Artificial Intelligence
Detect defects and augment predictions using Amazon Lookout for Vision and Amazon A2I
With machine learning (ML), more powerful technologies have become available that can automate the task of detecting visual anomalies in a product. However, implementing such ML solutions is time-consuming and expensive because it involves managing and setting up complex infrastructure and having the right ML skills. Furthermore, ML applications need human oversight to ensure accuracy with anomaly detection, help provide continuous improvements, and retrain models with updated predictions. However, you’re often forced to choose between an ML-only or human-only system. Companies are looking for the best of both worlds, integrating ML systems into your workflow while keeping a human eye on the results to achieve higher precision.
In this post, we show how you can easily set up Amazon Lookout For Vision to train a visual anomaly detection model using a printed circuit board dataset, use a human-in-the-loop workflow to review the predictions using Amazon Augmented AI (Amazon A2I), augment the dataset to incorporate human input, and retrain the model.
Solution overview
Lookout for Vision is an ML service that helps spot product defects using computer vision to automate the quality inspection process in your manufacturing lines, with no ML expertise required. You can get started with as few as 30 product images (20 normal, 10 anomalous) to train your unique ML model. Lookout for Vision uses your unique ML model to analyze your product images in near-real time and detect product defects, allowing your plant personnel to diagnose and take corrective actions.
Amazon A2I is an ML service that makes it easy to build the workflows required for human review. Amazon A2I brings human review to all developers, removing the undifferentiated heavy lifting associated with building human review systems or managing large numbers of human reviewers, whether running on AWS or not.
To get started with Lookout for Vision, we create a project, create a dataset, train a model, and run inference on test images. After going through these steps, we show you how you can quickly set up a human review process using Amazon A2I and retrain your model with augmented or human reviewed datasets. We also provide an accompanying Jupyter notebook.
Architecture overview
The following diagram illustrates the solution architecture.
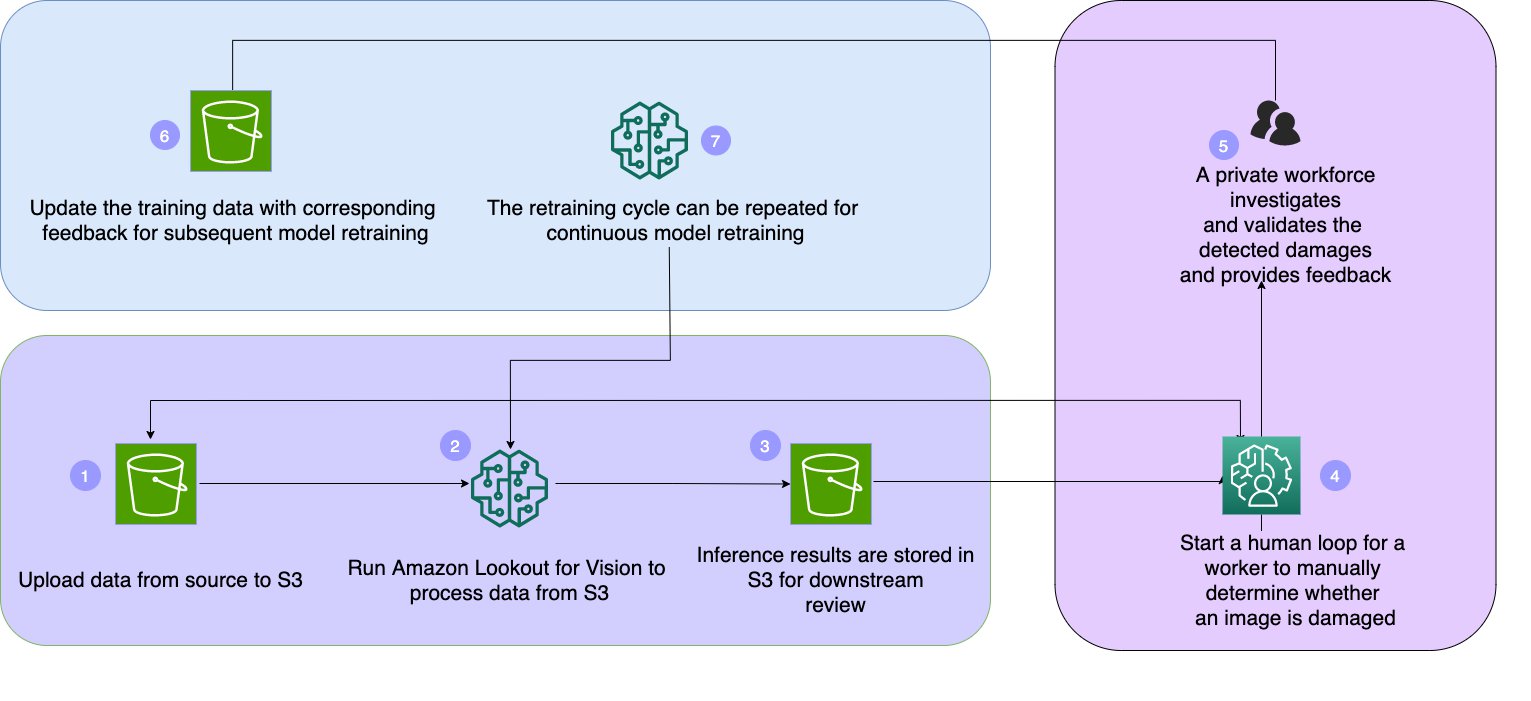
The solution has the following workflow:
- Upload data from the source to Amazon Simple Storage Service (Amazon S3).
