Artificial Intelligence
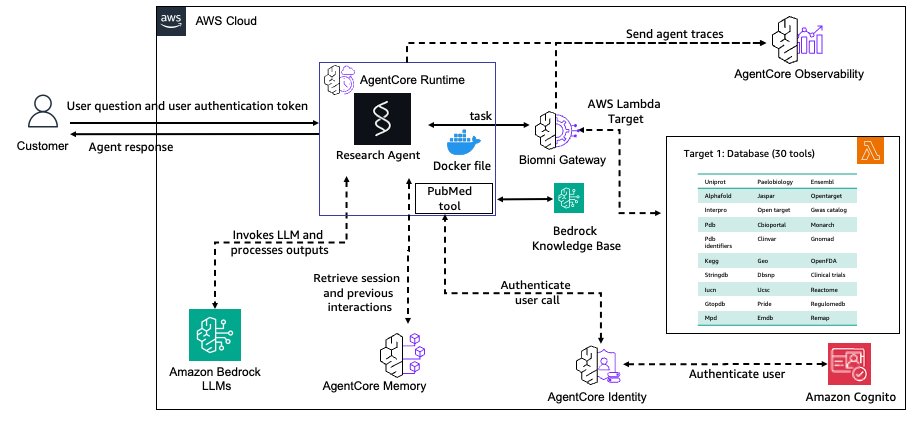
Build a biomedical research agent with Biomni tools and Amazon Bedrock AgentCore Gateway
In this post, we demonstrate how to build a production-ready biomedical research agent by integrating Biomni’s specialized tools with Amazon Bedrock AgentCore Gateway, enabling researchers to access over 30 biomedical databases through a secure, scalable infrastructure. The implementation showcases how to transform research prototypes into enterprise-grade systems with persistent memory, semantic tool discovery, and comprehensive observability for scientific reproducibility .
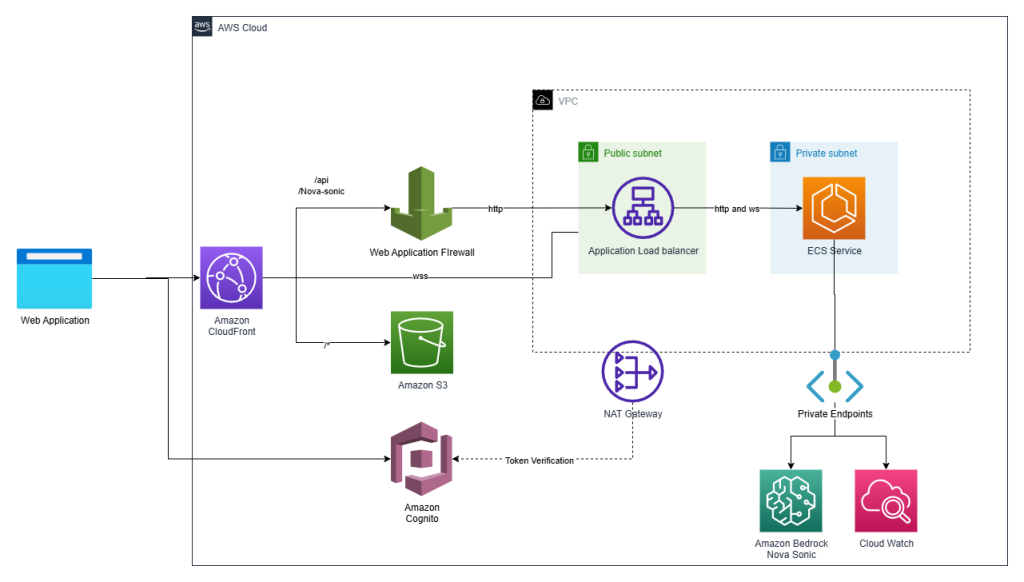
Make your web apps hands-free with Amazon Nova Sonic
Graphical user interfaces have carried the torch for decades, but today’s users increasingly expect to talk to their applications. In this post we show how we added a true voice-first experience to a reference application—the Smart Todo App—turning routine task management into a fluid, hands-free conversation.
