Artificial Intelligence
Category: Amazon SageMaker

Speed up delivery of ML workloads using Code Editor in Amazon SageMaker Unified Studio
In this post, we walk through how you can use the new Code Editor and multiple spaces support in SageMaker Unified Studio. The sample solution shows how to develop an ML pipeline that automates the typical end-to-end ML activities to build, train, evaluate, and (optionally) deploy an ML model.
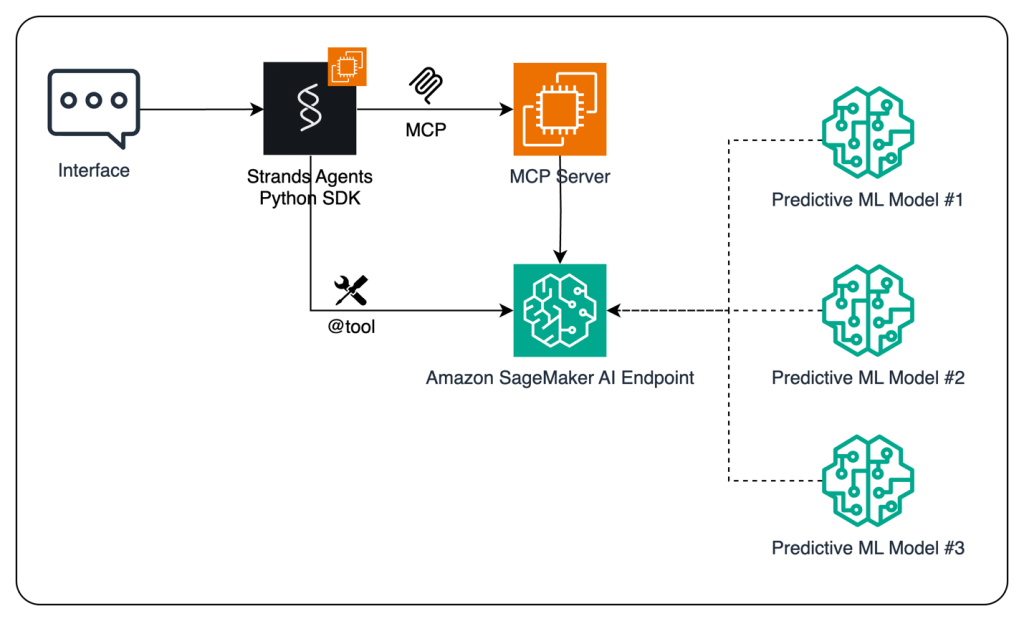
Enhance AI agents using predictive ML models with Amazon SageMaker AI and Model Context Protocol (MCP)
In this post, we demonstrate how to enhance AI agents’ capabilities by integrating predictive ML models using Amazon SageMaker AI and the MCP. By using the open source Strands Agents SDK and the flexible deployment options of SageMaker AI, developers can create sophisticated AI applications that combine conversational AI with powerful predictive analytics capabilities.
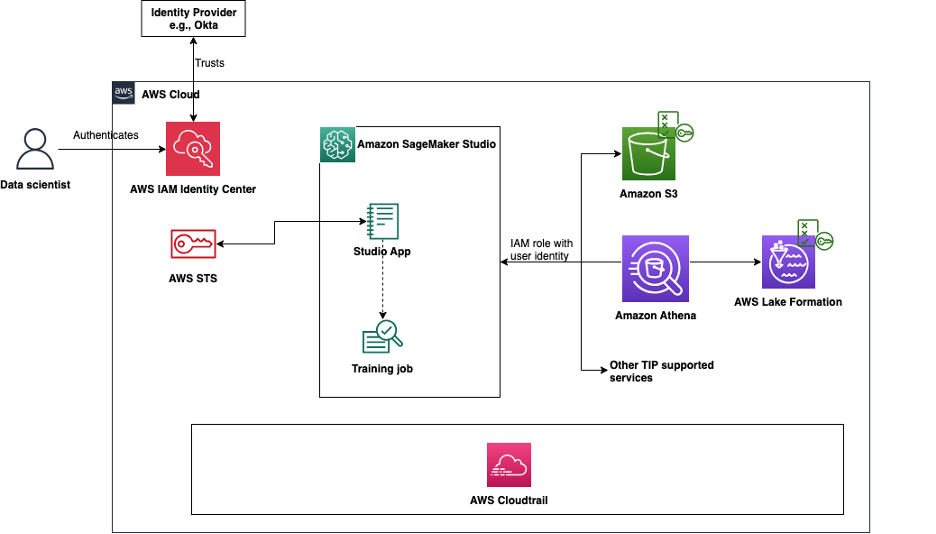
Simplify access control and auditing for Amazon SageMaker Studio using trusted identity propagation
