Artificial Intelligence
How VMware built an MLOps pipeline from scratch using GitLab, Amazon MWAA, and Amazon SageMaker
This post is co-written with Mahima Agarwal, Machine Learning Engineer, and Deepak Mettem, Senior Engineering Manager, at VMware Carbon Black
VMware Carbon Black is a renowned security solution offering protection against the full spectrum of modern cyberattacks. With terabytes of data generated by the product, the security analytics team focuses on building machine learning (ML) solutions to surface critical attacks and spotlight emerging threats from noise.
It is critical for the VMware Carbon Black team to design and build a custom end-to-end MLOps pipeline that orchestrates and automates workflows in the ML lifecycle and enables model training, evaluations, and deployments.
There are two main purposes for building this pipeline: support the data scientists for late-stage model development, and surface model predictions in the product by serving models in high volume and in real-time production traffic. Therefore, VMware Carbon Black and AWS chose to build a custom MLOps pipeline using Amazon SageMaker for its ease of use, versatility, and fully managed infrastructure. We orchestrate our ML training and deployment pipelines using Amazon Managed Workflows for Apache Airflow (Amazon MWAA), which enables us to focus more on programmatically authoring workflows and pipelines without having to worry about auto scaling or infrastructure maintenance.
With this pipeline, what once was Jupyter notebook-driven ML research is now an automated process deploying models to production with little manual intervention from data scientists. Earlier, the process of training, evaluating, and deploying a model could take over a day; with this implementation, everything is just a trigger away and has reduced the overall time to few minutes.
In this post, VMware Carbon Black and AWS architects discuss how we built and managed custom ML workflows using Gitlab, Amazon MWAA, and SageMaker. We discuss what we achieved so far, further enhancements to the pipeline, and lessons learned along the way.
Solution overview
The following diagram illustrates the ML platform architecture.
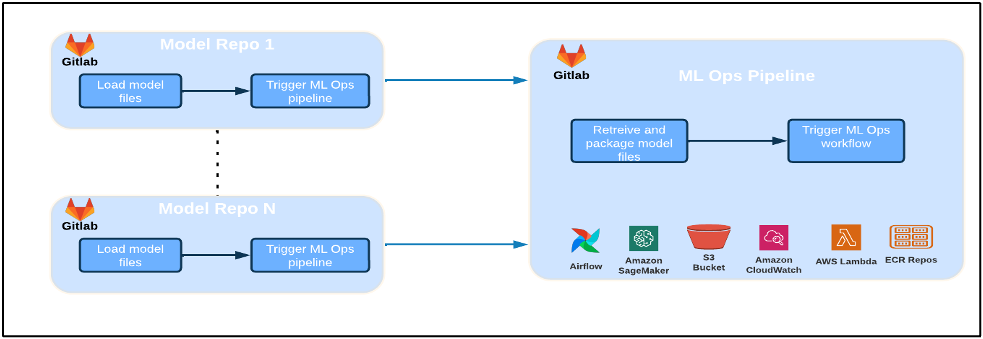
High level Solution Design
This ML platform was envisioned and designed to be consumed by different models across various code repositories. Our team uses GitLab as a source code management tool to maintain all the code repositories. Any changes in the model repository source code are continuously integrated using the Gitlab CI, which invokes the subsequent workflows in the pipeline (model training, evaluation, and deployment).
The following architecture diagram illustrates the end-to-end workflow and the components involved in our MLOps pipeline.
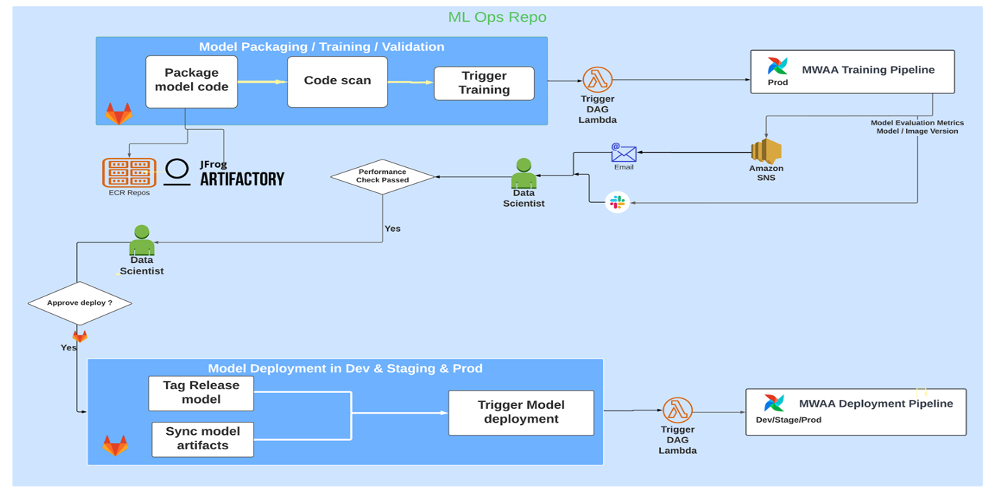
End-To-End Workflow
The ML model training, evaluation, and deployment pipelines are orchestrated using Amazon MWAA, referred to as a Directed Acyclic Graph (DAG). A DAG is a collection of tasks together, organized with dependencies and relationships to say how they should run.