- Run Lookout for Vision to process data from the Amazon S3 path.
- Store inference results in Amazon S3 for downstream review.
- Use Lookout for Vision to determine if an input image is damaged and validate that the confidence level is above 70%. If below 70%, we start a human loop for a worker to manually determine whether an image is damaged.
- A private workforce investigates and validates the detected damages and provides feedback.
- Update the training data with corresponding feedback for subsequent model retraining.
- Repeat the retraining cycle for continuous model retraining.
Prerequisites
Before you get started, complete the following steps to set up the Jupyter notebook:
- Create a notebook instance in Amazon SageMaker.
- When the notebook is active, choose Open Jupyter.
- On the Jupyter dashboard, choose New, and choose Terminal.
- In the terminal, enter the following code:
- Open the notebook for this post:
Amazon-Lookout-for-Vision-and-Amazon-A2I-Integration.ipynb.
You’re now ready to run the notebook cells.
- Run the setup environment step to set up the necessary Python SDKs and variables:
In the first step, you need to define the following:
- region – The Region where your project is located
- project_name – The name of your Lookout for Vision project
- bucket – The name of the Amazon S3 bucket where we output the model results
- model_version – Your model version (the default setting is 1)
- Create the S3 buckets to store images:
- Create a manifest file from the dataset by running the cell in the section Create a manifest file from the dataset in the notebook.
Lookout for Vision uses this manifest file to determine the location of the files, as well as the labels associated with the files.
Upload circuit board images to Amazon S3
To train a Lookout for Vision model, we need to copy the sample dataset from our local Jupyter notebook over to Amazon S3:
Create a Lookout for Vision project
You have a couple of options on how to create your Lookout for Vision project: the Lookout for Vision console, the AWS Command Line Interface (AWS CLI), or the Boto3 SDK. We chose the Boto3 SDK in this example, but highly recommend you check out the console method as well.
The steps we take with the SDK are:
- Create a project (the name was defined at the beginning) and tell your project where to find your training dataset. This is done via the manifest file for training.
- Tell your project where to find your test dataset. This is done via the manifest file for test.
This second step is optional. In general, all test-related code is optional; Lookout for Vision also works with just a training dataset. We use both because training and testing is a common (best) practice when training AI and ML models.
Create a manifest file from the dataset
Lookout for Vision uses this manifest file to determine the location of the files, as well as the labels associated with the files. See the following code:
Create a Lookout for Vision project
The following command creates a Lookout for Vision project:
Create and train a model
In this section, we walk through the steps of creating the training and test datasets, training the model, and hosting the model.
Create the training and test datasets from images in Amazon S3
After we create the Lookout for Vision project, we create the project dataset by using the sample images we uploaded to Amazon S3 along with the manifest files. See the following code:
Train the model
After we create the Lookout for Vision project and the datasets, we can train our first model:
When training is complete, we can view available model metrics:
You should see an output similar to the following.
| Metrics | Model Arn | Status Message | Performance | Model Performance |
| F1 Score | 1 | TRAINED | Training completed successfully. | 0.93023 |
| Precision | 1 | TRAINED | Training completed successfully. | 0.86957 |
| Recall | 1 | TRAINED | Training completed successfully. | 1 |
Host the model
Before we can use our newly trained Lookout for Vision model, we need to host it:
Set up Amazon A2I to review predictions from Lookout for Vision
In this section, you set up a human review loop in Amazon A2I to review inferences that are below the confidence threshold. You must first create a private workforce and create a human task UI.
