Amazon Web Services ブログ
Amazon Forecast が一般公開されました
履歴データを基に正確な時系列予測を得るのは、たやすい作業とは言えません。当社は昨年の re:Invent において Amazon Forecast を発表しました。これは、機械学習についてまったく経験がない人でも高い精度の予測をすることができる、完全マネージド型のサービスです。 その Amazon Forecast が一般公開されたことを、本日お伝えできるのは非常に喜ばしいことです。
Amazon Forecast では、サーバーのプロビジョニングは必要ありません。 これに必要なのは、履歴データ、そして予測結果に影響がありそうなメタデータを追加で揃えることだけです。たとえば、入手するか製造しようとしている特定の製品に関する需要は、天候、季節、そしてその製品が使用される土地などにより、おそらく変わってくるでしょう。
Amazon Forecast は、Amazon で使われているものと同じテクノロジーをベースにしており、スケーラブルで高い精度を持つ予測技術を使いやすく構築および運用するための、長年の経験を詰め込んだものとなっています。これは複数のデータセットを基に深層学習 を行い、多様なアルゴリズムを自動的に切り替えて使用するので、製品需要、クラウドのコンピューティング使用量、財務計画、サプライチェーン管理システムでのリソース管理など多くのユースケースに対応できます。
Amazon Forecast を使ってみる
今回の記事では、いくつかのサンプルデータを利用します。興味深いユースケースが良いので、今回はUCI の機械学習レポジトリが提供する、個別家庭の電力消費データセットを使うことにします。作業を簡単にするため、時間ごとのデータが CSV 形式のファイルに集められたバージョンを使っていきます。次に示すのはこのデータの最初の数行で、ここにはタイムスタンプ、電力消費量、クライアント ID が記述されています。
2014-01-01 01:00:00,38.34991708126038,client_12 2014-01-01 02:00:00,33.5820895522388,client_12 2014-01-01 03:00:00,34.41127694859037,client_12 2014-01-01 04:00:00,39.800995024875625,client_12 2014-01-01 05:00:00,41.044776119402975,client_12
