Blog AWS Indonesia
Praktik Terbaik Ketersediaan Amazon ECS
Kami di AWS menghabiskan banyak waktu memikirkan mengenai ketersediaan. Sangat penting bahwa layanan kami tetap tersedia bahkan pada kegagalan parsial yang tak terhindarkan, dalam rangka memberikan kemampuan pada pelanggan kami untuk mendapatkan wawasan dan melakukan tindakan perbaikan. Untuk mencapai hal ini, kami mengandalkan pada ketersediaan yang diberikan pada kami oleh keterlepasan Regional dan isolasi Availability Zone.
Secara konkret hal ini berarti bahwa layanan ECS control plane (layanan yang memberikan kemampuan manajemen ECS ke pelanggan kami) untuk tidak memiliki ketergantungan layanan di luar Region tempat kami beroperasi untuk menghindari dampak multi-region. Sebagai tambahan kami memastikan bahwa kami mendistribusikan layakan kami secara merata setidaknya pada tiga Availability Zone dalam suatu Region selama itu memungkinkan. Tidak semua layanan membutuhkan tingkat ketersediaan seperti ini. Di sini kami membahas mengenai praktek terbaik berdasarkan pengalaman kami untuk beban kerja yang berjalan pada ECS yang memang membutuhkan tingkat ketersediaan seperti ini.
Alasan kami mendukung tiga Availability Zone adalah biaya, pertukaran terhadap ketersediaan. Layanan yang membutuhkan ketersediaan tinggi memerlukan sejumlah redundansi. Layanan pada umumnya berjalan pada pemanfaatan optimal secara stabil, yang mencakup adanya ruang cadangan untuk menyerap ledakan dan untuk layanan dengan ketersediaan tinggi, ruang cadangan ini juga perlu untuk memperhitungkan penyerapan beban failover. Semakin besar radius ledakan dari sebuah kegagalan dalam mengurangi kapasitas ketersediaan, semakin besar ruang cadangan yang dibutuhkan untuk menyerapnya. Hal ini menurunkan penggunaan yang stabil pada satu server karena adanya kebutuhan untuk tambahan ruang cadangan untuk menangani kegagalan dan secara lebih jauh meningkatkan biaya. Contohnya, mari kita asumsikan sebuah beban kerja membutuhkan 60 host untuk melayani permintaan dengan optimal.
Kami membutuhkan 120 host untuk memastikan kapasitas yang memadai pada kejadian kegagalan dari Availability Zone jika layanan kami berjalan pada dua Availability Zone, yang berarti biayanya berganda. Namun, jika layanan kami berjalan pada tiga Availability Zone, kami hanya membutuhkan 90 host untuk mencapai profil ketersediaan yang sama. Kami melihat pengurangan biaya yang berkelanjutan dan penggunaan yang meningkat dengan menambah lebih banyak Availability Zone (bila memungkinkan) tetapi hasilnya berkurang dengan cepat dan kognitif berlebih meningkat. Untuk layanan internal ECS, kami telah menetapkan tiga Availability Zone, sebuah nilai yang didukung pada sebagian besar Region AWS.
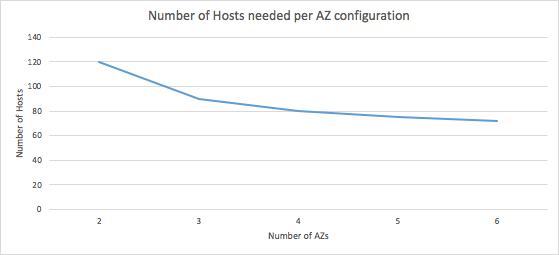
Jadi bagaimana arti semua ini untuk konfigurasi ECS Anda? Ketika melihat pada penyediaan kapasitas untuk klaster ECS Anda, adalah penting untuk mempertimbangkan kebuthan terhadap ketersediaan layanan Anda. Tiga penyebaran Availability Zone dari instans EC2 dalam klaster Anda memberikan keseimbangan yang baik atas ketersediaan dan biaya dengan mengurangi penggunaan optimal yang stabil untuk rasio ruang cadangan sambil tetap memenuhi tujuan ketersediaan. Persyaratan kapasitas lebih rendah yang dihasilkan dapat memberikan kesempatan untuk mendapatkan penghematan dengan pengukuran yang tepat atas pemilihan tipe instan EC2 Anda pada dua Availability Zone. Sebuah kesempatan penghematan biaya lainnya melalui pemanfaatan platform EC2 dengan kemampuan burst.
