Artificial Intelligence
Improve performance of Falcon models with Amazon SageMaker
What is the optimal framework and configuration for hosting large language models (LLMs) for text-generating generative AI applications? Despite the abundance of options for serving LLMs, this is a hard question to answer due to the size of the models, varying model architectures, performance requirements of applications, and more. The Amazon SageMaker Large Model Inference (LMI) container makes it straightforward to serve LLMs by bringing together a host of different frameworks and techniques that optimize the deployment of LLMs. The LMI container has a powerful serving stack called DJL serving that is agnostic to the underlying LLM. It provides system-level configuration parameters that can be tuned for extracting the best performance of the hosting infrastructure for a given LLM. It also has support for recent optimizations like continuous batching, also known as iterative batching or rolling batching, which provides significant improvements in throughput.
In an earlier post, we showed how you can use the LMI container to deploy the Falcon family of models on SageMaker. In this post, we demonstrate how to improve the throughput and latency of serving Falcon-40B with techniques like continuous batching. We also provide an intuitive understanding of configuration parameters provided by the SageMaker LMI container that can help you find the best configuration for your real-world application.
Fundamentals of text-generative inference for LLMs
Let’s first look at a few fundamentals on how to perform inference for LLMs for text generation.
Forward pass, activations, and the KV cache
Given an input sequence of tokens, they are run in a forward pass across all the layers of the LLM (like Falcon) to generate the next token. A forward pass refers to the process of input data being passed through a neural network to produce an output. In the case of text generation, the forward pass involves feeding an initial seed or context into the language model and generating the next character or token in the sequence. To generate a sequence of text, the process is often done iteratively, meaning it is repeated for each step or position in the output sequence. At each iteration, the model generates the next character or token, which becomes part of the generated text, and this process continues until the desired length of text is generated.
Text generation with language models like Falcon or GPT are autoregressive. This means that the model generates one token at a time while conditioning on the previously generated tokens. In other words, at each iteration, the model takes the previously generated text as input and predicts the next token based on that context. As mentioned in vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention, in this autoregressive decoding process, all the input tokens to the LLM produce their attention key and value tensors, and these tensors are kept in GPU memory to generate next tokens. These cached key and value tensors are often referred to as the KV cache.
Prefill and decode phases
In an autoregressive decoding process, like the one used in text generation with language models such as Falcon, there are typically two main phases: the prefill phase and the decode phase. These phases are crucial for generating coherent and contextually relevant text.
The prefill phase includes the following:
- Initial context – The prefill phase begins with an initial context or seed text provided by the user. This initial context can be a sentence, a phrase, or even just a single word. It sets the starting point for text generation and provides context for what comes next.
- Model conditioning – The provided context is used to condition the language model. The model takes this context as input and generates the next token (word or character) in the sequence based on its understanding of the context.
- Token generation – The model generates one token at a time, predicting what should come next in the text. This token is appended to the context, effectively extending it.
- Iterative process – The process of generating tokens is repeated iteratively. At each step, the model generates a token while considering the updated context, which now includes the tokens generated in previous steps.
The prefill phase continues until a predetermined stopping condition is met. This condition can be a maximum length for the generated text, a specific token that signals the end of the text, or any other criteria set by the user or the application.
The decode phase includes the following:
- Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct.
- Continuation from the last token – In the decode phase, the model starts from the last token generated during the prefill phase. It uses this token as the initial context and generates the next token to continue the text.
- Iterative completion – Like in the prefill phase, the process of generating tokens is again iterative. The model generates one token at a time, conditioning on the preceding tokens in the sequence.
- Stopping condition – The decode phase also has a stopping condition, which might be the same as in the prefill phase, such as reaching a maximum length or encountering an end-of-text token. When this condition is met, the generation process stops.
The combination of the prefill and decode phases allows autoregressive models to generate text that builds on an initial context and produces coherent, contextually relevant, and contextually consistent sequences of text.
Refer to A Distributed Serving System for Transformer-Based Generative Models for a detailed explanation of the process.
