Blog de Amazon Web Services (AWS)
Migración de Azure Blob Storage a Amazon S3 mediante AWS DataSync
AWS DataSync permite copiar datos de Azure Blob Storage
AWS DataSync es un servicio de transferencia de datos en línea totalmente administrado que facilita la automatización de la transferencia de datos a gran escala. Con AWS DataSync, puede implementar su agente y, con unos pocos clics o mediante la línea de comandos, tendrá ejecutada una tarea de transferencia de datos segura y confiable sin necesidad de implementar sus propias utilidades de software ni administrar scripts programados personalizados.
Al seleccionar los contenedores de Azure Blob Storage como ubicación de origen, AWS DataSync transfiere objetos de Azure Blob Storage de hasta 5 TB de tamaño con metadatos de objetos que no superan los 2 KB. Los metadatos de Azure Blob Storage son información adicional, como las propiedades del sistema y los pares de nombre-valor adicionales que puede definir, como el nombre del autor, el tipo de documento, la clase del documento, etc.
Azure Storage ofrece tres capas de acceso, que incluyen: capa activa, capa fria y capa de archivo. Las capas Activa y Fria se consideran capas de acceso en línea, lo que significa que los clientes pueden acceder a los datos inmediatamente cuando los soliciten. La capa de archivo está diseñada para datos a los que se accede con poca frecuencia. Si tiene datos archivados que deben transferirse al almacenamiento de AWS, tendrá que rehidratar los objetos de la capa de archivado a una capa de acceso en línea antes de poder transferirlos al almacenamiento de AWS. DataSync simplemente ignorará los objetos de Azure Blob Storage que están almacenados en la capa de archivo en lugar de generar un mensaje de error.
Descripción general y terminología de la solución AWS DataSync
DataSync tiene cuatro componentes para mover datos: tareas, ubicaciones, agentes y ejecución de tareas. La figura 1 muestra la relación entre los componentes y las configuraciones que utilizaremos en el tutorial.

Figura 1. Componentes principales de AWS DataSync
- Agente: máquina virtual (VM) que lee o escribe datos en una ubicación determinada. En este tutorial, implementamos el agente DataSync como una máquina virtual de Azure en una red virtual de Azure.
- Ubicación: la ubicación de origen y destino de la migración de datos. En este tutorial, el lugar de origen es un contenedor de Azure Blob Storage. La ubicación de destino es un bucket de Amazon S3.
- Tarea: Una tarea comprende una ubicación de origen y una ubicación de destino con una configuración que define cómo se transfieren los datos. Una tarea siempre sincroniza los datos del origen con el destino. La configuración incluye opciones como incluir/excluir valores predeterminados, programación de tareas, límites de ancho de banda, etc.
- Ejecución de tareas: es una ejecución individual de una tarea, que incluye información como la hora de inicio, la hora de finalización, los bytes registrados y el estado.
La siguiente imagen muestra cómo se migran los datos de Azure Blob Storage a Amazon S3 con AWS DataSync.
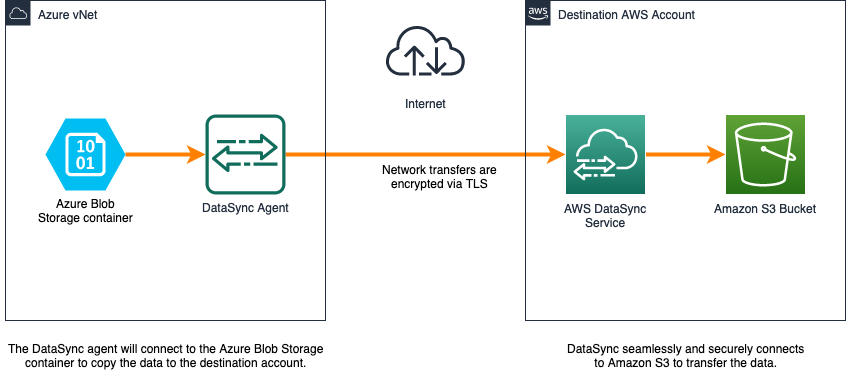
Figura 2. Arquitectura DataSync con contenedor de almacenamiento Azure Blob
Información sobre el tamaño de los agentes de AWS DataSync
Al implementar AWS DataSync en Azure, seleccione el tamaño de instancia adecuado a la cantidad de archivos que se van a transferir.