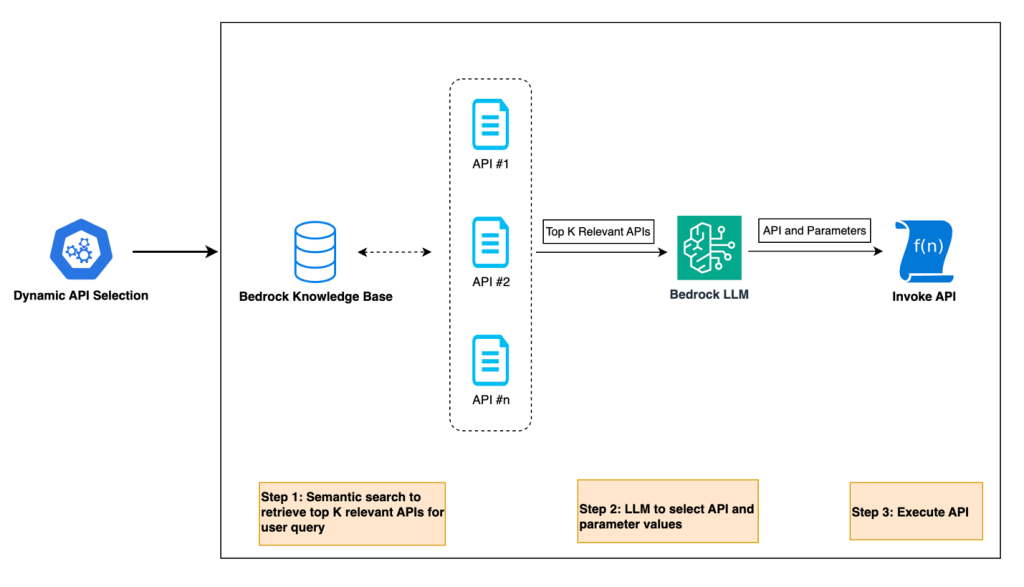
Harnessing the power of generative AI: Druva’s multi-agent copilot for streamlined data protection
Generative AI is transforming the way businesses interact with their customers and revolutionizing conversational interfaces for complex IT operations. Druva, a leading provider of data security solutions, is at the forefront of this transformation. In collaboration with Amazon Web Services (AWS), Druva is developing a cutting-edge generative AI-powered multi-agent copilot that aims to redefine the customer experience in data security and cyber resilience.
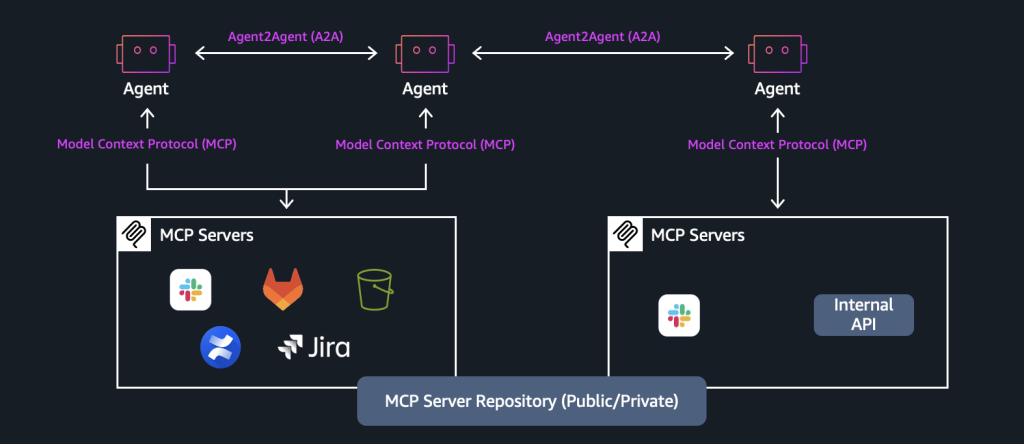
Introducing agent-to-agent protocol support in Amazon Bedrock AgentCore Runtime
In this post, we demonstrate how you can use the A2A protocol for AI agents built with different frameworks to collaborate seamlessly. You’ll learn how to deploy A2A servers on AgentCore Runtime, configure agent discovery and authentication, and build a real-world multi-agent system for incident response. We’ll cover the complete A2A request lifecycle, from agent card discovery to task delegation, showing how standardized protocols eliminate the complexity of multi-agent coordination.
