AWS Machine Learning Blog
Improve newspaper digitalization efficacy with a generic document segmentation tool using Amazon Textract
We are living in a digital age. Information that used to be spread by printouts is disseminated at unforeseen speeds through digital formats. In parallel to the inventions of new types of media, an increasing number of archives and libraries are trying to create digital repositories with new technologies. Digitization allows for preservation by creating an accessible surrogate, while at the same time enabling easier storage, indexing, and faster search.
In this post, we demonstrate how to efficiently digitize newspaper articles using Amazon Textract with a document segmentation module. Amazon Textract is a fully managed machine learning (ML) service that automatically extracts text and data from scanned documents. For this use case, we show how the customized segmentation tool further augments Amazon Textract to recognize small and old German fonts despite low image quality. Our proposed solution expands the capabilities of Amazon Textract in the following ways:
- Provides additional support for Amazon Textract to handle documents with complex structures and style (such as columnar texts with varying width, text blocks floating around images, texts nested within images and tables, and fonts with varying size and style)
- Overcomes the 10 MB image (such as JPEG and PNG format) size limit of Amazon Textract for large documents
Our generic document segmentation module intelligently segments the document with awareness of its layout—we can crop a large image file into smaller pieces that are consistent with the layout. Then each smaller image is under the 10 MB limit while the original resolution is maintained for optimal OCR results. Another benefit of this segmentation tool is that the extracted texts from the detected segments are correctly ordered and grouped following human reading habits. Raw Amazon Textract OCR results of a newspaper image can’t be automatically grouped into meaningful sentences without knowing which segment (or article) each word belongs to. In fact, segmenting a page into different regions with different context is a common practice in existing pipelines of historical document digitalization.
In the following sections, we show the process of developing a Fully Convolutional Network (FCN) based document segmentation engine with Amazon SageMaker and Amazon SageMaker Ground Truth. After applying the segmentation model on test newspaper images, it was able to distinguish between background, pictures, headlines, and different articles. We compared the word count with the out-of-the-box Amazon Textract as a proxy for word recall. For our specific use case (old, low-quality images of newspapers with small and old styled fonts in a complex layout), our solution was able to pick up more words consistently after cropping the image and sending the segments to Amazon Textract instead of the full page.
You can easily adapt this end-to-end workflow to any document layout analysis and use Amazon Textract to handle various context-aware text extraction tasks.
Solution pipeline
The end-to-end pipeline is shown in the following figure. The key idea is to add a segmentation step to split the newspaper into smaller segments according to its layout and feed each segment to Amazon Textract so that both image file size and image resolution thresholds are met in order to obtain high-quality text OCR results for each segment. We then concatenate results of all segments in an appropriate read order. The segmentation model is trained with Amazon SageMaker.

BBZ newspaper dataset
We trained the segmentation model based on a collection of historical Berliner Borsen-Zeitung (BBZ) newspapers. BBZ was a German newspaper published 1855–1944. Its layout was relatively complex, containing text, images, separator lines, embellishing borders, and various complex, multi-column tables. For this use case, we used around 200 newspaper images.
Create segment labels using Amazon SageMaker Ground Truth
We used Amazon SageMaker Ground Truth to create the segment labels for training. Ground Truth is a fully managed data labeling service that makes it easy to build highly accurate training datasets for ML. Ground Truth has several built-in labeling workflows, including object detection, image classification, text classification, and semantic segmentation.
Because our goal was to train a segmentation model, we created a semantic segmentation labeling task with five classes after browsing the dataset: article, image, advertisement, table, and title. The following images show examples of newspaper images with the segment labels. These labels were saved in a JSON format on Amazon Simple Storage Service (Amazon S3) and later processed to feed into the model data loader.

For more information about creating semantic segmentation labels, see Image Semantic Segmentation and this Amazon SageMaker Ground Truth – Build Highly Accurate Datasets and Reduce Labeling Costs by up to 70%.
Track labeling progress
Because we only used approximately 200 images, we created a private labeling workforce of four people for this labeling task. When using your own private team to perform data labeling, you may want to evenly split up the labeling work and track each worker’s throughput and efficiency. Ground Truth now logs worker events (for example, when a labeler starts and submits a task) to Amazon CloudWatch. In addition, you can use the built-in metrics feature of CloudWatch to measure and track throughput across a work team or for individual workers. For example, we can track each person’s progress (images labeled and hours spent) as shown in the following dashboard.

