Artificial Intelligence
Category: Amazon SageMaker JumpStart

Create a web UI to interact with LLMs using Amazon SageMaker JumpStart
The launch of ChatGPT and rise in popularity of generative AI have captured the imagination of customers who are curious about how they can use this technology to create new products and services on AWS, such as enterprise chatbots, which are more conversational. This post shows you how you can create a web UI, which […]

Mitigate hallucinations through Retrieval Augmented Generation using Pinecone vector database & Llama-2 from Amazon SageMaker JumpStart
Despite the seemingly unstoppable adoption of LLMs across industries, they are one component of a broader technology ecosystem that is powering the new AI wave. Many conversational AI use cases require LLMs like Llama 2, Flan T5, and Bloom to respond to user queries. These models rely on parametric knowledge to answer questions. The model […]

Operationalize LLM Evaluation at Scale using Amazon SageMaker Clarify and MLOps services
In the last few years Large Language Models (LLMs) have risen to prominence as outstanding tools capable of understanding, generating and manipulating text with unprecedented proficiency. Their potential applications span from conversational agents to content generation and information retrieval, holding the promise of revolutionizing all industries. However, harnessing this potential while ensuring the responsible and […]

Build a contextual chatbot for financial services using Amazon SageMaker JumpStart, Llama 2 and Amazon OpenSearch Serverless with Vector Engine
The financial service (FinServ) industry has unique generative AI requirements related to domain-specific data, data security, regulatory controls, and industry compliance standards. In addition, customers are looking for choices to select the most performant and cost-effective machine learning (ML) model and the ability to perform necessary customization (fine-tuning) to fit their business use cases. Amazon […]

Text embedding and sentence similarity retrieval at scale with Amazon SageMaker JumpStart
In this post, we demonstrate how to use the SageMaker Python SDK for text embedding and sentence similarity. Sentence similarity involves assessing the likeness between two pieces of text after they are converted into embeddings by the LLM, which is a foundation step for applications like Retrieval Augmented Generation (RAG).
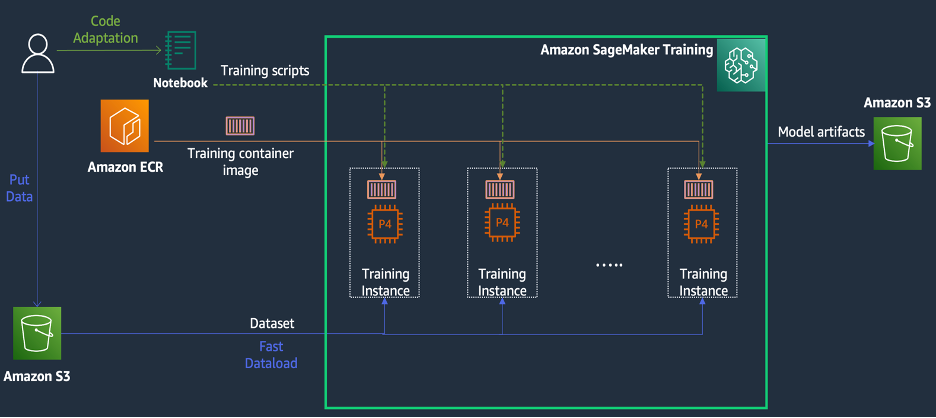
KT’s journey to reduce training time for a vision transformers model using Amazon SageMaker
KT Corporation is one of the largest telecommunications providers in South Korea, offering a wide range of services including fixed-line telephone, mobile communication, and internet, and AI services. KT’s AI Food Tag is an AI-based dietary management solution that identifies the type and nutritional content of food in photos using a computer vision model. This […]

Retrieval-Augmented Generation with LangChain, Amazon SageMaker JumpStart, and MongoDB Atlas Semantic Search
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to […]

Best prompting practices for using the Llama 2 Chat LLM through Amazon SageMaker JumpStart
Llama 2 stands at the forefront of AI innovation, embodying an advanced auto-regressive language model developed on a sophisticated transformer foundation. It’s tailored to address a multitude of applications in both the commercial and research domains with English as the primary linguistic concentration. Its model parameters scale from an impressive 7 billion to a remarkable […]

Fine-tune and Deploy Mistral 7B with Amazon SageMaker JumpStart
Today, we are excited to announce the capability to fine-tune the Mistral 7B model using Amazon SageMaker JumpStart. You can now fine-tune and deploy Mistral text generation models on SageMaker JumpStart using the Amazon SageMaker Studio UI with a few clicks or using the SageMaker Python SDK. Foundation models perform very well with generative tasks, […]

Harnessing the power of enterprise data with generative AI: Insights from Amazon Kendra, LangChain, and large language models
Large language models (LLMs) with their broad knowledge, can generate human-like text on almost any topic. However, their training on massive datasets also limits their usefulness for specialized tasks. Without continued learning, these models remain oblivious to new data and trends that emerge after their initial training. Furthermore, the cost to train new LLMs can […]