Recomendamos dedicar los siguientes recursos mínimos:
- Procesadores virtuales: cuatro procesadores virtuales asignados a la máquina virtual.
- Espacio en disco: 80 GB de espacio en disco para instalar la imagen de la máquina virtual y los datos del sistema.
- RAM: en función de la configuración del almacenamiento de datos:
- 32 GB de RAM asignados a la máquina virtual, para tareas que transfieren hasta 20 millones de archivos.
- 64 GB de RAM asignados a la máquina virtual, para tareas que transfieren más de 20 millones de archivos.
Si bien puede implementar un agente de DataSync en una instancia de Amazon EC2 para acceder a su almacenamiento de Azure, puede resultar beneficioso implementar el agente más cercano al sistema de almacenamiento al que DataSync necesita acceder. La implementación del agente DataSync en la misma red que el sistema de almacenamiento de origen reducirá la latencia de la red, aprovechará la compresión de datos que proporciona el protocolo de transferencia diseñado por AWS y eliminará la necesidad de tener un terminal público para su cuenta de almacenamiento de Azure.
Transport Layer Security (TLS) 1.2 cifra todos los datos transferidos entre el origen y el destino. Además, los datos nunca se mantienen en AWS DataSync. El servicio admite el uso del cifrado estándar para los buckets de S3.
Prerrequisitos
Necesitarás lo siguiente para completar los pasos de esta publicación:
- Cuenta de AWS
- Suscripción a la cuenta de Azure
- Bucket Amazon S3
- Contenedor Azure Blob Storage
- PowerShell
- CLI de Azure
- AZCopy
- Deberás habilitar las siguientes funciones de Windows en tu equipo local:
- Módulo Hyper-V para Windows PowerShell
- Servicios Hyper-V
Puede encontrar detalles sobre cómo configurar un contenedor de Azure Blob Storage aquí. También será necesario aprovisionar un bucket de S3. Encontrará detalles sobre cómo crear-lo aquí. Al bucket de S3 lo llamamos «datasynctest1234» y a la cuenta de almacenamiento de Azure «awsblobdatasync», que mencionaremos más adelante en este blog.
Despliegue del agente DataSync
En esta sección, nos centraremos en los pasos necesarios para implementar y configurar el agente DataSync.
Paso 1 Prepare la imagen del agente DataSync para la implementación
- Abra la consola de AWS DataSync en https://console.thinkwithwp.com/datasync/
- En la página Crear agente de la consola, seleccione «Microsoft Hyper-V» en el menú desplegable del hipervisor.
- Elija «Descargar la imagen» en la sección Deploy Agent. Esto descarga el agente en un archivo .zip que contiene un archivo de imagen VHDX.
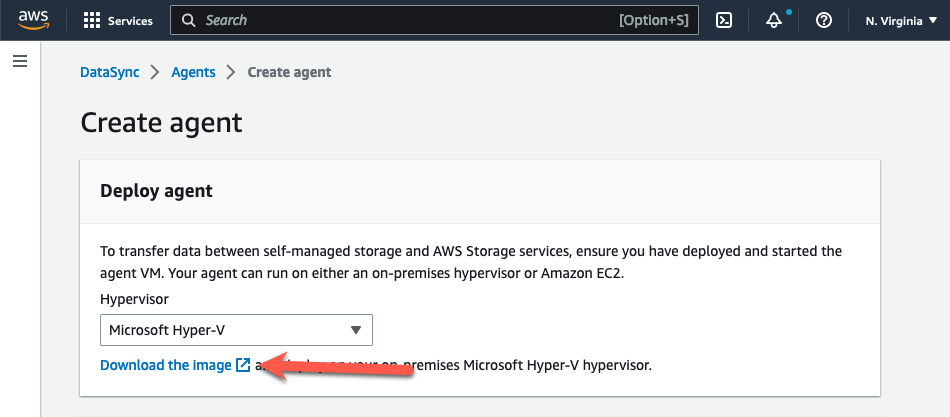
Figura 3. Descargar el agente DataSync
- Extraiga el archivo de imagen VHDX a su estación de trabajo.
