Artificial Intelligence
Fine-tune Falcon 7B and other LLMs on Amazon SageMaker with @remote decorator
Today, generative AI models cover a variety of tasks from text summarization, Q&A, and image and video generation. To improve the quality of output, approaches like n-short learning, Prompt engineering, Retrieval Augmented Generation (RAG) and fine tuning are used. Fine-tuning allows you to adjust these generative AI models to achieve improved performance on your domain-specific tasks.
With Amazon SageMaker, now you can run a SageMaker training job simply by annotating your Python code with @remote decorator. The SageMaker Python SDK automatically translates your existing workspace environment, and any associated data processing code and datasets, into an SageMaker training job that runs on the training platform. This has the advantage of writing the code in a more natural, object-oriented way, and still uses SageMaker capabilities to run training jobs on a remote cluster with minimal changes.
In this post, we showcase how to fine-tune a Falcon-7B Foundation Models (FM) using @remote decorator from SageMaker Python SDK. It also uses Hugging Face’s parameter-efficient fine-tuning (PEFT) library and quantization techniques through bitsandbytes to support fine-tuning. The code presented in this blog can also be used to fine-tune other FMs, such as Llama-2 13b.
The full precision representations of this model might have challenges to fit into memory on a single or even several Graphic Processing Units (GPUs) — or may even need a bigger instance. Hence, in order to fine-tune this model without increasing cost, we use the technique known as Quantized LLMs with Low-Rank Adapters (QLoRA). QLoRA is an efficient fine-tuning approach that reduces memory usage of LLMs while maintaining very good performance.
Advantages of using @remote decorator
Before going further, let’s understand how remote decorator improves developer productivity while working with SageMaker:
- @remote decorator triggers a training job directly using native python code, without the explicit invocation of SageMaker Estimators and SageMaker input channels
- Low barrier for entry for developers training models on SageMaker.
- No need to switch Integrated development environments (IDEs). Continue writing code in your choice of IDE and invoke SageMaker training jobs.
- No need to learn about containers. Continue providing dependencies in a
requirements.txtand supply that to remote decorator.
Prerequisites
An AWS account is needed with an AWS Identity and Access Management (AWS IAM) role that has permissions to manage resources created as part of the solution. For details, refer to Creating an AWS account.
In this post, we use Amazon SageMaker Studio with the Data Science 3.0 image and a ml.t3.medium fast launch instance. However, you can use any integrated development environment (IDE) of your choice. You just need to set up your AWS Command Line Interface (AWS CLI) credentials correctly. For more information, refer to Configure the AWS CLI.
For fine-tuning, the Falcon-7B, an ml.g5.12xlarge instance is used in this post. Please ensure sufficient capacity for this instance in AWS account.
You need to clone this Github repository for replicating the solution demonstrated in this post.
Solution overview
- Install pre-requisites to fine tuning the Falcon-7B model
- Set up remote decorator configurations
- Preprocess the dataset containing AWS services FAQs
- Fine-tune Falcon-7B on AWS services FAQs
- Test the fine-tune models on sample questions related to AWS services
1. Install prerequisites to fine tuning the Falcon-7B model
Launch the notebook falcon-7b-qlora-remote-decorator_qa.ipynb in SageMaker Studio by selecting the Image as Data Science and Kernel as Python 3. Install all the required libraries mentioned in the requirements.txt. Few of the libraries need to be installed on the notebook instance itself. Perform other operations needed for dataset processing and triggering a SageMaker training job.
2. Setup remote decorator configurations
Create a configuration file where all the configurations related to Amazon SageMaker training job are specified. This file is read by @remote decorator while running the training job. This file contains settings like dependencies, training image, instance, and the execution role to be used for training job. For a detailed reference of all the settings supported by config file, check out Configuring and using defaults with the SageMaker Python SDK.
