Artificial Intelligence
Category: Learning Levels
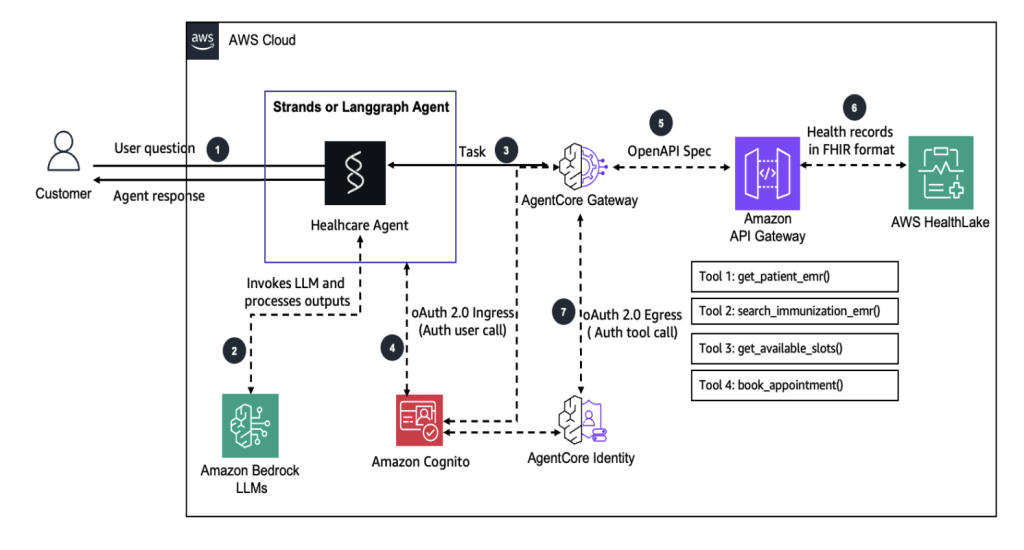
Building health care agents using Amazon Bedrock AgentCore
In this solution, we demonstrate how the user (a parent) can interact with a Strands or LangGraph agent in conversational style and get information about the immunization history and schedule of their child, inquire about the available slots, and book appointments. With some changes, AI agents can be made event-driven so that they can automatically send reminders, book appointments, and so on.

Migrate from Anthropic’s Claude Sonnet 3.x to Claude Sonnet 4.x on Amazon Bedrock
This post provides a systematic approach to migrating from Anthropic’s Claude 3.5 Sonnet to Claude Sonnet 4.5 on Amazon Bedrock. We examine the key model differences, highlight essential migration considerations, and deliver proven best practices to transform this necessary transition into a strategic advantage that drives measurable value for your organization.
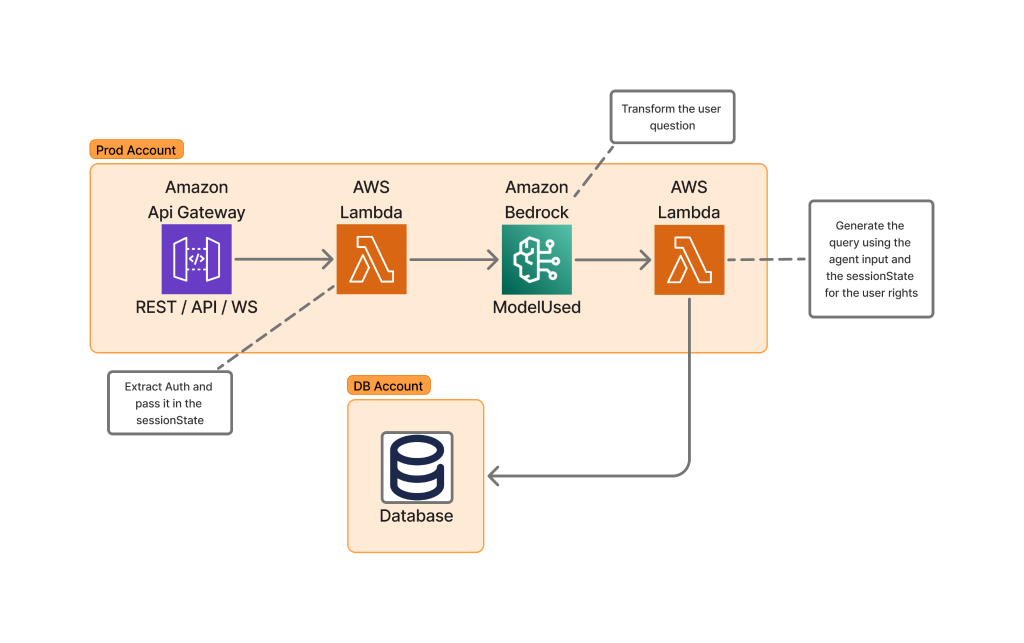
How Skello uses Amazon Bedrock to query data in a multi-tenant environment while keeping logical boundaries
Skello is a leading human resources (HR) software as a service (SaaS) solution focusing on employee scheduling and workforce management. Catering to diverse sectors such as hospitality, retail, healthcare, construction, and industry, Skello offers features including schedule creation, time tracking, and payroll preparation. We dive deep into the challenges of implementing large language models (LLMs) for data querying, particularly in the context of a French company operating under the General Data Protection Regulation (GDPR).