For more information, see Tracking the throughput of your private labeling team through Amazon SageMaker Ground Truth.
Customized semantic segmentation for newspaper
Inspired by a previous study that shows a semantic segmentation approach based on the visual appearance of the document, we developed a customized FCN semantic segmentation model for our use case. We trained the model from scratch with random weights initialization. The fully convolutional neural network includes the following components:
- Feature extraction down-sampling convolution
- Upscaling deconvolution
- Refinement convolution
- A classification layer that classifies the pixels into classes
The detailed network architecture is shown in the following figure (the refinement blocks aren’t shown given the size limit). To simplify the training task, we grouped all of the content blocks (articles, images, advertisements, tables, and titles) as foreground and kept other regions as the background. As part of feature extraction, the information in an image can be captured and encoded through convolution and max pooling. Then the deconvolution network decodes the downsized image and upscales it back to the original size. Finally, we applied a sigmoid function to make a pixel-level classification with probabilities.
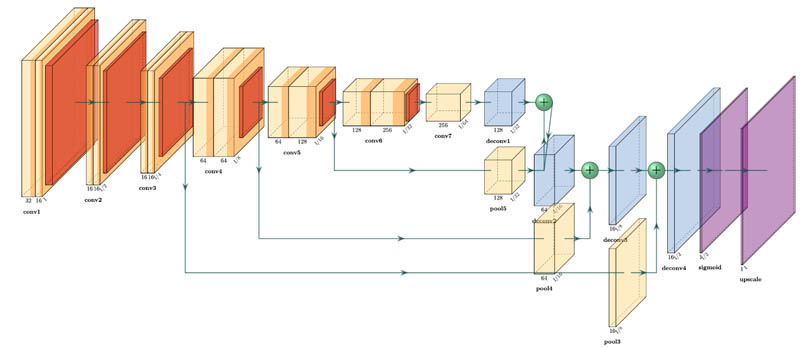
To fine-tune the model, we first generated masks from the ground truth bounding boxes of labeled segments that are needed to train the FCN model. The images and corresponding masks were resized to 512 x 512 and randomly combined into batches of 8 samples to be fed into the neural network. A weighted loss was applied to guarantee that the model wasn’t affected by the imbalance between the foreground and the background. The FCN model was trained on SageMaker with a ml.p3.8xlarge notebook instance. After training 100 epochs, the pixel-level accuracy of this semantic segmentation model was 0.90 on foreground pixels and 0.82 for background pixels on the test data.
Masks to bounding boxes conversion
Because the output of the FCN is a binary variable for each pixel, the boundary of each segment isn’t a rectangle and can’t be readily used to crop the newspaper. We developed a morphology-based algorithm to convert masks into regions, as illustrated in the following figure.
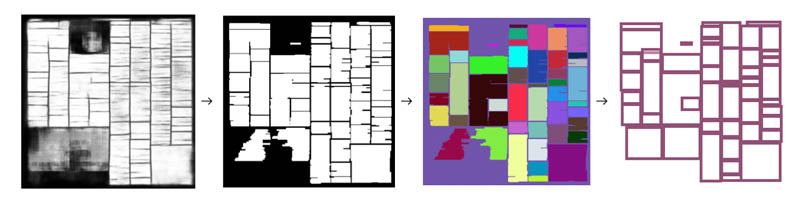
The steps of the algorithm are as follows:
- Binarize masks based on a threshold value obtained experimentally.
- Apply morphological operations (e.g. dilation and erosion) on the binarized image.
- Apply a flood fill algorithm to build connected components.
- Get the bounding boxes for each connected component by finding the minimum and maximum x and y coordinates.
Among the preceding steps, morphological operations are a broad set of image processing operations that process images based on shapes. These operations create a modified image of the same size after applying a structuring element to the initial image. They work similarly as convolutions in the convolutional neural networks except the weights of the structuring elements are fixed. Specifically, the value of each pixel in the output is derived from a certain form of summation or gradient of its neighboring pixels determined by the weights of the chosen structuring element. The purpose of such operations is to either enhance or dampen the features of interest. For example, the effect of morphological dilation makes objects more visible and fills in small holes in objects, and the effect of erosion is to remove isolated small regions.
Bounding box postprocessing
The resulting bounding boxes that we obtained from the mask conversion had the following defects:
- Overlapping bounding boxes
- Gaps between bounding boxes and imperfect column-wise alignment
- Overly fragmented segments (too many small segments)
We developed further postprocessing steps to alleviate these defects. The quality of the regions’ bounding boxes needed to be improved for the following reasons:
- To minimize the Amazon Textract API usage to reduce the compute costs because each segment incurs an Amazon Textract API call
- To avoid the same region to be processed repeatedly, which results in redundant text
- To avoid cutting a word or completely missing a word at the boundary of the segments
To remove overlapping bounding boxes, we applied simple intersection over union (IoU) thresholding. That is, if two bounding boxes intersect with each other, we compute the IoU ratio (area of overlap or area of union) between the two. We chose the IoU threshold to be 80% through experimentation, which meant that if the IoU is over 80%, we removed the smaller bounding box of the two.
When we looked closer at the boundary of the segments, we spotted gaps still existing between raw bounding boxes, and the bounding boxes weren’t perfectly aligned. Those regions often had text that we didn’t want to lose.
To remove gaps between bounding boxes and better align the boundaries, we clustered the raw bounding boxes in groups based on the Euclidean distances of the centroid of each bounding box and retained only the corner vertices of the cluster. This way, all the smaller bounding boxes whose centroids were close were combined together with only one aligned boundary.
We incorporated further steps to merge bounding boxes. For example, if bounding boxes were vertically aligned in a same column segment, we merged the neighboring vertically aligned bounding boxes.
Finally, we sorted the bounding boxes by the coordinates, according to a human read order from top to bottom, and left to right. The following images show an example of before and after postprocessing.

