Amazon Web Services ブログ
Amazon Aurora under the hood: Z-order curvesを用いたgeospatial indexの作成
Amazon Auroraのような高性能データベースシステムを設計する場合、一般的に最も幅広いワークロードを大きく改善出来るように取り組みたいと考えるかと思います。しかし時には、ゲームチェンジャーになりえる機会がある場合、特別な用途向けに改善を行うこともあります。
geospatial indexとはなにか、なぜ考慮する必要があるのか?
地理空間分析では、XY(Z)座標に沿った近さ、隣接性、重なりを識別することができます。
そのような分析を実行する必要があるアプリケーションには様々な例があります。タクシーアプリでは、利用可能な最寄りのタクシーを見つけることができます。不動産アプリは、サンフランシスコのPacific Heights地区で販売されている物件を探すことができます。
空間分析は、他にも多くの用途でも役立ちます:
- マーケティング – 店舗から2マイル以内のすべての見込み顧客をターゲットにプロモーションを行います
- 資産管理 – 顧客の位置と密度に基づいて影響を最小限に抑えるために修理ユニットを配置します
- リスク分析 – 顧客の居住地や職場の近くで車の盗難が発生した場合のリスクを見積もります
- 詐欺検出 – 前回のトランザクションからの距離に基づいて詐欺と考えられる取引の可能性を推定します
- ロジスティクス計画 – 運行の範囲を最小限にするように、トラブルのチケットを現場の技術者に割り当てます
これらのアプリケーションは、高性能な空間データのインデックスから利益を得ることができます。残念なことに、Bツリーのような伝統的なインデックスは、Linlandのために作られたものであり、FlatlandやSpacelandではそうではありません。そのため、高性能な空間インデックスが必要です。
Rツリーとは?
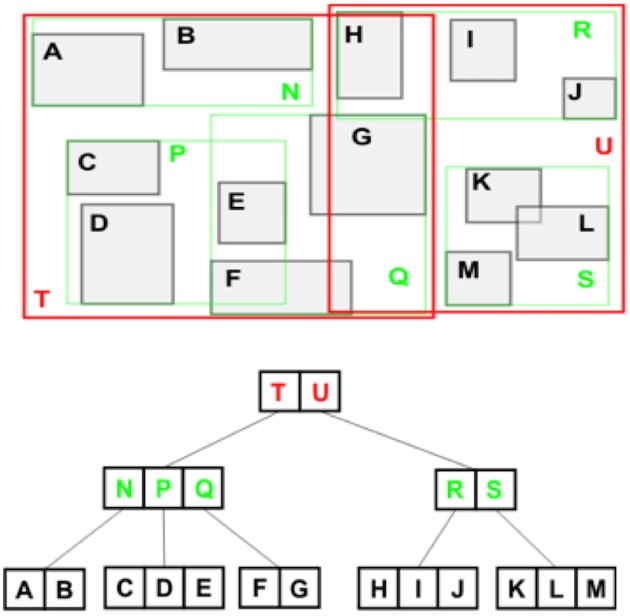
最も一般的に使用される空間インデックスはRツリーです(詳細はこちらの論文を参照してください)。 MySQLとOracleはどちらもR-treeを使用しています。基本的な考え方は、バランスサーチツリーないにバウンダリーレクタングルを保存することです。リーフはデータポイントであり、各内部ノードは、その下のノードのミニマムバウンダリーレクタングルです。したがって、次の例では、長方形Aはリーフノードです。このノードは、矩形NおよびTによって順番に境界が作成されます。
Rツリーの主な問題は、安定していないことです(つまり、決定論的です)。挿入順序が異なると、異なるツリーが生成され、パフォーマンスの特性が大きく異なります。私たちのテストでは、ランダムな挿入順序では、最適な順序で構築されたツリーよりも1桁も性能が劣化したツリーが生成されました。これは、データの挿入順序が予測できず、変更可能なOLTP環境では明らかに問題になります。このような状況では、Rツリーは時間とともに性能が劣化します。1つの回避策は、データを定期的にインデックスを再構築することです。しかし、インデックスの再構築は負荷がかかります。加えて通常この作業は、手作業が必要であり、数時間かかることがあります。また、その期間中の他のトランザクションは遅くなる可能性があります。
そのため、Rツリーは人気がありますが、常に良好なパフォーマンスは得られません。
他にいい方法はあるのか?
