Artificial Intelligence
Category: Amazon EC2

University of California Los Angeles delivers an immersive theater experience with AWS generative AI services
In this post, we will walk through the performance constraints and design choices by OARC and REMAP teams at UCLA, including how AWS serverless infrastructure, AWS Managed Services, and generative AI services supported the rapid design and deployment of our solution. We will also describe our use of Amazon SageMaker AI and how it can be used reliably in immersive live experiences.

Optimizing Mobileye’s REM™ with AWS Graviton: A focus on ML inference and Triton integration
In this post, we focus on one portion of the REM™ system: the automatic identification of changes to the road structure which we will refer to as Change Detection. We will share our journey of architecting and deploying a solution for Change Detection, the core of which is a deep learning model called CDNet. We will share real-life decisions and tradeoffs when building and deploying a high-scale, highly parallelized algorithmic pipeline based on a Deep Learning (DL) model, with an emphasis on efficiency and throughput.
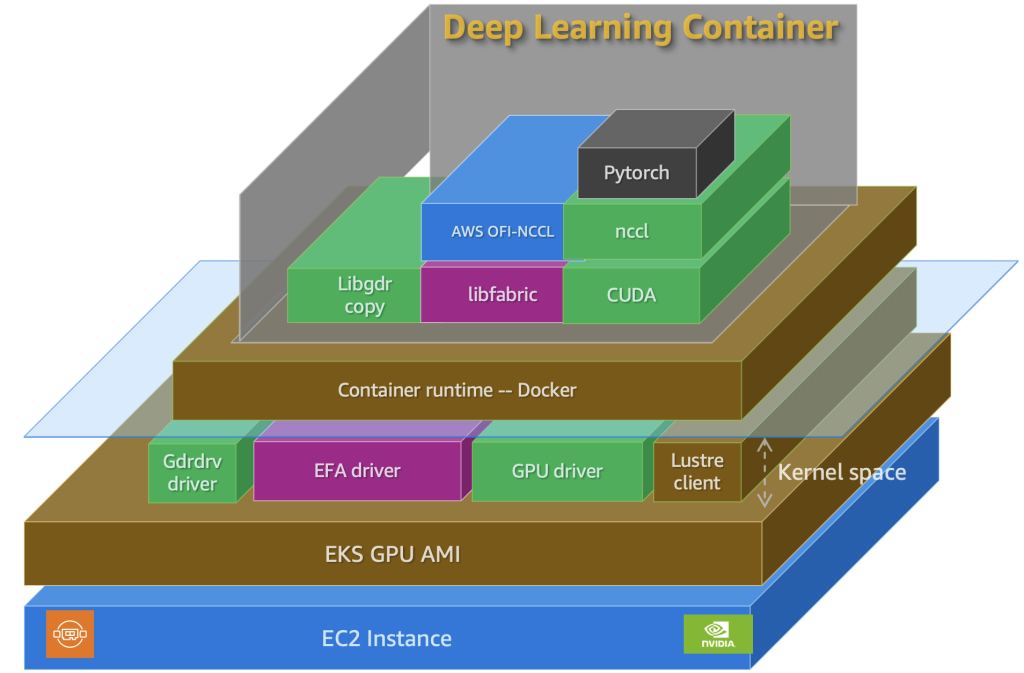
Configure and verify a distributed training cluster with AWS Deep Learning Containers on Amazon EKS
Misconfiguration issues in distributed training with Amazon EKS can be prevented following a systematic approach to launch required components and verify their proper configuration. This post walks through the steps to set up and verify an EKS cluster for training large models using DLCs.

How Amazon scaled Rufus by building multi-node inference using AWS Trainium chips and vLLM
In this post, Amazon shares how they developed a multi-node inference solution for Rufus, their generative AI shopping assistant, using Amazon Trainium chips and vLLM to serve large language models at scale. The solution combines a leader/follower orchestration model, hybrid parallelism strategies, and a multi-node inference unit abstraction layer built on Amazon ECS to deploy models across multiple nodes while maintaining high performance and reliability.

AWS AI infrastructure with NVIDIA Blackwell: Two powerful compute solutions for the next frontier of AI
In this post, we announce general availability of Amazon EC2 P6e-GB200 UltraServers and P6-B200 instances, powered by NVIDIA Blackwell GPUs, designed for training and deploying the largest, most sophisticated AI models.

Host concurrent LLMs with LoRAX
In this post, we explore how Low-Rank Adaptation (LoRA) can be used to address these challenges effectively. Specifically, we discuss using LoRA serving with LoRA eXchange (LoRAX) and Amazon Elastic Compute Cloud (Amazon EC2) GPU instances, allowing organizations to efficiently manage and serve their growing portfolio of fine-tuned models, optimize costs, and provide seamless performance for their customers.

Optimizing Mixtral 8x7B on Amazon SageMaker with AWS Inferentia2
This post demonstrates how to deploy and serve the Mixtral 8x7B language model on AWS Inferentia2 instances for cost-effective, high-performance inference. We’ll walk through model compilation using Hugging Face Optimum Neuron, which provides a set of tools enabling straightforward model loading, training, and inference, and the Text Generation Inference (TGI) Container, which has the toolkit for deploying and serving LLMs with Hugging Face.

Unleash AI innovation with Amazon SageMaker HyperPod
In this post, we show how SageMaker HyperPod, and its new features introduced at AWS re:Invent 2024, is designed to meet the demands of modern AI workloads, offering a persistent and optimized cluster tailored for distributed training and accelerated inference at cloud scale and attractive price-performance.

Reduce conversational AI response time through inference at the edge with AWS Local Zones
This guide demonstrates how to deploy an open source foundation model from Hugging Face on Amazon EC2 instances across three locations: a commercial AWS Region and two AWS Local Zones. Through comparative benchmarking tests, we illustrate how deploying foundation models in Local Zones closer to end users can significantly reduce latency—a critical factor for real-time applications such as conversational AI assistants.

How Rocket Companies modernized their data science solution on AWS
In this post, we share how we modernized Rocket Companies’ data science solution on AWS to increase the speed to delivery from eight weeks to under one hour, improve operational stability and support by reducing incident tickets by over 99% in 18 months, power 10 million automated data science and AI decisions made daily, and provide a seamless data science development experience.