- El archivo VHDX deberá convertirse en un archivo VHD de tamaño fijo para que sea compatible con Azure. Puede encontrar más información sobre cómo preparar un VHDX para subirlo a Azure aquí. Ejecute el siguiente comando y actualice la ruta y el nombre del archivo para que coincidan con su ubicación:
Convert-VHD -Path .\<path to vhdx>\aws-datasync-2.0.1678813931.1-x86_64.xfs.gpt.vhdx -DestinationPath .\<path to vhdx>\ aws-datasync-2016788139311-x86_64.vhd -VHDType Fixed
Paso 2 Cargue el VHD en un disco gestionado
- Determine el tamaño del VHD para poder crear un disco administrado vacío compatible. Utilice el comando «ls -l. » en el directorio que contiene la imagen del archivo VHD. Esto le dará el número de bytes del archivo VHD. Lo necesitarás para el parámetro –upload-size-bytes más adelante.

Figura 4. Identifique el tamaño en bytes del archivo DataSync VHD
- Cree el disco administrado vacío mediante la ejecución del siguiente comando. Actualice los parámetros con su información.
az disk create -n <yourdiskname> -g <yourresourcegroupname> -l <yourregion> --upload-type Upload --upload-size-bytes 85899346432--sku standard_lrs
- Generar una suscripción de acceso compartido (SAS)
az disk grant-access -n <yourdiskname> -g <yourresourcegroupname> --access-level Write --duration-in-seconds 86400
- Cargue DataSync VHD en el disco administrado vacío
AzCopy.exe copy "c:\somewhere\mydisk.vhd" "sas-URI"--blob-type PageBlob
- Cuando finalice la carga, revoque el SAS para preparar el disco para montarlo en la nueva máquina virtual.
az disk revoke-access -n <yourdiskname> -g <yourresourcegroupname>
Paso 3 Cree la máquina virtual del agente DataSync
az vm create --resource-group myResourceGroup --location eastus --name myNewVM --size Standard_E4as_v4 --os-type linux --attach-os-disk myManagedDisk
- Habilitar el diagnóstico de arranque
- Conéctese mediante una conexión en serie e inicie sesión en la consola local de su agente
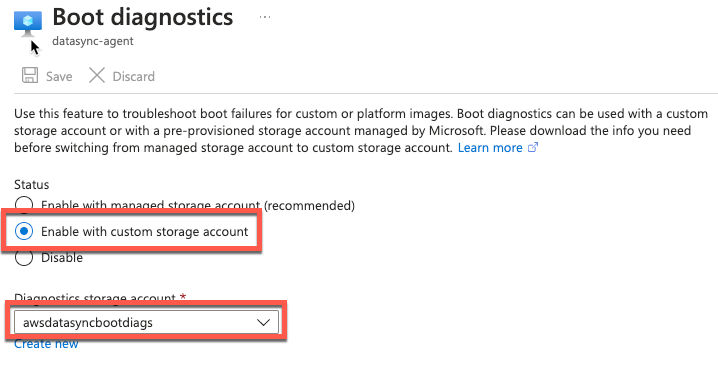
Figura 5. Habilitar el diagnóstico de inicio
- En el menú principal de AWS DataSync Activation — Configuration, escriba 0 para obtener una clave de activación.
- Introduzca la región de AWS en la que va a activar el agente.
- Introduzca el tipo de terminal de servicio que utilizará su agente. Las opciones incluyen pública, FIPS y VPC con AWS PrivateLink. Usaremos la opción pública en este ejemplo.
- La clave de activación se generará automáticamente y se mostrará en la pantalla. Selecciona y copia dicha clave.
Paso 4: Activar la máquina virtual del agente DataSync
- Abra la consola de AWS DataSync en https://console.thinkwithwp.com/datasync/
- En la página Crear agente de la consola, seleccione «Microsoft Hyper-V» en el menú desplegable del hipervisor.
- En la sección Terminal de servicio, seleccione la opción Terminales de servicio público en la región en la que activará su agente.
- En Activación de clave, selecciona Introducir manualmente la clave de activación del agente y pega el valor que copiaste de la consola local del agente.
- Proporcione un nombre único para el agente, si lo desea, y haga clic en el botón Crear agente.