At a high level, the solution architecture includes three main components:
- ML pipeline code repository
- ML model training and evaluation pipeline
- ML model deployment pipeline
Let’s discuss how these different components are managed and how they interact with each other.
ML pipeline code repository
After the model repo integrates the MLOps repo as their downstream pipeline, and a data scientist commits code in their model repo, a GitLab runner does standard code validation and testing defined in that repo and triggers the MLOps pipeline based on the code changes. We use Gitlab’s multi-project pipeline to enable this trigger across different repos.
The MLOps GitLab pipeline runs a certain set of stages. It conducts basic code validation using pylint, packages the model’s training and inference code within the Docker image, and publishes the container image to Amazon Elastic Container Registry (Amazon ECR). Amazon ECR is a fully managed container registry offering high-performance hosting, so you can reliably deploy application images and artifacts anywhere.
ML model training and evaluation pipeline
After the image is published, it triggers the training and evaluation Apache Airflow pipeline through the AWS Lambda function. Lambda is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers.
After the pipeline is successfully triggered, it runs the Training and Evaluation DAG, which in turn starts the model training in SageMaker. At the end of this training pipeline, the identified user group gets a notification with the training and model evaluation results over email through Amazon Simple Notification Service (Amazon SNS) and Slack. Amazon SNS is fully managed pub/sub service for A2A and A2P messaging.
After meticulous analysis of the evaluation results, the data scientist or ML engineer can deploy the new model if the performance of the newly trained model is better compared to the previous version. The performance of the models is evaluated based on the model-specific metrics (such as F1 score, MSE, or confusion matrix).
ML model deployment pipeline
To start deployment, the user starts the GitLab job that triggers the Deployment DAG through the same Lambda function. After the pipeline runs successfully, it creates or updates the SageMaker endpoint with the new model. This also sends a notification with the endpoint details over email using Amazon SNS and Slack.
In the event of failure in either of the pipelines, users are notified over the same communication channels.
SageMaker offers real-time inference that is ideal for inference workloads with low latency and high throughput requirements. These endpoints are fully managed, load balanced, and auto scaled, and can be deployed across multiple Availability Zones for high availability. Our pipeline creates such an endpoint for a model after it runs successfully.
In the following sections, we expand on the different components and dive into the details.
GitLab: Package models and trigger pipelines
We use GitLab as our code repository and for the pipeline to package the model code and trigger downstream Airflow DAGs.
Multi-project pipeline
The multi-project GitLab pipeline feature is used where the parent pipeline (upstream) is a model repo and the child pipeline (downstream) is the MLOps repo. Each repo maintains a .gitlab-ci.yml, and the following code block enabled in the upstream pipeline triggers the downstream MLOps pipeline.
The upstream pipeline sends over the model code to the downstream pipeline where the packaging and publishing CI jobs get triggered. Code to containerize the model code and publish it to Amazon ECR is maintained and managed by the MLOps pipeline. It sends the variables like ACCESS_TOKEN (can be created under Settings, Access), JOB_ID (to access upstream artifacts), and $CI_PROJECT_ID (the project ID of model repo) variables, so that the MLOps pipeline can access the model code files. With the job artifacts feature from Gitlab, the downstream repo acceses the remote artifacts using the following command:
The model repo can consume downstream pipelines for multiple models from the same repo by extending the stage that triggers it using the extends keyword from GitLab, which allows you reuse the same configuration across different stages.
After publishing the model image to Amazon ECR, the MLOps pipeline triggers the Amazon MWAA training pipeline using Lambda. After user approval, it triggers the model deployment Amazon MWAA pipeline as well using the same Lambda function.