Optimizing throughput using dynamic batching
So far, we’ve only talked about a single input. In practice, we expect to deal with multiple requests coming in randomly from the application clients for inference concurrently or in a staggered fashion. In the traditional way, basic batching can be used to increase the throughput and the utilization of the computing resources of the GPU. Batching is effectively combining the numerical representations of more than one request in a batch and performing parallel runs of the autoregressive forward passes. This intelligent batching is done at the serving side. SageMaker LMI’s DJLServing server can be configured to batch together multiple requests to process them in parallel by setting the following parameters in serving.properties:
- max_batch_delay = 100 – The maximum delay for batch aggregation in milliseconds. The default value is 100 milliseconds.
- batch_size = 32 – The dynamic batch size. The default is 1.
This basically shows that DJLServing will queue up requests for 100 milliseconds at a time or if the number of requests that are queued up are up to the batch_size specified, the batch will be scheduled to run to the backend for inference. This is known as dynamic batching. It’s dynamic because the batch size may change across batches depending on how many requests were added in that time duration. However, because requests might have different characteristics, (for example, some requests might be of shape 20 tokens of input and 500 tokens of output, whereas others might be reversed, with 500 tokens of input but only 20 for output), some requests might complete processing faster than others in the same batch. This could result in underutilization of the GPU while waiting for all in-flight requests in the batch to complete its decode stage, even if there are additional requests waiting to be processed in the queue. The following diagram illustrates this process.
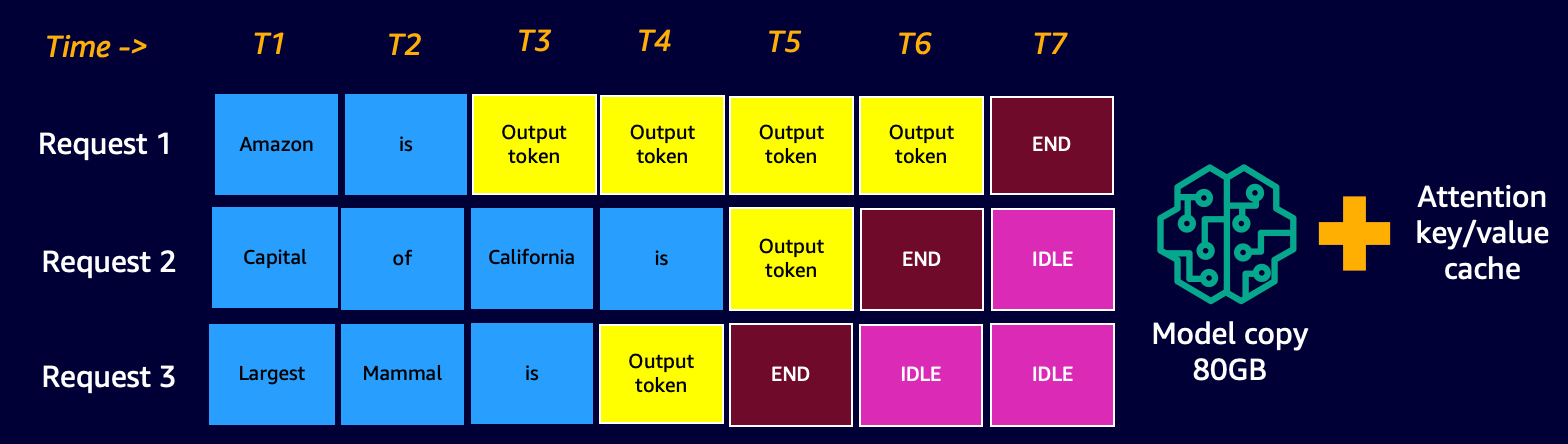
Dynamic Batching Visual – notice the idle windows at the end of Request 2 and 3
Optimizing throughput using continuous batching
With continuous batching, also known as iterative or rolling batching, we take advantage of the differences between the prefill and decode stages. To activate continuous batching, DJServing provides the following additional configurations as per serving.properties:
- engine=MPI – We encourage you to use the MPI engine for continuous batching.
- option.rolling_batch=auto or lmi-dist – We recommend using auto because it will automatically pick the most appropriate rolling batch algorithm along with other optimizations in the future.
- option.max_rolling_batch_size=32 – This limits the number of concurrent requests. The default is 32.