私たちはそう考えています!トランザクションと同時実行に最適なデータ構造があります。それはBツリーです。 あらゆる場面で使用され、高いパフォーマンスを発揮するのはデータベースにとって基本です。
しかし、ちょっと待ってください。私はB-treeが多次元データに対してうまく機能しないと言いました。それは本当です。2次元を1次元にマップするトリックがあります。
私たちは、space-filling z-order curves(空間充填zオーダー曲線)を使用して行います。これは、ポイントのz値は、その座標値のバイナリ表現をインターリーブすることによって計算されます。zオーダー曲線は、これらの点をz値の順に横切る線です。たとえば、次の図は、0≤x≤7、0≤y≤7の整数座標の場合のz値を示しています(10進数と2進数の両方を示しています)。
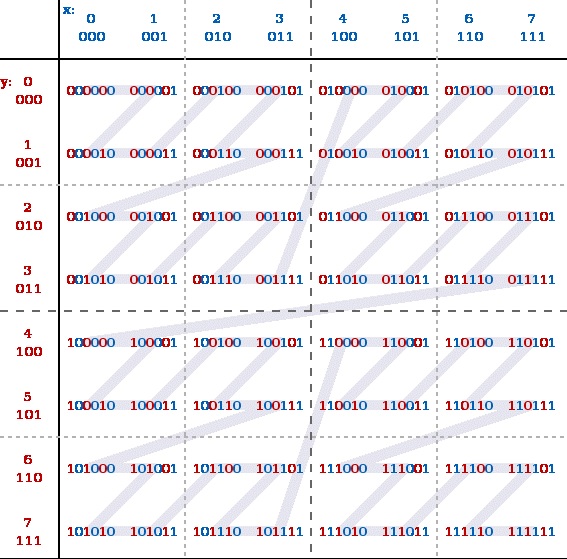
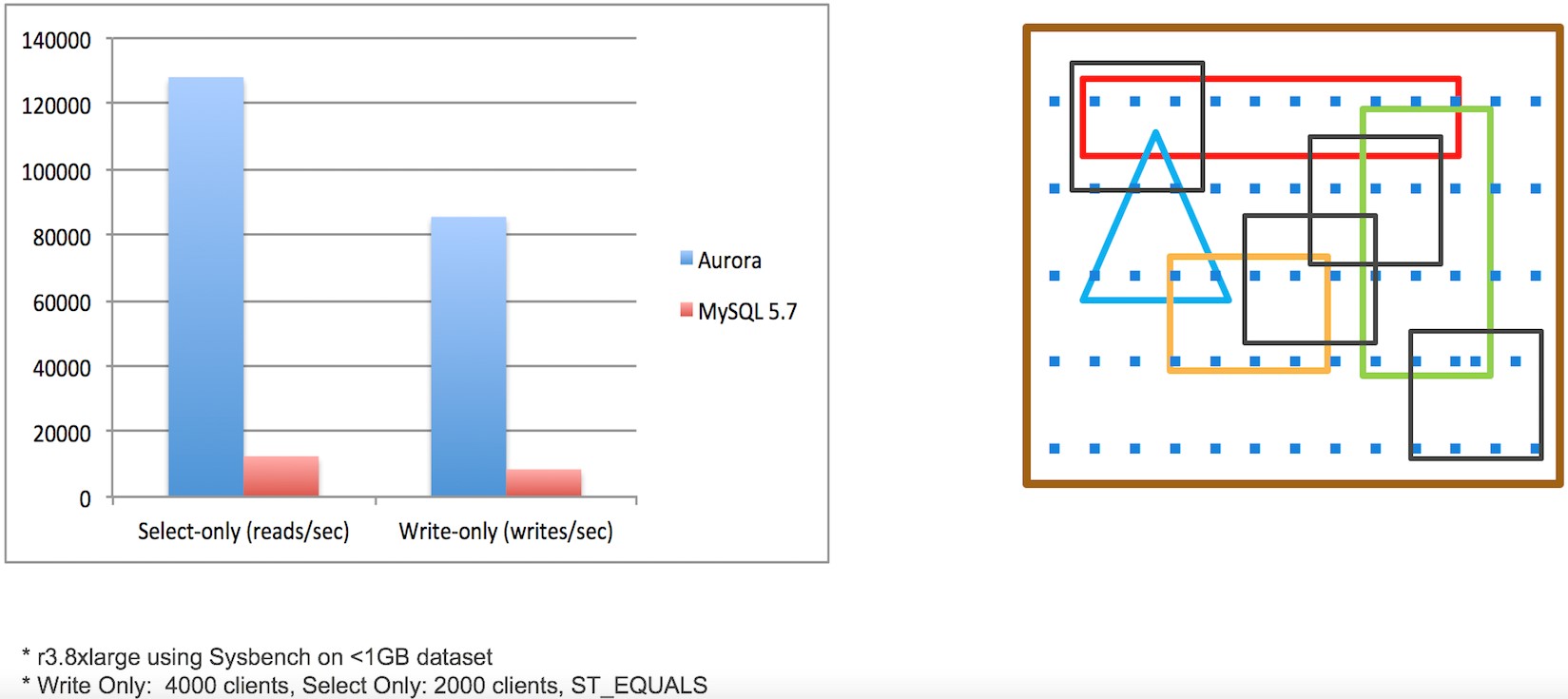
zオーダー曲線上のBツリーの単純な実装では不十分です。なぜこれが当てはまるのかを知るために、以下の例を見てみましょう。緑色の四角形内のすべての点をBツリーで検索すると、クエリー領域外に30個の余分なz値(黄色い三角形の警告標識が付いている物)がスキャンされます。

元のクエリをより少ない偽陽性z値をカバーする小さなクエリに分割することで、この問題を改善します。(これを行うために幾つかの方法を使用していますが、それはこの記事でお伝えする範囲を超えています)