Semantic versioning and passing versions downstream
We developed custom code to version ECR images and SageMaker models. The MLOps pipeline manages the semantic versioning logic for images and models as part of the stage where model code gets containerized, and passes on the versions to later stages as artifacts.
Retraining
Because retraining is a crucial aspect of an ML lifecycle, we have implemented retraining capabilities as part of our pipeline. We use the SageMaker list-models API to identify if it’s retraining based on the model retraining version number and timestamp.
We manage the daily schedule of the retraining pipeline using GitLab’s schedule pipelines.
Terraform: Infrastructure setup
In addition to an Amazon MWAA cluster, ECR repositories, Lambda functions, and SNS topic, this solution also uses AWS Identity and Access Management (IAM) roles, users, and policies; Amazon Simple Storage Service (Amazon S3) buckets, and an Amazon CloudWatch log forwarder.
To streamline the infrastructure setup and maintenance for the services involved throughout our pipeline, we use Terraform to implement the infrastructure as code. Whenever infra updates are required, the code changes trigger a GitLab CI pipeline that we set up, which validates and deploys the changes into various environments (for example, adding a permission to an IAM policy in dev, stage and prod accounts).
Amazon ECR, Amazon S3, and Lambda: Pipeline facilitation
We use the following key services to facilitate our pipeline:
- Amazon ECR – To maintain and allow convenient retrievals of the model container images, we tag them with semantic versions and upload them to ECR repositories set up per
${project_name}/${model_name}through Terraform. This enables a good layer of isolation between different models, and allows us to use custom algorithms and to format inference requests and responses to include desired model manifest information (model name, version, training data path, and so on). - Amazon S3 – We use S3 buckets to persist model training data, trained model artifacts per model, Airflow DAGs, and other additional information required by the pipelines.
- Lambda – Because our Airflow cluster is deployed in a separate VPC for security considerations, the DAGs cannot be accessed directly. Therefore, we use a Lambda function, also maintained with Terraform, to trigger any DAGs specified by the DAG name. With proper IAM setup, the GitLab CI job triggers the Lambda function, which passes through the configurations down to the requested training or deployment DAGs.
Amazon MWAA: Training and deployment pipelines
As mentioned earlier, we use Amazon MWAA to orchestrate the training and deployment pipelines. We use SageMaker operators available in the Amazon provider package for Airflow to integrate with SageMaker (to avoid jinja templating).
We use the following operators in this training pipeline (shown in the following workflow diagram):
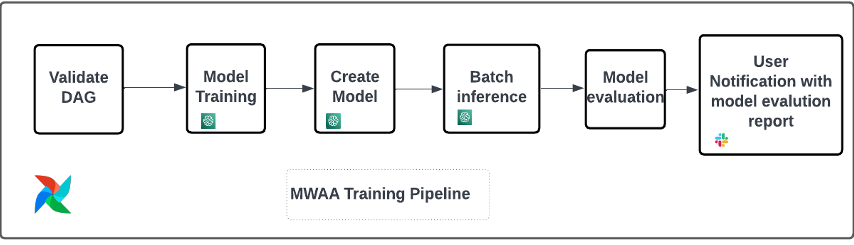
MWAA Training Pipeline
We use the following operators in the deployment pipeline (shown in the following workflow diagram):
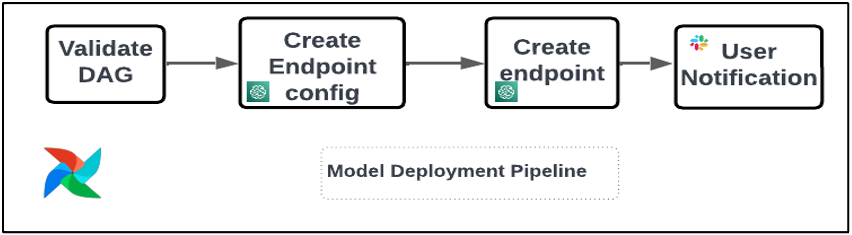
Model Deployment Pipeline
We use Slack and Amazon SNS to publish the error/success messages and evaluation results in both pipelines. Slack provides a wide range of options to customize messages, including the following:
- SnsPublishOperator – We use SnsPublishOperator to send success/failure notifications to user emails
- Slack API – We created the incoming webhook URL to get the pipeline notifications to the desired channel
CloudWatch and VMware Wavefront: Monitoring and logging
We use a CloudWatch dashboard to configure endpoint monitoring and logging. It helps visualize and keep track of various operational and model performance metrics specific to each project. On top of the auto scaling policies set up to track some of them, we continuously monitor the changes in CPU and memory usage, requests per second, response latencies, and model metrics.