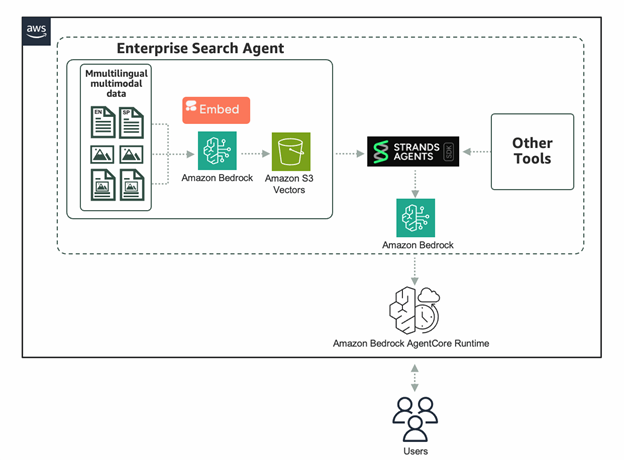
Powering enterprise search with the Cohere Embed 4 multimodal embeddings model in Amazon Bedrock
The Cohere Embed 4 multimodal embeddings model is now available as a fully managed, serverless option in Amazon Bedrock. In this post, we dive into the benefits and unique capabilities of Embed 4 for enterprise search use cases. We’ll show you how to quickly get started using Embed 4 on Amazon Bedrock, taking advantage of integrations with Strands Agents, S3 Vectors, and Amazon Bedrock AgentCore to build powerful agentic retrieval-augmented generation (RAG) workflows.
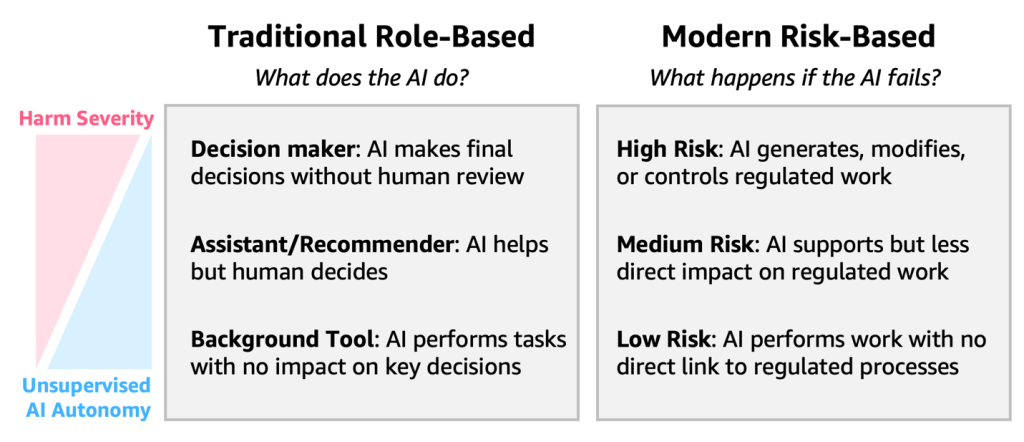
A guide to building AI agents in GxP environments
The regulatory landscape for GxP compliance is evolving to address the unique characteristics of AI. Traditional Computer System Validation (CSV) approaches, often with uniform validation strategies, are being supplemented by Computer Software Assurance (CSA) frameworks that emphasize flexible risk-based validation methods tailored to each system’s actual impact and complexity (FDA latest guidance). In this post, we cover a risk-based implementation, practical implementation considerations across different risk levels, the AWS shared responsibility model for compliance, and concrete examples of risk mitigation strategies.