Create a workforce
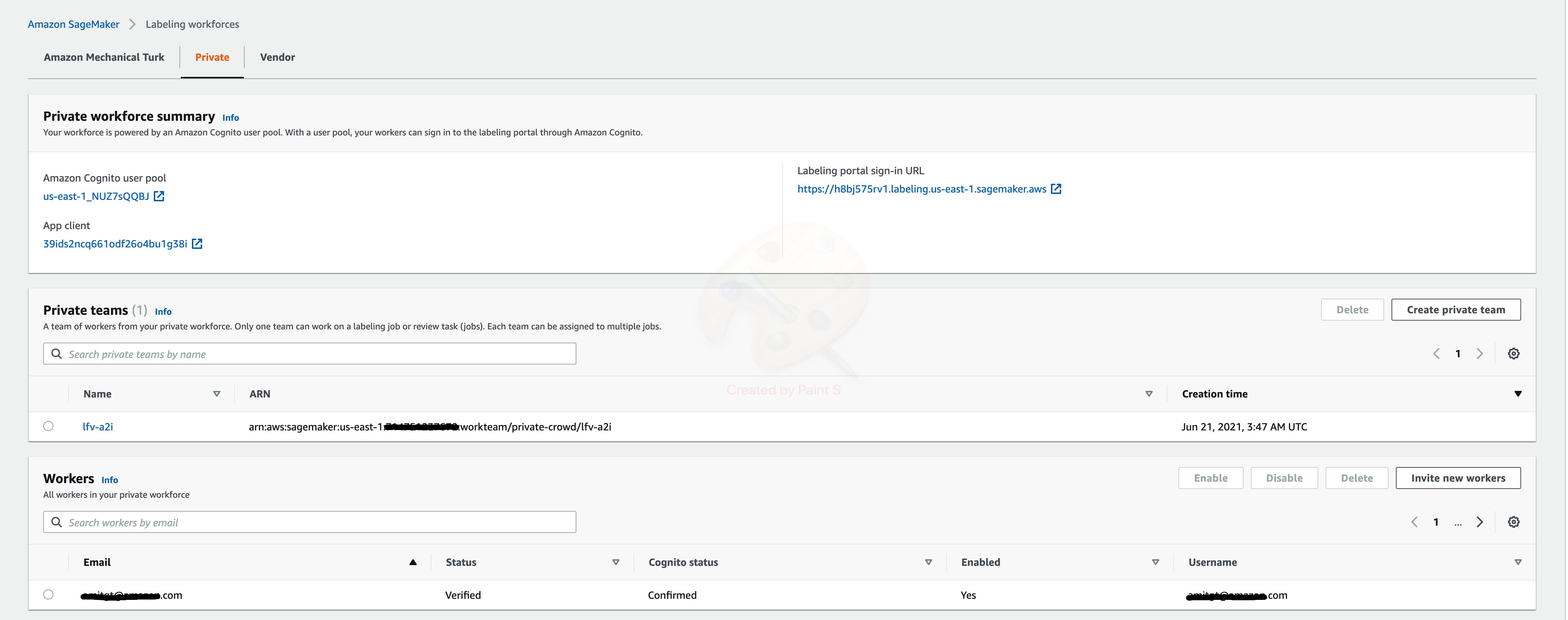
You need to create a workforce via the SageMaker console. Note the ARN of the workforce and enter its value in the notebook cell:
The following screenshot shows the details of a private team named lfv-a2i and its corresponding ARN.
Create a human task UI
You now create a human task UI resource: a UI template in liquid HTML. This HTML page is rendered to the human workers whenever a human loop is required. For over 70 pre-built UIs, see the amazon-a2i-sample-task-uis GitHub repo.
Follow the steps provided in the notebook section Create a human task UI to create the web form, initialize Amazon A2I APIs, and inspect output:
Create a human task workflow
Workflow definitions allow you to specify the following:
- The worker template or human task UI you created in the previous step.
- The workforce that your tasks are sent to. For this post, it’s the private workforce you created in the prerequisite steps.
- The instructions that your workforce receives.