CloudWatch is even integrated with a VMware Tanzu Wavefront dashboard so that it can visualize the metrics for model endpoints as well as other services at the project level.
Business benefits and what’s next
ML pipelines are very crucial to ML services and features. In this post, we discussed an end-to-end ML use case using capabilities from AWS. We built a custom pipeline using SageMaker and Amazon MWAA, which we can reuse across projects and models, and automated the ML lifecycle, which reduced the time from model training to production deployment to as little as 10 minutes.
With the shifting of the ML lifecycle burden to SageMaker, it provided optimized and scalable infrastructure for the model training and deployment. Model serving with SageMaker helped us make real-time predictions with millisecond latencies and monitoring capabilities. We used Terraform for the ease of setup and to manage infrastructure.
The next steps for this pipeline would be to enhance the model training pipeline with retraining capabilities whether it’s scheduled or based on model drift detection, support shadow deployment or A/B testing for faster and qualified model deployment, and ML lineage tracking. We also plan to evaluate Amazon SageMaker Pipelines because GitLab integration is now supported.
Lessons learned
As part of building this solution, we learned that you should generalize early, but don’t over-generalize. When we first finished the architecture design, we tried to create and enforce code templating for the model code as a best practice. However, it was so early on in the development process that the templates were either too generalized or too detailed to be reusable for future models.
After delivering the first model through the pipeline, the templates came out naturally based on the insights from our previous work. A pipeline can’t do everything from day one.
Model experimentation and productionization often have very different (or sometimes even conflicting) requirements. It is crucial to balance these requirements from the beginning as a team and prioritize accordingly.
Additionally, you might not need every feature of a service. Using essential features from a service and having a modularized design are keys to more efficient development and a flexible pipeline.
Conclusion
In this post, we showed how we built an MLOps solution using SageMaker and Amazon MWAA that automated the process of deploying models to production, with little manual intervention from data scientists. We encourage you to evaluate various AWS services like SageMaker, Amazon MWAA, Amazon S3, and Amazon ECR to build a complete MLOps solution.
*Apache, Apache Airflow, and Airflow are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
About the Authors
 Deepak Mettem is a Senior Engineering Manager in VMware, Carbon Black Unit. He and his team work on building the streaming based applications and services that are highly available, scalable and resilient to bring customers machine learning based solutions in real-time. He and his team are also responsible for creating tools necessary for data scientists to build, train, deploy and validate their ML models in production.
Deepak Mettem is a Senior Engineering Manager in VMware, Carbon Black Unit. He and his team work on building the streaming based applications and services that are highly available, scalable and resilient to bring customers machine learning based solutions in real-time. He and his team are also responsible for creating tools necessary for data scientists to build, train, deploy and validate their ML models in production.
 Mahima Agarwal is a Machine Learning Engineer in VMware, Carbon Black Unit.
Mahima Agarwal is a Machine Learning Engineer in VMware, Carbon Black Unit.
She works on designing, building, and developing the core components and architecture of the machine learning platform for the VMware CB SBU.
 Vamshi Krishna Enabothala is a Sr. Applied AI Specialist Architect at AWS. He works with customers from different sectors to accelerate high-impact data, analytics, and machine learning initiatives. He is passionate about recommendation systems, NLP, and computer vision areas in AI and ML. Outside of work, Vamshi is an RC enthusiast, building RC equipment (planes, cars, and drones), and also enjoys gardening.
Vamshi Krishna Enabothala is a Sr. Applied AI Specialist Architect at AWS. He works with customers from different sectors to accelerate high-impact data, analytics, and machine learning initiatives. He is passionate about recommendation systems, NLP, and computer vision areas in AI and ML. Outside of work, Vamshi is an RC enthusiast, building RC equipment (planes, cars, and drones), and also enjoys gardening.
 Sahil Thapar is an Enterprise Solutions Architect. He works with customers to help them build highly available, scalable, and resilient applications on the AWS Cloud. He is currently focused on containers and machine learning solutions.
Sahil Thapar is an Enterprise Solutions Architect. He works with customers to help them build highly available, scalable, and resilient applications on the AWS Cloud. He is currently focused on containers and machine learning solutions.