With continuous batching, the serving stack (DJLServing) doesn’t wait for all in-flight requests in a batch to complete its decode stage. Rather, at logical breaks (at the end of one iteration in the decode stage), it pulls in additional requests that are waiting in the queue while the current batch is still processing (hence the name rolling batch). It does this check for pending requests at the end of each iteration of the decode stage. Remember, for each request, we need to run the prefill stage followed by the sequential decode stage. Because we can process all the tokens from the initial prompt of a request in parallel for its prefill stage, anytime a new request is pulled in, we temporarily pause the decode stage of in-flight requests of the batch—we temporarily save its KV cache and activations in memory and run the prefill stage of the new requests.
The size of this cache can be configured with the following option:
- option.max_rolling_batch_prefill_tokens=1024 – Limits the number of simultaneous prefill tokens saved in the cache for the rolling batch (between the decode and the prefill stages)
When the prefill is complete, we combine the new requests and the old paused requests in a new rolling batch, which can proceed with their decode stage in parallel. Note that the old paused requests can continue their decode stage where they left off and the new requests will start from their first new token.
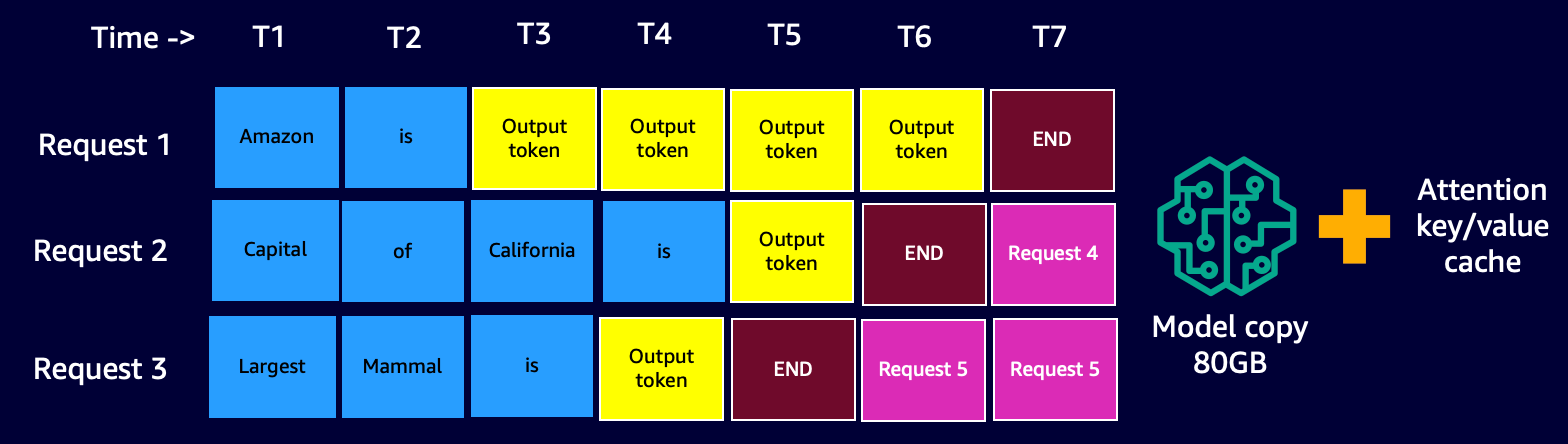
Continuous or Iterative Batching Visual – notice that the idle times are replaced with follow on requests
You might have already realized that continuous batching is an almost similar approach with which we naturally parallelize tasks in our daily lives. We have messages, emails, phone notifications (potentially new requests) coming in at random times (analogous to multiple requests coming in a random staggered fashion for GPUs). This is all happening while we go about completing our in-flight tasks—composing emails, coding, participating in meetings (analogous to the currently processing tasks in the GPUs). At logical breaks, we pause our in-flight tasks and check our notifications to decide if there is some action required on our part, and if there is, we add it to our in-flight tasks (real-life rolling batch), or put it on a to-do list (the queue).
Putting it all together: How to think about memory utilization of GPUs
It’s recommended to load test your model to see which configuration is the most cost-effective for your business use case. To build an understanding, let’s visualize the memory footprint of the GPUs as the model is loaded and as successive requests are processed in a rolling batch. For this post, let’s assume we are loading the Falcon-40B model onto one of the G5 instance types instance that are installed with NVIDIA A10G GPUs, each with 24 GB of memory. Note that a similar understanding is applicable for the p3, p4, and p5 instance types, which come with the V100, A100, and H100 GPU series.