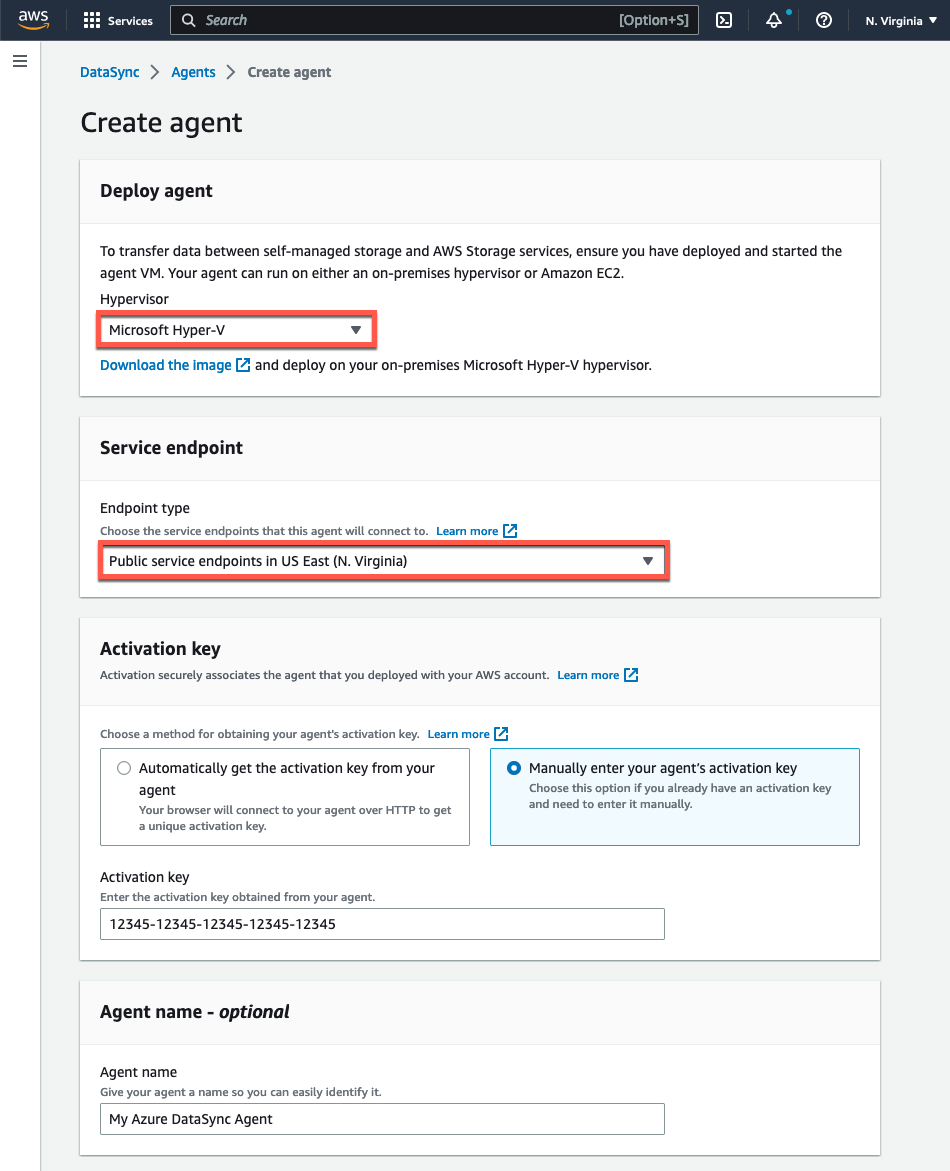
Figura 6. Crear el agente DataSync
Configuración de la replicación de datos
En esta sección, nos centraremos en los pasos necesarios para crear ubicaciones de almacenamiento y configurar la replicación de datos.
Paso 1 Configurar la ubicación de origen de Azure Blob Storage
Configure el contenedor origen de Azure Blob Storage como una ubicación de Azure Blob DataSync. Elija la opción Ubicaciones en el panel de navegación de la izquierda y seleccione Crear ubicación. A continuación, seleccione Microsoft Azure Blob Storage como tipo de ubicación. Asegúrese de seleccionar el agente que creó en los pasos anteriores.

Figura 7. Creación de la ubicación de Azure Blob Storage
A continuación, deberá especificar una URL de contenedor y un token SAS. Si lo desea, puede especificar la ruta de una carpeta del contenedor para recuperar un subconjunto de datos. Siga estos pasos para recuperar la URL del contenedor y generar un token SAS de Azure.