In this post, we explore how to enable and use trusted identity propagation in Amazon SageMaker Studio, which allows organizations to simplify access management by granting permissions to existing AWS IAM Identity Center identities. The solution demonstrates how to implement fine-grained access controls based on a physical user’s identity, maintain detailed audit logs across supported AWS services, and support long-running user background sessions for training jobs.
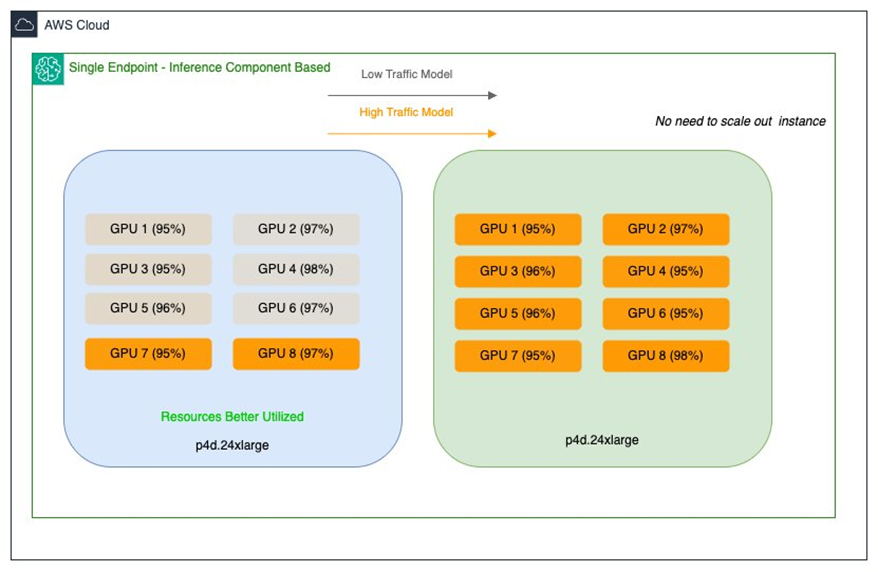
Optimizing Salesforce’s model endpoints with Amazon SageMaker AI inference components
In this post, we share how the Salesforce AI Platform team optimized GPU utilization, improved resource efficiency and achieved cost savings using Amazon SageMaker AI, specifically inference components.
Scalable intelligent document processing using Amazon Bedrock Data Automation
In the blog post Scalable intelligent document processing using Amazon Bedrock, we demonstrated how to build a scalable IDP pipeline using Anthropic foundation models on Amazon Bedrock. Although that approach delivered robust performance, the introduction of Amazon Bedrock Data Automation brings a new level of efficiency and flexibility to IDP solutions. This post explores how Amazon Bedrock Data Automation enhances document processing capabilities and streamlines the automation journey.