それは私たちがポイントするために必要なものすべてを提示します。ポリゴンはどのように空間充填曲線で動作するのでしょうか?ポリゴンが単一点のように見えるまでズームアウトしたとします。どの程度ズームアウトしなければならないかは、ポリゴンの”レベル”によります。各空間オブジェクトは、オブジェクトのレベルとzアドレスの組み合わせとしてBツリーに格納されます。zアドレスがポイントのように見えるまでズームアウトしたので、zアドレスをポイントのように扱うことができます。他のシステムでは、このレベルを手動で指定する必要があります。明らかに、予測不可能で変更可能なデータを扱うOLTPシステムでは動作しません。このレベルはユーザーの設定なしで自動的に設定します。
Auroraのgeospatial indexesは、MySQL 5.7よりもselect-only(1秒当たりの読み込み回数)ワークロードで10倍以上、write-only(1秒当たりの書き込み回数)で20倍以上優れています。具体的には、サイズが1 GB未満のデータセットでSysbenchを使用して、AuroraとAmazon RDS for MySQL 5.7をdb.r3.8xlargeインスタンスを用いて計測しました。select-onlyのテストでは、2,000クライアントとST_EQUALSクエリを使用しました。write-onlyテストでは、4,000のクライアントを使用しました。
ご質問がある場合は、aurora-pm@amazon.comまでご連絡ください。
About the Author
 Sirish Chandrasekaran is a product manager for Amazon Aurora at Amazon Web Services.
Sirish Chandrasekaran is a product manager for Amazon Aurora at Amazon Web Services.
翻訳は星野が行いました。(原文はこちら)