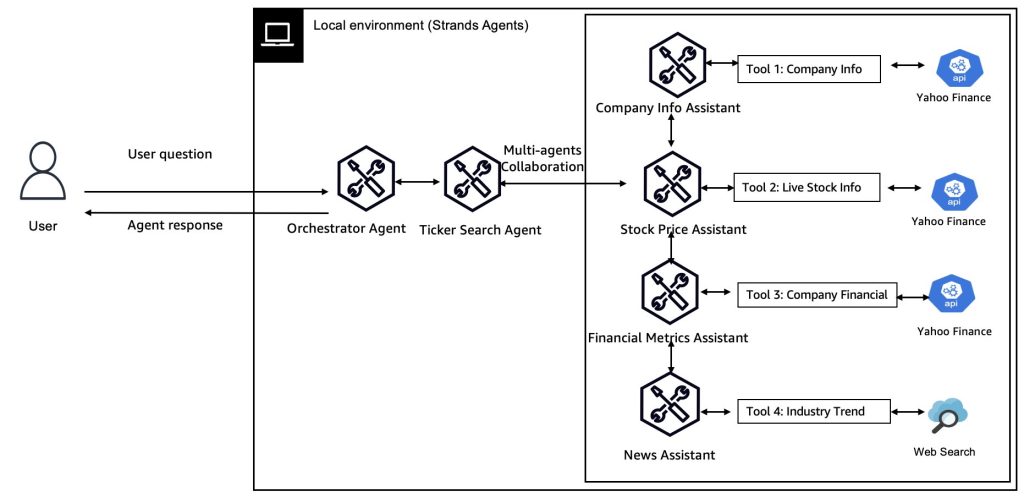
Multi-Agent collaboration patterns with Strands Agents and Amazon Nova
In this post, we explore four key collaboration patterns for multi-agent, multimodal AI systems – Agents as Tools, Swarms Agents, Agent Graphs, and Agent Workflows – and discuss when and how to apply each using the open-source AWS Strands Agents SDK with Amazon Nova models.
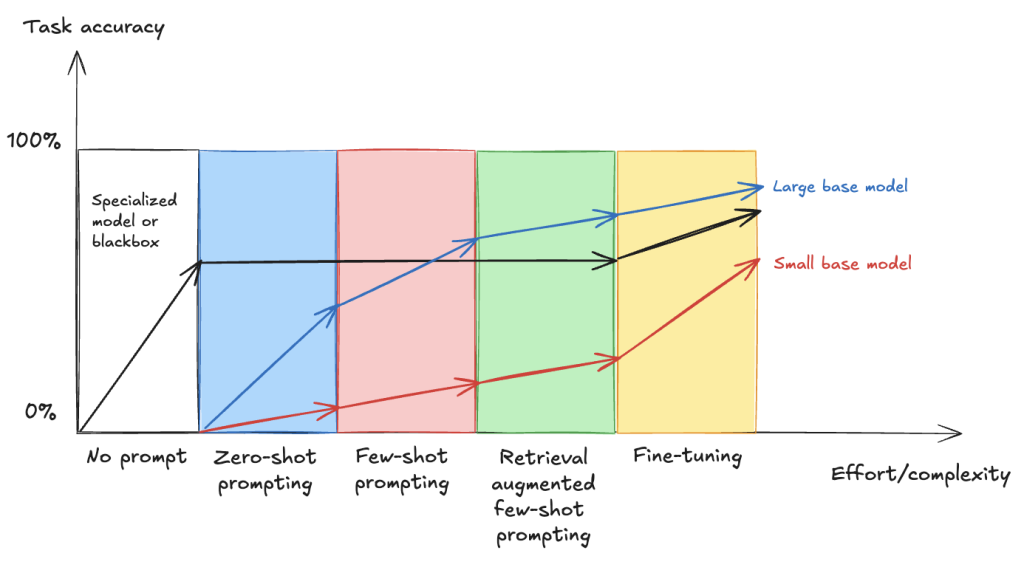
Fine-tune VLMs for multipage document-to-JSON with SageMaker AI and SWIFT
In this post, we demonstrate that fine-tuning VLMs provides a powerful and flexible approach to automate and significantly enhance document understanding capabilities. We also demonstrate that using focused fine-tuning allows smaller, multi-modal models to compete effectively with much larger counterparts (98% accuracy with Qwen2.5 VL 3B).