それでは、Amazon Forecast コンソールを使いながら、予測子の構築と予測値の取得がいかに簡単かを確かめてみましょう。より進んだユーザーのためのオプションは、Jupyter ノートブックと AWS SDK for Python から利用できます。この GitHub レポジトリにサンプルのノートブックがいくつかあります。
Amazon Forecast コンソールで先ず最初に行うステップは、データセットグループの作成です。データセットグループは、お互いに関連のあるデータのためのコンテナーとして機能します。
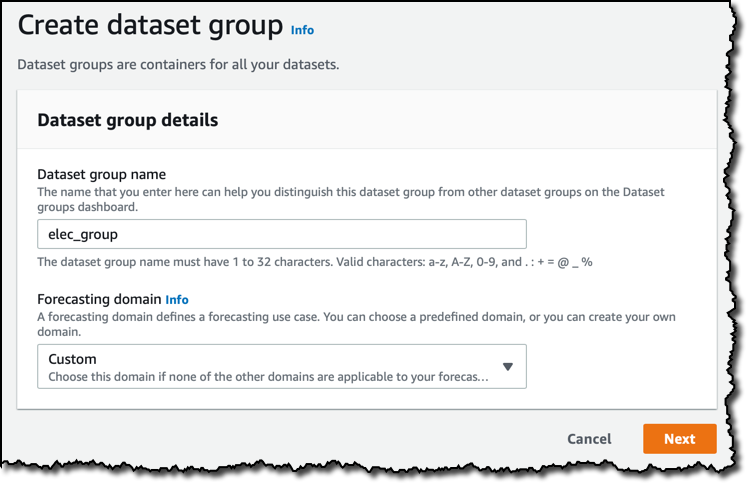
データセットグループに合わせて、[Forecasting domain] から一つを選択します。各ドメインは、小売り、在庫計画、ウェブのトラフィックなど、それぞれ特定のユースケースに対応しています。また、そのトレーニングに使われたデータ形式を基にしたデータセットタイプを使用します。今回は、帰属するカテゴリーがないすべてのユースケースをカバーしている、[Custom] ドメインを使用しましょう。
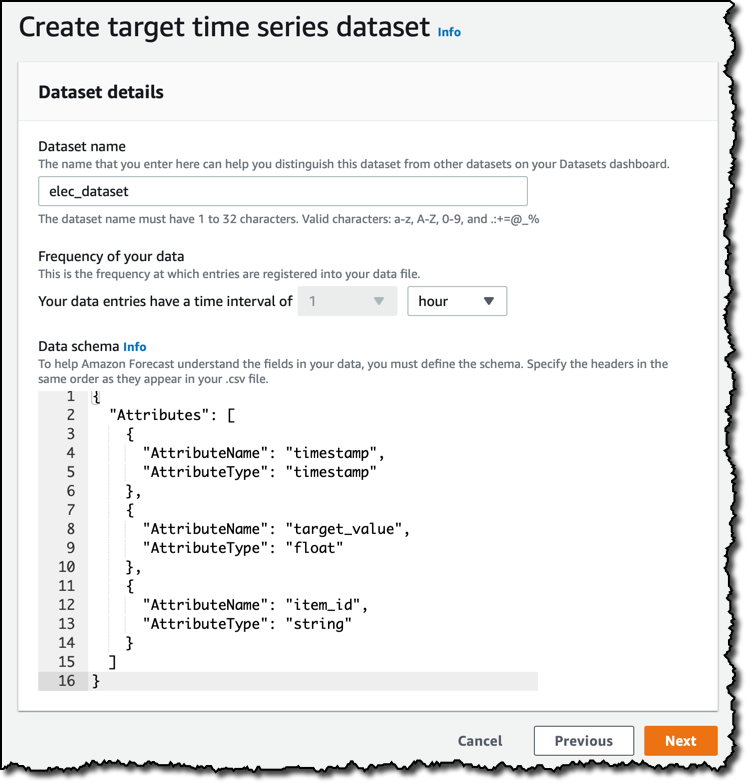
次に行うのは、データセットの作成です。今アップロードしようとしているデータは時間ごとに集められたものですので、[Frequency of your data] では 1 hour を設定します。[Data schema] にデフォルトで表示されている内容は、先に [Forecasting domain] で選択した内容に従っています。 使用しているのが Custom ドメインですから、[Data schema] には、timestamp、target_value、item_id を含むように変更します。この順序は、この記事の最初でご覧にいれた数行のサンプルデータと同じです。
この状態で、時系列データを Amazon Simple Storage Service (S3) からデータセットへとアップロードします。デフォルトのタイムスタンプ形式は、使用するデータのものと一致していますから、修正の必要はありません。Amazon Forecast にS3 バケットへのアクセス許可を付与するためには、AWS Identity and Access Management (IAM) ロールが必要です。ロールは、ここでどれかを選択することも、このユースケース用に新しく作成することもできます。普段と同様に、寛容すぎる IAM ロールを作成することは避け、権限を今回の処理が必要とする最小限に留めるため、最小権限 のアプローチをすることにします。履歴データを検索する S3 バケットとフォルダーを Amazon Forecast に設定した後、ジョブのインポートを行います。