Melalui pengukuran yang tepat platform Anda untuk kestabilan yang optimal dengan ruang cadangan, Anda mungkin berada pada posisi untuk memanfaatkan kemampuan burst dari platform T3 untuk menyerap sebgaian porsi dari potensi beban failover sehingga mengurangi biaya ruang cadangan dan hanya membayar untuk itu jika diperlukan. Ketika didukung oleh sebuah kelompok penskalaan otomatis (Auto Scaling Group) EC2, yang akan memastikan bahwa kapasitas yang hilang digantikan, hal ini bisa menjadi mekanisme penghematan biaya yang sangat meyakinkan sambil tetap memenuhi tujuan dari ketersediaan Anda. AWS merekomendasikan untuk melakukan pengukuran kinerja (benchmarking) atas layanan Anda, termasuk skenario failover untuk memvalidasi pilihan Anda.
Setelah menyediakan klaster ECS Anda dengan persebaran yang sesuai untuk kapasitas komputasinya, penting untuk memastikan bahwa ECS akan menggunakan penyebaran ini untuk penempatan Task untuk menjaga ketersediaannya, ECS dan EC2 menyediakan beberapa alat yang berguna untuk membantu meningkatkan konstruksi ketersediaan AWS. Penting untuk memahami bahwa alat ini bekerja untuk memastikan bahwa Anda dapat mencapai tujuan ketersediaan dengan cara terbaik.
Peralatan ECS Untuk Ketersediaan Kontainer
Strategi penempatan Persebaran ECS
Kapasitas yang tersedia pada kelompok ECS digunakan untuk menempatkan Task ke dalam klaster ECS dengan Task ECS yang diluncurkan ke dalam sebuah klaster ECS. Sebuah klaster ECS yang dikonfigurasikan untuk menggunakan EC2 akan memiliki instans-instans EC2 yang terdaftar di dalamnya dan setiap instan EC2 berada pada sebuah Availability Zone tunggal. Anda harus memastikan bahwa Anda memiliki instans-instans EC2 yang terdaftar pada klaster Anda dari beberapa Availability Zone. Anda dapat membaca lebih lanjut tentang meluncurkan instan EC2 ke dalam klaster ECS di sini.
ECS mendukung penentuan strategi penempatan di dalam definisi layanan ECS atau sebagai sebuah argumen dalam permintaan RunTask. Strategi persebaran penempatan meminta ECS untuk menyebarkan Task ke berdasarkan upaya terbaik atas beberapa atribut kapasitas yang mendasarinya. Dengan menentukan “availability-zone” sebagai atribut penyebaran tersebut, ECS akan menyebarkan Task yang diluncurkan semerata mungkin pada Availability Zone untuk instan-instan EC2 yang terdaftar pada klaster ECS.
