Artificial Intelligence

Introducing structured output for Custom Model Import in Amazon Bedrock
Today, we are excited to announce the addition of structured output to Custom Model Import. Structured output constrains a model’s generation process in real time so that every token it produces conforms to a schema you define. Rather than relying on prompt-engineering tricks or brittle post-processing scripts, you can now generate structured outputs directly at inference time.

Transform your MCP architecture: Unite MCP servers through AgentCore Gateway
Earlier this year, we introduced Amazon Bedrock AgentCore Gateway, a fully managed service that serves as a centralized MCP tool server, providing a unified interface where agents can discover, access, and invoke tools. Today, we’re extending support for existing MCP servers as a new target type in AgentCore Gateway. With this capability, you can group multiple task-specific MCP servers aligned to agent goals behind a single, manageable MCP gateway interface. This reduces the operational complexity of maintaining separate gateways, while providing the same centralized tool and authentication management that existed for REST APIs and AWS Lambda functions.
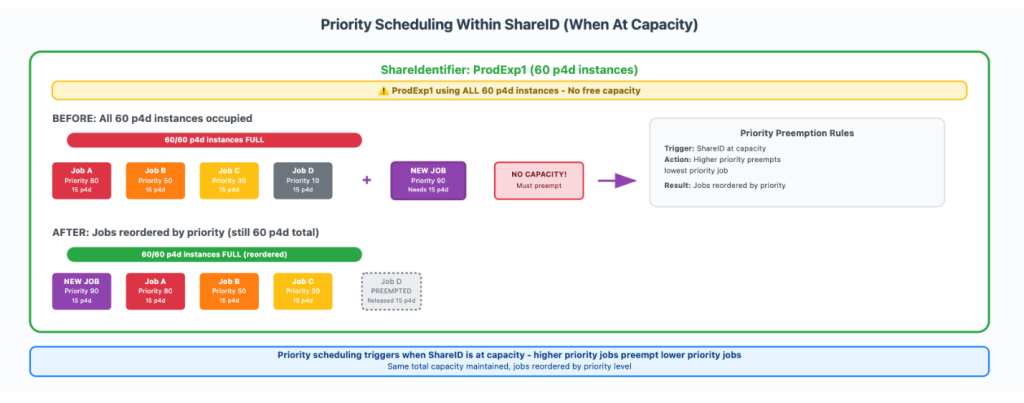
How Amazon Search increased ML training twofold using AWS Batch for Amazon SageMaker Training jobs
In this post, we show you how Amazon Search optimized GPU instance utilization by leveraging AWS Batch for SageMaker Training jobs. This managed solution enabled us to orchestrate machine learning (ML) training workloads on GPU-accelerated instance families like P5, P4, and others. We will also provide a step-by-step walkthrough of the use case implementation.

Iterate faster with Amazon Bedrock AgentCore Runtime direct code deployment
Amazon Bedrock AgentCore is an agentic platform for building, deploying, and operating effective agents securely at scale. Amazon Bedrock AgentCore Runtime is a fully managed service of Bedrock AgentCore, which provides low latency serverless environments to deploy agents and tools. It provides session isolation, supports multiple agent frameworks including popular open-source frameworks, and handles multimodal […]
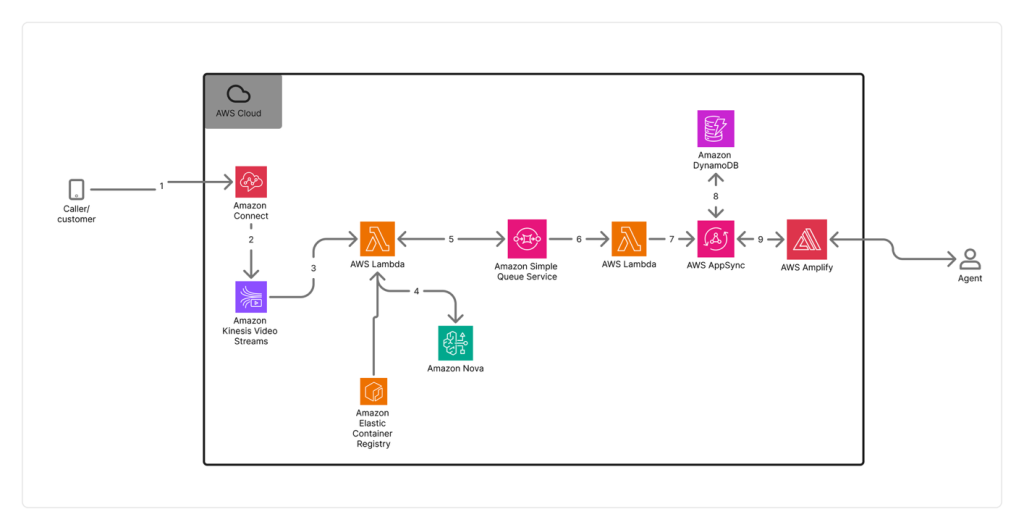
How Switchboard, MD automates real-time call transcription in clinical contact centers with Amazon Nova Sonic
In this post, we examine the specific challenges Switchboard, MD faced with scaling transcription accuracy and cost-effectiveness in clinical environments, their evaluation process for selecting the right transcription solution, and the technical architecture they implemented using Amazon Connect and Amazon Kinesis Video Streams. This post details the impressive results achieved and demonstrates how they were able to use this foundation to automate EMR matching and give healthcare staff more time to focus on patient care.