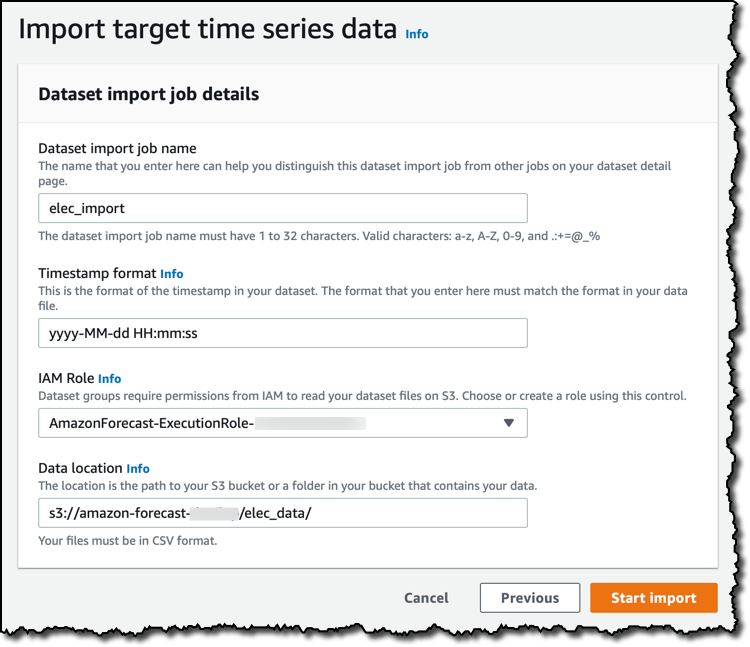
データセットグループの ダッシュボード に、この処理の概要が表示されます。ターゲットの時系列データがインポートされる間、次のようなオプションの追加もできます。
- 予測対象とするアイテムに関するアイテムのメタデータ情報。例として、販売シナリオごとに分けたアイテムの色、あるいは今回の電力消費予測のユースケースでは家庭の形態 (アパート住まいか戸建てか?) などがこれにあたります。
- 予測の対象となる数値は含まないもののモデルの改善に役立つ関連時系列データ。たとえば、E コマース企業が採用する価格とプロモーションは、実際の売り上げと関係性があるでしょう。

今回のユースケースには、これ以上追加するべき事項はありません。データセットのインポートが完了すれば、予測子のトレーニングを開始し、その後で予測を実施することができます。[Predictor name] に名前を入力した後、今回のケースでは [Forecast horizon] に [24 hours] を、[Forecast frequency] には予測を行いたい時間間隔を選択します。
予測子のトレーニングをする際は、ARIMA や DeepAR+ など、特定の 機械学習アルゴリズム を好みに合わせて選択することもできますが、シンプルな方が良いので AutoML を使うことにします。これで、Amazon Forecast がすべてのアルゴリズムを評価し、最良のパフォーマンスのものを自動的に選択してくれます。
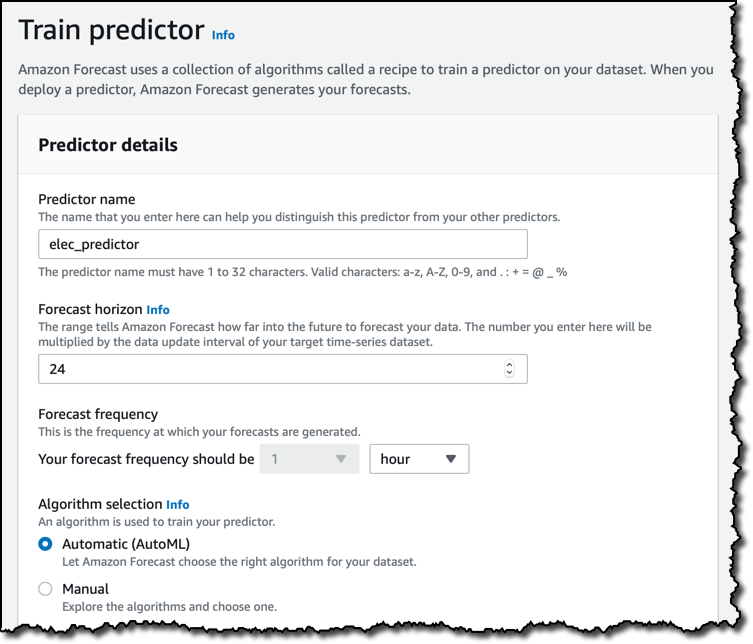
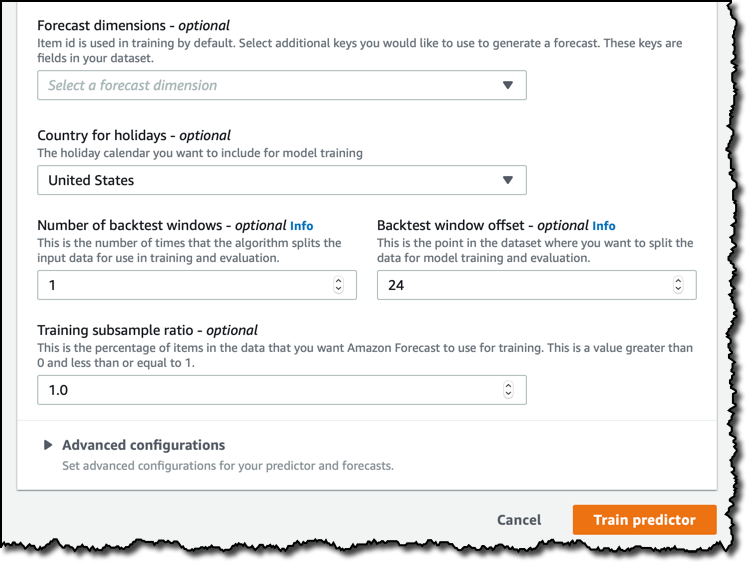
今回のデータセットでは、各家庭は item_id という 1 つの数値で判別されていますが、必要であればさらにディメンションを増やすこともできます。たとえば、休日を指定するために国を選択することも可能です。これはオプションですが、人々が休日を過ごしているかどうかが影響を与えるデータを使用している場合、結果を改善し得る要素です。電力消費は休日によって変動すると思われますので、ここでは、使用するデータが取得された国である [United States] を選択します。
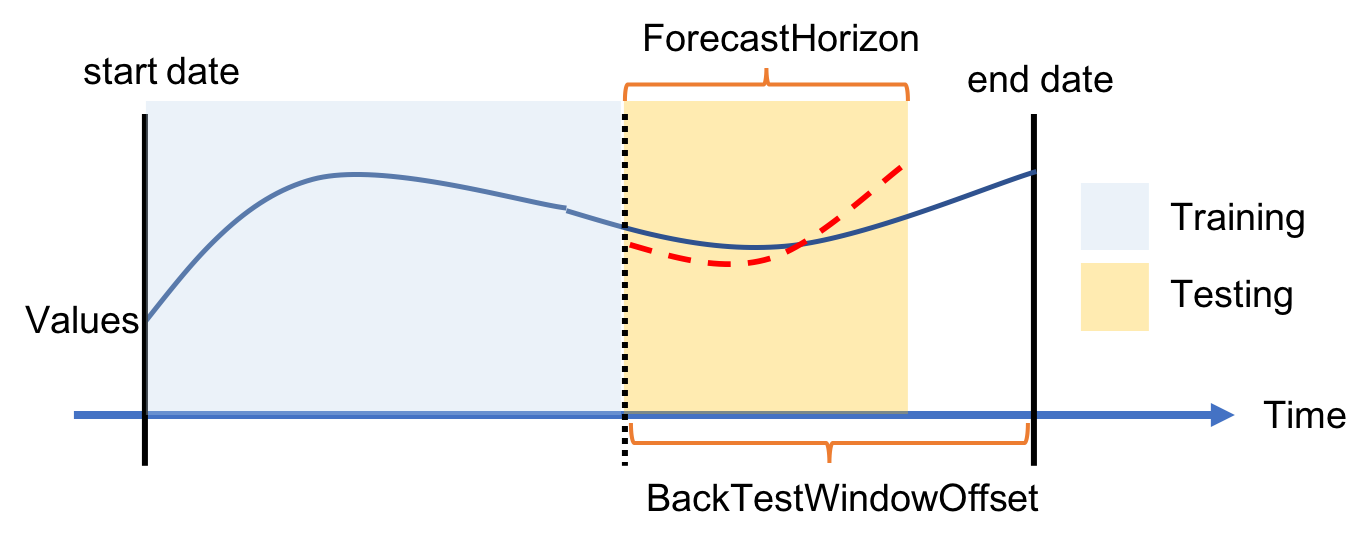