El token SAS de Azure proporciona acceso delegado a los recursos de la cuenta de almacenamiento. Puede proporcionar un acceso detallado a sus datos definiendo los recursos a los que se puede acceder, los permisos de esos recursos y la duración de la validez del token SAS. Puede generar un token SAS de Azure a nivel de cuenta de almacenamiento o a nivel de bloque de contenedores. Generar el token a nivel de bloque del contenedor puede resultar útil cuando se desea limitar el acceso a un solo contenedor.
Puede generar un token SAS de Azure desde el portal de Azure, Azure Storage Explorer o la CLI de Azure. Usaremos el método Azure Portal para crear un token a nivel de cuenta.
- En el portal de Azure, vaya a la cuenta de almacenamiento y seleccione Firma de acceso compartido en la parte izquierda de la página. Borre todos los servicios permitidos, excepto
- Seleccione Contenedor y Objeto en los tipos de recursos permitidos. Asigne los permisos de lectura y lista desde los permisos autorizados. Asigne el permiso de lectura/escritura en la sección permisos del índice de blob para copiar las etiquetas. Puede encontrar detalles adicionales relacionados con los permisos del token SAS en la documentación.
- Especifique las fechas y horas de inicio y caducidad de la clave firmada. Asegúrese de que el período de validez del token sea suficiente para migrar los datos.
- Revise la configuración y seleccione Generar SAS y cadena de conexión.
- Los valores de SAS Token y de Blob Service SAS URL se mostrarán en la parte inferior de la pantalla. Copie el campo del SAS token de la consola de AWS.