Train and deploy AI models at trillion-parameter scale with Amazon SageMaker HyperPod support for P6e-GB200 UltraServers
In this post, we review the technical specifications of P6e-GB200 UltraServers, discuss their performance benefits, and highlight key use cases. We then walk though how to purchase UltraServer capacity through flexible training plans and get started using UltraServers with SageMaker HyperPod.

How Indegene’s AI-powered social intelligence for life sciences turns social media conversations into insights
This post explores how Indegene’s Social Intelligence Solution uses advanced AI to help life sciences companies extract valuable insights from digital healthcare conversations. Built on AWS technology, the solution addresses the growing preference of HCPs for digital channels while overcoming the challenges of analyzing complex medical discussions on a scale.
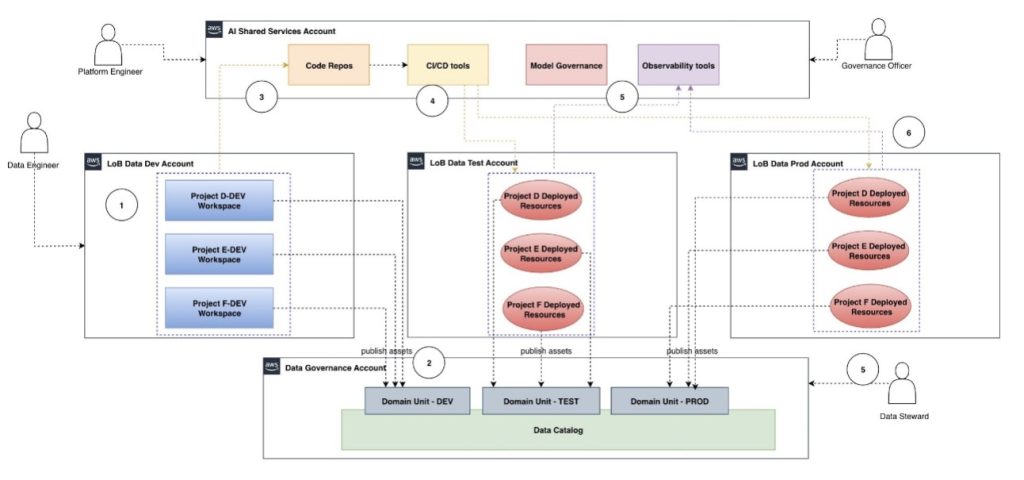
Automate AIOps with Amazon SageMaker Unified Studio projects, Part 1: Solution architecture
This post presents architectural strategies and a scalable framework that helps organizations manage multi-tenant environments, automate consistently, and embed governance controls as they scale their AI initiatives with SageMaker Unified Studio.

Fine-tune OpenAI GPT-OSS models on Amazon SageMaker AI using Hugging Face libraries
Released on August 5, 2025, OpenAI’s GPT-OSS models, gpt-oss-20b and gpt-oss-120b, are now available on AWS through Amazon SageMaker AI and Amazon Bedrock. In this post, we walk through the process of fine-tuning a GPT-OSS model in a fully managed training environment using SageMaker AI training jobs.

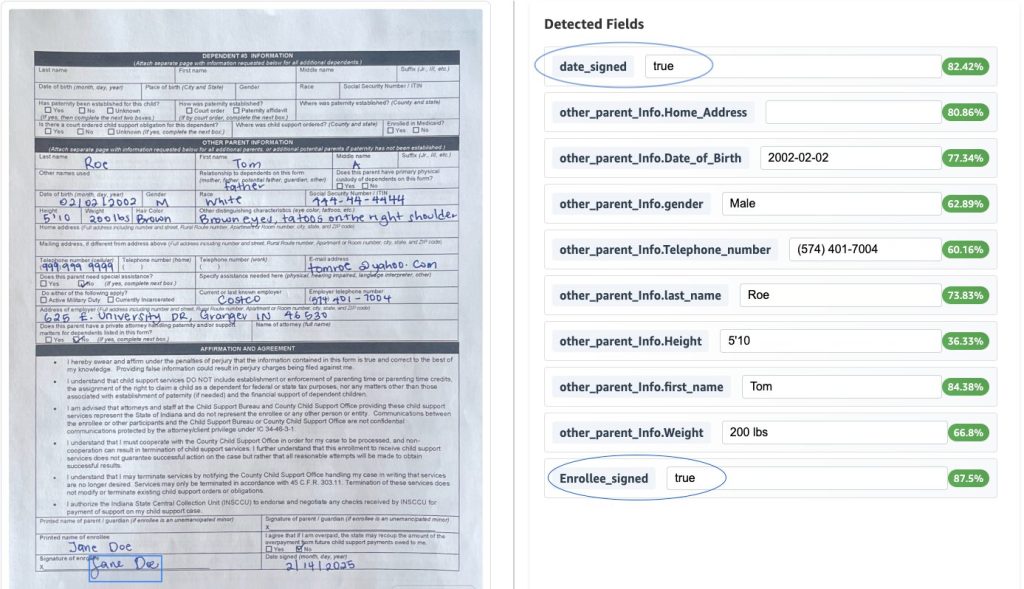
Process multi-page documents with human review using Amazon Bedrock Data Automation and Amazon SageMaker AI
In this post, we show how to process multi-page documents with a human review loop using Amazon Bedrock Data Automation and Amazon SageMaker AI.