バックテストウィンドウでの設定はさらに進んだトピックです。そして、時系列を扱う機械学習がどのように評価されるかについて特別の関心がない場合は、次の段落をスキップしていただいてかまいません。今回はデフォルトのままにしておきます。
機械学習モデルのトレーニングを行うには、データセットを次のような 2 つに分割する必要があります。1 つはトレーニングデータセットで、機械学習アルゴリズムのトレーニングに使います。もう 1 つは、評価データセットで、トレーニングしたモデルのパフォーマンス評価に使用します。時系列データからは、これらのサブセットを一般で行うようにランダムに取り出すことはできません。各データポイントの順番が重要だからです。Amazon Forecast では、時系列データを 1 つ以上のパーツに分割する手法を取っており、データの順番を維持しているこれらのパーツは バックテストウィンドウと呼ばれます。バックテストウィンドウに対するモデルの評価を行う際は、常に同じ長さの評価用データセットを使う必要があります。そうしないと結果が整合せず、比較がとても困難になるからです。 [Backtest window offset] は評価に使っているデータの分割点までいくつのデータポイントがあるのかを示します。この数値は、すべての分割データ内で同じになります。たとえば、他のウィンドウオフセットを選ばず 24 (時間) のままにしておくと、モデルの評価は常に 1 日分のデータを使うようになります。
進んだ設定項目では、それをサポートしているアルゴリズムのための [hyperparameter optimization (HPO)] や、データの内容からさらに情報を算出するための [featurizations] などのオプションを有効化できます。今回は、これらの設定には触りません。
数分間すると予測子がアクティブになります。この予測子の性能を確認するため、自動的に算出されているメトリックをいくつか見てみます。

Quantile loss (QL) は、現実の需要から特定の分位における予測値がどの程度離れているかを算出した値です。この数値は、特定の分位における過小評価と過大評価に重みを付けます。たとえば P90 forecast として検出された値は、90% の時間において現実の需要が予測値より下回っていることを意味します。実際の需要が予測値を上回ってしまうと、逆の場合に比べて損失は大きくなり得ます。
予測子の準備ができて、テスト結果が満足いくものとなったら、それを使い予測の作成を行います。