The following is the overview of getting an approximate value of total memory required to serve Falcon-40B:
- Model size = Number of model parameters (40 billion for Falcon-40B) x 4 bytes per parameter (for FP32) = 160 GB
- Approximate total memory required to load Falcon-40B for inference = Model size (=160 GB) + KV Cache (Attention Cache) (=*20 GB) + Additional memory overhead by ML Frameworks (approximately 2 GB)

Memory Visual – Understanding the memory footprint of a loaded Falcon-40B model
For Falcon-40B, if we compress the model by quantizing the model to the bfloat16 (2 bytes) data type, the model size becomes approximately 80 GB. As you can see, this is still larger than the memory supported by one accelerator device, so we need to adopt a model partitioning (sharding) technique with a special tensor parallelism (TP) approach and shard the model across multiple accelerator devices. Let’s assume that we have chosen g5.24xlarge, which has 4 A10G GPU devices. If we configure DJLServing (serving.properties) with the following, we can expect that the 80 GB of model weights will be divided equally across all 4 GPUs:
- option.tensor_parallel_degree = 4 or 8, or use max (maximum GPUs detected on the instance)
With tensor_parallel_degree set to 4, about 20 GB of the 24 GB GPU memory (approximately 84%) is already utilized even before a single request has been processed. The remaining 16% of the GPU will be used for the KV cache for the incoming requests. It’s possible that for your business scenario and its latency and throughput requirements, 2–3 GB of the remaining memory is more than enough. If not, you can increase the instance size to g5.48xlarge, which has 8 GPUs and uses tensor_parallel_degree set to 8. In such a case, only approximately 10 GB of the available 24 GB memory of each GPU is utilized for model weights and we have about 60% of the remaining GPU for the activations and KV cache. Intuitively, we can see that this configuration may allow us to have a higher throughput. Additionally, because we have a larger buffer now, we can increase the max_rolling_batch_prefill_tokens and max_rolling_batch_size parameters to further optimize the throughput. Together, these two parameters will control the preallocations of the activation prefills and KV cache for the model. A larger number for these two parameters will co-relate to a larger throughput, assuming you have enough buffer for the KV cache in the GPU memory.
Continuous batching with PagedAttention
PagedAttention is a new optimization algorithm developed by UC Berkeley that improves the continuous batching process by allowing the attention cache (KV cache) to be non-contiguous by allocating memory in fixed-size pages or blocks. This is inspired by virtual memory and paging concepts used by operating systems.
As per the vLLM paper, the attention cache of each sequence of tokens is partitioned into blocks and mapped to physical blocks through a block table. During the computation of attention, a PagedAttention kernel can use the block table to efficiently fetch the blocks from physical memory. This results in a significant reduction of memory waste and allows for larger batch size, increased GPU utilization, and higher throughput.
Performance comparison
To ensure effective load testing of your deployment configuration, it’s recommended to begin by considering the business scenario and clearly defining the characteristics of the input and output for the LLM-based application. For instance, if you are working on a call center summarization use case, the input could consist of larger text, such as a 500-token chat transcript between a customer service agent and a customer, but the output might be relatively smaller, around 100 tokens, representing a summary of the transcript. On the other hand, if you’re working on a code generation scenario, the input could be as short as 15 tokens, like “write an efficient implementation in Python for describing all EC2 resources, including pagination,” but the output could be much larger, reaching 500 tokens. It’s also important to consider whether achieving lower latency or maximizing throughput is the top priority for your specific scenario.
After gaining a comprehensive understanding of the business scenario, you can analyze and determine the optimal configuration for your hosting environment. In this context, the hosting environment encompasses various key elements, including the instance type and other configuration parameters such as tensor_parallel_degree, max_rolling_batch_size, max_rolling_batch_prefill_tokens, and more. Our objective is to identify the most effective setup to support our response time, throughput, and model output quality requirements.