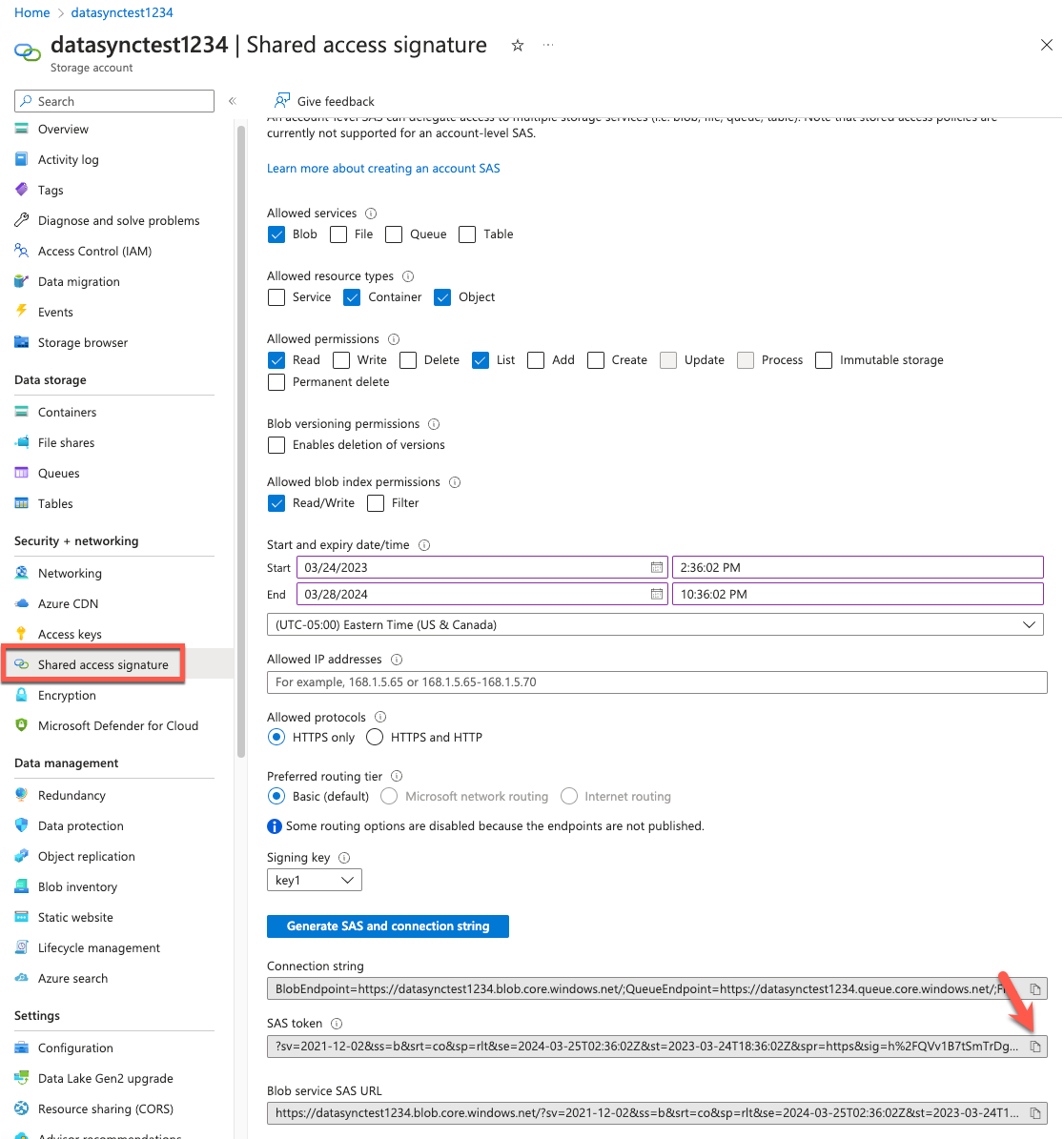
Figura 8. Identifique el token SAS
6. Copie la URL del contenedor de las propiedades del contenedor de Azure Blob.
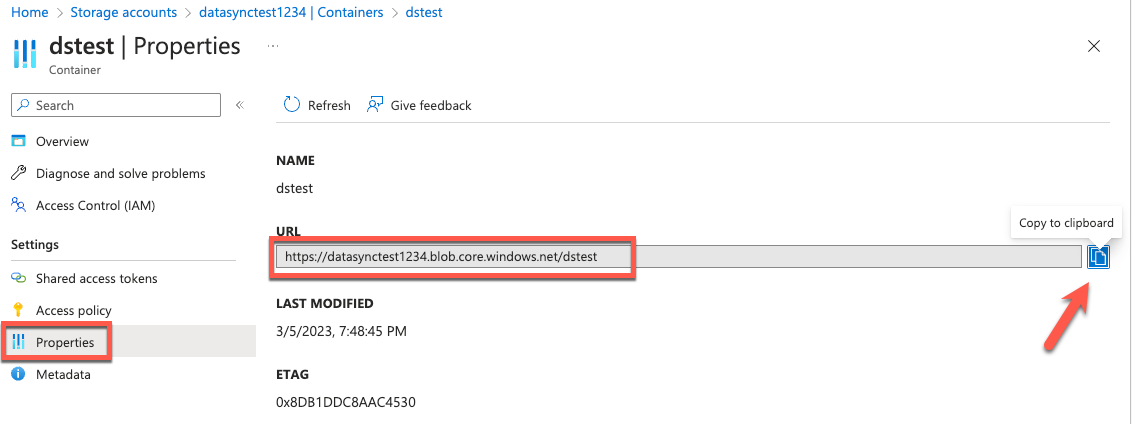
Figura 9. Identificar la URL del contenedor
Paso 2: Configurea la ubicación de destino
Configure la ubicación de destino como Amazon S3. Seleccione Ubicaciones en el menú de navegación de la izquierda y haga clic en Crear ubicación. Elija el bucket de Amazon S3 de destino, la clase de almacenamiento de S3 , el folder y el rol de IAM con los permisos para acceder al bucket de Amazon S3. DataSync puede transferir datos directamente a todas las clases de almacenamiento de S3 sin tener que gestionar políticas de ciclo de vida de día cero. Para cada transferencia, puede seleccionar la clase de almacenamiento S3 más rentable según sus necesidades. DataSync detecta archivos u objetos que existen en el sistema de archivos o en el bucket de destino. Los datos que cambiaron entre la ubicación de origen y la ubicación de destino se transferirán en ejecuciones secuenciales de la tarea de AWS DataSync.

Figura 10: Crie a localização do S3
Paso 3: Crear la tarea de replicación
Configure los parámetros de la tarea asignando la ubicación de origen de Azure Blob Storage existente en el paso 3 y el bucket de Amazon S3 de destino en el paso 4. Consulte la documentación de configuración de tareas para obtener más información sobre la configuración y las opciones de la tarea.