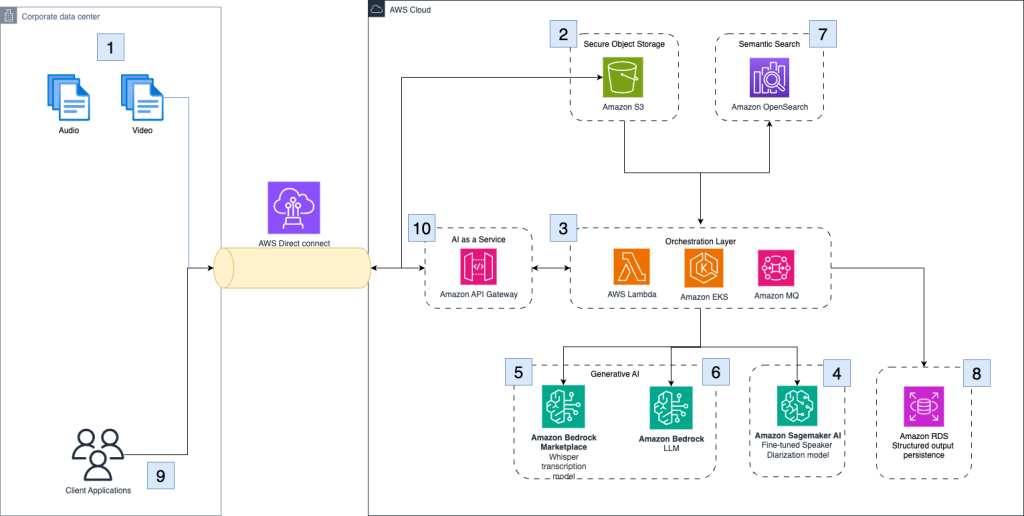
How Clario automates clinical research analysis using generative AI on AWS
In this post, we demonstrate how Clario has used Amazon Bedrock and other AWS services to build an AI-powered solution that automates and improves the analysis of COA interviews.
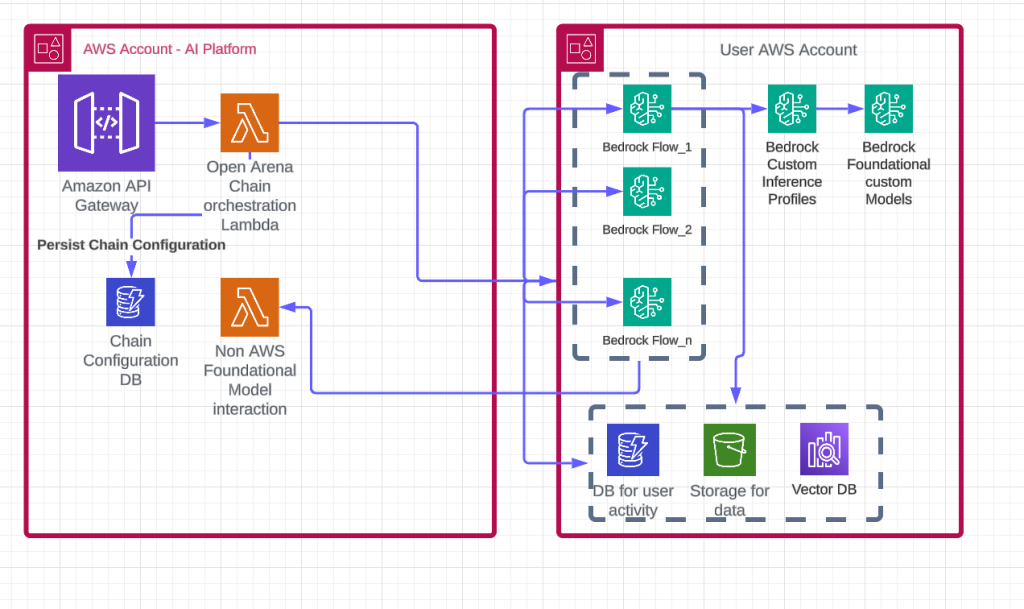
Democratizing AI: How Thomson Reuters Open Arena supports no-code AI for every professional with Amazon Bedrock
In this blog post, we explore how TR addressed key business use cases with Open Arena, a highly scalable and flexible no-code AI solution powered by Amazon Bedrock and other AWS services such as Amazon OpenSearch Service, Amazon Simple Storage Service (Amazon S3), Amazon DynamoDB, and AWS Lambda. We’ll explain how TR used AWS services to build this solution, including how the architecture was designed, the use cases it solves, and the business profiles that use it.