Artificial Intelligence
Category: Amazon Textract

Intelligent document processing with AWS AI services: Part 2
Amazon’s intelligent document processing (IDP) helps you speed up your business decision cycles and reduce costs. Across multiple industries, customers need to process millions of documents per year in the course of their business. For customers who process millions of documents, this is a critical aspect for the end-user experience and a top digital transformation […]

Intelligent document processing with AWS AI services: Part 1
Organizations across industries such as healthcare, finance and lending, legal, retail, and manufacturing often have to deal with a lot of documents in their day-to-day business processes. These documents contain critical information that are key to making decisions on time in order to maintain the highest levels of customer satisfaction, faster customer onboarding, and lower […]

Analyze and tag assets stored in Veeva Vault PromoMats using Amazon AppFlow and Amazon AI Services
In a previous post, we talked about analyzing and tagging assets stored in Veeva Vault PromoMats using Amazon AI services and the Veeva Vault Platform’s APIs. In this post, we explore how to use Amazon AppFlow, a fully managed integration service that enables you to securely transfer data from software as a service (SaaS) applications […]

Use AWS AI and ML services to foster accessibility and inclusion of people with a visual or communication disability
AWS offers a broad set of artificial intelligence (AI) and machine learning (ML) services, including a suite of pre-trained, ready-to-use services for developers with no prior ML experience. In this post, we demonstrate how to use such services to build an application that fosters the inclusion of people, who speak a different language or those […]

Merge cells and column headers in Amazon Textract tables
Financial documents such as bank, loan, or mortgage statements are often formatted to be visually appealing and easy to read for the human eye. These same features can also make automated processing challenging at times. For instance, in the following sample statement, merging rows or columns in a table helps reduce information redundancy, but it […]

Moderate, classify, and process documents using Amazon Rekognition and Amazon Textract
Many companies are overwhelmed by the abundant volume of documents they have to process, organize, and classify to serve their customers better. Examples of such can be loan applications, tax filing, and billing. Such documents are more commonly received in image formats and are mostly multi-paged and in low-quality format. To be more competitive and […]

Increase your content reach with automated document-to-speech conversion using Amazon AI services
Reading the printed word opens up a world of information, imagination, and creativity. However, scanned books and documents may be difficult for people with vision impairment and learning disabilities to consume. In addition, some people prefer to listen to text-based content versus reading it. A document-to-speech solution extends the reach of digital content by giving […]

Specify and extract information from documents using the new Queries feature in Amazon Textract
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. Amazon Textract now offers the flexibility to specify the data you need to extract from documents using the new Queries feature within the Analyze Document API. You don’t need to know the structure of the […]
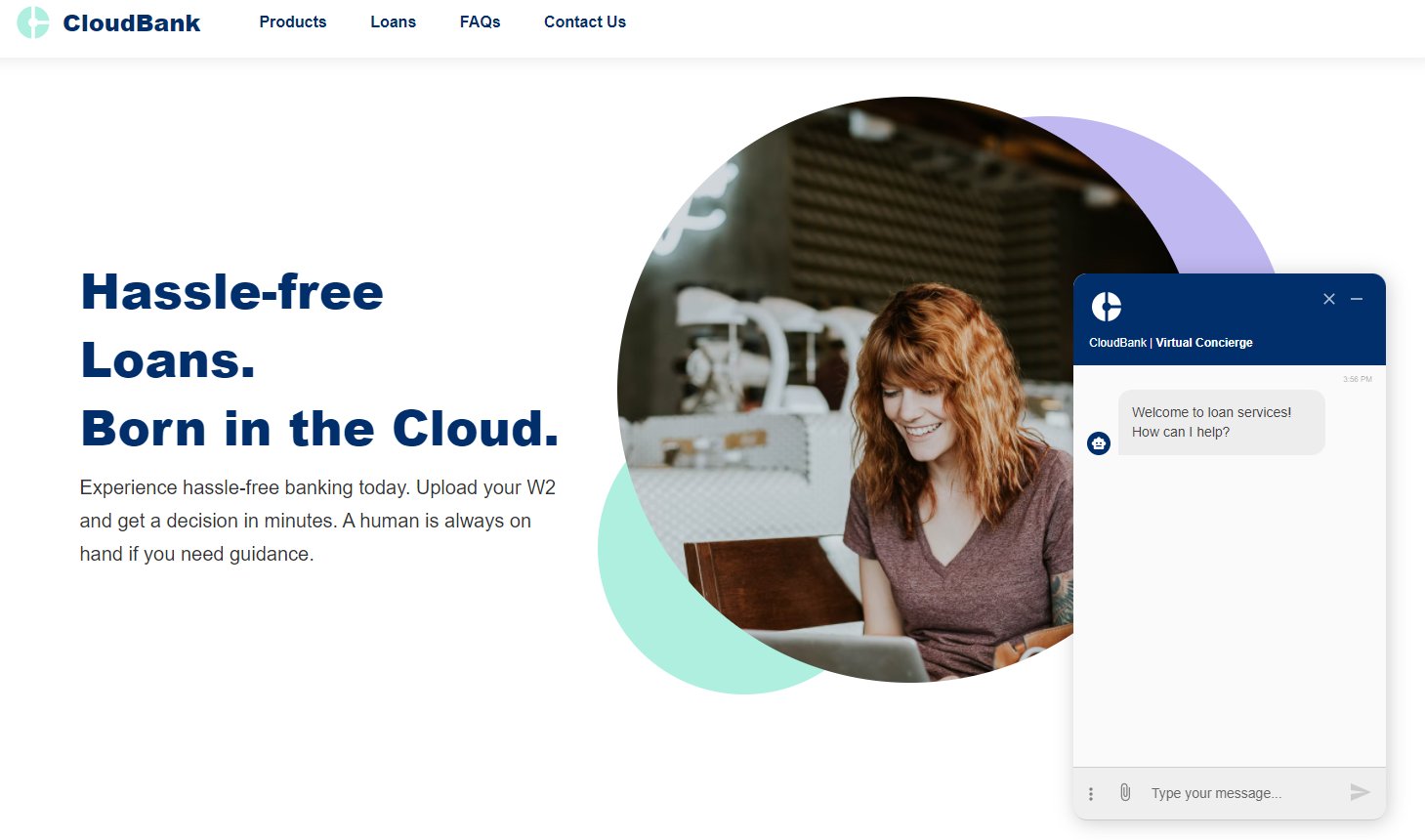
Build a virtual credit approval agent with Amazon Lex, Amazon Textract, and Amazon Connect
Banking and financial institutions review thousands of credit applications per week. The credit approval process requires financial organizations to invest time and resources in reviewing documents like W2s, bank statements, and utility bills. The overall experience can be costly for the organization. At the same time, organizations have to consider borrowers, who are waiting for […]

Enable Amazon Kendra search for a scanned or image-based text document
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines search for your websites and applications so your employees and customers can easily find the content they’re looking for, even when it’s scattered across multiple locations and content repositories within your organization. Amazon Kendra supports a variety of document formats, […]