Figura 11. Configurar el lugar de origen
Tras configurar la ubicación de origen, haga clic en Siguiente y seleccione el bucket de Amazon S3 de destino:

Figura 12. Configurar la ubicación de destino
El siguiente es un ejemplo de los ajustes que configuramos anteriormente.
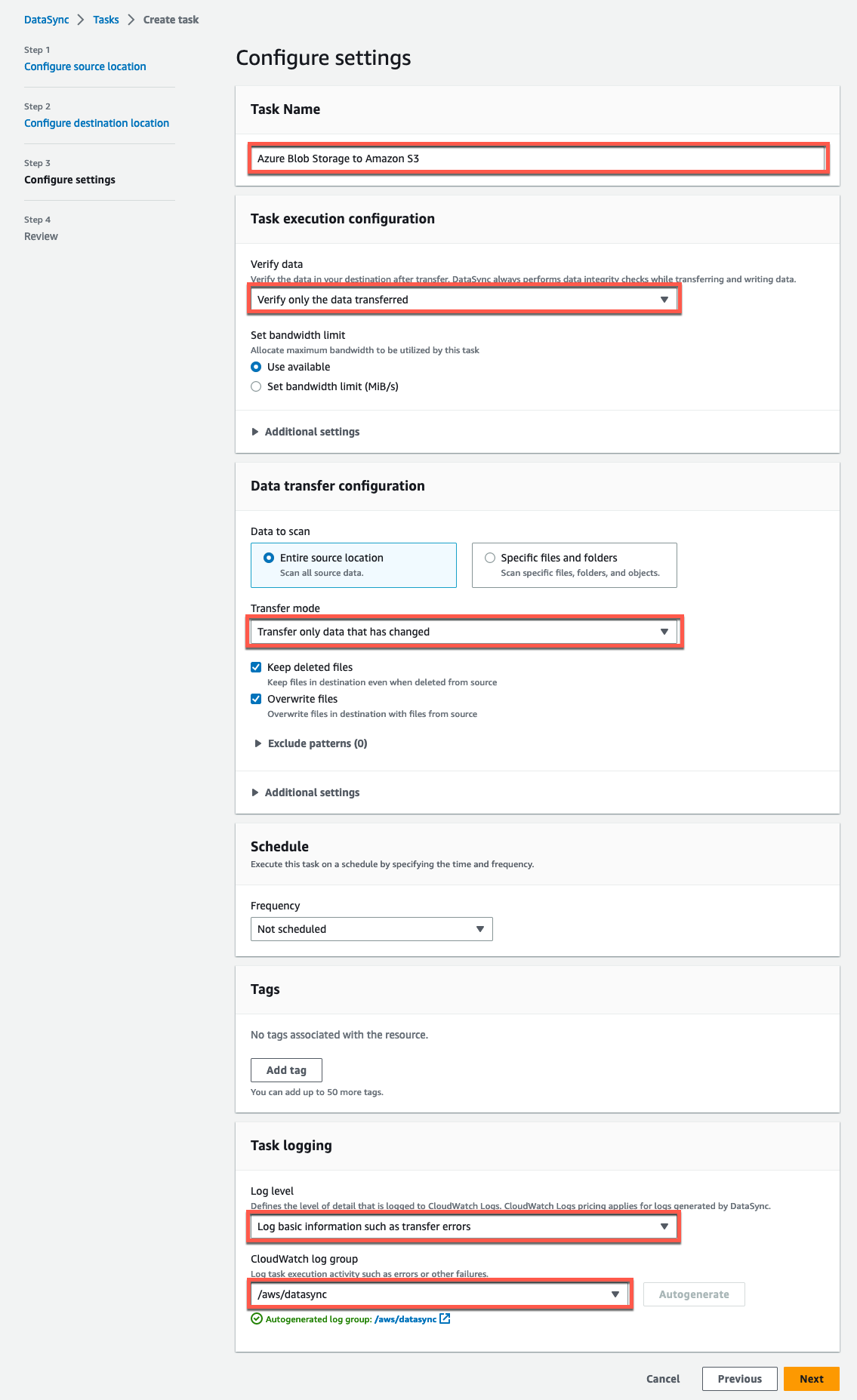
Figura 13. Configuración de tareas de DataSync
Paso 4: Iniciar la tarea DataSync
Inicie la tarea para que DataSync pueda transferir los datos haciendo clic en Iniciar en la lista de tareas o en la propia descripción general de la tarea. Para obtener más información sobre la ejecución de tareas y la supervisión de su tarea de DataSync con Amazon CloudWatch, haga clic en los enlaces.