This post uses the Create Flow Definition API to create a workflow definition. The results of human review are stored in an Amazon S3 bucket, which can be accessed by the client application. Run the cell Create a Human task Workflow in the notebook and inspect the output:
Make predictions and start a human loop based on the confidence level threshold
In this section, we loop through an array of new images and use the Lookout for Vision SDK to determine if our input images are damaged or not, and if they’re above or below a defined threshold. For this post, we set the threshold confidence level at .70. If our result is below .70, we start a human loop for a worker to manually determine if our image is normal or an anomaly. See the following code:
You should get the output shown in the following screenshot.


Complete your review and check the human loop status
If inference results are below the defined threshold, a human loop is created. We can review the status of those jobs and wait for results:
The work team sees the following screenshot to choose the correct label for the image.

View results of the Amazon A2I workflow and move objects to the correct folder for retraining
After the work team members have completed the human loop tasks, let’s use the results of the tasks to sort our images into the correct folders for training a new model. See the following code:
Retrain your model based on augmented datasets from Amazon A2I
Training a new model version can be triggered as a batch job on a schedule, manually as needed, based on how many new images have been added to the training folders, and so on. For this example, we use the Lookout for Vision SDK to retrain our model using the images that we’ve now included in our modified dataset. Follow the accompanying Jupyter notebook downloadable from [GitHub-LINK] for the complete notebook.
You should see an output similar to the following.
Now that we’ve trained a new model using newly added images, let’s check the model metrics! We show the results from the first model and the second model at the same time:
You should see an output similar to the following. The table shows two models: a hosted model (ModelVersion:1) and the retrained model (ModelVersion:2). The performance of the retrained model is better with the human reviewed and labeled images.
| Metrics | ModelVersion | Status | StatusMessage | Model Performance |
| F1 Score | 2 | TRAINED | Training completed successfully. | 0.98 |
| Precision | 2 | TRAINED | Training completed successfully. | 0.96 |
| Recall | 2 | TRAINED | Training completed successfully. | 1 |
| F1 Score | 1 | HOSTED | The model is running. | 0.93023 |
| Precision | 1 | HOSTED | The model is running. | 0.86957 |
| Recall | 1 | HOSTED | The model is running. | 1 |
Clean up
Run the Stop the model and cleanup resources cell to clean up the resources that were created. Delete any Lookout for Vision projects you’re no longer using, and remove objects from Amazon S3 to save costs. See the following code:
Conclusion
This post demonstrated how you can use Lookout for Vision and Amazon A2I to train models to detect defects in objects unique to your business and define conditions to send the predictions to a human workflow with labelers to review and update the results. You can use the human labeled output to augment the training dataset for retraining to improve the model accuracy.
Start your journey towards industrial anomaly detection and identification by visiting the Lookout for Vision Developer Guide and the Amazon A2I Developer Guide.
About the Author
 Dennis Thurmon is a Solutions Architect at AWS, with a passion for Artificial Intelligence and Machine Learning. Based in Seattle, Washington, Dennis worked as a Systems Development Engineer on the Amazon Go and Amazon Books team before focusing on helping AWS customers bring their workloads to life in the AWS Cloud.
Dennis Thurmon is a Solutions Architect at AWS, with a passion for Artificial Intelligence and Machine Learning. Based in Seattle, Washington, Dennis worked as a Systems Development Engineer on the Amazon Go and Amazon Books team before focusing on helping AWS customers bring their workloads to life in the AWS Cloud.
 Amit Gupta is an AI Services Solutions Architect at AWS. He is passionate about enabling customers with well-architected machine learning solutions at scale.
Amit Gupta is an AI Services Solutions Architect at AWS. He is passionate about enabling customers with well-architected machine learning solutions at scale.
 Neel Sendas is a Senior Technical Account Manager at Amazon Web Services. Neel works with enterprise customers to design, deploy, and scale cloud applications to achieve their business goals. He has worked on various ML use cases, ranging from anomaly detection to predictive product quality for manufacturing and logistics optimization. When he is not helping customers, he dabbles in golf and salsa dancing.
Neel Sendas is a Senior Technical Account Manager at Amazon Web Services. Neel works with enterprise customers to design, deploy, and scale cloud applications to achieve their business goals. He has worked on various ML use cases, ranging from anomaly detection to predictive product quality for manufacturing and logistics optimization. When he is not helping customers, he dabbles in golf and salsa dancing.