Quantify the benefit of the additional segmentation step
Given that we did not have the ground truth for the text in the newspapers, we used word count as a proxy of the word recall metric to evaluate the information gains by adding the segmentation step.
In the following figure, each dot represents one test sample image. The X axis represents the number of words extracted by Amazon Textract without segmentation, and the Y axis is the number of words from the concatenated articles with segmentation. We found that in general the number of words Amazon Textract recognized increased by zooming onto the segments of the newspaper. On average, the word count increased by 97%.
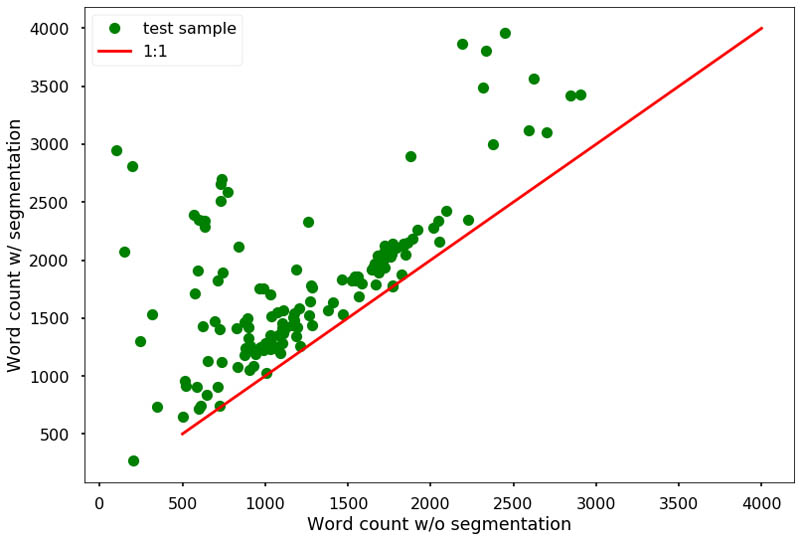
The word count increase is most significant for the pages of “Kurszettel der Berliner Börsen-Zeitung” (stock list of Berlin Stock-Newspaper in English). The following image shows such a comparison. The recognized words by Amazon Textract are highlighted by the small bounding boxes. The left image shows the words recognized by Amazon Textract using the full page. The right image shows the words recognized by feeding the cropped parts to Amazon Textract. For this specific example, the number of words increased from 100 to 2,945.

Summary
We developed a custom neural network-based document segmentation engine on Amazon SageMaker. Together, with Amazon Textract, it provides an optimal text extraction solution for newspapers. The segmentation module we used as a preprocessing step strengthened Amazon Textract to better handle documents with complex layouts, such as newspapers. The additional segmentation step also helped improve the quality of extraction for texts of small font sizes and lower resolution by zooming in each segment of the document.
If you want help with accelerating the use of ML in your products and services, please contact the Amazon ML Solutions Lab program. The Amazon ML Solutions Lab pairs your team with ML experts to help you identify and build ML solutions to address your organization’s highest return on investment ML opportunities. Through discovery workshops and ideation sessions, the ML Solutions Lab works backward from your business problems to deliver a roadmap of prioritized ML use cases with an implementation plan to address them.
About the Authors
 Guang Yang is a data scientist at the Amazon ML Solution Lab where he works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art ML/AI solutions.
Guang Yang is a data scientist at the Amazon ML Solution Lab where he works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art ML/AI solutions.

Wenzhen Zhu is a data scientist with the Amazon ML Solution Lab team at Amazon Web Services. She leverages Machine Learning and Deep Learning to solve diverse problems across industries for AWS customers.
 Suchitra Sathyanarayana is a manager at the Amazon ML Solutions Lab, where she helps AWS customers across different industry verticals accelerate their AI and cloud adoption. She holds a PhD in Computer Vision from Nanyang Technological University, Singapore.
Suchitra Sathyanarayana is a manager at the Amazon ML Solutions Lab, where she helps AWS customers across different industry verticals accelerate their AI and cloud adoption. She holds a PhD in Computer Vision from Nanyang Technological University, Singapore.
 Raj Biswas is a Data Scientist at the Amazon Machine Learning Solutions Lab. He helps AWS customers to develop machine learning powered solutions across diverse industry verticals for their most pressing business challenges. Prior to joining AWS, he was a graduate student at Columbia University in Data Science.
Raj Biswas is a Data Scientist at the Amazon Machine Learning Solutions Lab. He helps AWS customers to develop machine learning powered solutions across diverse industry verticals for their most pressing business challenges. Prior to joining AWS, he was a graduate student at Columbia University in Data Science.

Tianyu Zhang is a data scientist at the Amazon ML Solutions Lab. He helps AWS customers solve business problems by applying ML and AI techniques. Most recently, he has built NLP model and predictive model for procurement and sports.