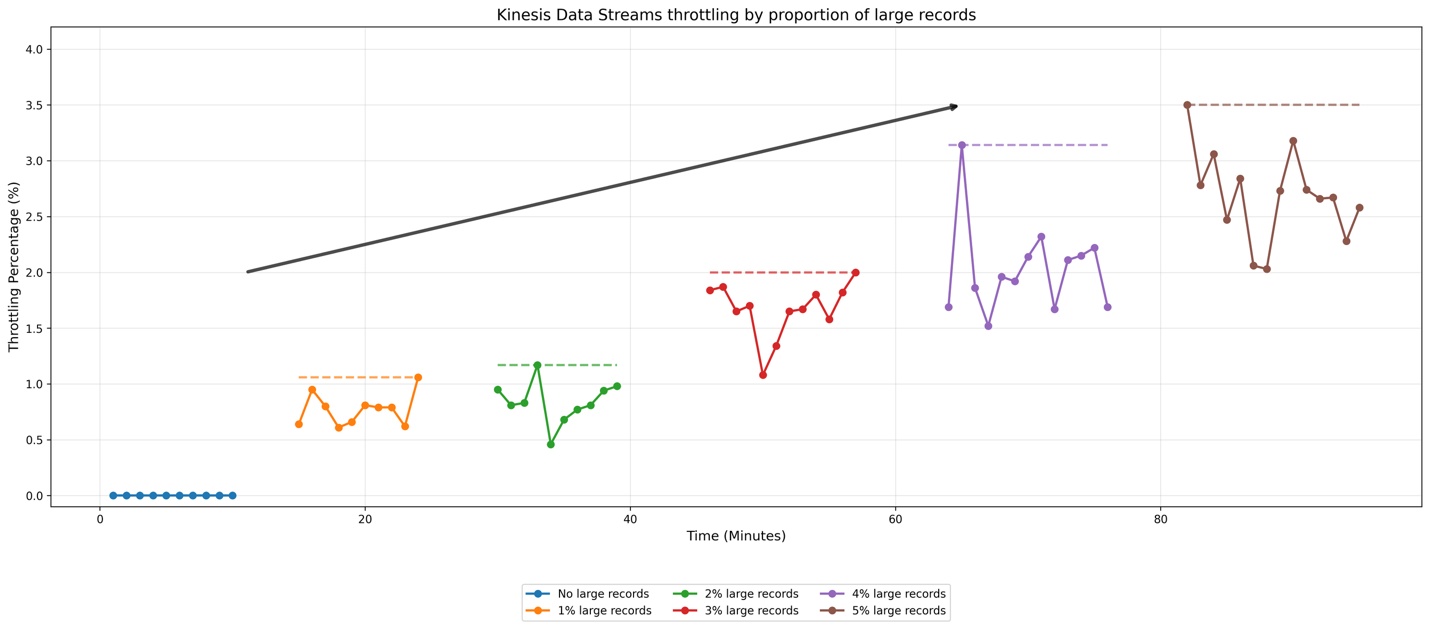
グラフでは、水平方向の注釈がスロットリング発生のピークを示しています。青い線で表されるベースラインシナリオでは、スロットリングイベントは最小限です。大規模レコードの割合が 1% から 5% に増加するにつれて、ストリームがデータをスロットリングする頻度が増加し、2% と 5% のシナリオ間でスロットリングイベントが顕著に加速しています。このテストは、Kinesis Data Streams が増加する大規模レコードの割合をどのように管理するかを示しています。
最適なパフォーマンスのために、大規模レコードを総レコード数の 1〜2% に維持することをお勧めします。本番環境では、実際のストリーム動作は、ベースラインレコードのサイズ、大規模レコードのサイズ、大規模レコードがストリームに出現する頻度という 3 つの主要な要因に基づいて異なります。特定の動作を判断するために、実際の需要パターンでテストすることをお勧めします。
オンデマンドストリームでは、シャードあたりの受信トラフィックが 500 KB/秒を超えると、15 分以内にシャードが分割されます。親シャードのハッシュキー値は子シャードに均等に再分配されます。Kinesis はストリームを自動的にスケーリングしてシャード数を増やし、採用されているパーティションキー戦略に応じて大規模レコードをより多くのシャードに分散できるようにします。
大規模レコードで最適なパフォーマンスを得るために:
- ランダムなパーティションキー戦略を使用して、大規模レコードをシャード間で均等に分散させます。
- プロデューサーアプリケーションにバックオフとリトライロジックを実装します。
- シャードレベルのメトリクスを監視して、潜在的なボトルネックを特定します。
大規模レコードを継続的にストリーミングする必要がある場合は、Amazon S3 を使用してペイロードを保存し、メタデータ参照のみをストリームに送信することを検討してください。詳細については、Amazon Kinesis Data Streams での大規模レコードの処理を参照してください。
まとめ
Amazon Kinesis Data Streams で、レコードサイズの上限が従来の 1MiB から 10 倍の 10MiB までサポートされるようになりました。この機能強化により、複雑な回避策が不要になり、IoT 分析、変更データキャプチャ、AI/ML ワークロードのデータパイプラインが簡素化されます。既存の Kinesis Data Streams API をコード変更なしでそのまま使用でき、断続的な大規模ペイロードの処理における柔軟性が向上します。
- 最適なパフォーマンスのために、大規模レコードを総レコード数の 1〜2% に維持することをお勧めします。
- 大規模レコードで最良の結果を得るには、均等に分散されたパーティションキー戦略を実装してレコードをシャード間で均等に分散させ、プロデューサーアプリケーションにバックオフとリトライロジックを含め、シャードレベルのメトリクスを監視して潜在的なボトルネックを特定してください。