In our analysis, we benchmarked the performance to illustrate the benefits of continuous batching over traditional dynamic batching. We used the configurations detailed in the following table in serving.properties for dynamic batching and iterative batching, using an LMI container on SageMaker.
| Dynamic Batching | Continuous Batching | Continuous Batching with PagedAttention |
|
engine=Python option.model_id=tiiuae/falcon-40b option.tensor_parallel_degree=8 option.dtype=fp16 batch_size=4 max_batch_delay=100 option.trust_remote_code = true |
engine = MPI option.model_id = {{s3_url}} option.trust_remote_code = true option.tensor_parallel_degree = 8 option.max_rolling_batch_size = 32 option.rolling_batch = auto option.dtype = fp16 option.max_rolling_batch_prefill_tokens = 1024 option.paged_attention = False |
engine = MPI option.model_id = {{s3_url}} option.trust_remote_code = true option.tensor_parallel_degree = 8 option.max_rolling_batch_size = 32 option.rolling_batch = auto option.dtype = fp16 option.max_rolling_batch_prefill_tokens = 1024 option.paged_attention = True |
The two configurations were benchmarked for Falcon-40B with the FP16 data type deployed on ml.g5.48xlarge in a couple of different scenarios that represent real-world applications:
- A small number of input tokens with a large number of tokens being generated – In this scenario, number of input tokens was fixed at 32 and 128 new tokens were generated
| Batching Strategy | Throughput (tokens/sec) | Latency p90 (secs) |
| Dynamic Batching | 5.53 | 58.34 |
| Continuous Batching | 56.04 | 4.74 |
| Continuous Batching with PagedAttention | 59.18 | 4.76 |
- A large input with a small number of tokens being generated – Here, we fix the number of input tokens at 256 and prompt the LLM to summarize the input to 32 tokens
| Batching Strategy | Throughput (tokens/sec) | Latency p90 (secs) |
| Dynamic Batching | 19.96 | 59.31 |
| Continuous Batching | 46.69 | 3.88 |
| Continuous Batching with PagedAttention | 44.75 | 2.67 |
We can see that continuous batching with PagedAttention provides a throughput improvement of 10 times greater in scenario 1 and 2.3 times in scenario 2 compared to using dynamic batching on SageMaker while using the LMI container.
Conclusion
In this post, we looked at how LLMs use memory and explained how continuous batching improves the throughput using an LMI container on SageMaker. We demonstrated the benefits of continuous batching for Falcon-40B using an LMI container on SageMaker by showing benchmark results. You can find the code on the GitHub repo.
About the Authors
 Abhi Shivaditya is a Senior Solutions Architect at AWS, working with strategic global enterprise organizations to facilitate the adoption of AWS services in areas such as Artificial Intelligence, distributed computing, networking, and storage. His expertise lies in Deep Learning in the domains of Natural Language Processing (NLP) and Computer Vision. Abhi assists customers in deploying high-performance machine learning models efficiently within the AWS ecosystem.
Abhi Shivaditya is a Senior Solutions Architect at AWS, working with strategic global enterprise organizations to facilitate the adoption of AWS services in areas such as Artificial Intelligence, distributed computing, networking, and storage. His expertise lies in Deep Learning in the domains of Natural Language Processing (NLP) and Computer Vision. Abhi assists customers in deploying high-performance machine learning models efficiently within the AWS ecosystem.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
 Pinak Panigrahi works with customers to build machine learning driven solutions to solve strategic business problems on AWS. When not occupied with machine learning, he can be found taking a hike, reading a book or watching sports.
Pinak Panigrahi works with customers to build machine learning driven solutions to solve strategic business problems on AWS. When not occupied with machine learning, he can be found taking a hike, reading a book or watching sports.
 Abhi Sodhani holds the position of Senior AI/ML Solutions Architect at AWS, where he specializes in offering technical expertise and guidance on Generative AI and ML solutions to customers. His primary focus is to assist Digital Native Businesses in realizing the full potential of Generative AI and ML technologies, enabling them to achieve their business objectives effectively. Beyond his professional endeavors, Abhi exhibits a strong passion for intellectual pursuits such as reading, as well as engaging in activities that promote physical and mental well-being, such as yoga, meditation.
Abhi Sodhani holds the position of Senior AI/ML Solutions Architect at AWS, where he specializes in offering technical expertise and guidance on Generative AI and ML solutions to customers. His primary focus is to assist Digital Native Businesses in realizing the full potential of Generative AI and ML technologies, enabling them to achieve their business objectives effectively. Beyond his professional endeavors, Abhi exhibits a strong passion for intellectual pursuits such as reading, as well as engaging in activities that promote physical and mental well-being, such as yoga, meditation.
 Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.