It’s not mandatory to use the config.yaml file in order to work with the @remote decorator. This is just a cleaner way to supply all configurations to the @remote decorator. This keeps SageMaker and AWS related parameters outside of code with a one time effort for setting up the config file used across the team members. All the configurations could also be supplied directly in the decorator arguments, but that reduces readability and maintainability of changes in the long run. Also, the configuration file can be created by an administrator and shared with all the users in an environment.
Preprocess the dataset containing AWS services FAQs
Next step is to load and preprocess the dataset to make it ready for training job. First, let us have a look at the dataset:
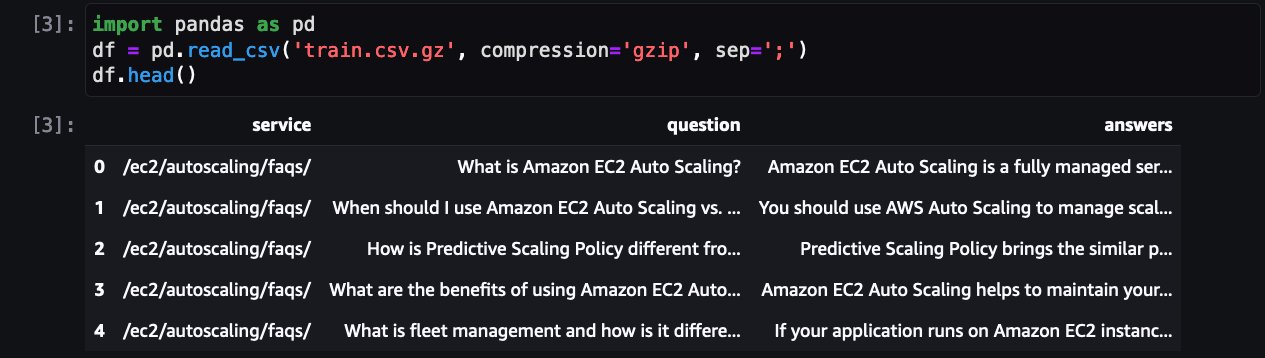
It shows FAQ for one of the AWS services. In addition to QLoRA, bitsanbytes is used to convert to 4-bit precision to quantize frozen LLM to 4-bit and attach LoRA adapters on it.
Create a prompt template to convert each FAQ sample to a prompt format:
Next step is to convert the inputs (text) to token IDs. This is done by a Hugging Face Transformers Tokenizer.
Now simply use the prompt_template function to convert all the FAQ to prompt format and set up train and test datasets.

4. Fine tune Falcon-7B on AWS services FAQs
Now you can prepare the training script and define the training function train_fn and put @remote decorator on the function.
The training function does the following:
- tokenizes and chunks the dataset
- set up
BitsAndBytesConfig, which specifies the model should be loaded in 4-bit but while computation should be converted tobfloat16. - Load the model
- Find target modules and update the necessary matrices by using the utility method
find_all_linear_names - Create LoRA configurations that specify ranking of update matrices (
s), scaling factor (lora_alpha), the modules to apply the LoRA update matrices (target_modules), dropout probability for Lora layers(lora_dropout),task_type, etc. - Start the training and evaluation
And invoke the train_fn()
The tuning job would be running on the Amazon SageMaker training cluster. Wait for tuning job to finish.
5. Test the fine tune models on sample questions related to AWS services
Now, it’s time to run some tests on the model. First, let us load the model:
Now load a sample question from the training dataset to see the original answer and then ask the same question from the tuned model to see the answer in comparison.