Layanan penjadwalan Replika ECS mempergunakan sebuah strategi penyebaran Availability Zone secara default jika tidak ada strategi penempatan lain yang disediakan. RunTask dapat dikonfigurasikan untuk mempergunakan strategi persebaran Availability Zone dengan menetapkan jenis dan properti bidang untuk strategi penempatan sebagai berikut di dalam permintaan RunTask:
"placementStrategy": [
{
"type": "spread",
"field": "attribute:ecs.availability-zone"
}
],Untuk penempatan persebaran pada Availability Zone, ECS akan bekerja untuk menyebarkan Task yang diluncurkan semerata mungkin pada Availability Zone untuk instan yang terdaftar pada klaster ECS. Dari perspektif ketersediaan, hal ini yang diinginkan. Namun ada beberapa sisi tajam yang haris diperhatikan. ECS terlihat untuk menyebarkan Task untuk layanan ini pada Availability Zone berdasarkan upaya terbaik tetapi hal ini dapat terhambat bergantung pada bagaiana klaster ECS dikonfigurasikan:
Klaster yang tidak seimbang
Sebuah klaster yang tidak seimbang terjadi jika kapasitas instans EC2 yang terdaftar di klaster tidak tersebar secara proporsional pada Availability Zone saat kapasitas yang tersedia pada beberapa Availability Zone lebih dari lainnya. Ini akan menghasilkan beberapa Availability Zone memiliki instans EC2 terdaftar lebih banyak dari lainnya, ECS akan selalu mencari untuk menyebarkan Task secara merata dengan mempergunakan penempatan persebaran pada semua Availability Zone di mana kapasitas didaftarkan. Jika klaster Anda tidak memiliki persebaran yang merata atas kapasitas instan EC2 pada Availability Zone, akan menghasilkan penempatan task yang lebih padat pada host yang penyediaannya lebih sedikit di Availability Zone tersebut. Pada kasus yang ekstrim, hal ini dapat berarti bahwa semua Task yang ditujukan untuk Availability Zone tersebut berada pada sebuah host tunggal jika hanya host tersebut yang memiliki kapasitas.
Sebagai contoh mari asumsikan bahwa sebuah klaster X memiliki sembilan instan EC2 pada Availability Zone 1, Availability Zone 2 dan Availability Zone 3. Namun klaster ini tidak seimbang dengan Availability Zone 1 memiliki dua instans, Availability Zone 2 memiliki sebuah instans dan Availability Zone 3 memiliki lima instans. Mari asumsikan sekarang bahwa kita memiliki layanan ECS yang dikonfigurasikan untuk mempergunakan klaster ini dengan Task berjumlah sembilan. ECS akan menyebarkan Task pada Availability Zone yang ada dengan hasil Availability Zone 1 memiliki tiga task yang tersebar pada dua instans, Availability Zone 2 memiliki tiga task yang semuanya ditempatkan pada satu instans, dan Availability Zone 3 memiliki tiga task yang tesebar pada lima instans.
Hal ini mewakili sebuah resiko ketersediaan dari dua perspektif. Pertama, Task pada Availability Zone 2 beresiko dari kegagalan sebuah Availability Zone dan juga beresiko dari sebuah kekagalan host tunggal. Efeknya, kegagalan sebuah instan untuk kluster kita pada Availability Zone sama dengan kegagalan Availability Zone secara total. Lebih jauh lagi, jika Availability Zone 3 mengalami kegagalan, klaster akan kehilangan secara efektif 50% dari kapasitas yang tersedia, lebih dari yang diinginkan dari modek ketersediaan kita. Hal ini membawa resiko potensi atas kegagalan lebih jauh karena peningkatan beban yang tidak direncanakan pada kapasitas layanan yang tersisa.
Klaster Dengan Kapasitas Terbatas
Penempatan persebaran ECS mempergunakan upaya terbaik dan dan ECS akan lebih memilih penempatan task daripada menggagalkan peluncuran. Jika klaster Anda memiliki kapasitas terbatas, ECS akan menempatkan pada kapasitas yang tesedia. Pada kasus ekstrim, hal ini bisa berarti bahwa semua Task untuk sebuah layanan ditempatkan pada sebuah Availability Zone. Klaster dengan kapasitas terbatas dapat terjadi sebagai hasil dari sejumlah faktor. Mempergunakan tipe instan EC2 yang beragam pada sebuah klaster kecuali seimbang pada semua Availability Zone dapat menghasilkan pada sumber daya tersedia yang tidak proporsional di salah satu Availability Zone.
Berbagi klaster untuk beberapa layanan dengan keterbatasan ketersediaan dan kriteria penempatan juga dapat menghasilkan kapasitas tersedia yang tidak terdistribusi merata pada Availability Zone. Hasilnya adalah sebuah resiko ketersediaan untuk layanan dan potensi untuk kegagalan dalam satu Availability Zone yang mengakibatkan kehilangan secara proporsional dari kesehatan Task dan potensi untuk pemadaman yang lebih luas karena kapasitas penggantian tidak tersedia saat dibutuhkan.