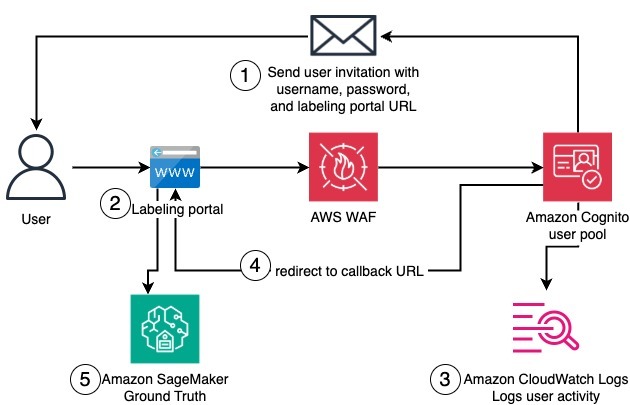
Create a private workforce on Amazon SageMaker Ground Truth with the AWS CDK
In this post, we present a complete solution for programmatically creating private workforces on Amazon SageMaker AI using the AWS Cloud Development Kit (AWS CDK), including the setup of a dedicated, fully configured Amazon Cognito user pool.
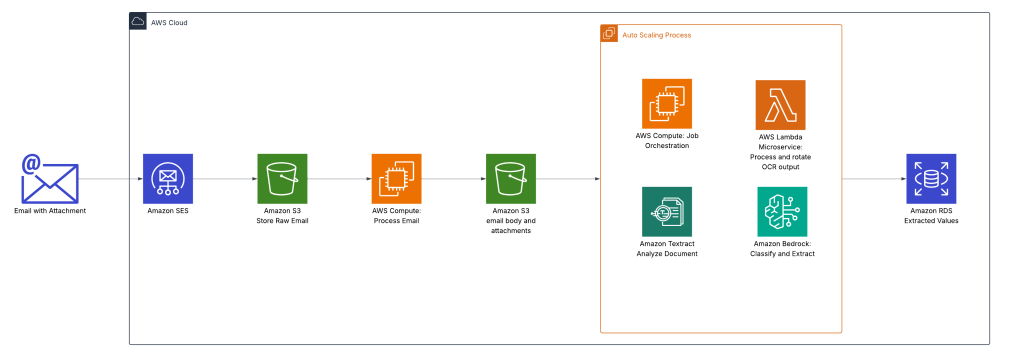
Oldcastle accelerates document processing with Amazon Bedrock
This post explores how Oldcastle partnered with AWS to transform their document processing workflow using Amazon Bedrock with Amazon Textract. We discuss how Oldcastle overcame the limitations of their previous OCR solution to automate the processing of hundreds of thousands of POD documents each month, dramatically improving accuracy while reducing manual effort.

Build trustworthy AI agents with Amazon Bedrock AgentCore Observability
In this post, we walk you through implementation options for both agents hosted on Amazon Bedrock AgentCore Runtime and agents hosted on other services like Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Kubernetes Service (Amazon EKS), AWS Lambda, or alternative cloud providers. We also share best practices for incorporating observability throughout the development lifecycle.