Build reliable AI systems with Automated Reasoning on Amazon Bedrock – Part 1
Enterprises in regulated industries often need mathematical certainty that every AI response complies with established policies and domain knowledge. Regulated industries can’t use traditional quality assurance methods that test only a statistical sample of AI outputs and make probabilistic assertions about compliance. When we launched Automated Reasoning checks in Amazon Bedrock Guardrails in preview at […]

Custom Intelligence: Building AI that matches your business DNA
In 2024, we launched the Custom Model Program within the AWS Generative AI Innovation Center to provide comprehensive support throughout every stage of model customization and optimization. Over the past two years, this program has delivered exceptional results by partnering with global enterprises and startups across diverse industries—including legal, financial services, healthcare and life sciences, […]
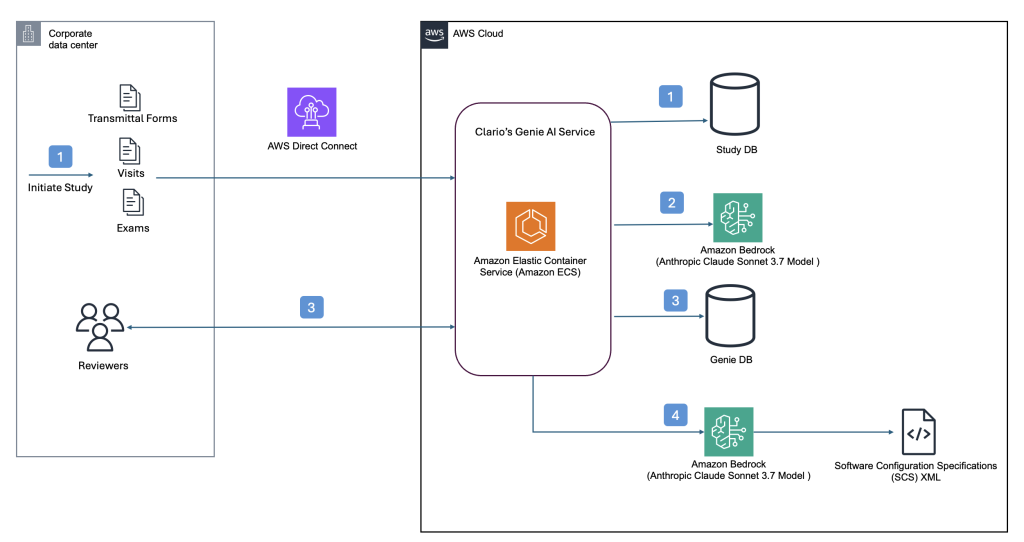
Clario streamlines clinical trial software configurations using Amazon Bedrock
This post builds upon our previous post discussing how Clario developed an AI solution powered by Amazon Bedrock to accelerate clinical trials. Since then, Clario has further enhanced their AI capabilities, focusing on innovative solutions that streamline the generation of software configurations and artifacts for clinical trials while delivering high-quality clinical evidence.

Introducing Amazon Bedrock cross-Region inference for Claude Sonnet 4.5 and Haiku 4.5 in Japan and Australia
こんにちは, G’day. The recent launch of Anthropic’s Claude Sonnet 4.5 and Claude Haiku 4.5, now available on Amazon Bedrock, marks a significant leap forward in generative AI models. These state-of-the-art models excel at complex agentic tasks, coding, and enterprise workloads, offering enhanced capabilities to developers. Along with the new models, we are thrilled to announce that […]

Reduce CAPTCHAs for AI agents browsing the web with Web Bot Auth (Preview) in Amazon Bedrock AgentCore Browser
AI agents need to browse the web on your behalf. When your agent visits a website to gather information, complete a form, or verify data, it encounters the same defenses designed to stop unwanted bots: CAPTCHAs, rate limits, and outright blocks. Today, we are excited to share that AWS has a solution. Amazon Bedrock AgentCore […]