Penskalaan Otomatis EC2 dan Penyeimbangan Availability Zone Klaster Anda
EC2 menyediakan sebuah mekanisme untuk menyeimbangnkan kapasitas EC secara otomatis di seluruh Availability one melalui EC2 Auto Scaling. EC2 Auto Scaling ini akan memastikan secara otomatis untuk kapasitas dapat tersebar dengan baik di seluruh Availability Zone. Sebagai tambahan, EC Auto scaling juga akan melihat unutuk menggantikan kapasitas pada Klaster pada kejadian kegagalan Availability Zone di Availability Zone yang sehat dan saat pemulihan akan berusaha untuk menyeimbangkan ulang kapasitas di semua Availability Zone.
Mempergunakan EC2 Auto Scaling Group untuk Klaster ECS Anda menghilangkan beban untuk harus memantau dan menyeimbangkan persebaran Availability Zone pada Klaster EC2 Anda. Anda dapat membaca lebih jauh mengenai penggunaan EC2 Auto Scaling dengan Klaster ECS di sini.
ECS dan Fargate
AWS Fargate adalah mesin komputasi untuk ECS yang menghilangkan kebutuhan untuk melakukan konfigurasi, mengelola, dan mengatur skala instan EC2. Fargate memastikan persebaran Availability Zone sambil menghilangkan kompleksitas untuk mengelola infrastruktur EC2 dan bekerja untuk memastikan bahwa Task pada Replica Service berjalan dengan seimbang di semua Availability Zone. Untuk peluncuran RunTask dengan tipe peluncuran Fargate, Fargate akan melihat untuk menyebarkan penempatan Task di semua Availability Zone yang tersedia memastikan distribusi merata dari Task Definition Family di mana Task itu berada. Dengan mempergunakan Fargate, Anda dapat menghindari beban berat dari kepemilikan dan pengelolaan infrastruktur yang memungkinkan Anda untuk fokus dalam membuat aplikasi yang memuaskan pelanggan Anda.
Rekomendasi dan Praktik terbaik
Untuk mengatasi skenario di atas, yang terbaik adalah memastikan hal berikut:
- Mendukung untuk mengkonfigurasi Klaster ECS dengan kapasitas instans EC2 berada pada setidaknya tiga Availability Zone
- Mendukung untuk mengkonfigurasi Klaster ECS dengan kapasitas instans EC2 yang homogen dan menjaga jumlah instans yang seimbang di semua Availability Zone
- Mendukung untuk Klaster ECS dengan tenant tunggal
- Saat Klaster dengan multi tenan dibutuhkan, pastikan bahwa kebutuhan keterseidaan dan strategi penempatan untuk Klaster ECS berbagi tenan selaras untuk semua layanan dan Task yang dijalankan di Klaster tersbeut, (contoh: memastikan bahwa semua Task yang diluncurkan mempergunakan strategi penyebaran Availability Zone)
- Mempertimbangkan penggunaan EC2 Auto Scaling untuk mengelola kapasitas EC2 pada Klaster ECS Anda.
- Mempertimbangkan untuk menjalankan beban kerja Anda pada Fargate
Kesimpulan
Di AWS, kami mempertimbangkan bahwa ketersediaan adalah hal yang besar dan berusaha keras untuk menyediakan pelanggan kami dengan peralatan yang diperlukan untuk membuat pencapaian ketersediaan sesederhana mungkin. Namun penting untuk memahami praktik terbaik mengenai dasar dari peralatan tersebut dan nuansa dari peralatan tersebut adalah untuk memastikan ketersediaan yang paling baik untuk layanan Anda. Ada biaya atas penskalaan untuk ketersediaan dan tidak semua layanan memiliki persyaratan waktu henti nol (zero downtime). Bagi mereka yang mengikuti rekomendasi di atas akan membantu untuk meningkatkan ketersediaan, mengurangi biaya dan menghindari hasil yang tidak diharapkan yang didapat dari konfigurasi infrastruktur yang tidak diinginkan.
Tulisan ini berasal dari artikel Amazon ECS availability best practices yang ditulis oleh Malcolm Featonby dan diterjemahkan oleh Harry Kurniawan.