Here is a sample a question from training set and the original answer:
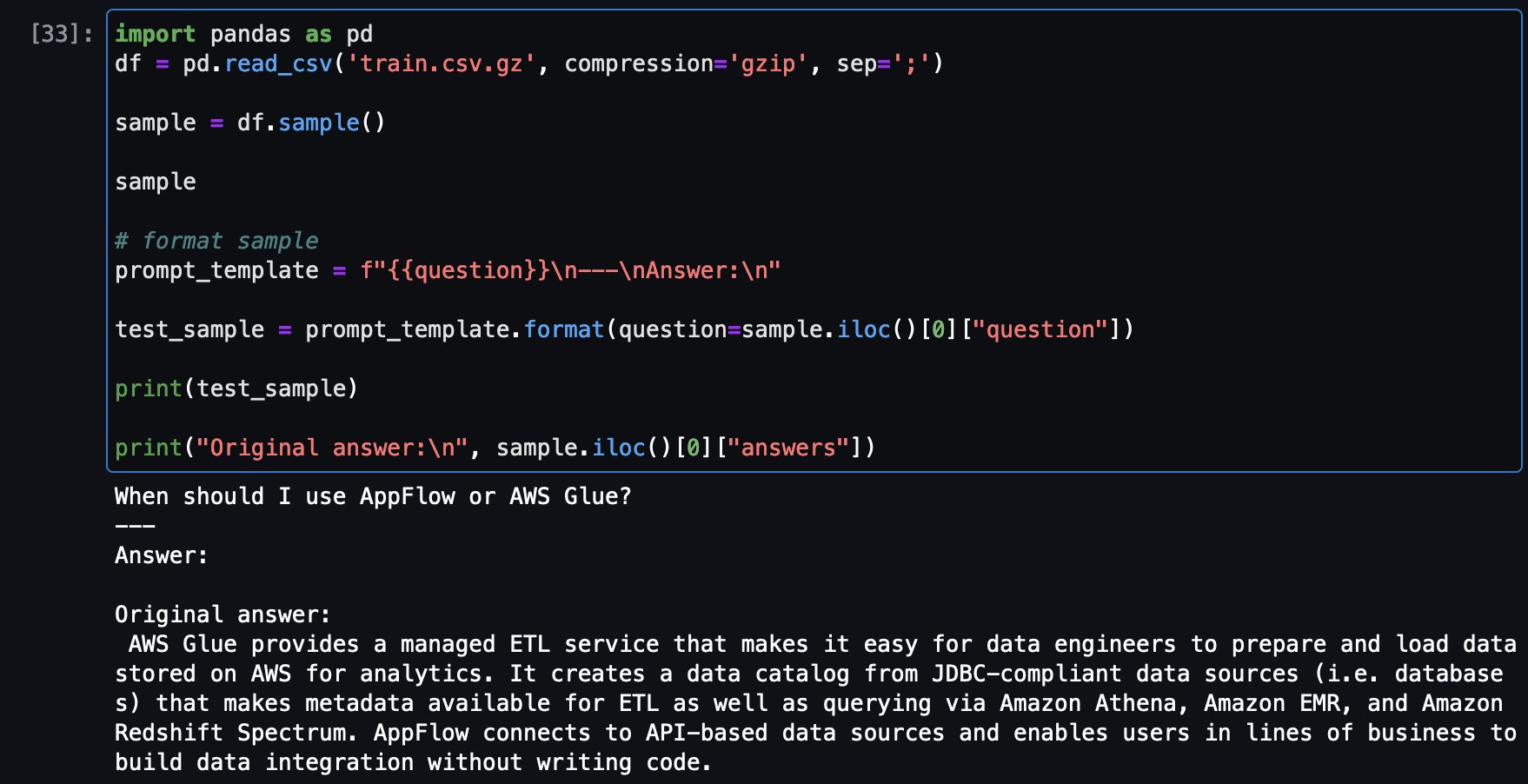
Now, same question being asked to tuned Falcon-7B model:
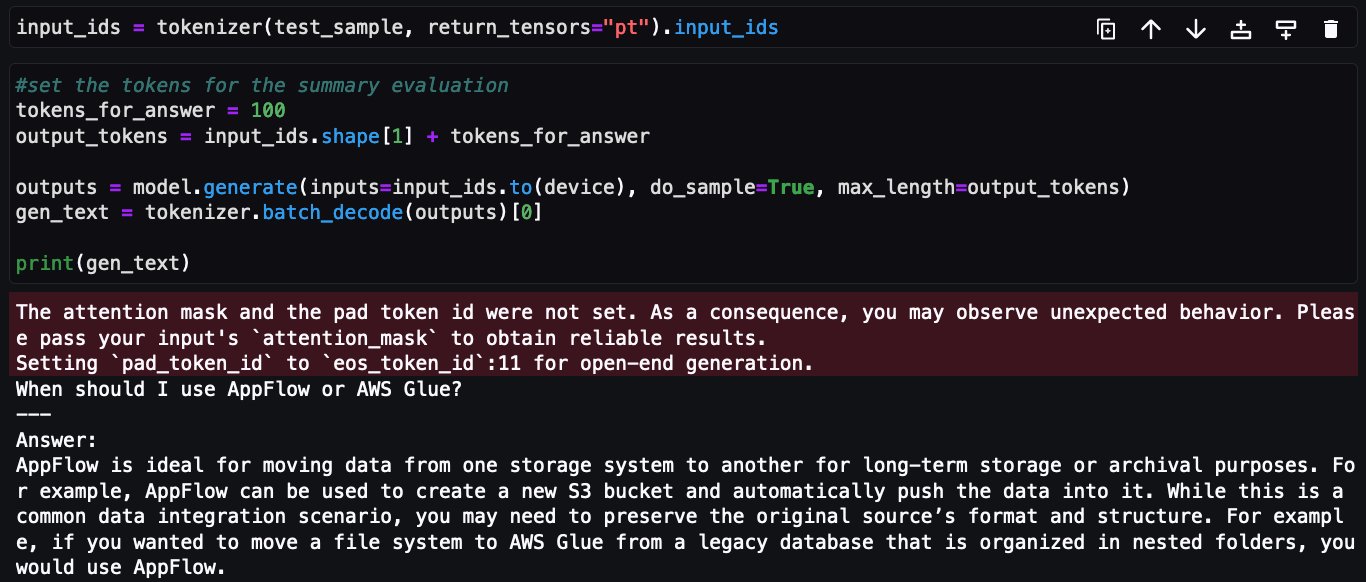
This concludes the implementation of fine tuning Falcon-7B on AWS services FAQ dataset using @remote decorator from Amazon SageMaker Python SDK.
Cleaning up
Complete the following steps to clean up your resources:
- Shut down the Amazon SageMaker Studio instances to avoid incurring additional costs.
- Clean up your Amazon Elastic File System (Amazon EFS) directory by clearing the Hugging Face cache directory:
Conclusion
In this post, we showed you how to effectively use the @remote decorator’s capabilities to fine-tune Falcon-7B model using QLoRA, Hugging Face PEFT with bitsandbtyes without applying significant changes in the training notebook, and used Amazon SageMaker capabilities to run training jobs on a remote cluster.
All the code shown as part of this post to fine-tune Falcon-7B is available in the GitHub repository. The repository also contains notebook showing how to fine-tune Llama-13B.
As a next step, we encourage you to check out the @remote decorator functionality and Python SDK API and use it in your choice of environment and IDE. Additional examples are available in the amazon-sagemaker-examples repository to get you started quickly. You can also check out the following posts:
- Run your local machine learning code as Amazon SageMaker Training jobs with minimal code changes
- Access private repos using the @remote decorator for Amazon SageMaker training workloads
- Interactively fine-tune Falcon-40B and other LLMs on Amazon SageMaker Studio notebooks using QLoRA
About the Authors
 Bruno Pistone is an AI/ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations.
Bruno Pistone is an AI/ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations.
 Vikesh Pandey is a Machine Learning Specialist Solutions Architect at AWS, helping customers from financial industries design and build solutions on generative AI and ML. Outside of work, Vikesh enjoys trying out different cuisines and playing outdoor sports.
Vikesh Pandey is a Machine Learning Specialist Solutions Architect at AWS, helping customers from financial industries design and build solutions on generative AI and ML. Outside of work, Vikesh enjoys trying out different cuisines and playing outdoor sports.