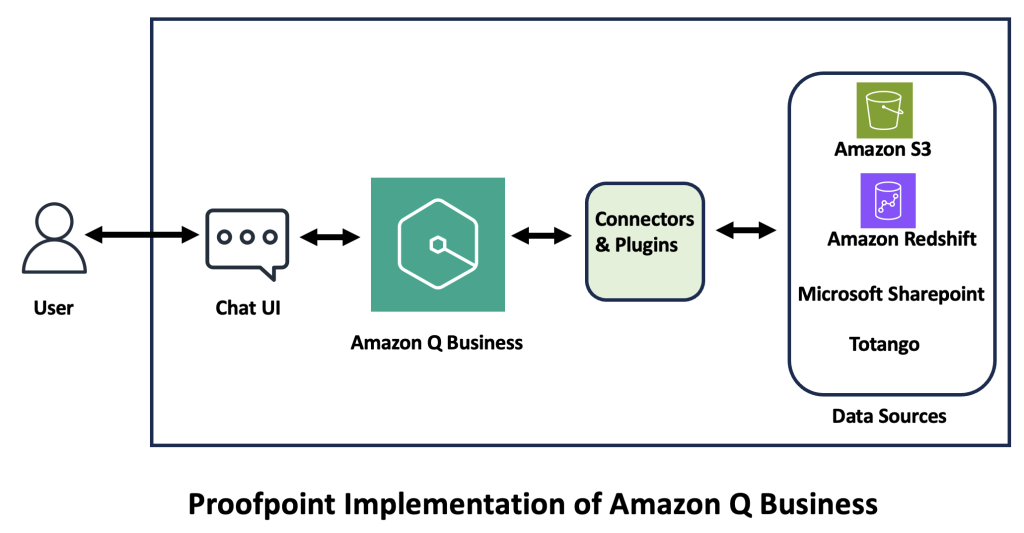
Unlocking the future of professional services: How Proofpoint uses Amazon Q Business
Proofpoint has redefined its professional services by integrating Amazon Q Business, a fully managed, generative AI powered assistant that you can configure to answer questions, provide summaries, generate content, and complete tasks based on your enterprise data. In this post, we explore how Amazon Q Business transformed Proofpoint’s professional services, detailing its deployment, functionality, and future roadmap.
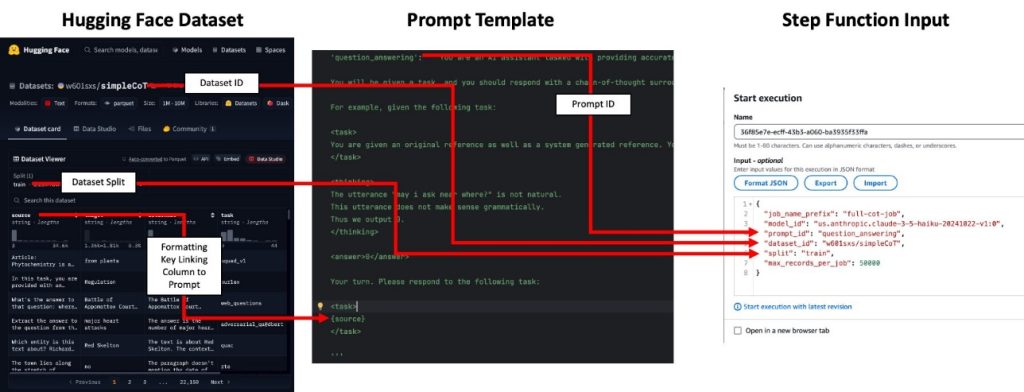
Build a serverless Amazon Bedrock batch job orchestration workflow using AWS Step Functions
In this post, we introduce a flexible and scalable solution that simplifies the batch inference workflow. This solution provides a highly scalable approach to managing your FM batch inference needs, such as generating embeddings for millions of documents or running custom evaluation or completion tasks with large datasets.

Deploy Amazon Bedrock Knowledge Bases using Terraform for RAG-based generative AI applications
In this post, we demonstrated how to automate the deployment of Amazon Knowledge Bases for RAG applications using Terraform.

Document intelligence evolved: Building and evaluating KIE solutions that scale
In this blog post, we demonstrate an end-to-end approach for building and evaluating a KIE solution using Amazon Nova models available through Amazon Bedrock. This end-to-end approach encompasses three critical phases: data readiness (understanding and preparing your documents), solution development (implementing extraction logic with appropriate models), and performance measurement (evaluating accuracy, efficiency, and cost-effectiveness). We illustrate this comprehensive approach using the FATURA dataset—a collection of diverse invoice documents that serves as a representative proxy for real-world enterprise data.