予測がアクティブになれば、クエリを送って結果を得ることができます。CSV ファイルとして予測結果全体をエクスポートすることや、特定のルックアップにクエリを送ることができます。ここではルックアップを使てみましょう。ここで使用するデータセットでは、指定した時間帯における家庭での電力消費量を予測することができます。使っているデータセットが古いため、日付は過去のものとなります。もちろん、皆さんは未来を予測するために、Amazon Forecast をご利用になることでしょう。

予測結果での各タイムスタンプについて、いくつかの値を見る事ができます。ここでの P10、P50、P90の数値は、それぞれ 10%、50%、90% の確立で、実際の需要量に合致します。これらを利用する方法は、使っているユースケースと、需要に対する過小および過大な予測がどう影響するかにより変わってきます。P50 の予測値が、実際の需要にもっとも近いと考えられます。P10 と P90 の予測値は、期待する値に対して 80% の信頼区間にあります。

今すぐ利用可能です
Amazon Forecast は、コンソールを使う他に、AWS Command Line Interface (CLI)、AWS SDKs などからも利用いただけます。Amazon Forecast の使用例として、AWS SDK for Python を使う Jupyter ノートブックでは新しい予測子の作成が行えたり、ブラウザ内の AWS SDK for JavaScript からはウェブやモバイルのアプリが予測結果を取得することができます。さらに、既存のエンタープライズアプリケーションに、AWS SDK for Java もしくは AWS SDK for .NET を使って予測機能を追加することも可能です。
データセットグループの作成から予測結果の照会と取得までのAmazon Forecast API に関する作業の流れを、次の図に示します。

今回の一連の作業に使ったデータセットとその他のサンプルは、次の GitHub レポジトリで入手可能です。
現在 Amazon Forecast は、米国東部 (バージニア北部)、米国西部 (オレゴン)、米国東部 (オハイオ)、欧州 (アイルランド)、アジアパシフィック (シンガポール)、アジアパシフィック (東京) で利用できます。
機能上の特色と料金についての詳細情報は、次のリンクをクリックしてご覧ください。
皆様がこの機能を利用されることを楽しみにしています。結果が出たらお知らせいただけると幸いです。
— Danilo