Tras completar los pasos de este tutorial, dispondrá de una canalización de datos segura para mover sus datos de forma eficiente de Azure Blob Storage a Amazon S3. Cada vez que se ejecuta la tarea DataSync, comprueba las ubicaciones de origen y destino para ver si hay cambios y ejecuta una copia de cualquier diferencia en los datos y los metadatos. Hay varias fases por las que pasa una tarea de DataSync: lanzamiento, preparación, transferencia y verificación. El tiempo empleado en la fase de preparación varía según la cantidad de archivos en las ubicaciones de origen y destino. Por lo general, toma de unos minutos a varias horas. Consulte la Guía del usuario de DataSync para obtener más información sobre las fases de la tarea DataSync.
Limpieza
Para obtener más información sobre los precios de AWS, consulte la documentación de AWS DataSync. Si bien no hay ningún cargo adicional por la transferencia de datos entrantes, es posible que haya cargos por datos salientes en la cuenta de origen de Azure. Consulte el sitio de precios del proveedor para obtener información actualizada sobre las tarifas de salida. Para evitar cargos continuos por los recursos que has creado, sigue estos pasos:
- Elimine la tarea DataSync creada en el paso 3 de la configuración de la replicación de datos.
- Elimine los sitios de origen y destino creados en los pasos 1 y 2 de la configuración de la replicación de datos.
- Elimine el agente DataSync creado en el paso 3 de la implementación de DataSync
- Elimine la máquina virtual de Azure y los recursos adjuntos que se crearon al implementar el agente DataSync.
- Elimine todos los objetos del bucket de S3 del paso 1 de la configuración de la replicación de datos. El bucket debe estar vacío para poder eliminarlo siguiendo los pasos que se indican aquí.
Conclusión
En esta entrada de blog, analizamos la implementación paso a paso del agente AWS DataSync en Azure. Creamos y configuramos una tarea que copia los datos de los objetos de un contenedor de Azure Blob Storage a un bucket de S3 en AWS sin administrar scripts ni utilidades personalizados.
Los clientes pueden beneficiarse de la fácil migración de datos de Azure Blob Storage a los servicios de almacenamiento de AWS, como Amazon S3, Amazon Elastic File System y cualquier sistema de archivos Amazon FSx compatible. La compatibilidad con la copia de datos de los servicios de almacenamiento de AWS a Azure Blob Storage se añadirá como parte de la disponibilidad general (GA). Al aprovechar un servicio gestionado como DataSync, se elimina la carga de administrar la infraestructura adicional, se ahorra tiempo operativo y se reduce la complejidad de mover datos a gran escala.
Estos son otros recursos que le ayudarán a empezar a utilizar AWS DataSync:
- Novedades de AWS DataSync
- Guía del usuario de AWS DataSync
- AWS re:Post
- AWS DataSync Primer: curso en línea gratuito de una hora, una hora e individual
- Cómo transferir datos de recursos compartidos para pequeñas y medianas empresas de Azure Files a AWS mediante AWS DataSync
Gracias por leer esta publicación sobre la migración de Azure Blob Storage a Amazon S3 mediante AWS DataSync. Le animo a que pruebe esa solución hoy. Si tiene algún comentario o pregunta, déjelo en la sección de comentarios.
Este artículo fue traducido del Blog de AWS en Inglés.
Acerca de los autores
Revisores e Traductores
 Gustavo Lima es arquitecto de soluciones en AWS en el segmento Partner First SP High Biller. Cuenta con más de 13 años de experiencia en el área de soluciones de almacenamiento y protección de datos. Se unió al equipo en 2022.
Gustavo Lima es arquitecto de soluciones en AWS en el segmento Partner First SP High Biller. Cuenta con más de 13 años de experiencia en el área de soluciones de almacenamiento y protección de datos. Se unió al equipo en 2022.
 Maribel Ramirez Madrigal es arquitecto de soluciones en AWS. Se unió al equipo en 2021.
Maribel Ramirez Madrigal es arquitecto de soluciones en AWS. Se unió al equipo en 2021.