- 最大レコードサイズを引き上げる前に、すべてのダウンストリームアプリケーションとコンシューマーがより大きなレコードを処理できることを確認してください。
この機能を活用して、より強力で効率的なストリーミングアプリケーションを構築されることを楽しみにしています。詳細については、Amazon Kinesis Data Streams のドキュメントをご覧ください。
著者について
 Sumant Nemmani は Amazon Kinesis Data Streams のプロダクトマネージャーです。お客様から学ぶことに情熱を持ち、AWS で価値を引き出すお手伝いをすることを楽しんでいます。仕事以外では、バンド Project Mishram で音楽を作ったり、旅行中に歴史や食べ物を探索したり、テクノロジーや歴史に関する長編ポッドキャストを聴いたりしています。
Sumant Nemmani は Amazon Kinesis Data Streams のプロダクトマネージャーです。お客様から学ぶことに情熱を持ち、AWS で価値を引き出すお手伝いをすることを楽しんでいます。仕事以外では、バンド Project Mishram で音楽を作ったり、旅行中に歴史や食べ物を探索したり、テクノロジーや歴史に関する長編ポッドキャストを聴いたりしています。
 Umesh Chaudhari は AWS のシニアストリーミングソリューションアーキテクトです。お客様と協力してリアルタイムデータ処理システムの設計と構築を行っています。データ分析システムのアーキテクチャ設計、設計、開発を含むソフトウェアエンジニアリングの豊富な経験を持っています。仕事以外では、旅行やテクノロジートレンドのフォローを楽しんでいます。
Umesh Chaudhari は AWS のシニアストリーミングソリューションアーキテクトです。お客様と協力してリアルタイムデータ処理システムの設計と構築を行っています。データ分析システムのアーキテクチャ設計、設計、開発を含むソフトウェアエンジニアリングの豊富な経験を持っています。仕事以外では、旅行やテクノロジートレンドのフォローを楽しんでいます。
 Pratik Patel はシニアテクニカルアカウントマネージャーであり、ストリーミング分析のスペシャリストです。AWS のお客様と協力し、ベストプラクティスを使用したソリューションの計画と構築を支援する継続的なサポートと技術ガイダンスを提供し、お客様の AWS 環境を運用上健全に保つことに積極的に取り組んでいます。
Pratik Patel はシニアテクニカルアカウントマネージャーであり、ストリーミング分析のスペシャリストです。AWS のお客様と協力し、ベストプラクティスを使用したソリューションの計画と構築を支援する継続的なサポートと技術ガイダンスを提供し、お客様の AWS 環境を運用上健全に保つことに積極的に取り組んでいます。
この記事は Kiro が翻訳を担当し、ソリューションアーキテクト の 榎本 貴之 がレビューしました。